快速提交PAI-DLC訓(xùn)練任務(wù)
learn
手動(dòng)配置
40
教程簡(jiǎn)介
在本教程中,您將學(xué)習(xí)如何使用阿里云機(jī)器學(xué)習(xí)平臺(tái)PAI控制臺(tái)提交分布式訓(xùn)練(DLC)任務(wù)。
PAI-DLC(Deep Learning Containers)是基于云原生容器服務(wù)的深度學(xué)習(xí)訓(xùn)練平臺(tái),為您提供靈活、穩(wěn)定、易用和較優(yōu)性能的深度學(xué)習(xí)訓(xùn)練環(huán)境。PAI平臺(tái)同時(shí)還提供了完善的SDK和OpenAPI,實(shí)現(xiàn)了基于代碼提交任務(wù),使得PAI-DLC更靈活地應(yīng)用到您的日常生產(chǎn)中。
我能學(xué)到什么
學(xué)會(huì)使用控制臺(tái)界面提交DLC訓(xùn)練任務(wù)的流程。
操作難度 | 中 |
所需時(shí)間 | 40分鐘 |
使用的阿里云產(chǎn)品 | |
所需費(fèi)用 | 阿里云免費(fèi)試用在華北2(北京)、華東2(上海)、華東1(杭州)、華南1(深圳)為您提供了一定數(shù)量的DLC免費(fèi)資源包供您使用,超出免費(fèi)額度后將收取費(fèi)用。DLC的計(jì)費(fèi)詳情請(qǐng)參見分布式訓(xùn)練(DLC)計(jì)費(fèi)說明。 【重要】PAI-DLC免費(fèi)資源包只適用于本教程中的PAI-DLC產(chǎn)品。如果您領(lǐng)取了PAI-DLC資源包后,使用了PAI-DLC及PAI的其他產(chǎn)品功能(如PAI-DSW、PAI-EAS等),PAI-DLC產(chǎn)品產(chǎn)生的費(fèi)用由資源包抵扣,其他產(chǎn)品功能產(chǎn)生的費(fèi)用無法抵扣,會(huì)產(chǎn)生對(duì)應(yīng)的費(fèi)用賬單。 |
準(zhǔn)備環(huán)境及資源
10
開始教程前,請(qǐng)按以下步驟準(zhǔn)備環(huán)境和資源:
【重要】PAI-DLC免費(fèi)資源包只適用于本教程中的PAI-DLC產(chǎn)品。如果您領(lǐng)取了PAI-DLC資源包后,使用了PAI-DLC及PAI的其他產(chǎn)品功能(如PAI-DSW、PAI-EAS等),PAI-DLC產(chǎn)品產(chǎn)生的費(fèi)用由資源包抵扣,其他產(chǎn)品功能產(chǎn)生的費(fèi)用無法抵扣,會(huì)產(chǎn)生對(duì)應(yīng)的費(fèi)用賬單。
訪問阿里云免費(fèi)試用。單擊頁面右上方的登錄/注冊(cè)按鈕,并根據(jù)頁面提示完成賬號(hào)登錄(已有阿里云賬號(hào))、賬號(hào)注冊(cè)(尚無阿里云賬號(hào))或?qū)嵜J(rèn)證(根據(jù)試用產(chǎn)品要求完成個(gè)人實(shí)名認(rèn)證或企業(yè)實(shí)名認(rèn)證)。
申請(qǐng)免費(fèi)試用OSS,并創(chuàng)建Bucket。
【說明】本教程以使用OSS創(chuàng)建數(shù)據(jù)集來存儲(chǔ)代碼文件為例,來說明如何提交訓(xùn)練任務(wù)。
領(lǐng)取對(duì)象存儲(chǔ)OSS資源抵扣包。
進(jìn)入OSS免費(fèi)資源包申請(qǐng)頁面,單擊立即試用,在確認(rèn)并了解相關(guān)信息后,根據(jù)頁面提示申請(qǐng)?jiān)囉谩?/p>
【注意】:如果您的對(duì)象存儲(chǔ)OSS資源抵扣包已使用完畢或無領(lǐng)取資格,開通PAI試用后,將正常收取費(fèi)用,計(jì)費(fèi)詳情請(qǐng)參見OSS按量付費(fèi)。
創(chuàng)建OSS Bucket。
登錄OSS控制臺(tái),在Bucket列表頁面單擊創(chuàng)建Bucket開始創(chuàng)建Bucket。本教程的核心配置參數(shù)如下,其他參數(shù)可保持默認(rèn)值,詳細(xì)創(chuàng)建步驟請(qǐng)參見創(chuàng)建有地域?qū)傩訠ucket。
地域:選擇有地域?qū)傩?/b>,華南1(深圳)地域。
其他參數(shù):保持默認(rèn)值即可。
申請(qǐng)開通免費(fèi)試用PAI。
進(jìn)入模型訓(xùn)練PAI-DLC免費(fèi)資源包申請(qǐng)頁面,并在模型訓(xùn)練PAI-DLC卡片上單擊立即試用。
【說明】:如果您此前已申請(qǐng)過試用PAI的免費(fèi)資源包,此時(shí)界面會(huì)提示為已試用,您可以直接單擊已試用按鈕,進(jìn)入PAI的控制臺(tái)。
在模型訓(xùn)練PAI-DLC面板,勾選服務(wù)協(xié)議后,單擊立即試用,進(jìn)入免費(fèi)開通頁面。
開通機(jī)器學(xué)習(xí)PAI并創(chuàng)建默認(rèn)工作空間。其中關(guān)鍵參數(shù)配置如下,更多詳情內(nèi)容,請(qǐng)參見開通并創(chuàng)建默認(rèn)工作空間。如果您后續(xù)使用RAM用戶來提交DLC訓(xùn)練任務(wù),您需要將RAM用戶添加為默認(rèn)工作空間的成員,并配置管理員角色,詳情請(qǐng)參見管理工作空間成員。
本教程選擇的地域?yàn)椋?b data-tag="uicontrol" id="8bfe4b0820kij" class="uicontrol">華南1(深圳)。
單擊免費(fèi)開通并創(chuàng)建默認(rèn)工作空間:在彈出的開通頁面中配置訂單詳情。配置要點(diǎn)如下。
本教程不需要開通除OSS產(chǎn)品外的其他產(chǎn)品,您需要在組合開通配置模塊,去勾選其他產(chǎn)品的復(fù)選框。
在服務(wù)角色授權(quán)模塊單擊去授權(quán),根據(jù)界面提示為PAI完成授權(quán),然后返回開通頁面,刷新頁面,繼續(xù)開通操作。
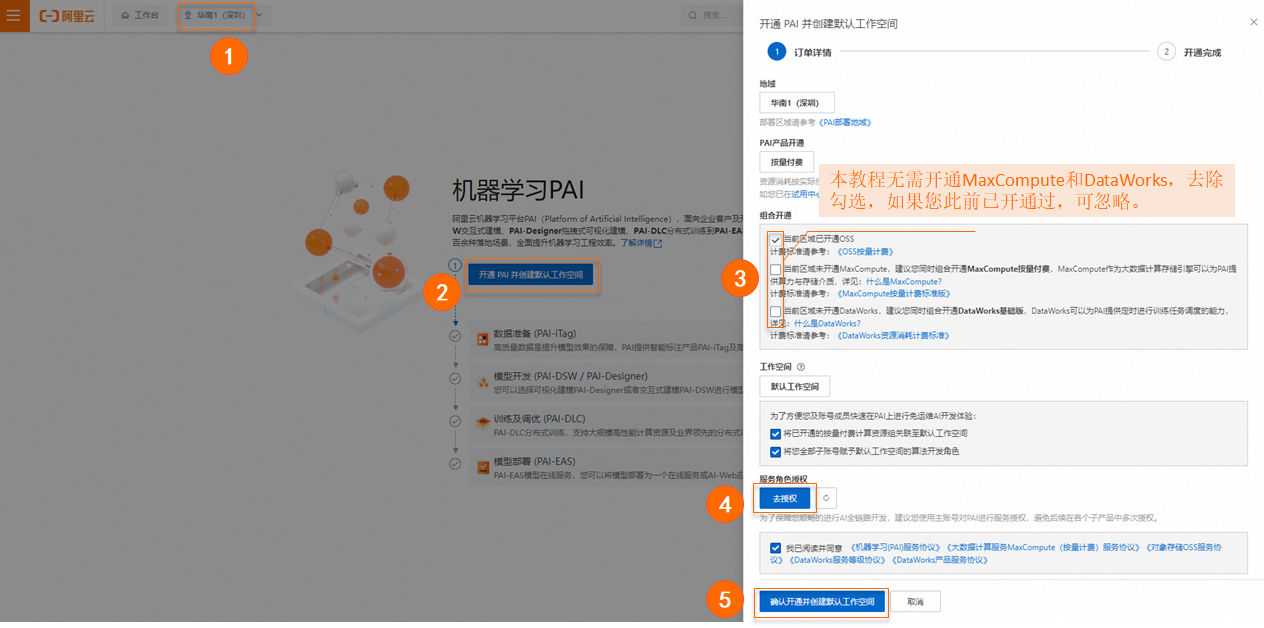
開通成功后,單擊進(jìn)入PAI控制臺(tái)。
【重要】以下幾種情況可能產(chǎn)生額外費(fèi)用。
使用了除免費(fèi)資源類型外的計(jì)費(fèi)資源類型:
您申請(qǐng)?jiān)囉玫氖荘AI-DLC免費(fèi)資源包,但您提交DLC訓(xùn)練任務(wù)使用的資源類型非阿里云免費(fèi)試用提供的資源類型。當(dāng)前可申請(qǐng)免費(fèi)使用的資源類型有:ecs.gn6v-c8g1.2xlarge、ecs.g6.xlarge、ecs.gn7i-c8g1.2xlarge。
申請(qǐng)?jiān)囉玫拿赓M(fèi)資源包與使用的產(chǎn)品資源不對(duì)應(yīng):
您提交了DLC訓(xùn)練任務(wù),但您申請(qǐng)?jiān)囉玫氖荘AI-DSW或PAI-EAS產(chǎn)品的免費(fèi)資源包。您使用DLC產(chǎn)品產(chǎn)生的費(fèi)用無法使用免費(fèi)資源包抵扣,會(huì)產(chǎn)生后付費(fèi)賬單。
您申請(qǐng)?jiān)囉玫氖荘AI-DLC免費(fèi)資源包,但您使用的產(chǎn)品是PAI-DSW或PAI-EAS。使用PAI-DSW和PAI-EAS產(chǎn)品產(chǎn)生的費(fèi)用無法使用DLC免費(fèi)資源包抵扣,會(huì)產(chǎn)生后付費(fèi)賬單。
免費(fèi)額度用盡或超出試用期:
領(lǐng)取免費(fèi)資源包后,請(qǐng)?jiān)诿赓M(fèi)額度和有效試用期內(nèi)使用。如果免費(fèi)額度用盡或試用期結(jié)束后,若繼續(xù)使用計(jì)算資源,將會(huì)產(chǎn)生后付費(fèi)賬單。
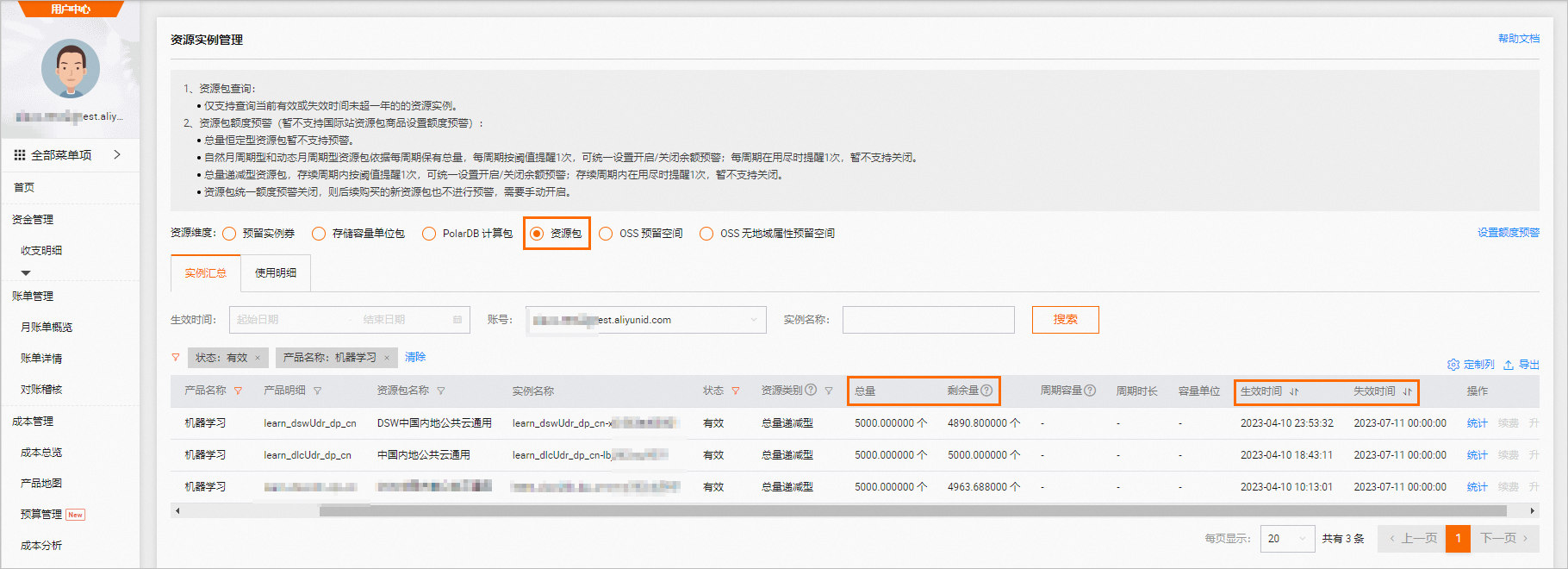
如果您使用的是DLC或DSW產(chǎn)品,請(qǐng)前往資源實(shí)例管理頁面,查看免費(fèi)額度使用量和過期時(shí)間,如下圖所示。
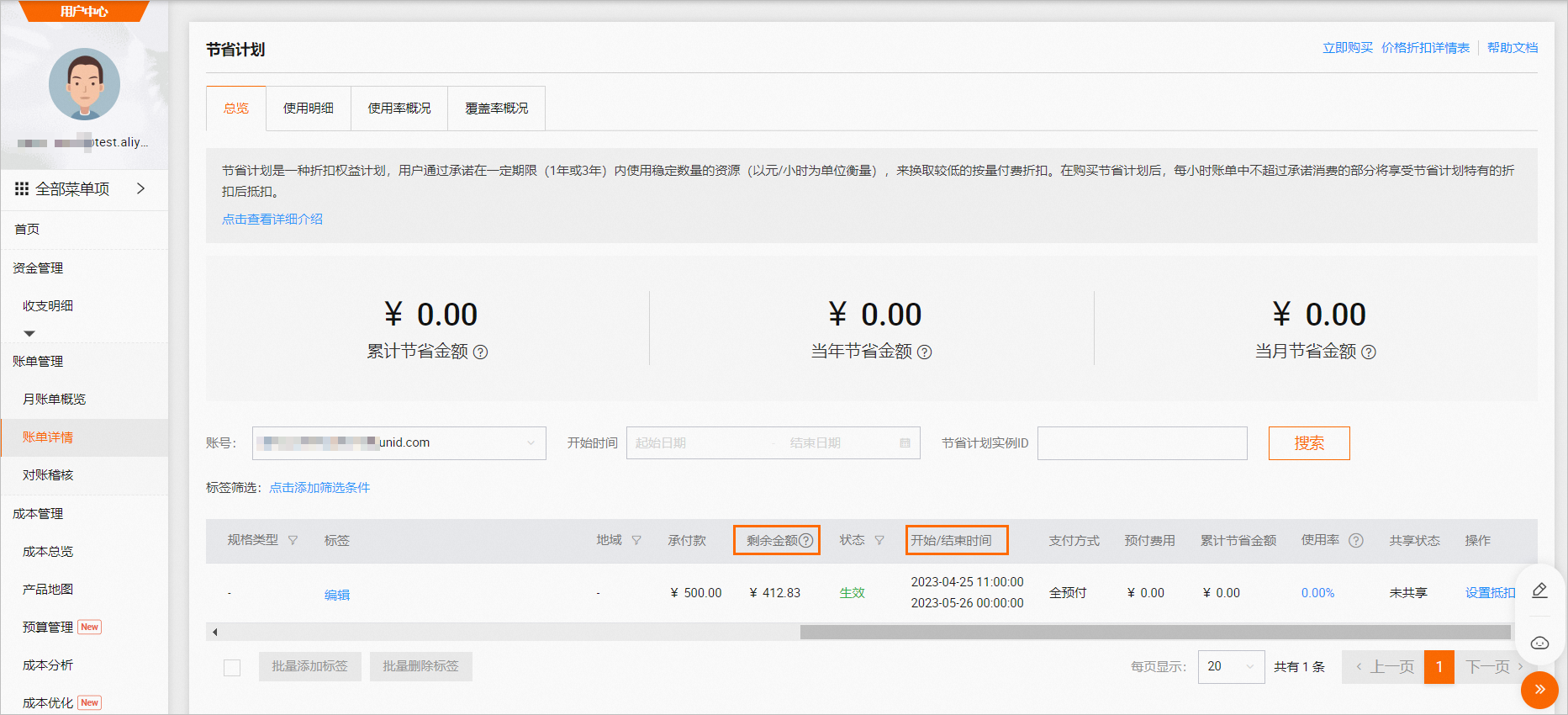
如果您使用的是EAS產(chǎn)品,請(qǐng)前往節(jié)省計(jì)劃頁面,查看抵扣包剩余金額和過期時(shí)間,如下圖所示。
準(zhǔn)備訓(xùn)練腳本
5
在本地創(chuàng)建torch_ddp_sample_code.py(Python)代碼文件,文件內(nèi)容如下。
import datetime import logging import os import argparse from math import ceil from random import Random import torch import torch.distributed as dist import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import torch.utils.data import torch.utils.data.distributed from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors from torch.autograd import Variable from torch.nn.modules import Module from torchvision import datasets, transforms gbatch_size = 128 epochs = 10 world_size = os.environ.get("WORLD_SIZE", "{}") rank = os.environ.get("RANK", "{}") class DistributedDataParallel(Module): def __init__(self, module): super(DistributedDataParallel, self).__init__() self.module = module self.first_call = True def allreduce_params(): if self.needs_reduction: self.needs_reduction = False buckets = {} for param in self.module.parameters(): if param.requires_grad and param.grad is not None: tp = type(param.data) if tp not in buckets: buckets[tp] = [] buckets[tp].append(param) for tp in buckets: bucket = buckets[tp] grads = [param.grad.data for param in bucket] coalesced = _flatten_dense_tensors(grads) dist.all_reduce(coalesced) coalesced /= dist.get_world_size() for buf, synced in zip(grads, _unflatten_dense_tensors(coalesced, grads)): buf.copy_(synced) for param in list(self.module.parameters()): def allreduce_hook(*unused): Variable._execution_engine.queue_callback(allreduce_params) if param.requires_grad: param.register_hook(allreduce_hook) def weight_broadcast(self): for param in self.module.parameters(): dist.broadcast(param.data, 0) def forward(self, *inputs, **kwargs): if self.first_call: logging.info("first broadcast start") self.weight_broadcast() self.first_call = False logging.info("first broadcast done") self.needs_reduction = True return self.module(*inputs, **kwargs) class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 10, kernel_size=5) self.conv2 = nn.Conv2d(10, 20, kernel_size=5) self.conv2_drop = nn.Dropout2d() self.fc1 = nn.Linear(320, 50) self.fc2 = nn.Linear(50, 10) def forward(self, x): x = F.relu(F.max_pool2d(self.conv1(x), 2)) x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) x = x.view(-1, 320) x = F.relu(self.fc1(x)) x = F.dropout(x, training=self.training) x = self.fc2(x) return F.log_softmax(x) def partition_dataset(rank): dataset = datasets.MNIST( './data{}'.format(rank), train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])) size = dist.get_world_size() bsz = int(gbatch_size / float(size)) train_sampler = torch.utils.data.distributed.DistributedSampler(dataset) train_set = torch.utils.data.DataLoader( dataset, batch_size=bsz, shuffle=(train_sampler is None), sampler=train_sampler) return train_set, bsz def average_gradients(model): size = float(dist.get_world_size()) group = dist.new_group([0]) for param in model.parameters(): dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM, group=group) param.grad.data /= size def run(gpu): rank = dist.get_rank() torch.manual_seed(1234) train_set, bsz = partition_dataset(rank) model = Net() if gpu: model = model.cuda() model = torch.nn.parallel.DistributedDataParallel(model) else: model = DistributedDataParallel(model) optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) num_batches = ceil(len(train_set.dataset) / float(bsz)) logging.info("num_batches = %s", num_batches) time_start = datetime.datetime.now() for epoch in range(epochs): epoch_loss = 0.0 for data, target in train_set: if gpu: data, target = Variable(data).cuda(), Variable(target).cuda() else: data, target = Variable(data), Variable(target) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) epoch_loss += loss.item() loss.backward() average_gradients(model) optimizer.step() logging.info('Epoch {} Loss {:.6f} Global batch size {} on {} ranks'.format( epoch, epoch_loss / num_batches, gbatch_size, dist.get_world_size())) if gpu: logging.info("GPU training time= {}".format( str(datetime.datetime.now() - time_start))) else: logging.info("CPU training time= {}".format( str(datetime.datetime.now() - time_start))) if __name__ == "__main__": logging.basicConfig(level=logging.INFO, format=('%(levelname)s|%(asctime)s' '|%(pathname)s|%(lineno)d| %(message)s'), datefmt='%Y-%m-%dT%H:%M:%S', ) logging.getLogger().setLevel(logging.INFO) parser = argparse.ArgumentParser(description='Train Pytorch model using DDP') parser.add_argument('--gpu', action='store_true', help='Use GPU and CUDA') parser.set_defaults(gpu=False) args = parser.parse_args() if args.gpu: logging.info("\n======= CUDA INFO =======") logging.info("CUDA Availability: %s", torch.cuda.is_available()) if torch.cuda.is_available(): logging.info("CUDA Device Name: %s", torch.cuda.get_device_name(0)) logging.info("CUDA Version: %s", torch.version.cuda) logging.info("=========================\n") dist.init_process_group(backend='gloo', init_method='env://',world_size=int(world_size),rank=int(rank)) run(gpu=False) dist.destroy_process_group()支持使用以下兩種方式保存代碼數(shù)據(jù),供后續(xù)模型訓(xùn)練使用。本教程以創(chuàng)建數(shù)據(jù)集為例。
單擊
 ,選擇已創(chuàng)建的Bucket。
,選擇已創(chuàng)建的Bucket。單擊新建目錄,輸入目錄名稱,單擊確定。
進(jìn)入新創(chuàng)建的目錄中,單擊上傳文件,按照界面操作指引上傳步驟1中在本地創(chuàng)建的torch_ddp_sample_code.py代碼文件。
選中步驟b創(chuàng)建的目錄,單擊確定。
將步驟1創(chuàng)建的代碼文件保存到您的Git地址。
【說明】您可以將代碼文件保存到您自己的Git地址;您也可以使用阿里云云效基礎(chǔ)版保存代碼文件,該版本免費(fèi)使用,但有代碼庫容量限制,如果您使用云效其他版本,會(huì)收取費(fèi)用,具體計(jì)費(fèi)詳情請(qǐng)參見計(jì)費(fèi)說明。
創(chuàng)建代碼集,其中關(guān)鍵參數(shù)配置如下,其他參數(shù)取默認(rèn)配置即可。更多詳細(xì)內(nèi)容,請(qǐng)參見代碼配置。
參數(shù)
描述
名稱
代碼集名稱。
Git地址
您在步驟a中配置的Git地址。
創(chuàng)建數(shù)據(jù)集
創(chuàng)建對(duì)象存儲(chǔ)(OSS)類型數(shù)據(jù)集,其中關(guān)鍵參數(shù)配置如下,其他參數(shù)取默認(rèn)配置即可。更多詳細(xì)內(nèi)容,請(qǐng)參見創(chuàng)建及管理數(shù)據(jù)集。
參數(shù) | 描述 |
數(shù)據(jù)集名稱 | 自定義數(shù)據(jù)集名稱,本教程配置為:dataset-oss。 |
選擇數(shù)據(jù)存儲(chǔ) | 選擇對(duì)象存儲(chǔ)(OSS)。 |
屬性 | 選擇文件夾。 |
從阿里云云存儲(chǔ)創(chuàng)建 | 按照以下操作步驟選擇代碼文件所在的OSS存儲(chǔ)空間(Bucket)路徑。 |
默認(rèn)掛載路徑 | 保持默認(rèn)配置: |
創(chuàng)建代碼集
提交訓(xùn)練任務(wù)
15
進(jìn)入新建任務(wù)頁面。
登錄PAI控制臺(tái)。
在頁面左上方,選擇工作空間所在地域。本教程選擇:華南1(深圳)。
在左側(cè)導(dǎo)航欄單擊工作空間列表,在工作空間列表頁面中單擊默認(rèn)工作空間名稱,進(jìn)入對(duì)應(yīng)工作空間內(nèi)。
在工作空間頁面的左側(cè)導(dǎo)航欄選擇模型開發(fā)與訓(xùn)練>分布式訓(xùn)練(DLC),在分布式訓(xùn)練(DLC)頁面,單擊新建任務(wù)。
配置訓(xùn)練任務(wù)的關(guān)鍵參數(shù),其他參數(shù)配置說明,請(qǐng)參見創(chuàng)建訓(xùn)練任務(wù)。
在基本信息區(qū)域,配置任務(wù)名稱。本教程配置為:doc_test_for_dlc。
在環(huán)境信息區(qū)域,配置以下關(guān)鍵參數(shù)。
參數(shù)
描述
節(jié)點(diǎn)鏡像
目前PAI-DLC支持使用官方鏡像和自定義鏡像。
本教程選擇官方鏡像:pytorch-training:1.8pai-gpu-py36-cu101-ubuntu18.04。
掛載配置
單擊添加按鈕,掛載類型選擇自定義數(shù)據(jù)集,并配置以下參數(shù):
數(shù)據(jù)集:選擇已創(chuàng)建的數(shù)據(jù)集dataset-oss。
掛載路徑:配置為
/mnt/data/。
啟動(dòng)命令
本教程配置為:
python /mnt/data/torch_ddp_sample_code.py。【說明】如果您將代碼文件保存為代碼集,需要根據(jù)實(shí)際情況來配置執(zhí)行命令。
代碼配置
本教程無需配置該參數(shù)。
【說明】如果您將代碼文件保存為代碼集,需要配置該參數(shù)。
在資源信息區(qū)域,配置以下關(guān)鍵參數(shù)。
參數(shù)
描述
資源來源
本教程選擇:公共資源。
框架
本教程選擇:PyTorch。
任務(wù)資源
單擊
 ,配置資源規(guī)格。本教程選擇。阿里云免費(fèi)試用提供的節(jié)點(diǎn)規(guī)格包括以下幾種規(guī)格:
,配置資源規(guī)格。本教程選擇。阿里云免費(fèi)試用提供的節(jié)點(diǎn)規(guī)格包括以下幾種規(guī)格:ecs.gn7i-c8g1.2xlarge
ecs.g6.xlarge
ecs.gn6v-c8g1.2xlarge
單擊確定,大約需要持續(xù)10分鐘,任務(wù)運(yùn)行成功。
完成
5
完成以上操作后,您的DLC訓(xùn)練任務(wù)已提交成功。您可以在分布式訓(xùn)練(DLC)頁面查看已提交的訓(xùn)練任務(wù)。
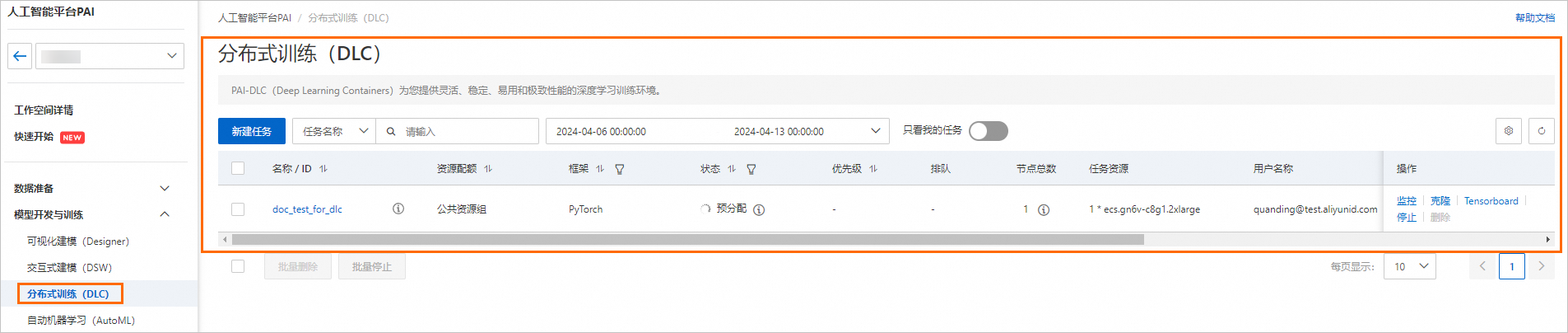
清理及后續(xù)
5
清理
領(lǐng)取免費(fèi)資源包后,請(qǐng)?jiān)诿赓M(fèi)額度和有效試用期內(nèi)使用。如果免費(fèi)額度用盡或試用期結(jié)束后,繼續(xù)使用計(jì)算資源,會(huì)產(chǎn)生后付費(fèi)賬單。
您可前往資源實(shí)例管理頁面,查看免費(fèi)額度使用量和過期時(shí)間。
如果無需繼續(xù)使用DLC訓(xùn)練任務(wù),您可以刪除DLC任務(wù)。
在分布式訓(xùn)練(DLC)頁面,當(dāng)目標(biāo)任務(wù)狀態(tài)為已成功、已停止或已失敗,您可以單擊操作列下的刪除,來刪除目標(biāo)任務(wù)。當(dāng)目標(biāo)任務(wù)狀態(tài)為其他狀態(tài)時(shí),您可以先單擊操作列下的停止,再單擊操作列下的刪除,即可刪除任務(wù)。
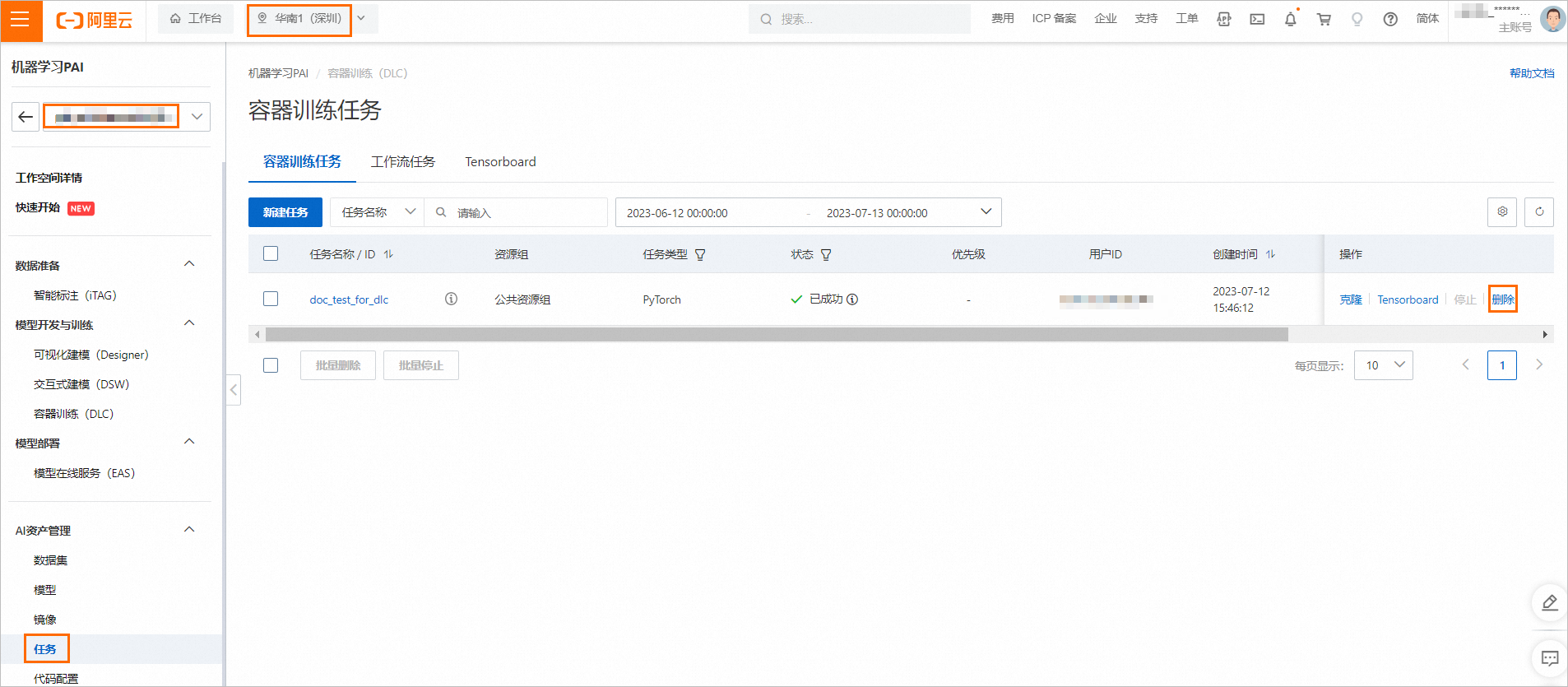
對(duì)象存儲(chǔ)OSS資源清理
刪除對(duì)象存儲(chǔ)空間,詳情請(qǐng)參見刪除存儲(chǔ)空間。
后續(xù)
在試用有效期期間,您還可自行提交DLC訓(xùn)練任務(wù)進(jìn)行模型訓(xùn)練。
總結(jié)
常用知識(shí)點(diǎn)
問題1:新建任務(wù)頁面,本教程必須完成的配置有哪些?(單選題)
任務(wù)名稱&節(jié)點(diǎn)鏡像&任務(wù)類型&執(zhí)行命令&數(shù)據(jù)集配置
代碼配置
最長(zhǎng)運(yùn)行時(shí)長(zhǎng)
正確答案是任務(wù)名稱&節(jié)點(diǎn)鏡像&任務(wù)類型&執(zhí)行命令&數(shù)據(jù)集配置。
問題2:提交DLC訓(xùn)練任務(wù)后,可以到哪個(gè)頁面查看已提交的訓(xùn)練任務(wù)?(單選題)
分布式訓(xùn)練(DLC)
鏡像
數(shù)據(jù)集
正確答案是分布式訓(xùn)練(DLC)。