本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
本文介紹如何使用TPC-DS進行測試DDI引擎性能,給出推薦的實踐步驟。
前提條件
通過主賬號登錄阿里云 Databricks控制臺,當前 TPC-DS 測試流程已在 Databricks Runtime 9.1 以上版本做驗證,請選擇DBR9及以上版本產品。
為保證測試效果,推薦最小測試數據量應為1T,故需創建特定規模的集群,創建步驟請參見創建集群,推薦集群規模如下:
ECS實例類型
vCore
vMem
系統盤/數據盤
實例個數
Master
16 cores
64GB
200GB/500GB
1
Worker
32 cores
128GB
200GB/500GB
6
元數據選擇類型建議使用數據湖元數據,該方式采用阿里云數據湖構建(Data Lake Formation)作為統一元數據存儲,采用服務化高可用的元數據,實現了多引擎統一元數據存儲。
已使用OSS管理控制臺創建非系統目錄存儲空間,詳情請參見創建存儲空間。
警告首次使用DDI產品創建的Bucket為系統目錄Bucket,不建議存放數據,您需要再創建一個Bucket來讀寫數據。
說明DDI支持免密訪問OSS路徑,結構為:oss://BucketName/Object
BucketName為您的存儲空間名稱;
Object為上傳到OSS上的文件的訪問路徑。
例:讀取在存儲空間名稱為databricks-demo-hangzhou文件路徑為demo/The_Sorrows_of_Young_Werther.txt的文件
// 從oss地址讀取文本文檔 val text = sc.textFile("oss://databricks-demo-hangzhou/demo/The_Sorrows_of_Young_Werther.txt")
TPC-DS項目簡介
本項目基于社區的TPC-DS項目,該項目包含生成測試集數據、運行實例SQL、輸出各階段執行時間指標等功能,以此檢驗引擎的性能。本文的TPC-DS實現將生成數據、運行測試以及迭代循環等功能整合,統一使用一套參數,用戶可以專注于測試數據與DDI引擎性能本身,屏蔽底層較繁瑣的細節。
參數列表
可執行參數 | 參數定義 | 推薦值 |
--scaleFactor | Int型參數,測試集數據規模,單位為GB | 推薦最小數據量為1T,參數為1000 |
--location | String類型參數,數據集與運算結果產生的OSS目錄 | 避免系統目錄bucket |
--format | String類型參數,Spark數據的存儲類型 | 數據湖元數據,參數為delta |
--overwrite | Boolean型參數,是否覆蓋生成數據集 | 推薦為true,也可根據步驟判斷 |
--numPartitions | Int型參數,dsdgen生成數據的分區數,即輸入任務數 | 根據數據量決定,1T數據推薦為100 |
--numberOfIteration | Int型參數,測試集運算執行次數 | 單獨生成數據集時,參數為0 運行測試數據集時,參數為大于0 |
--generateData | Boolean型參數,是否生成數據集 | 單獨生成數據集時,參數為true 運行測試數據集時,參數為false |
其余參數較為固定,可參考以下推薦用例。
TPC-DS項目最佳實踐
步驟一 :TPC-DS工程下載
示例工程下載:(請聯系Databricks運維)
在OSS已創建的bucket中創建一個目錄,存放上述下載的jar包。
步驟二 :創建TPC-DS測試項目
本文的TPC-DS的實現基于TPC-DS的基準測試,并不能與已發布的TPC-DS基準測試結果相比較,本文中的測試并不符合TPC-DS的基準測試的所有要求。
在Databricks數據洞察的項目空間中創建一個新項目,操作如下:
步驟三 :生成測試數據集腳本
spark資源可以根據測試數據量與集群規模配置的具體情況,進行逐一調整。
scale_factor參數控制整個測試集的數據量(如scale_factor=1000 即1T的數據量)。
以下的OSS路徑要替換為用戶自己設置的路徑,分別用于讀取jar包和存放生成的測試數據集與性能測試結果。
執行腳本如下:
--class com.databricks.spark.sql.perf.tpcds.GenTPCDSData
--deploy-mode cluster
--name generate_dataset
--queue default
--master yarn
--conf spark.yarn.submit.waitAppCompletion=true
--conf spark.driver.cores=4
--conf spark.driver.memory=12G
--conf spark.executor.cores=7
--conf spark.executor.memory=20G
--conf spark.executor.instances=30
--conf spark.executor.memoryOverhead=2048
--conf spark.default.parallelism=600
--conf spark.shuffle.service.enabled=true
--conf spark.sql.autoBroadcastJoinThreshold=-1
oss://tpc-ds-test/tpcds-jar/spark-sql-perf-assembly-0.5.1-SNAPSHOT.jar
--scaleFactor 1000
--location oss://tpc-ds-test
--format delta
--overwrite true
--numPartitions 100
--numberOfIteration 0
--generateData true生成的數據集會存儲在location參數所指定路徑的data目錄下(如上面的例子,數據集在:oss://tpc-ds-test/data)
步驟四:運行TPC-DS測試集
運行測試集的方法和生成數據的操作一致,僅需要修改下面兩個參數:
numberOfIteration:更改為1,代表測試集將被運行1次,產生1次迭代結果,也可自行選擇迭代執行次數。
generateData:更改為false,代表只執行測試集運算,不進行重復測試集數據生成。
執行腳本如下:
--class com.databricks.spark.sql.perf.tpcds.GenTPCDSData
--deploy-mode cluster
--name run_dataset
--queue default
--master yarn
--conf spark.yarn.submit.waitAppCompletion=true
--conf spark.driver.cores=4
--conf spark.driver.memory=12G
--conf spark.executor.cores=7
--conf spark.executor.memory=20G
--conf spark.executor.instances=30
--conf spark.executor.memoryOverhead=2048
--conf spark.default.parallelism=600
--conf spark.shuffle.service.enabled=true
--conf spark.sql.autoBroadcastJoinThreshold=-1
oss://tpc-ds-test/tpcds-jar/spark-sql-perf-assembly-0.5.1-SNAPSHOT.jar
--scaleFactor 1000
--location oss://tpc-ds-test
--format delta
--overwrite true
--numPartitions 100
--numberOfIteration 1
--generateData false運行完成后結果會存儲在location參數所指定路徑的result目錄下(如上面的例子,結果在:oss://tpc-ds-test/result)
步驟五:結果分析
最終在oss://tpc-ds-test/result/timestamp=${TimeStamp}的目錄下,產生一個JSON類型的結果文件,實例如下圖(數值僅供參考):
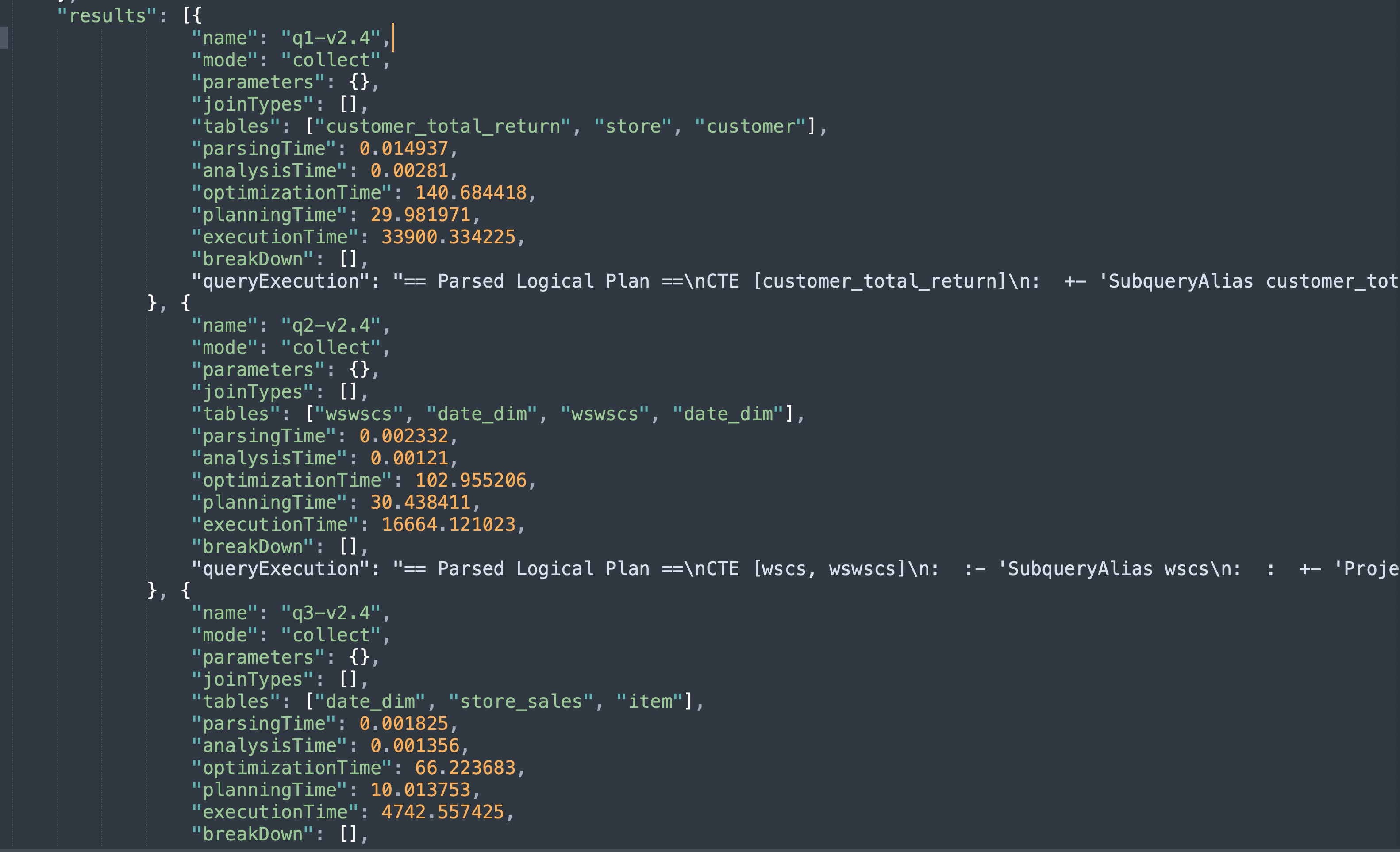
可以看到針對每個SQL測試都會產生相應的指標結果項(毫秒單位),可以著重關注于executionTime,該指標區分度較大,主要體現DDI引擎性能上的優勢。