DLA Lakehouse實時入湖方案利用數據湖技術,重構數倉語義;分析數據湖數據,實現數倉的應用。本文以RDS MySQL數據源為例介紹了RDS MySQL從入湖到分析的操作步驟。
背景信息
數據湖分析(Data Lake Analytics)是?前炙?可熱的?向,主要是以對象存儲系統為核心,構建海量、低成本的結構化、半結構化、?結構化對象?件的入湖、存儲和分析業務。?前各?云?商都在積極跟進,布局相關的業務能力,阿?云數據湖分析團隊在這個?向也很早就投?相關產品的研發。隨著數據湖的應?越來越多,?家發現依賴數據湖最原始的能力,僅僅做簡單的存儲和分析,往往會遇到很多的問題。比較典型的痛點如下:
- 多源頭數據需要統?存儲管理,并需要便捷的融合分析。
- 源頭數據元信息不確定或變化大,需要?動識別和管理;簡單的元信息發現功能時效性不夠。
- 全量建倉或直連數據庫進行分析對源庫造成的壓?較大,需要卸載線上壓?規避故障。
- 建倉延遲較?(T+1天),需要T+10m的低延遲入湖。
- 更新頻繁致小文件多,分析性能差,需要Upsert?動合并。
- 海量數據在事務庫或傳統數倉中存儲成本高,需要低成本歸檔。
- 源庫?存儲格式或非分析型格式,分析能力弱,需要?持列式存儲格式。
- ?建?數據平臺運維成本高,需要產品化、云原生、?體化的?案。
- 常見數倉的存儲不開放,需要?建能力、開源可控。
Lakehouse是一種更先進的范式(Paradigm)和方案,用來解決上述簡單入湖分析遇到的各種痛點問題。在Lakehouse技術中,?常關鍵的技術就是多版本的?件管理協議,它提供?湖和分析過程中的增量數據實時寫?、ACID事務和多版本、小?件?動合并優化、元信息校驗和?動進化、?效的列式分析格式、?效的索引優化、超?分區表存儲等能?。?前開源社區有Hudi、Delta、Iceberg等數據湖方案,阿?云數據湖分析團隊選擇了比較成熟的Hudi作為DLA Lakehouse的湖倉?體化格式。關于Lakehouse的更多介紹,請參見Lakehouse介紹。
DLA Lakehouse核心概念和相關約束說明
- Lakehouse(湖倉)有兩重含義:
- 范式:即解決簡單?湖分析所遇到的痛點問題的?種解決?案。
- 存儲空間:?來提供?個從其他地?入湖寫?數據的空間,后續所有相關操作都圍繞著這個湖倉來進行。
- 不同的Lakehouse有完全不同的路徑,路徑之間不可以相互有前綴關系(防止數據覆蓋)。
- Lakehouse不能輕易進行修改。
- Workload(?作負載)是圍繞湖倉?體化而展開的核心工作的編排調度(由DLA Lakehouse統?調度),包括如下功能特點:
- 入湖建倉
- 為了將其他源頭的數據,匯總到整個湖倉內構建?個統?的數據平臺,例如有DB類型的?湖建倉,也有Kafka的入湖建倉,還有OSS的數據轉換建倉。
- 不同的入湖建倉,涉及到全量、增量等多個階段,會統?編排并統?協調調度,簡化?戶管理成本。
- 查詢優化
為了提升分析能力,構建各種查詢優化方面的工作負載,比如自動構建索引、自動清理歷史數據、自動構建物化視圖等。
- 管理
- 成本優化:?動?命周期、冷熱分層存儲等。
- 數據互通:跨域建倉等。
- 數據安全:備份恢復等能力。
- 數據質量:DQC自動校驗等。
- 入湖建倉
- Job作業對于Workload的實際作業拆分和執行,以及調度到不同的計算平臺上執行,對?戶不可見;目前DLA只?持調度作業到DLA Serverless Spark上執行。核心單元概念如下:
- 全量作業(從某個Workload中拆分出來)
- 增量作業(從某個Workload中拆分出來)
- Clustering:小文件聚合
- Indexing:自動索引構建
- Compaction:自動日志合并
- Tier:自動分層存儲
- Lifecycle:自動生命周期管理
- MaterializedView:物化視圖
- DB(庫):DLA的庫
- Table(表):DLA的表
- Partition(分區):DLA的分區
- Column(列):DLA的列
DLA Lakehouse方案介紹
DLA Lakehouse實時入湖是分鐘級近實時的數據入湖方案,它能夠構建統一、低成本、海量數據、自動元信息同步的湖倉平臺,并支持高性能的DLA Spark計算和DLA
Presto分析。DLA Lakehouse實時入湖方案的存儲與計算完全分離,寫、存、讀完全彈性,它的方案架構如下圖所示: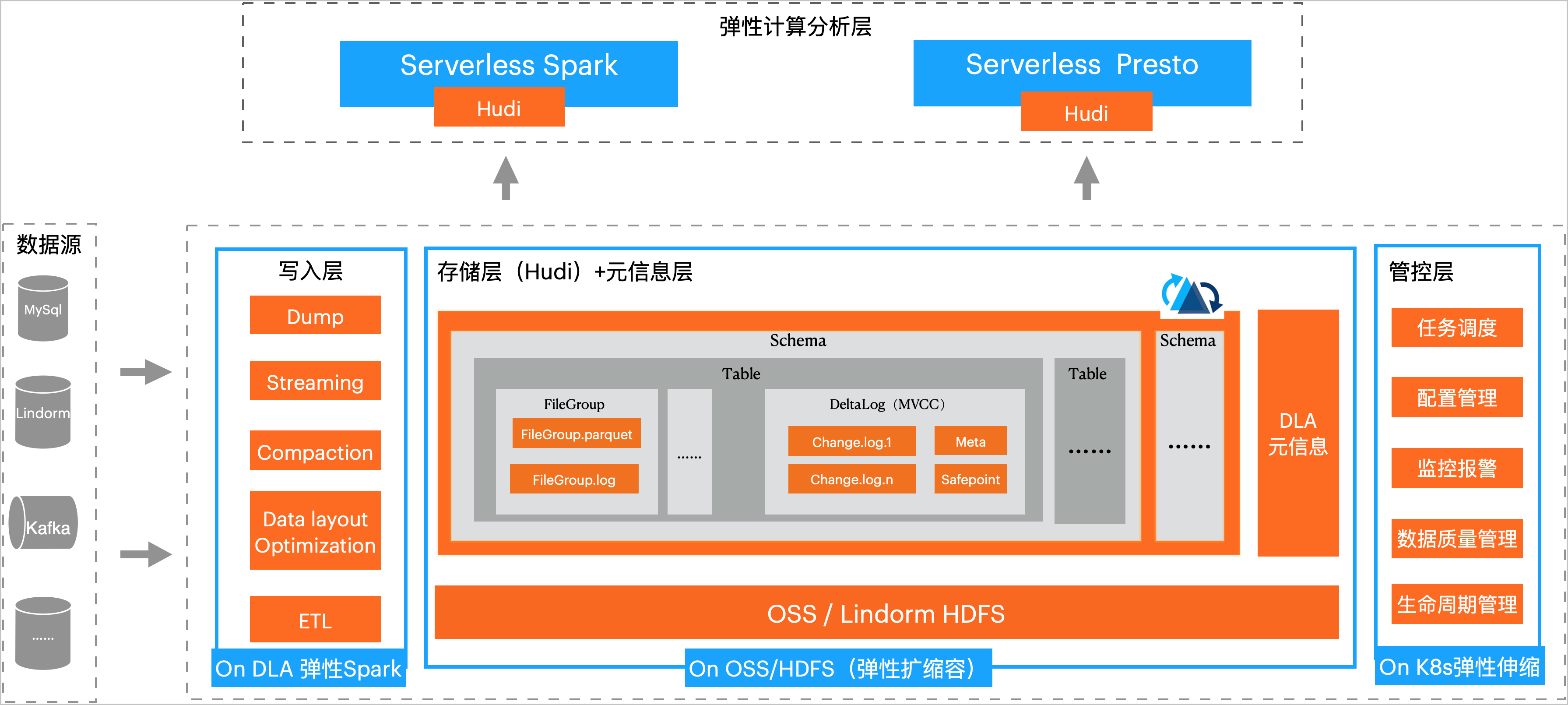
準備工作
您需要在DLA中進行以下操作:
- 開通云原生數據湖分析服務說明 如果未注冊阿里云賬號,請先注冊賬號。
- 創建虛擬集群說明 DLA基于Spark引擎來運行DLA Lakehouse,因此創建虛擬集群的時候需要選擇Spark引擎。
您需要在RDS中進行以下操作:
- 創建RDS MySQL實例說明 由于DLA Lakehouse只支持專有網絡,故創建RDS MySQL實例時,網絡類型請選擇專有網絡。
- 創建數據庫和賬號
- 通過DMS登錄RDS數據庫
- 在SQLConsole窗口中執行SQL語句創建庫表并插入數據。
您需要在DTS中進行以下操作:
說明 目前DLA中RDS數據源的入湖分析工作負載,會先利用RDS做數據的全量同步,然后依賴DTS數據訂閱功能做增量同步,最終實現完整的RDS數據入湖。
- 創建RDS MySQL數據訂閱通道說明
- 由于DLA Lakehouse只支持專有網絡,故訂閱任務的網絡類型請選擇專有網絡。
- 由于DLA Lakehouse無法自動更新元數據信息,故需要訂閱的數據類型請選擇數據更新和結構更新。
- 新增消費組
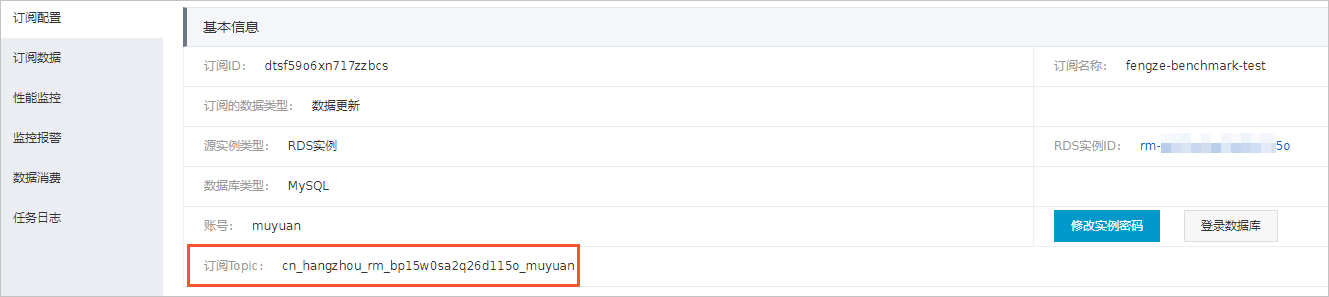
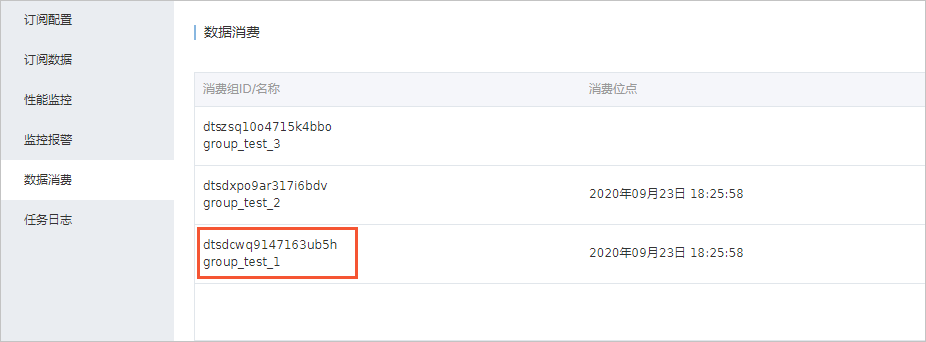
- 查看訂閱Topic和消費者ID。后續的創建RDS入湖負載的增量同步配置中需要使用這2個參數。
- 在訂閱任務的訂閱配置中可以查看訂閱Topic。
- 在訂閱任務的數據消費中可以查看消費者ID。
- 在訂閱任務的訂閱配置中可以查看訂閱Topic。
確保您的數據流在RDS中部署的區域與DTS、DLA、OSS的區域相同。
操作步驟
- 創建湖倉。
- 在新建湖倉頁面進行參數配置。參數說明如下表所示:
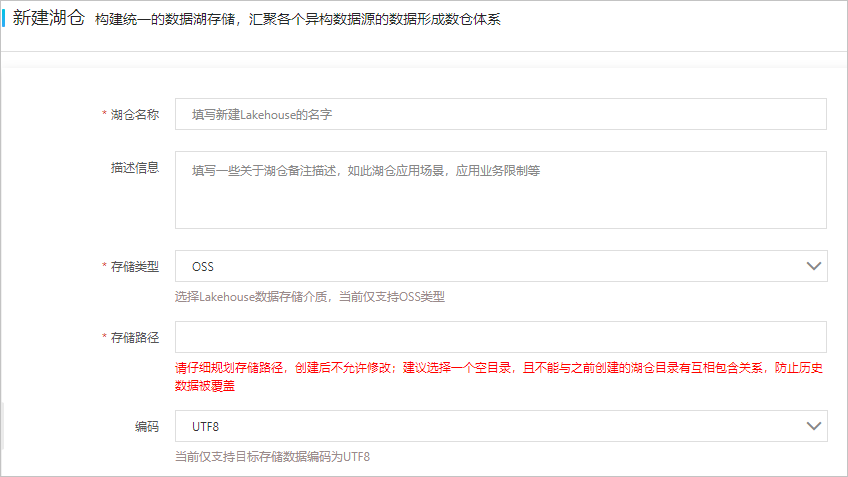
參數名稱 參數說明 湖倉名稱 DLA Lakehouse的名稱。 描述信息 湖倉備注描述,例如湖倉應用場景、應用業務限制等。 存儲類型 DLA Lakehouse數據的存儲介質,當前僅?持OSS類型。 存儲路徑 DLA Lakehouse數據在OSS中的存儲路徑。 說明 請謹慎規劃存儲路徑,創建后不允許修改。建議選擇一個空目錄,且不能與之前創建的湖倉目錄有互相包含關系,防止歷史數據被覆蓋。編碼 存儲數據的編碼類型,當前僅?持?標存儲數據編碼為UTF8。
湖倉創建成功后,湖倉列表頁簽中將展示創建成功的湖倉任務。
- 在新建湖倉頁面進行參數配置。參數說明如下表所示:
- 創建入湖負載。
- 在新建工作負載頁面,進行數據源的基礎配置、全量同步配置、增量同步配置、生成目標數據規則配置。說明 當前僅支持RDS數據源和PolarDB數據源。
- 基礎配置的參數說明如下:
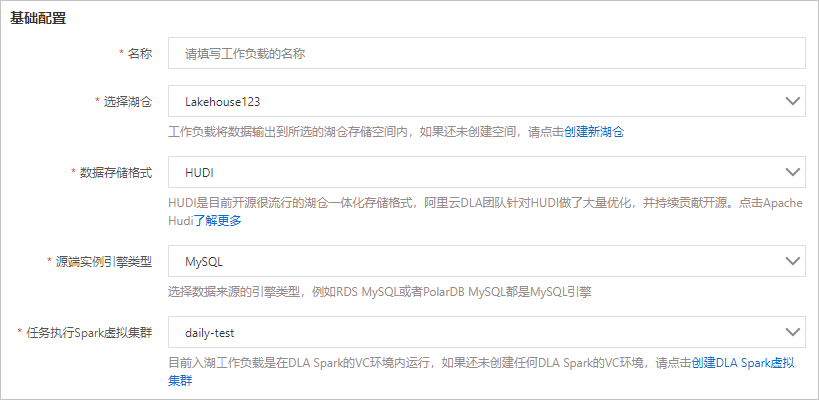
參數名稱 參數說明 名稱 工作負載的名稱。 選擇湖倉 工作負載將數據輸出到所選的湖倉存儲空間內。可下拉選擇已經創建的湖倉。 數據存儲格式 數據的存儲格式固定為HUDI。 源端實例引擎類型 數據源的引擎類型。當前僅支持MySQL引擎。 任務執行Spark虛擬集群 執行Spark作業的虛擬集群。目前入湖?作負載在DLA Spark的虛擬集群中運行。如果您還未創建虛擬集群,請進行創建,具體請參見創建虛擬集群。 說明 請確保您選擇的Spark虛擬集群處于正常運行狀態,如果您選擇的Spark虛擬集群處于非正常運行狀態,啟動工作負載時將失敗。 - 全量同步配置的參數說明如下:
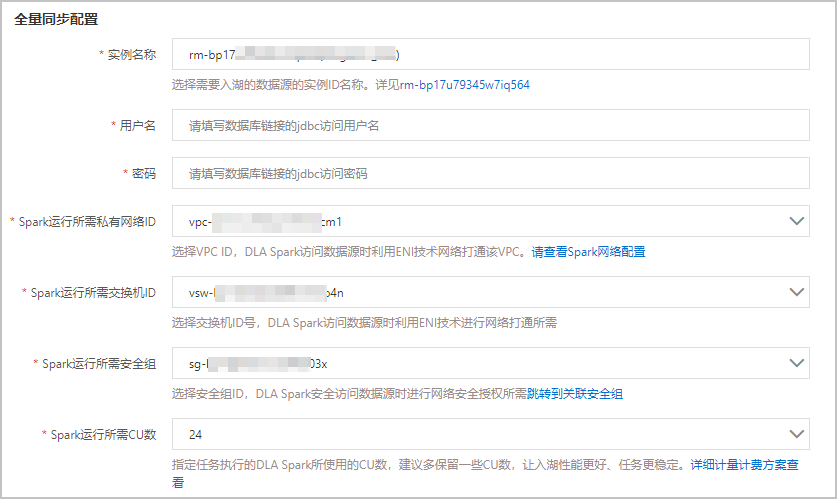
參數名稱 參數說明 實例名稱 選擇需要入湖的數據源的實例ID名稱。 用戶名 需要入湖的數據源實例的訪問用戶名。 密碼 需要入湖的數據源實例的訪問密碼。 Spark運行所需私有網絡ID DLA Spark利用ENI技術配置該VPC網絡來訪問數據源。關于DLA Spark如何配置數據源VPC網絡,請參見配置數據源網絡。 Spark運行所需交換機ID DLA Spark運行所需VPC網絡下的交換機ID。 Spark運行所需安全組 DLA Spark訪問數據源時進行網絡安全授權的安全組ID。您可以到RDS數據源實例的數據安全性頁面中獲取安全組ID,如未設置安全組請進行添加,具體操作請參見設置安全組。 Spark運行所需CU數 指定執行DLA Spark作業所使用的CU數,建議多保留一些CU數,讓入湖性能更好、作業任務更穩定。 - 增量同步配置的參數說明如下:

參數名稱 參數說明 同步方式 增量同步的通道類型。當前僅?持DTS?式。 訂閱配置 增量同步所使用的DTS訂閱通道配置,分別選擇訂閱Topic和消費組ID。 DTS用戶名 增量同步DTS數據訂閱消費組的賬號信息。 DTS密碼 增量同步DTS數據訂閱消費組賬號對應的密碼信息。 Spark運行所需私有網絡ID DLA Spark利用ENI技術配置該VPC網絡來訪問數據源。關于DLA Spark如何配置數據源VPC網絡,請參見配置數據源網絡。 Spark運行所需交換機ID DLA Spark運行所需VPC網絡下的交換機ID。 Spark運行所需安全組 DLA Spark訪問數據源時進行網絡安全授權的安全組ID。您可以到RDS數據源實例的數據安全性頁面中獲取安全組ID,如未設置安全組請進行添加,具體操作請參見設置安全組。 Spark運行所需CU數 指定執行DLA Spark作業所使用的CU數,建議多保留一些CU數,讓入湖性能更好、作業任務更穩定。 高級規則配置 - 消費位點:數據消費的時間點。當前取值固定為earliest,表示自動從最開始的時間點獲取數據。
- 每批次消費記錄條數:表示每次通過DTS拉取的數據量。
- 生成目標數據規則配置的參數說明如下:
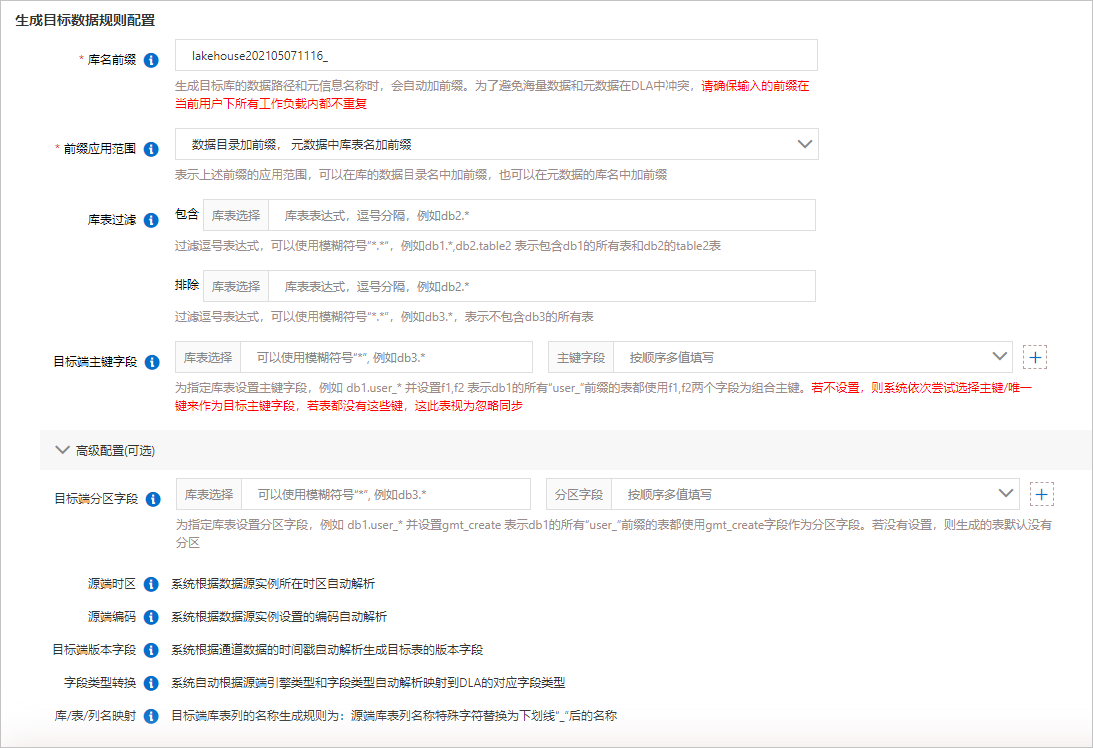
參數名稱 參數說明 庫名前綴 生成目標庫的數據路徑和元信息名稱時,會自動添加該前綴。為了避免海量數據和元數據在DLA中沖突,請確保輸入的前綴在當前阿里云賬號下的所有工作負載內都不重復。 前綴應用范圍 設置庫名前綴的應用范圍。包括: - 數據目錄加前綴,元數據中庫表名加前綴
- 數據目錄不加前綴,元數據中庫表名加前綴
庫表過濾 設置需要同步的庫和表范圍。排除的優先級高于包含。 目標端主鍵字段 為指定庫表設置主鍵字段。例如:庫表選擇輸入 db1.user_*,主鍵字段輸入f1,f2,表示db1的所有user_前綴的表都使?f1,f2兩個字段作為組合主鍵。說明 如果不設置該參數,則系統依次嘗試選擇表中的主鍵或唯一鍵來作為目標端主鍵字段;如果表中不存在主鍵或唯一鍵,則視為忽略同步。高級配置 目標端分區字段:為指定庫表設置分區字段。例如:庫表選擇輸入
db1.user_*,分區字段輸入gmt_create,表示db1的所有user_前綴的表都使?gmt_create字段作為分區字段。如果不設置該參數,則生成的表默認沒有分區。
- 基礎配置的參數說明如下:
入湖負載創建成功后,在工作負載列表頁簽中將展示創建成功的工作負載。
- 在新建工作負載頁面,進行數據源的基礎配置、全量同步配置、增量同步配置、生成目標數據規則配置。
- 啟動工作負載。在工作負載列表頁簽中,定位到創建成功的入湖負載,在操作列單擊啟動。
 工作負載任務啟動成功后,狀態將由NO STATUS(未啟動)變為RUNNING(運行中)。
工作負載任務啟動成功后,狀態將由NO STATUS(未啟動)變為RUNNING(運行中)。 您還可以在操作列停止和校正工作負載任務、查看Spark日志。具體說明如下:
您還可以在操作列停止和校正工作負載任務、查看Spark日志。具體說明如下:操作按鈕 含義 詳情 單擊該按鈕,可以查看Spark日志或者UI,并定位工作負載任務啟動失敗原因。 停止 單擊該按鈕,可以停止工作負載任務。 校正 單擊該按鈕,可以對啟動失敗的工作負載任務進行數據校正。 說明 校正一般使用在庫表變更、字段格式不一致等場景下。校正過程會重新進行部分存量數據的全量同步,請慎重填寫庫表篩選表達式,建議使用精確匹配表達式篩選,避免校正一些不必要的數據。如果未填寫需要校正的庫表,則校正失敗。工作負載任務啟動成功后,在湖倉列表頁簽單擊存儲路徑下的OSS路徑鏈接,可以跳轉到OSS控制臺查看已經從RDS數據源同步過來的庫表路徑以及表文件。- 數據庫路徑
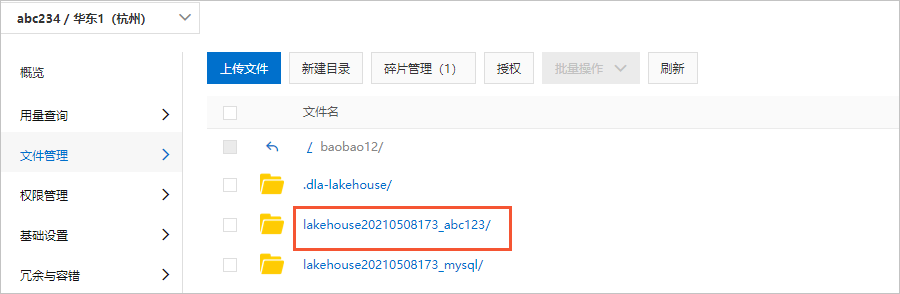
- 數據表路徑
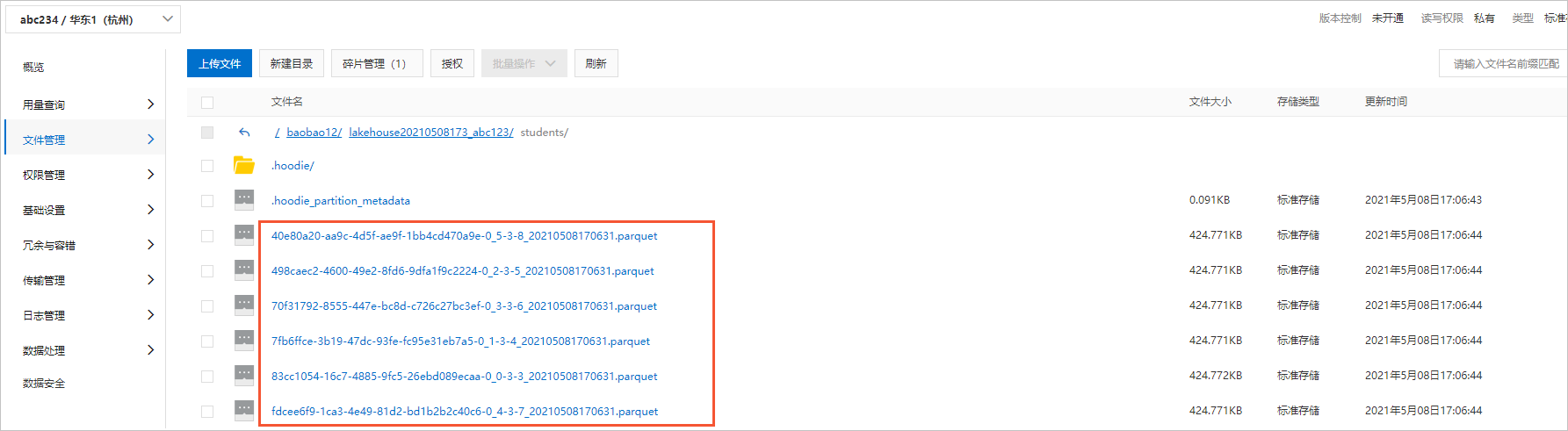
- 數據表文件
- 數據庫路徑
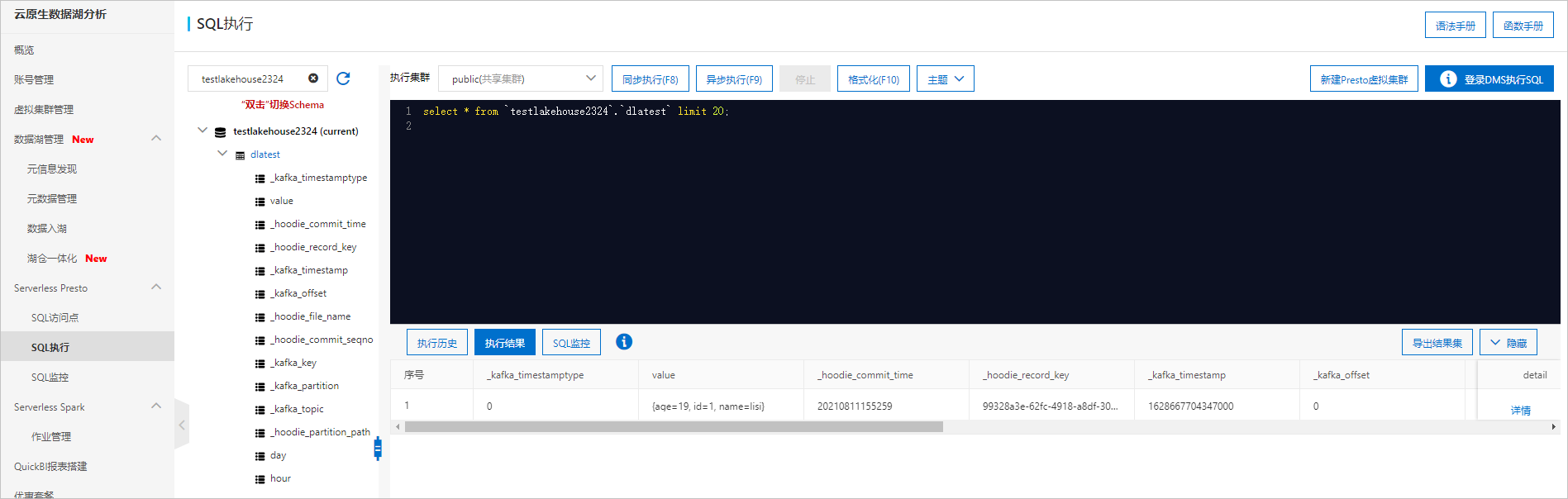
- 進行數據分析。工作負載任務啟動成功后,在頁面中,查看從RDS數據源同步過來的元數據信息。
 單擊操作列的查詢數據,在頁面,查看從RDS數據源同步過來的全量表數據。
單擊操作列的查詢數據,在頁面,查看從RDS數據源同步過來的全量表數據。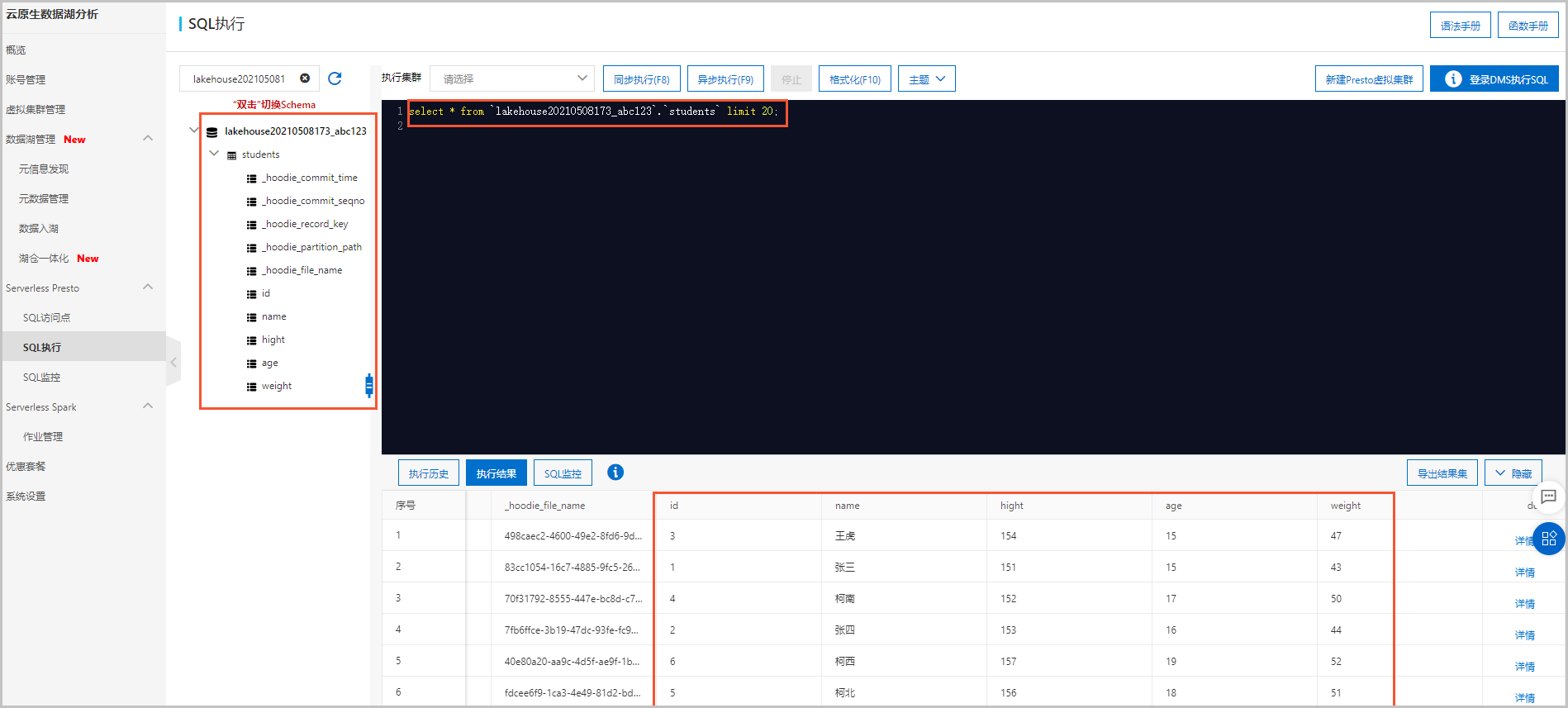 如果您在數據源RDS中變更了原始數據,在頁面進行查詢時,數據會同步進行更新。
如果您在數據源RDS中變更了原始數據,在頁面進行查詢時,數據會同步進行更新。