本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
Delta Lake支持Apache Spark DataFrame讀寫API提供的大多數選項,用于對表執行批量讀寫。
詳細內容可參考Databricks官網文章:表批讀寫
有關演示這些功能的Databricks筆記本,請參閱入門筆記本二。
有關Delta Lake SQL命令的信息,請參見
Databricks Runtime 7.0及更高版本:Databricks Runtime 7.x SQL參考
Databricks Runtime 6.x及以下版本:Databricks Runtime 5.5 LTS和6.x SQL參考
建立表格
Delta Lake支持使用DataFrameWriter(Scala/Java / Python)直接基于路徑創建表。Delta Lake還支持使用標準DDL CREATE TABLE在元存儲中創建表。 使用Delta Lake在元存儲中創建表時,它將表數據的位置存儲在元存儲中。此方式使其他用戶更容易發現和引用數據,而無需擔心數據存儲的準確位置。但是,元存儲不是表中有效內容的真實來源。數據內容仍然由Delta Lake負責存儲。
SQL
%sql
-- Create table in the metastore
CREATE TABLE events (
date DATE,
eventId STRING,
eventType STRING,
data STRING)
USING DELTA
Python
%pyspark
df = spark.createDataFrame([("case21", '2020-10-12', 21, 'INFO'),("case22", '2020-10-13', 22, 'INFO')], ['data', 'date', 'eventId', 'eventType'])
df.write.format("delta").saveAsTable("events2") # create table in the metastore
df.write.format("delta").save("/mnt/delta/events3") # create table by path
Scala
%spark
val df = spark.createDataFrame(Seq(("case21", "2020-10-12", 21, "INFO"))).toDF("data", "date", "eventId", "eventType")
df.write.format("delta").saveAsTable("events4") // create table in the metastore
df.write.format("delta").save("/mnt/delta/events5") // create table by path
在Databricks Runtime 7.0及更高版本中,您可以使用DataFrameWriterV2接口創建Delta表。SQL還支持在路徑中創建表,而無需在Hive元存儲中創建條目。
SQL
%sql
-- Create a table by path
CREATE OR REPLACE TABLE delta.`/mnt/delta/events` (
date DATE,
eventId STRING,
eventType STRING,
data STRING)
USING DELTA
PARTITIONED BY (date);
-- Create a table in the metastore
CREATE OR REPLACE TABLE events (
date DATE,
eventId STRING,
eventType STRING,
data STRING)
USING DELTA
PARTITIONED BY (date);SCALA
%spark
val df = spark.createDataFrame(Seq(("case21", "2020-10-12", 21, "INFO"))).toDF("data", "date", "eventId", "eventType")
df.writeTo("delta.`/mnt/delta/events`").using("delta").partitionedBy("date").createOrReplace() // create table by path
df.writeTo("events").using("delta").partitionedBy("date").createOrReplace() // create table in the metastore分區數據
您可以對數據進行分區以加快其謂詞及分區列的查詢和DML。要在創建Delta表時對數據進行分區,請按列指定分區。常見的模式是按日期劃分,例如:
SQL
%sql
-- Create table in the metastore
CREATE TABLE events (
date DATE,
eventId STRING,
eventType STRING,
data STRING)
USING DELTA
PARTITIONED BY (date)
LOCATION '/mnt/delta/events'
Python
%pyspark
df = spark.createDataFrame([("case21", '2020-10-12', 21, 'INFO'),("case22", '2020-10-13', 22, 'INFO')], ['data', 'date', 'eventId', 'eventType'])
df.write.format("delta").partitionBy("date").saveAsTable("events1") # create table in the metastore
df.write.format("delta").partitionBy("date").save("/mnt/delta/events2") # create table by path
Scala
%spark
val df = spark.createDataFrame(Seq(("case21", "2020-10-12", 21, "INFO"))).toDF("data", "date", "eventId", "eventType")
df.write.format("delta").partitionBy("date").saveAsTable("events3") // create table in the metastore
df.write.format("delta").partitionBy("date").save("/mnt/delta/events4") // create table by path
控制數據位置
要控制Delta表文件的位置,可以選擇將LOCATION指定為OSS上的路徑。與不指定路徑的內部表不同,當您使用DROP表時,不會刪除外部表的文件
如果運行CREATE TABLE的位置已經包含使用Delta Lake存儲的數據,Delta Lake將執行以下操作:
如果只指定表名和位置,例如:
SQL
%sql
CREATE TABLE events
USING DELTA
LOCATION '/mnt/delta/events'Hive Metastore中的表會自動繼承現有數據的Schema,分區和表屬性。此功能可用于將數據“導入”到元存儲中。
如果指定任何配置(Schema,分區或表屬性),則Delta Lake會驗證該規范與現有數據的配置是否完全匹。
如果指定的配置與數據的配置不完全匹配,則Delta Lake會拋出描述差異的異常。
讀取表
您可以通過指定表名或路徑將Delta表加載到DataFrame中:
SQL
%sql
SELECT * FROM events -- query table in the metastore
SELECT * FROM delta.`/mnt/delta/events` -- query table by pathPython
%pyspark
spark.table("events") # query table in the metastore
spark.read.format("delta").load("/mnt/delta/events") # query table by pathScala
%spark
spark.table("events") // query table in the metastore
spark.read.format("delta").load("/mnt/delta/events") // create table by path返回的DataFrame會自動讀取表中之前查詢結果的最新快照;您不需要運行REFRESH TABLE。當查詢中有適用的謂詞時,Delta-Lake會自動使用分區和統計來讀取最小數量的數據。
查詢表的舊快照(按時間順序查看)
Delta Lake按時間順序查看允許您查詢Delta表的舊快照。按時間順序查看有很多用例,包括:
重新創建分析,報告或輸出(例如,機器學習模型的輸出)。這對于排查問題或者審計尤其有用,特別是在管控行業中。
編寫復雜的時間查詢。
修正數據中的錯誤。
在快速變更的表中,提供一系列的快照查詢功能。
本節介紹了舊版本表和數據保存相關的查詢方法,并提供了示例。
語法
本節說明如何查詢較舊版sql本的Delta表。
SQL AS OF 語法
%sql
SELECT * FROM
events
TIMESTAMP AS OF timestamp_expression
SELECT * FROM events VERSION AS OF versiontimestamp_expression為實際的時間,你可以通過DESCRIBE HISTORY events查看表的歷史版本
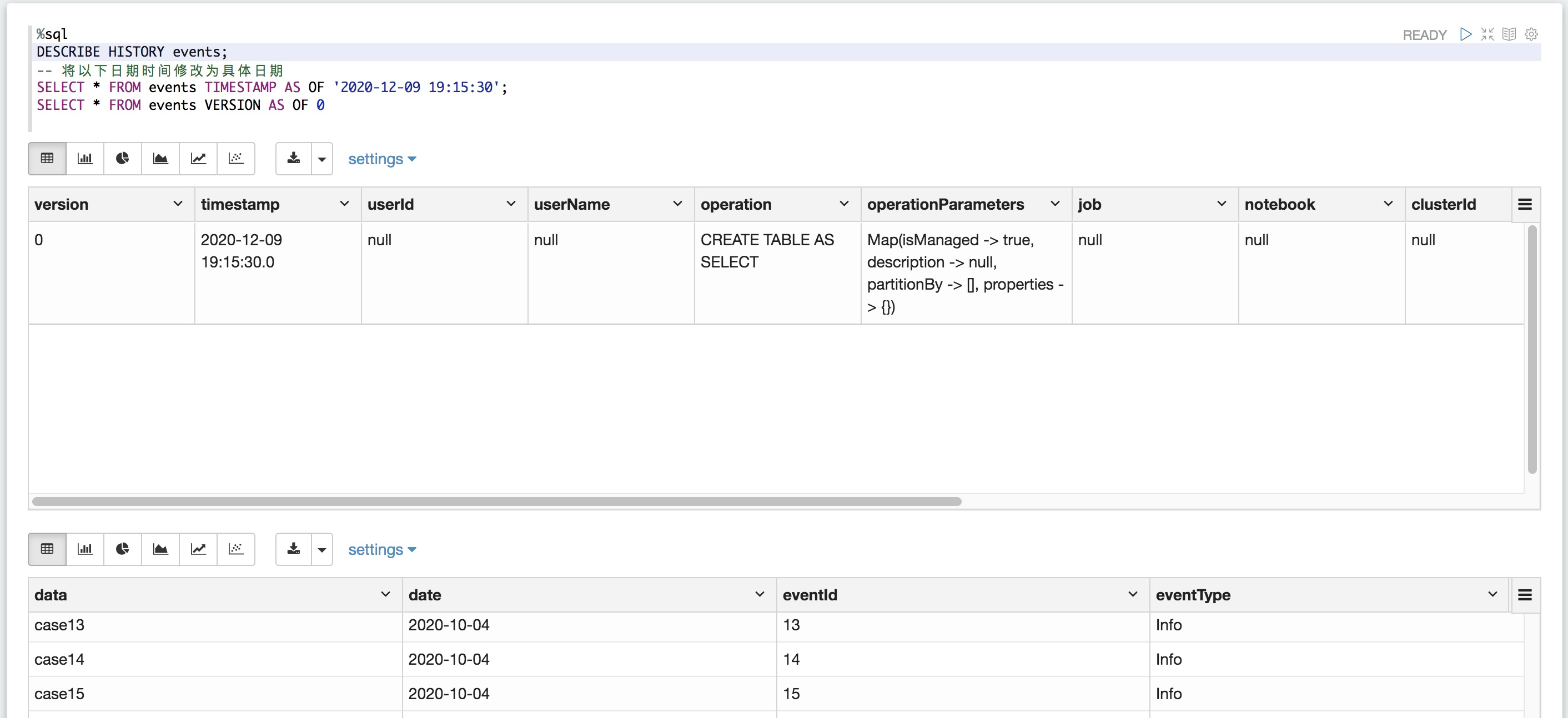
table_identifier
[database_name.] table_name:一個表名,可以選擇用數據庫名限定。
delta.`<path-to-table>` :現有Delta表的位置。
時間戳表達式可以是以下任一項
'2018-10-18T22:15:12.013z',即可以轉換為時間戳的字符串
cast('2018-10-18 13:36:32 CEST' as timestamp)
'2018-10-18',即日期字符串
在Databricks運行時6.6及更高版本中:
current_timestamp() - interval 12 hours
date_sub(current_date(), 1)
任意可以轉換為時間戳的其它表達式
version是一個長整型數值,可以從DESCRIBE HISTORY table_spec查詢中獲取到。
時間戳表達式和版本都不能是子查詢。
SQL
%sql
SELECT * FROM events TIMESTAMP AS OF '2018-10-18T22:15:12.013Z'
SELECT * FROM delta.`/mnt/delta/events` VERSION AS OF 123DataFrameReader選項
您可以使用DataFrameReader從特定版本的Delta表中創建DataFrame
Python
%pyspark
df1 = spark.read.format("delta").option("timestampAsOf", timestamp_string).load("/mnt/delta/events")
df2 = spark.read.format("delta").option("versionAsOf", version).load("/mnt/delta/events")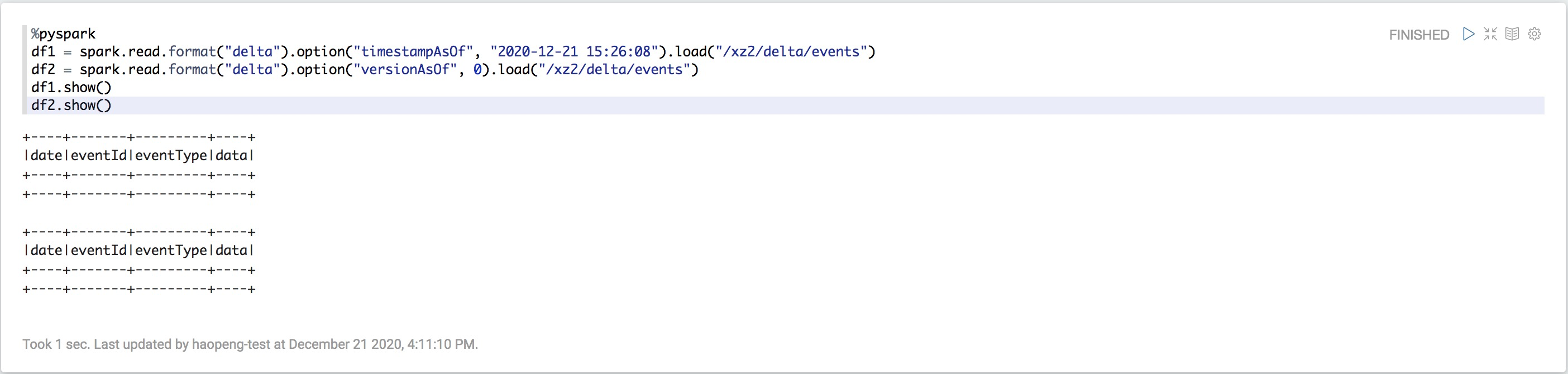
對于timestamp_string,僅接受日期或時間戳記字符串。例如"2019-01-01"和"2019-01-01T00:00:00.000Z"。
一種常見的模式是在執行Databricks作業期間使用Delta表的最新狀態來更新下游應用程序。
由于 Delta 表會自動更新,因此,如果基礎數據進行了更新,則在多次調用時,從 Delta 表加載的DataFrame可能返回不同的結果。通過使用按時間順序查看,您可以修復多次調用的DataFrame返回的數據:
Python
%pyspark
latest_version = spark.sql("SELECT max(version) FROM (DESCRIBE HISTORY delta.`/mnt/delta/events`)").collect()
df = spark.read.format("delta").option("versionAsOf", latest_version[0][0]).load("/mnt/delta/events")
語法
您可能有一個參數化的管道,其中管道的輸入路徑是作業的參數。在執行作業之后,您可能希望在將來某個時間重新生成輸出。在這種情況下,可以使用@語法指定時間戳或版本。時間戳必須為yyyymmddhhmmssss格式。您可以在@之后指定一個版本,方法是在版本前面加一個v。例如,要查詢表evnets件的版本123,請指定evnets@v123。
SQL
%sql
SELECT * FROM events@20190101000000000;
SELECT * FROM events@v123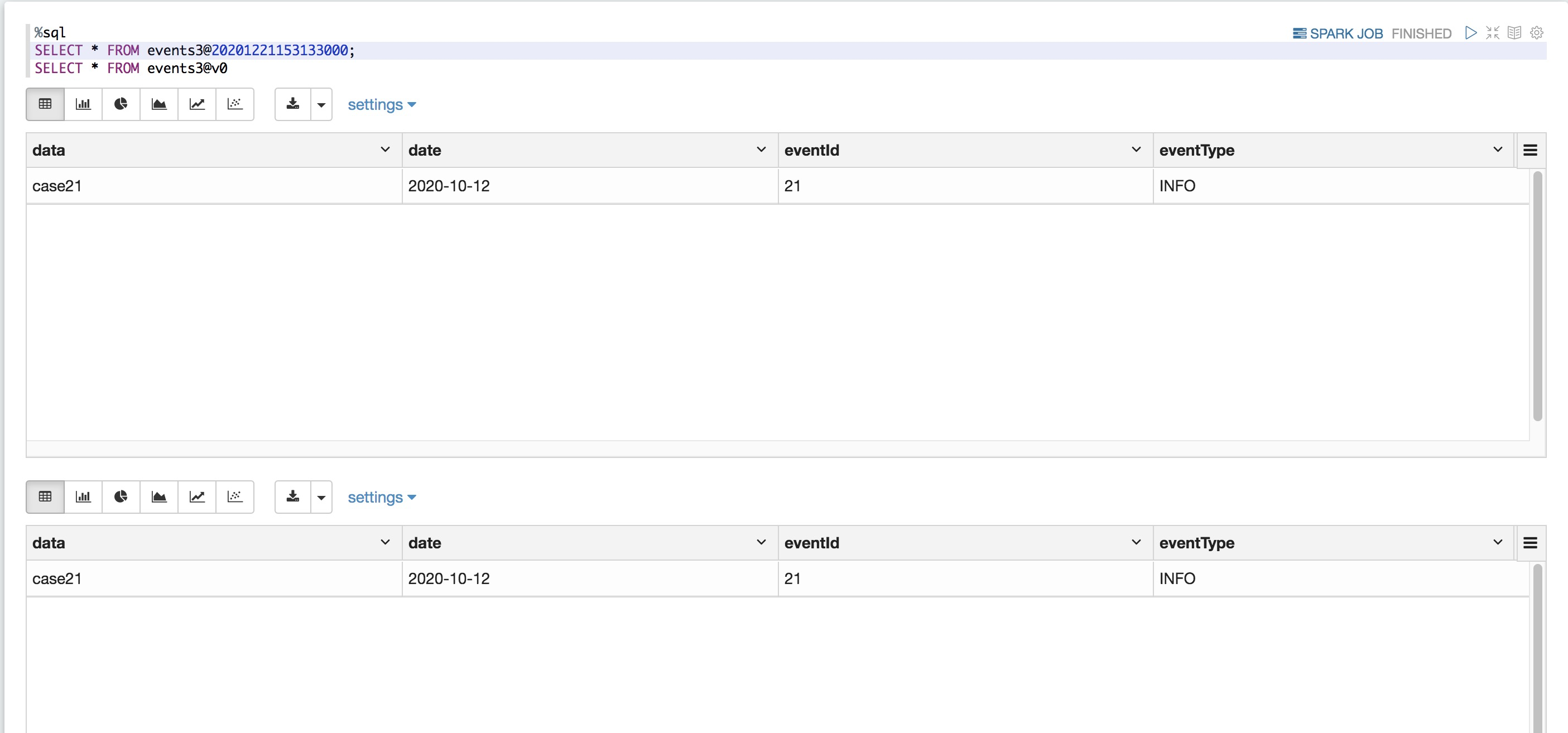
Python
%pyspark
spark.read.format("delta").load("/mnt/delta/events@20190101000000000") # table on 2019-01-01 00:00:00.000
spark.read.format("delta").load("/mnt/delta/events@v123") # table on version 123數據保存
默認情況下,Delta表將提交歷史記錄保留30天。這意味著您可以聲明一個30天以內的版本。但是,有以下注意事項:
您沒有在Delta表上運行VACUUM。如果運行VACUUM,您將無法恢復到默認的7天數據保留期之前的版本。
您可以使用以下表屬性來配置保留期:
delta.logRetentionDuration = "interval <interval>":控制表的歷史記錄保留時間長度。每次寫入一個檢查點時,Databricks都會自動清除早于保留間隔的日志條目。如果將此配置設置為足夠大的值,則會保留許多日志條目。這不會影響性能,因為針對日志的操作恒定時間。歷史記錄的操作是并行的(但是隨著日志大小的增加,它將變得更加昂貴)。默認值為interval 30 days
delta.deletedFileRetentionDuration = "interval <interval>":控制選擇的文件必須選擇時間段,默認值為間隔7天。若要訪問 30 天的歷史數據,請設置 delta.deletedFileRetentionDuration = "interval 30 days"。此設置可能會導致您的存儲成本上升。
重要VACUUM 不清理日志文件;寫入檢查點后,日志文件將自動清除。
按時間順序查看到以前的版本,必須保留日志文件和該版本的數據文件。
案例
修復用戶111表的意外刪除問題:
SQL
%sql INSERT INTO my_table SELECT * FROM my_table TIMESTAMP AS OF date_sub(current_date(), 1) WHERE userId = 111修復對表的意外錯誤更新:
SQL
%sql MERGE INTO my_table target USING my_table TIMESTAMP AS OF date_sub(current_date(), 1) source ON source.userId = target.userId WHEN MATCHED THEN UPDATE SET *查詢過去一周增加的新客戶數量。
SQL
%sql SELECT count(distinct userId) - ( SELECT count(distinct userId) FROM my_table TIMESTAMP AS OF date_sub(current_date(), 7))
寫入表格
追加
使用append模式,可以將新數據以原子的方式添加到現有的Delta表中:
SQL
%sql
INSERT INTO events SELECT * FROM newEventsPython
%pyspark
df.write.format("delta").mode("append").save("/mnt/delta/events")
df.write.format("delta").mode("append").saveAsTable("events")Scala
%spark
df.write
.format("delta")
.mode("overwrite")
.option("replaceWhere", "date >= '2017-01-01' AND date <= '2017-01-31'")
.save("/mnt/delta/events")覆蓋
要原子式地替換表中的所有數據,可以使用overwrite模式:
SQL
%sql
INSERT OVERWRITE TABLE events SELECT * FROM newEvents
Python
%pyspark
from pyspark.sql.functions import to_date
df = spark.createDataFrame([("case21", '2020-10-12', 23, 'INFO'),("case22", '2020-10-13', 24, 'INFO')], ['data', 'date', 'eventId', 'eventType'])
df1 = df.select('data', to_date('date', 'yyyy-MM-dd').alias('date'), 'eventId', 'eventType')
df1.write.format("delta").mode("append").save("/mnt/delta/events")
df1.write.format("delta").mode("append").saveAsTable("events")Scala
%spark
df.write
.format("delta")
.mode("overwrite")
.option("replaceWhere", "date >= '2017-01-01' AND date <= '2017-01-31'")
.save("/mnt/delta/events")使用DataFrames,還可以選擇性地只覆蓋與分區列上的謂詞匹配的數據。以下命令將原子式地把大于10-4的數據替換為10-12、10-13號的數據
Python
%pyspark
df = spark.createDataFrame([("case21", '2020-10-12', 21, 'INFO'),("case22", '2020-10-13', 22, 'INFO')], ['data', 'date', 'eventId', 'eventType'])
df1 = df.select('data', to_date('date', 'yyyy-MM-dd').alias('date'), 'eventId', 'eventType')
# 可以替換分區部分數據(replaceWhere中字段必須是分區字段);此處替換大于等于10-4的數據,并將10-12、10-13號的數據填入
df1.write.format("delta").mode("overwrite").option("replaceWhere", "date >= '2020-10-4'").saveAsTable("events_partition")
spark.table("events_partition").show(50)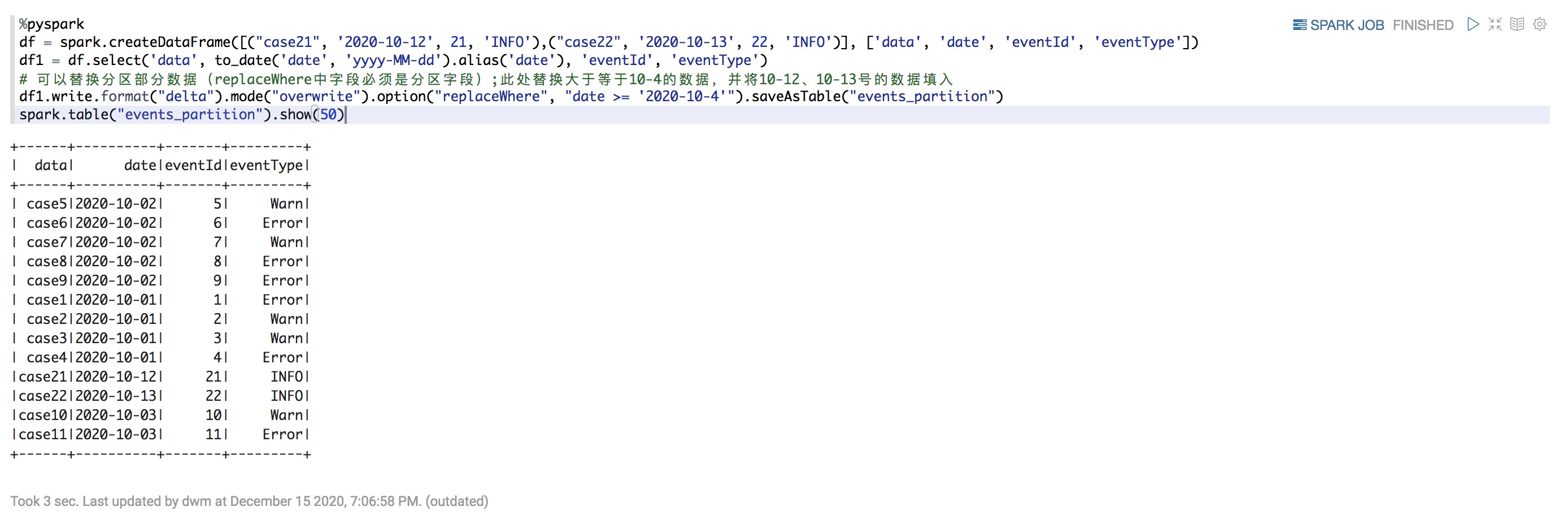
Scala
%spark
df.write
.format("delta")
.mode("overwrite")
.option("replaceWhere", "date >= '2017-01-01' AND date <= '2017-01-31'")
.save("/mnt/delta/events")此示例代碼將數據寫入df,驗證所有數據均位于指定分區內,并執行atomic替換。
與Apache Spark中的文件API不同,Delta Lake會記住并強制執行表的Schema。這意味著默認情況下,覆蓋不會替換現有表的Schema。
有關Delta Lake在更新表方面的支持,請參閱表刪除,更新和合并。
設置用戶定義的提交元數據
您可以使用DataFrameWriter選項userMetadata或SparkSession配置spark.databricks.delta.commitInfo.userMetadata,將用戶定義的字符串指定為這些操作進行的提交中的元數據。如果同時指定了兩個參數,則以DataFrameWriter選項userMetadata優先。用戶定義的元數據在歷史記錄操作中是可讀的。
SQL
%sql
SET spark.databricks.delta.commitInfo.userMetadata=overwritten-for-fixing-incorrect-data
INSERT OVERWRITE events SELECT * FROM newEventsPython
%python
df.write.format("delta") \
.mode("overwrite") \
.option("userMetadata", "overwritten-for-fixing-incorrect-data") \
.save("/mnt/delta/events")Scala
%spark
df.write.format("delta")
.mode("overwrite")
.option("userMetadata", "overwritten-for-fixing-incorrect-data")
.save("/mnt/delta/events")Schema驗證
Delta Lake自動驗證正在寫入的DataFrame的Schema與表的Schema兼容。Delta Lake使用以下規則來確定從DataFrame到表的寫入是否兼容:
所有DataFrame列都必須存在于目標表中。如DataFrame中有表中不存在列,則會拋出異常。表中存在但DataFrame中不存在的列設置為NULL。
DataFrame列數據類型必須與目標表中的列數據類型匹配。如果它們不匹配,則會拋出異常。
DataFrame列名稱不能僅通過大小寫來區分。這意味著您不能在同一表中定義諸如“ Foo”和“ foo”之類的列。雖然可以在區分大小寫或不區分大小寫(默認)模式下使用Spark,但在存儲和返回列信息時,Parquet區分大小寫。在存儲Schema時,Delta Lake 保留但不區分大小寫,并采用此限制來避免潛在的錯誤、數據損壞或丟失問題。
Delta Lake支持DDL顯式添加新列,并具有自動更新Schema的功能。
如果您指定其他選項(例如partitionBy與附加模式結合使用),則Delta Lake會驗證它們是否匹配,并在任何不匹配項時發生錯誤。如果分區不存在,會在對現有數據分區之后自動進行追加。
在Databricks Runtime 7.0及更高版本中,INSERT語法提供了Schema強制實施并支持Schema演變。如果不能將列的數據類型安全地強制轉換為Delta Lake表的數據類型,則將拋出運行時異常。如果啟用Schema演化,則新列可以作為Schema的最后一列(或嵌套列)存在,以使Schema得以演化。
更新表Schema
Delta Lake可讓您更新表的Schema。支持以下類型的更改:
添加新列(在任意位置)
重新排序現有列
您可以使用DDL顯式進行更改,也可以使用DML隱式進行更改。
更新Delta表Schema時,從該表讀取的流將終止。如果你希望流繼續進行,則必須重新啟動它。
有關推薦的方法,請參見生產中的結構化流。
顯示更新Schema
您可以使用以下DDL顯式更改表的Schema。
添加列
SQL
%sql
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment] [FIRST|AFTER colA_name], ...)默認情況下,可空性為true。
要將列添加到嵌套字段,請使用:
SQL
%sql
ALTER TABLE table_name ADD COLUMNS (col_name.nested_col_name data_type [COMMENT col_comment] [FIRST|AFTER colA_name], ...)例
如果運行之前的Schema為:ALTER TABLE boxes ADD COLUMNS (colB.nested STRING AFTER field1)
| - colA
| - colB
| +-field1
| +-field2之后的Schema是:
| - colA
| - colB
| +-field1
| +-nested
| +-field2僅支持為結構添加嵌套列。不支持數組和映射。
更改列注釋或順序
SQL
%sql
ALTER TABLE table_name CHANGE [COLUMN] col_name col_name data_type [COMMENT col_comment] [FIRST|AFTER colA_name]要更改嵌套字段中的列,請使用
SQL
%sql
ALTER TABLE table_name CHANGE [COLUMN] col_name.nested_col_name nested_col_name data_type [COMMENT col_comment] [FIRST|AFTER colA_name]例
如果運行之前的Schema為:ALTER TABLE boxes CHANGE COLUMN colB.field2 field2 STRING FIRST
| - colA
| - colB
| +-field1
| +-field2之后的模式是:
| - colA
| - colB
| +-field2
| +-field1更換列
SQL
%sql
ALTER TABLE table_name REPLACE COLUMNS (col_name1 col_type1 [COMMENT col_comment1], ...)例
運行以下DSL時:
SQL
%sql
ALTER TABLE boxes REPLACE COLUMNS (colC STRING, colB STRUCT<field2:STRING, nested:STRING, field1:STRING>, colA STRING)如果之前的Schema是:
| - colA
| - colB
| +-field1
| +-field2之后的模式是:
| - colC
| - colB
| +-field2
| +-nested
| +-field1
| - colA更改列類型或名稱
更改列的類型或名稱或刪除列需要重寫表。為此,請使用以下overwriteSchema選項:
更改列類型
Python
%pyspark
spark.read.table(...)
.withColumn("date", col("date").cast("date"))
.write
.format("delta")
.mode("overwrite")
.option("overwriteSchema", "true")
.saveAsTable(...)更改列名
Python
%pyspark
spark.read.table(...)
.withColumnRenamed("date", "date_created")
.write
.format("delta")
.mode("overwrite")
.option("overwriteSchema", "true")
.saveAsTable(...)自動Schema更新
Delta Lake可以作為DML事務的一部分(附加或覆蓋)自動更新表的Schema,并使該Schema與正在寫入的數據兼容。
添加列
在以下情況下,會自動添加DataFrame中存在但表中缺少的列將作為寫事務的一部分:
write或writeStream有.option("mergeSchema", "true")
spark.databricks.delta.schema.autoMerge.enabled是 true
如果同時指定了兩個選項,則以該DataFrameWriter的option選項為準。添加的列將追加到它們所在結構的末尾。追加新列時將保留大小寫。
當啟用了表訪問控制時,mergeSchema不受支持(因為它將需要MODIFY的請求為ALL PRIVILEGES的請求) 。
mergeSchema 不能與INSERT INTO或.write.insertInto()一起使用。
NullType 列
由于Parquet不支持Nulltype,因此在寫入Delta表時會將Nulltype列從DataFrame中刪除,但仍存儲在Schema中。當為該列接收到不同的數據類型時,Delta Lake會將Schema合并到新的數據類型。如果Delta Lake收到現有列的Nulltype,則在寫入過程中將保留舊Schema,并刪除新列。
Nulltype不支持流式傳輸。由于必須在使用流式傳輸時設置Schema,因此這種情況很少見。Nulltype也不適用于ArrayType和MapType的復雜類型。
替換表Schema
默認情況下,覆蓋表中的數據不會覆蓋Schema。在不使用replaceWhere的情況下使用mode(“overwrite”)重寫表時,您可能仍然希望覆蓋正在寫入的數據的Schema。通過將overwriteSchema選項設置為true,可以替換表的Schema和分區:
Python
%pyspark
df.write.option("overwriteSchema", "true")Table上的視圖
就像您可能使用數據源表一樣,Delta Lake支持在Delta表之上創建視圖。
這些視圖與表訪問控制集成在一起,以實現列級和行級安全性。
使用視圖進行操作時的核心挑戰是解析Schema。如果更改Delta表Schema,則必須重新創建派生視圖以說明對該Schema的添加任何內容。例如,如果向Delta表中添加一個新列,則必須確保此列在該基于該基表構建的相應視圖中可用。
表屬性
你可以在CREATE和ALTER時使用TBLPROPERTIES作為表屬性來存儲你的元數據
TBLPROPERTIES作為Delta表元數據一部分存儲。如果給定位置中已經存在Delta表,則不能在CREATE語句中定義新的TBLPROPERTIES 。
此外,為了調整行為和性能,Delta Lake支持某些Delta表屬性:
阻止Delta表中刪除和更新:delta.appendOnly=true。
配置按時間順序查看保留屬性:delta.logRetentionDuration=<interval-string>和delta.deletedFileRetentionDuration=<interval-string>。
配置要收集其統計信息的列數:delta.dataSkippingNumIndexedCols=<number-of-columns>。此屬性僅對寫入的新數據有效。
這些是唯一受支持的delta.前綴表屬性。
修改Delta表屬性是一種寫操作,它將與其他并發的寫操作發生沖突,從而導致它們失敗。我們建議您僅在表上沒有并發寫操作時才修改表屬性。
您還可以使用Spark配置在首次提交delta表時設置delta.-prefixed屬性。例如,要使用該屬性初始化Delta表delta.appendOnly=true,請將Spark配置spark.databricks.delta.properties.defaults.appendOnly設置為true。例如:
SQL
%sql
spark.sql("SET spark.databricks.delta.properties.defaults.appendOnly = true")Scala
%spark
spark.conf.set("spark.databricks.delta.properties.defaults.appendOnly", "true")Python
%pyspark
spark.conf.set("spark.databricks.delta.properties.defaults.appendOnly", "true")元數據表
Delta Lake具有豐富的功能,可用于瀏覽元數據表。
它支持SHOW[PARTITIONS | COLUMNS]和DESCRIBE TABLE。查看
Databricks Runtime 7.0及更高版本
Databricks Runtime 6.x及以下版本
它還提供以下獨特命令:
DESCRIBE DETAlL
DESCRIBE HISTORY
DESCRIBE DETAlL
提供有關Schema,分區,表大小等的信息。
DESCRIBE HISTORY
提供源信息,包括操作,用戶等,以及每次寫入表的操作指標。表格歷史記錄將保留30天。
數據側欄提供了Delta表的詳細表信息和歷史的可視化視圖。除了表Schema和示例數據外,還可以單擊“歷史記錄”選項卡來查看與“DESCRIBE HISTORY”一起顯示的表歷史記錄。