設計方案
基于穩定性支柱設計原則,整體穩定性設計方案可參考如下:
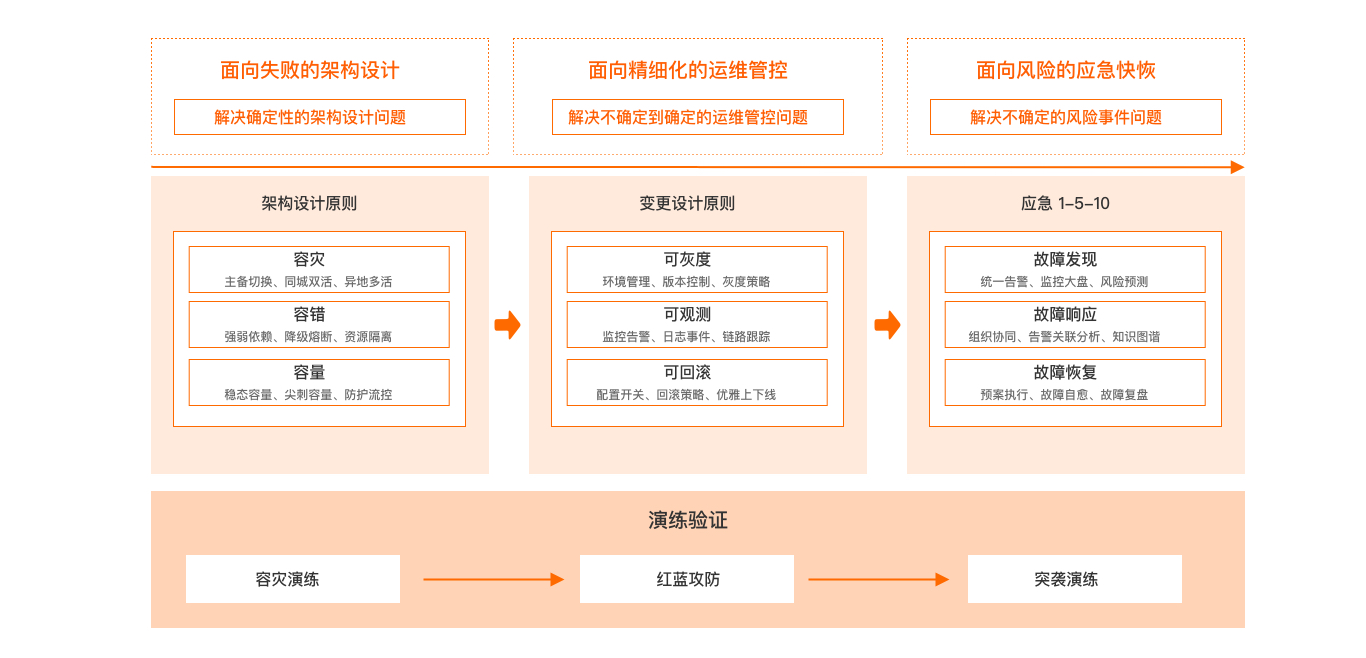
架構設計原則
軟件系統從所有的功能都在一個應用程序內運行的單體應用架構,到不同的功能模塊分別部署在不同的服務器上的傳統分布式應用架構,再到服務細分通過輕量級的通信機制進行互相調用的微服務架構,到現在將云計算、容器化、微服務架構等技術結合起來的云原生架構。在軟件系統架構演進中不變的是系統的基本屬性,包含存儲、計算和網絡,變的是存儲、計算和網絡的實現方式和規模,往大規模、高性能、高可靠、易擴展等方向迭代演進,所以對架構穩定性提出了更高的要求。
系統可預見的穩定性風險包含軟硬件故障和不可預期的流量,小到線程級風險,大到地域級災難,從此出發可通過容災、容錯、容量三方面建立系統架構穩定性。
容災
容災就是在災難發生時,在保證生產系統的數據盡量少丟失的情況下,保持生存系統的業務不間斷地運行。異地多活、同城雙活都屬于容災的范疇。借助阿里云多區域(Region)及可用區(Availability Zone,簡稱AZ)能力,應用可以用較小成本來完成容災架構部署。
容災需要具備較為完善的數據保護與災難恢復功能,保證生產中心不能正常工作時數據的完整性及業務的連續性,并在最短時間內由災備中心接替,恢復業務系統的正常運行,將損失降到最小。
容錯
容錯是指在分布式系統中,系統出現故障時,通過設計和實現可靠的機制和策略,使系統能夠自動檢測、排除或者糾正錯誤,保證系統能夠正常運行,從而提高系統的可靠性和穩定性。
容量
容量是在一定時間內,系統能夠處理的最大工作量或數據量,或指系統所能夠承載的最大負載。系統容量與系統的硬件、軟件、架構以及網絡帶寬等因素密切相關。在云上,還需要關注單個阿里云賬號下的云服務配額,避免因觸及云服務配額限制導致的業務故障。
變更設計原則
在企業的運維管理與運行過程中,就會有變更產生。變更是指添加、修改或刪除任何可能對服務產生直接或間接影響的內容。當變更失敗時可能會帶來嚴重后果:業務中斷、客戶輿情等等一系列問題。為了降低變更帶來的業務風險,需要遵循變更設計原則:可灰度、可監控、可回滾。
可灰度
可灰度,需要建立起完整的灰度發布機制,完善的灰度機制有助于變更失敗時降低業務影響,提升用戶體驗。
灰度發布機制包含但不限于以下幾點:灰度方式、灰度批次、間隔時間、灰度觀測等。灰度發布需注意:
灰度間隔時間:合理設定灰度間隔時間,不宜過長。過長的灰度間隔時間可能導致下游應用出現數據不一致等問題。
灰度發布方式:合理選擇灰度發布方式,可按用戶、按區域、按渠道等方式進行灰度,避免出現灰度過程中用戶體驗不一致的問題。
灰度發布批次:建議先小范圍的進行灰度驗證,再逐步擴大灰度范圍。
灰度觀測指標:明確灰度期間的可觀測指標,用于判斷發布結果,避免造成連鎖反應。
可回滾
大部分變更要做好應急恢復手段,最常用的技術手段就是回滾。
理論上回滾永遠是最合適最有效的方法,當問題發生時,保證業務連續運行永遠是第一要義。實際中可能存在其他解決方案,但后果無法預料,所以選擇回滾是最好方式。
在發布時建議多版本小更新,避免因變更版本跨度較大,帶來的系統依賴關系問題導致無法回滾。
可觀測
在變更過程中,會影響到現有環境以及上下游業務,通過對業務、鏈路、資源等做到可觀測,就能夠第一時間發現問題。在觀測過程中,關注業務指標(如下單成功率)和應用指標(如CPU、Load、異常數量等)。當指標較多時,優先關注高優先級的業務指標,業務指標能夠最直觀反映當前系統狀況,當業務指標發生變化時,往往應用指標也會有相應的變化。
變更前需準備好對應的檢查清單。在變更期間,要做到持續觀察監控數據,確定是否有負面影響或問題。在變更結束后,對變更前后的業務指標進行對比,沒有問題后才結束變更。
應急響應機制
應急響應機制的關鍵點在于事件發生后,有標準的操作流程和動作。阿里巴巴在過去十幾年的安全生產過程中,沉淀了一套故障應急響應機制,簡稱應急響應1-5-10。是指在1分鐘內發現故障,5分鐘內組織相關人員進行初步排查,10分鐘內開展故障恢復和處理工作。企業在設計應急響應機制時,可以參考該方式明確響應期間的標準動作和流程,確保在事件發生時,相關干系人都能夠明確自身職責和所需要采取的措施。
故障發現
故障一旦發生,越早發現故障,能夠越早進行響應。建議通過以下途徑實現故障的快速發現:
統一告警:在發現故障后,需要將相關信息及時告知相關人員,包括系統管理員、運維人員等。可以通過短信、郵件、釘釘等方式進行告警,確保所有相關人員第一時間得知故障情況,以便快速組織應急響應。
監控大屏:監控大屏是指將所有系統的運行情況以圖形化的方式展示在屏幕上,以便實時監控系統健康狀況。在發生故障時,監控大屏可以快速反應故障情況,并提供相關數據,為故障排查及處理提供依據。
風險預測:風險預測是指在發生故障前,通過數據分析、機器學習等方式,預測系統的風險情況,提前進行預防和處理。在故障應急響應中,風險預測可以作為重要參考,幫助快速識別問題的根本原因,提高故障處理效率和精度。
故障響應
在發現故障后,需要快速定位問題,通常有以下做法:
組織協調:故障發生后,需要迅速組織相關人員進行應急響應。組織協調包括設置指揮中心、確定應急響應流程、分配任務等。這些工作的目的是提高應急響應的效率和準確性,讓每個人都清楚自己的任務和責任,避免出現混亂和誤操作。
告警關聯分析:在故障發生時,系統會自動產生告警信息。為了更好地定位故障原因,需要對各種告警信息進行關聯分析。這樣可以快速確定故障的范圍和影響,并且能夠幫助排查故障的根本原因。告警關聯分析可以使用各種工具和算法,如事件關聯分析、機器學習等。
知識圖譜:知識圖譜是指通過將各種數據和知識進行關聯和組織,建立一種知識庫或知識圖譜,以便在故障發生時快速定位和解決問題。在應急響應中,知識圖譜可以指導故障排查和處理工作,提高效率和準確性。知識圖譜可以使用各種工具和技術,如自然語言處理、圖數據庫等。
故障恢復
定位故障原因后,按照應急預案快速恢復業務,并在事后進行復盤總結。
預案執行:在故障響應的過程中,需要按照事先制定的應急預案進行執行。應急預案包括了應急響應流程、各個崗位的職責、處理流程等。預案執行能夠保證故障恢復和處理的規范化和標準化。
故障自愈:故障自愈是指系統自動檢測到故障并采取自動恢復措施。故障自愈技術可以幫助故障恢復和處理更加快速和準確。例如,利用容器技術,系統可以自動遷移容器來解決故障。
故障復盤:故障復盤是指對故障進行分析和總結,以便更好地避免故障的再次發生。在故障復盤過程中,需要對故障的起因、影響、處理過程等進行詳細的記錄和分析,并制定相關的措施。故障復盤也是一種學習和提高的過程,能夠不斷完善系統和提高團隊的應急響應能力。
演練常態化
故障演練提供了一種端到端的測試理念與工具框架,本質是通過主動引入故障來充分驗證軟件質量的脆弱性。從提前發現系統風險、提升測試質量、完善風險預案、加強監控告警、提升故障應急效率等方面做到故障發生前有效預防,故障發生時及時應對,故障恢復后回歸驗證。基于故障本身打造分布式系統韌性,持續提升軟件質量,增強團隊對軟件生產運行的信心。故障演練可分為方案驗證的容災演練、穩定性驗收的紅藍攻防,以及故障應急驗證的突襲演練。
容災演練
容災演練是通過模擬實例、機房或地域級故障,判斷系統服務的逃逸能力,驗證系統的容災能力以及面對災難時的應對能力。容災演練可以幫助企業更好的驗證RPO、RTO指標,及時發現和解決相關問題,提高系統的可用性和可靠性。
紅藍攻防
紅藍攻防是在想定情況誘導下進行的作戰指揮和行動演練,是部隊在完成理論學習和基礎訓練之后實施的,近似實戰的綜合性訓練,是軍事訓練的高級階段。演習通常分為紅軍,藍軍,多以紅軍守,藍軍進攻為主。
紅藍攻防不僅能夠用于安全演練,在穩定性演練中同樣適用。在穩定性攻防中,藍軍從第三方角度發掘各類脆弱點,并向業務所依賴的各種軟硬件注入故障,不斷驗證業務系統的可靠性。而紅軍則需要按照預先定義的故障響應和應急流程進行處置。在演練結束后,建議針對故障中的發現、響應、恢復三個階段的時長和操作內容進行復盤,并梳理改進點進行優化,提升業務系統的穩定性。
突襲演練
突襲演練是一種手段以及目標對紅軍不透明的組織形式。通過突襲演練可以全面檢驗技術團隊在面對突發故障時的應急和恢復能力,提升人員的安全意識。在突襲演練中,紅藍雙方是純對抗的關系,因此對紅藍雙方提出了更高的要求,藍軍不僅需要了解目標系統的薄弱點,更需要了解目標系統的業務,紅軍不僅僅需要修復故障,還需要快速的發現故障和有效的應急協同。相比較計劃演練,突襲演練涉及到的人員,場景,流程也會更加復雜,同時不但確保演練計劃的私密性,還需要充分評估在紅軍未及時處理故障時的影響面控制。