DLA Spark基于云原生架構,提供面向數據湖場景的數據分析和計算功能。開通DLA服務后,您只需簡單的配置,就可以提交Spark作業,無需關心Spark集群部署。
云原生數據湖分析(DLA)產品已退市,云原生數據倉庫 AnalyticDB MySQL 版湖倉版支持DLA已有功能,并提供更多的功能和更好的性能。AnalyticDB for MySQL相關使用文檔,請參見Spark應用開發。
傳統開源Spark集群版面臨的挑戰
Spark是大數據領域十分流行的引擎,面向數據湖場景,Spark本身內置的數據源連接器,可以很方便的擴展接口。Spark既支持使用SQL,又支持編寫多種語言的DataFrame代碼,兼具易用性和靈活性。Spark一站式的引擎能力,可以同時提供SQL、流、機器學習、圖計算的能力。傳統Spark集群版的方案架構圖如下所示: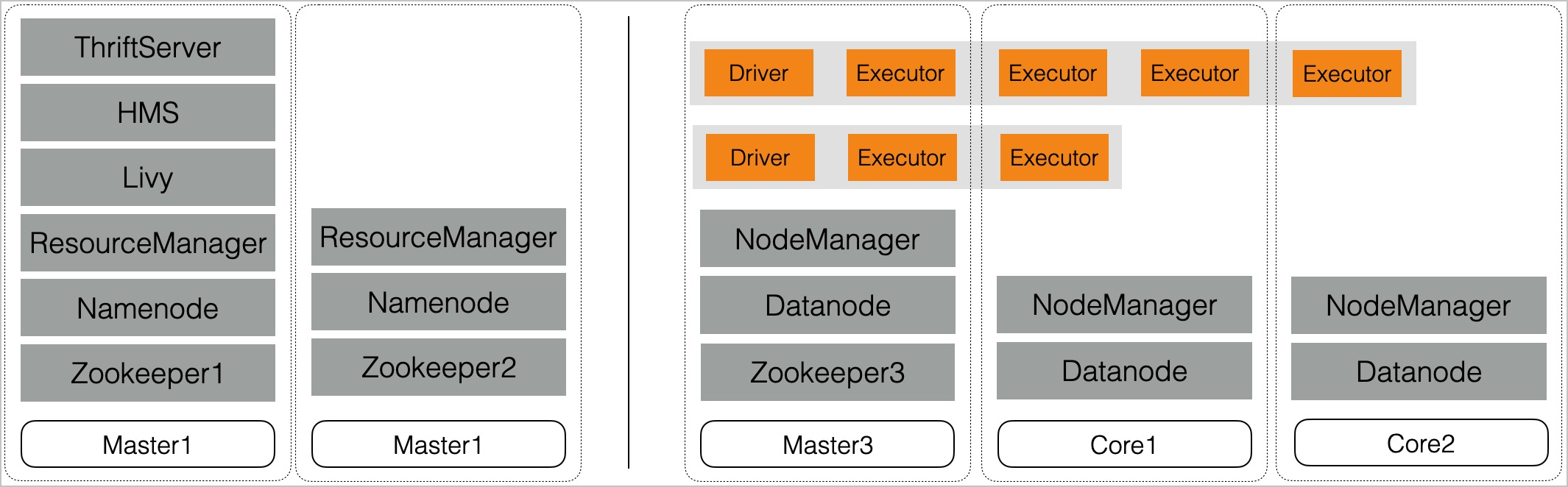
但是對于傳統Spark集群版,用戶首先需要部署一套開源大數據基礎組件:Yarn、HDFS、Zookeeper等,可能會存在以下問題:
使用門檻高:開發者需要同時熟悉多種大數據組件,才能完成開發與運維相關工作,如果遇到疑難問題,還要去深入研究社區源碼。
運維成本高:企業往往需要一個運維團隊,以運維多套開源組件。運維團隊的職責包括配置資源節點、配置和部署開源軟件、監控開源組件、開源組件升級、集群擴縮容等。典型的,為了滿足企業級需求,比如權限隔離、監控報警等,還需要做定制化開發。
資源成本高:Spark作業負載往往具備波峰波谷的特點,在低峰期,Spark集群的空閑資源是浪費的;Spark集群的管控組件(比如,集群Master節點,Zookeeper、Hadoop等后臺進程的資源開銷等),是不會對用戶產生價值的,屬于額外開銷。
彈性能力不足:在業務高峰期,企業往往需要能夠準確預估資源需求,并及時擴容機器。如果擴容過多,則會存在資源浪費,如果擴容過少,則會影響業務。而且集群擴容過程較復雜,時間也會較長,并且云上容易出現資源庫存不足的問題。
解決方案
Serverless Spark是云原生數據湖團隊基于Apache Spark打造的服務化的大數據分析與計算服務。方案架構圖如下所示: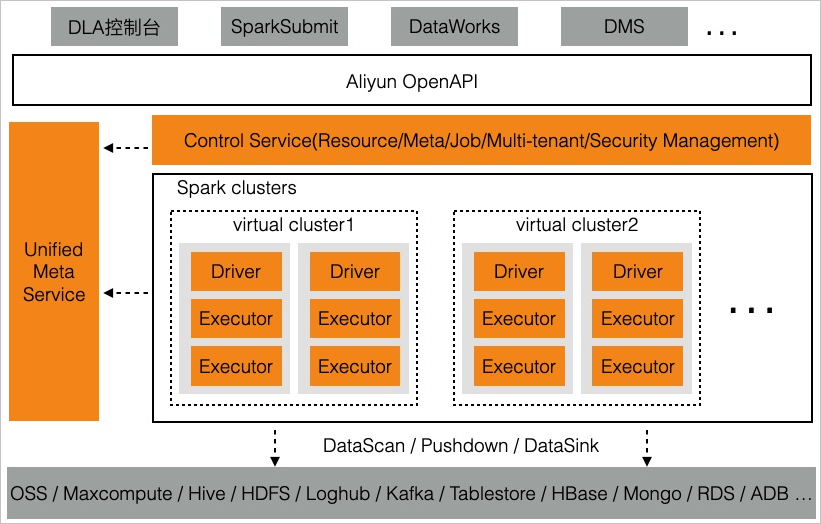
Serverless Spark將Spark、Serverless、云原生技術,深度整合到一起,相對于傳統開源Spark集群版方案,具體以下優勢:
入門門檻低:Serverless Spark屏蔽掉了底層的基礎組件,提供簡單的API、腳本以及控制臺使用方式。開發者只需要了解開源Spark的使用方式就可以進行大數據業務開發。
0運維:用戶只需通過產品接口管理Spark作業即可,無需關心服務器配置以及Hadoop集群配置,無需擴縮容等運維操作。
作業級細粒度的彈性能力:Serverless Spark按照Driver和Executor的粒度創建資源,相比于集群版的計算節點,粒度要細很多,粒度細的好處是庫存不足的問題會大大降低。支持秒級拉起,目前每分鐘可以拉起500~1000個計算節點,可以快速響應業務資源需求。
更低成本:每作業,每賬單,不使用不收費。用戶無需為管控資源付費,無需為低峰期空閑的計算資源付費。
良好的性能:云原生數據湖團隊對Spark引擎做了深度定制和優化,特別是針對云產品,比如OSS,典型場景下,性能可以提升3~5倍。
說明關于進一步的性價比對比數據,您可以參考性價比白皮書中的測試結果。
企業級能力:Serverless Spark跟Serverless Presto共用元數據,可以通過GRANT、REVOKE語句對子用戶進行權限管理。提供服務化的UI服務,相較于社區HistoryServer方式,無論作業多復雜,運行時間多長,都可以秒級打開。
基本概念
虛擬集群(Virtual Cluster)
Serverless Spark采用多租戶模式,Spark進程運行在安全隔離的環境中,虛擬集群是資源隔離和安全隔離的單元。區別于傳統實體集群,虛擬集群中沒有固定的計算資源,您無需配置和維護計算節點,只需根據實際業務需要分配資源額度和配置待訪問目標數據所在的網絡環境。同時,虛擬集群也可以配置默認的Spark作業參數,方便您統一管理Spark作業。關于如何創建虛擬集群,請參考創建虛擬集群。
計算單元CU(Compute Unit)
CU主要是Serverless Spark計量的基本單元,1CU=1 vCPU 4GB Memory。作業結束后,DLA會按照Driver和Executor實際使用的總和CU * 時,進行計量。具體的計費信息,請參考計費概述。
資源規格(Resource Specification)
Serverless Spark底層采用阿里云輕量虛擬機ECI,ECI跟ECS類似,都具備規格,DLA平臺對具體的ECI規格進行了屏蔽、簡化,用戶只需要配置small、medium、large這樣的簡單配置即可,平臺在調度的時候會優先使用高性能計算資源。
資源規格
計算資源
消耗的CU數
c.small
1Core 2GB
0.8CU
small
1Core 4GB
1CU
m.small
1Core 8GB
1.5CU
c.medium
2Core 4GB
1.6CU
medium
2Core 8GB
2CU
m.medium
2Core 16GB
3CU
c.large
4Core 8GB
3.2CU
large
4Core 16GB
4CU
m.large
4Core 32GB
6CU
c.xlarge
8Core 16GB
6.4CU
xlarge
8Core 32GB
8CU
m.xlarge
8Core 64GB
12CU
c.2xlarge
16Core 32GB
12.8CU
2xlarge
16Core 64GB
16CU
m.2xlarge
16Core 128GB
24CU
開始使用Serverless Spark
您可以參考DLA Spark快速入門來提交您的第一個Spark作業。
如果您需要訪問數據源,請參考連接數據源目錄下面的文檔。
如果您對時空計算有需求,請參考數據湖時空引擎Ganos。
如果您想聯系我們做進一步交流,請參考專家服務。