基于流量請求數(shù)實現(xiàn)服務(wù)自動擴縮容
Knative中提供了開箱即用、基于流量請求的自動擴縮容KPA(Knative Pod Autoscaler)功能。本文介紹如何基于流量請求數(shù)實現(xiàn)服務(wù)自動擴縮容。
前提條件
已創(chuàng)建ACK托管集群或ACK Serverless集群,且集群版本為1.20及以上。具體操作,請參見已創(chuàng)建Kubernetes托管版集群、已創(chuàng)建ACK Serverless集群。
實現(xiàn)原理
Knative Serving會為每個Pod注入一個名為queue-proxy的QUEUE代理容器,該容器負責(zé)向Autoscaler報告業(yè)務(wù)容器的并發(fā)指標(biāo)。Autoscaler接收到這些指標(biāo)之后,會根據(jù)并發(fā)請求數(shù)及相應(yīng)的算法,調(diào)整Deployment的Pod數(shù)量,從而實現(xiàn)自動擴縮容。

算法
Knative Pod Autoscaler(KPA)基于每個Pod的平均請求數(shù)(或并發(fā)數(shù))進行自動擴縮容,Knative默認使用基于并發(fā)數(shù)的自動彈性,每個Pod的最大并發(fā)數(shù)為100。此外,Knative還提供了目標(biāo)使用率(target-utilization-percentage)的概念,用于指定自動擴縮容的目標(biāo)使用率。
基于并發(fā)數(shù)彈性為例,Pod數(shù)計算方式如為:Pod數(shù)=并發(fā)請求總數(shù)/(Pod最大并發(fā)數(shù)*目標(biāo)使用率)
例如,如果服務(wù)中Pod最大并發(fā)數(shù)設(shè)置為10,目標(biāo)使用率設(shè)置為0.7,此時如果接收到了100個并發(fā)請求,則Autoscaler就會創(chuàng)建15個Pod(即100/(0.7*10)≈15)。
KPA基于每個Pod的平均請求數(shù)(或并發(fā)數(shù))來進行自動擴縮容,并結(jié)合了Stable穩(wěn)定模式和Panic恐慌模式兩個概念,以實現(xiàn)精細化的彈性。
Stable穩(wěn)定模式
在穩(wěn)定模式中,KPA會在默認的穩(wěn)定窗口期(默認為60秒)內(nèi)計算Pod的平均并發(fā)數(shù)。根據(jù)這個平均并發(fā)數(shù),KPA會調(diào)整Pod的數(shù)量,以保持穩(wěn)定的負載水平。
Panic恐慌模式
在恐慌模式中,KPA會在恐慌窗口期(默認為6秒)內(nèi)計算Pod的平均并發(fā)數(shù)。恐慌窗口期=穩(wěn)定窗口期*panic-window-percentage(panic-window-percentage取值是0~1,默認是0.1)。當(dāng)請求突然增加導(dǎo)致當(dāng)前Pod的使用率超過恐慌窗口百分比時,KPA會快速增加Pod的數(shù)量以滿足負載需求。
在KPA中,彈性生效的判斷是基于恐慌模式下計算得出的Pod數(shù)量是否超過恐慌閾值(PanicThreshold)。恐慌閾值=panic-threshold-percentage/100,panic-threshold-percentage默認為200,即恐慌閾值默認為2。
綜上所述,如果在恐慌模式下計算得出的Pod數(shù)量大于或等于當(dāng)前Ready Pod數(shù)量的兩倍,那么KPA將使用恐慌模式下計算得出的Pod數(shù)量進行彈性生效;否則,將使用穩(wěn)定模式下計算得出的Pod數(shù)量。
KPA配置介紹
config-autoscaler配置介紹
配置KPA,需要配置config-autoscaler,該參數(shù)默認已配置,以下為重點參數(shù)介紹。
執(zhí)行以下命令,查看config-autoscaler。
kubectl -n knative-serving describe cm config-autoscaler預(yù)期輸出(config-autoscaler默認的ConfigMap):
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
# 默認Pod最大并發(fā)數(shù),默認值為100。
container-concurrency-target-default: "100"
# 并發(fā)數(shù)目標(biāo)使用率。默認值為70,70實際表示0.7。
container-concurrency-target-percentage: "70"
# 默認每秒請求數(shù)(RPS)。默認值為200。
requests-per-second-target-default: "200"
# 突發(fā)請求容量參數(shù)主要是為了應(yīng)對突發(fā)流量,以防止Pod業(yè)務(wù)容器被過載。當(dāng)前默認值211。
# 它通過Activator作為請求緩沖區(qū),通過這個參數(shù)的計算結(jié)果,來調(diào)節(jié)是否請求通過Activator組件。
# 當(dāng)該值為0時,只有Pod縮容到0時,才切換到Activator。
# 當(dāng)該值大于0并且container-concurrency-target-percentage設(shè)置為100時,請求總是會通過Activator。
# 當(dāng)該值為-1,表示無限的請求突發(fā)容量。請求也總是會通過Activator。其他負值無效。
# 如果當(dāng)前Ready Pod數(shù)*最大并發(fā)數(shù)-突發(fā)請求容量-恐慌模式計算出來的并發(fā)數(shù)<0,意味著突發(fā)流量超過了容量閾值,則切換到Activator進行請求緩沖。
target-burst-capacity: "211"
# 穩(wěn)定窗口,默認值為60秒。
stable-window: "60s"
# 恐慌窗口比例,默認值為10,則表示默認恐慌窗口期為6秒(60*0.1=6)。
panic-window-percentage: "10.0"
# 恐慌閾值比例,默認值200。
panic-threshold-percentage: "200.0"
# 最大擴縮容速率,表示一次擴容最大數(shù)。實際計算方式:math.Ceil(MaxScaleUpRate*readyPodsCount) 。
max-scale-up-rate: "1000.0"
# 最大縮容速率,默認值為2,表示每次縮容一半。
max-scale-down-rate: "2.0"
# 是否開始縮容到0,默認開啟。
enable-scale-to-zero: "true"
# 優(yōu)雅縮容到0的時間,即延遲多久縮容到0,默認30秒。
scale-to-zero-grace-period: "30s"
# Pod縮容到0保留期,該參數(shù)適用于Pod啟動成本較高的情況
scale-to-zero-pod-retention-period: "0s"
# 彈性插件類型,當(dāng)前支持的彈性插件包括:KPA、HPA、AHA以及MPA(ACK Serverless集群中配合MSE支持縮容到0)。
pod-autoscaler-class: "kpa.autoscaling.knative.dev"
# activator請求容量。
activator-capacity: "100.0"
# 創(chuàng)建revision時,初始化啟動的Pod數(shù),默認1。
initial-scale: "1"
# 是否允許創(chuàng)建revision時,初始化0個Pod, 默認false,表示不允許。
allow-zero-initial-scale: "false"
# revision級別最小保留的Pod數(shù)量。默認0,表示最小值可以為0。
min-scale: "0"
# revision級別最大擴容的Pod數(shù)量。默認0,表示無最大擴容上限。
max-scale: "0"
# 表示延遲縮容時間。默認0,表示立即縮容。
scale-down-delay: "0s"指標(biāo)配置介紹
可以通過autoscaling.knative.dev/metric注解為每個Revision配置指標(biāo),不同的彈性插件支持的指標(biāo)配置不同。
支持的指標(biāo):
"concurrency"、"rps"、"cpu"、"memory"以及其他自定義指標(biāo)。默認指標(biāo):
"concurrency"。
Concurrency并發(fā)數(shù)指標(biāo)配置
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: "concurrency"每秒請求數(shù)(RPS)指標(biāo)配置
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: "rps"CPU指標(biāo)配置
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev"
autoscaling.knative.dev/metric: "cpu"Memory指標(biāo)配置
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev"
autoscaling.knative.dev/metric: "memory"目標(biāo)閾值配置介紹
可以通過autoscaling.knative.dev/target注解為每一個Revision配置目標(biāo)閾值。通過container-concurrency-target-default注解為Configmap全局配置目標(biāo)閾值。
Revision級別配置
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "50"全局配置
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200"縮容到0配置介紹
通過全局配置是否縮容到0
enable-scale-to-zero參數(shù)可取值為"false"或"true",用于指定Knative服務(wù)在空閑時是否自動縮減為零副本。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
enable-scale-to-zero: "false" # 值被設(shè)置為"false",表示自動縮容功能被禁用,即Knative服務(wù)在空閑時不會自動縮減為零副本。全局配置優(yōu)雅縮容到0的時間
scale-to-zero-grace-period參數(shù)用于指定Knative服務(wù)在縮減為零副本之前的等待時間。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-grace-period: "40s"Pod縮容到0保留期
Revision級別配置
autoscaling.knative.dev/scale-to-zero-pod-retention-period注解用于配置Knative服務(wù)的自動縮容功能,指定在服務(wù)空閑一段時間后保留的Pod的時間周期。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m5s" spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56全局級別配置
scale-to-zero-pod-retention-period的配置項用于指定Knative服務(wù)在縮減為零副本之前保留的Pod的時間周期。apiVersion: v1 kind: ConfigMap metadata: name: config-autoscaler namespace: knative-serving data: scale-to-zero-pod-retention-period: "42s"
并發(fā)數(shù)配置介紹
并發(fā)數(shù)表示單個Pod能同時處理的最大請求數(shù)量。可以通過并發(fā)軟限制配置、并發(fā)硬限制配置、目標(biāo)使用率配置、每秒請求數(shù)(RPS)配置來設(shè)置并發(fā)數(shù)。
并發(fā)軟限制配置
并發(fā)軟限制是有針對性的限制,而不是嚴(yán)格執(zhí)行的界限。在某些情況下,特別是請求突然爆發(fā)時,可能會超過該值。
Revision級別配置
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/target: "200"全局級別配置
apiVersion: v1 kind: ConfigMap metadata: name: config-autoscaler namespace: knative-serving data: container-concurrency-target-default: "200" # 指定Knative服務(wù)的默認容器并發(fā)目標(biāo)。
并發(fā)硬限制配置(Revision級別)
僅當(dāng)您的應(yīng)用程序有明確的執(zhí)行并發(fā)上限時,才建議使用硬限制配置。因為指定較低的硬限制可能會對應(yīng)用程序的吞吐量和延遲產(chǎn)生負面影響。
并發(fā)硬限制是強制上限。如果并發(fā)達到硬限制,多余的請求將被緩沖,直到有足夠的可用資源來執(zhí)行請求。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
spec:
containerConcurrency: 50目標(biāo)使用率
使用目標(biāo)利用率值調(diào)整并發(fā)值,該值指定Autoscaler實際目標(biāo)值的百分比。這也稱為資源預(yù)熱,可以在請求達到定義的硬限制之前進行擴容。
例如,containerConcurrency設(shè)置為10,目標(biāo)利用率值設(shè)置為70(百分比),則當(dāng)所有現(xiàn)有Pod的平均并發(fā)請求數(shù)達到7時,Autoscaler將創(chuàng)建一個新Pod。因為Pod從創(chuàng)建到Ready需要一定的時間,通過降低目標(biāo)利用率值可以提前擴容Pod,從而減少冷啟動導(dǎo)致的響應(yīng)延遲等問題。
Revision級別配置
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/target-utilization-percentage: "70" # 配置Knative服務(wù)的自動縮放功能,指定了目標(biāo)資源利用率的百分比。 spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56全局級別配置
apiVersion: v1 kind: ConfigMap metadata: name: config-autoscaler namespace: knative-serving data: container-concurrency-target-percentage: "70" # Knative將盡量確保每個Pod的并發(fā)數(shù)不超過當(dāng)前可用資源的70%。
每秒請求數(shù)(RPS)配置
RPS表示單個Pod每秒能處理的請求數(shù)。
Revision級別配置
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/target: "150" autoscaling.knative.dev/metric: "rps" # 表示服務(wù)的自動縮放將根據(jù)每秒請求數(shù)(RPS)來調(diào)整副本數(shù)。 spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56全局級別配置
apiVersion: v1 kind: ConfigMap metadata: name: config-autoscaler namespace: knative-serving data: requests-per-second-target-default: "150"
場景一:設(shè)置并發(fā)請求數(shù)實現(xiàn)自動擴縮容
設(shè)置并發(fā)請求數(shù),通過KPA實現(xiàn)自動擴縮容。
為集群部署Knative,具體操作,請參見在ACK集群中部署Knative、在ACK Serverless集群中部署Knative。
創(chuàng)建autoscale-go.yaml。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" # 設(shè)置當(dāng)前最大并發(fā)請求數(shù)為10。 spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1執(zhí)行以下命令,部署autoscale-go.yaml。
kubectl apply -f autoscale-go.yaml獲取服務(wù)訪問網(wǎng)關(guān)。
ALB
執(zhí)行以下命令,獲取服務(wù)訪問網(wǎng)關(guān)。
kubectl get albconfig knative-internet預(yù)期輸出:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
執(zhí)行以下命令,獲取服務(wù)訪問網(wǎng)關(guān)。
kubectl -n knative-serving get ing stats-ingress預(yù)期輸出:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
執(zhí)行以下命令,獲取服務(wù)訪問網(wǎng)關(guān)。
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"預(yù)期輸出:
121.XX.XX.XXKourier
執(zhí)行以下命令,獲取服務(wù)訪問網(wǎng)關(guān)。
kubectl -n knative-serving get svc kourier預(yù)期輸出:
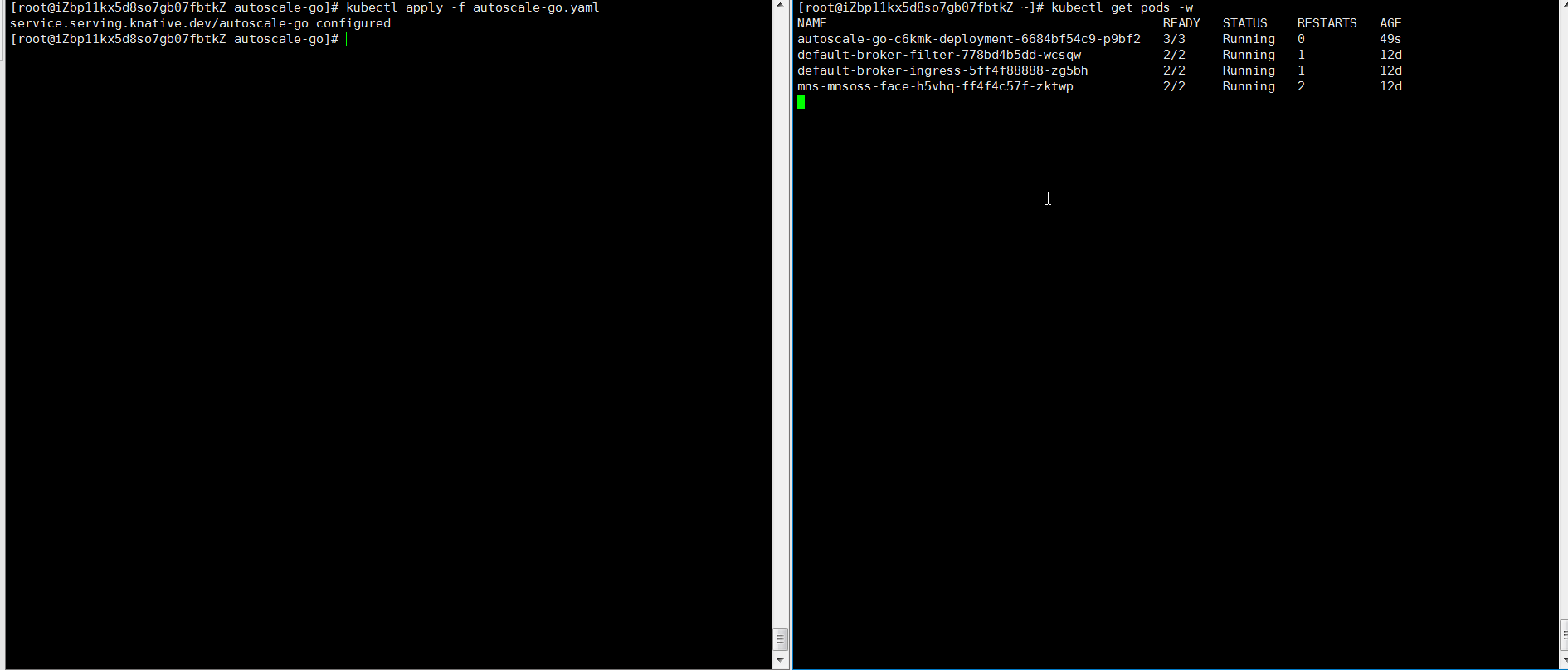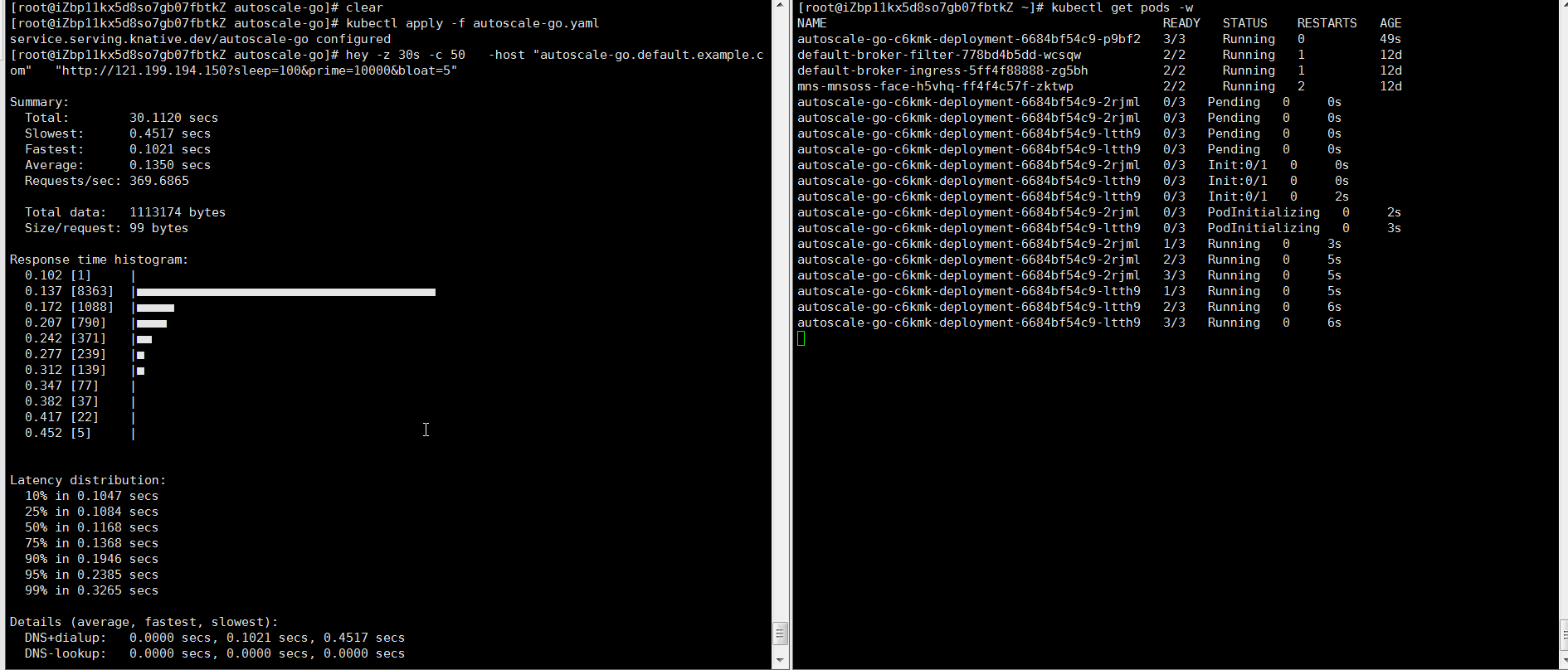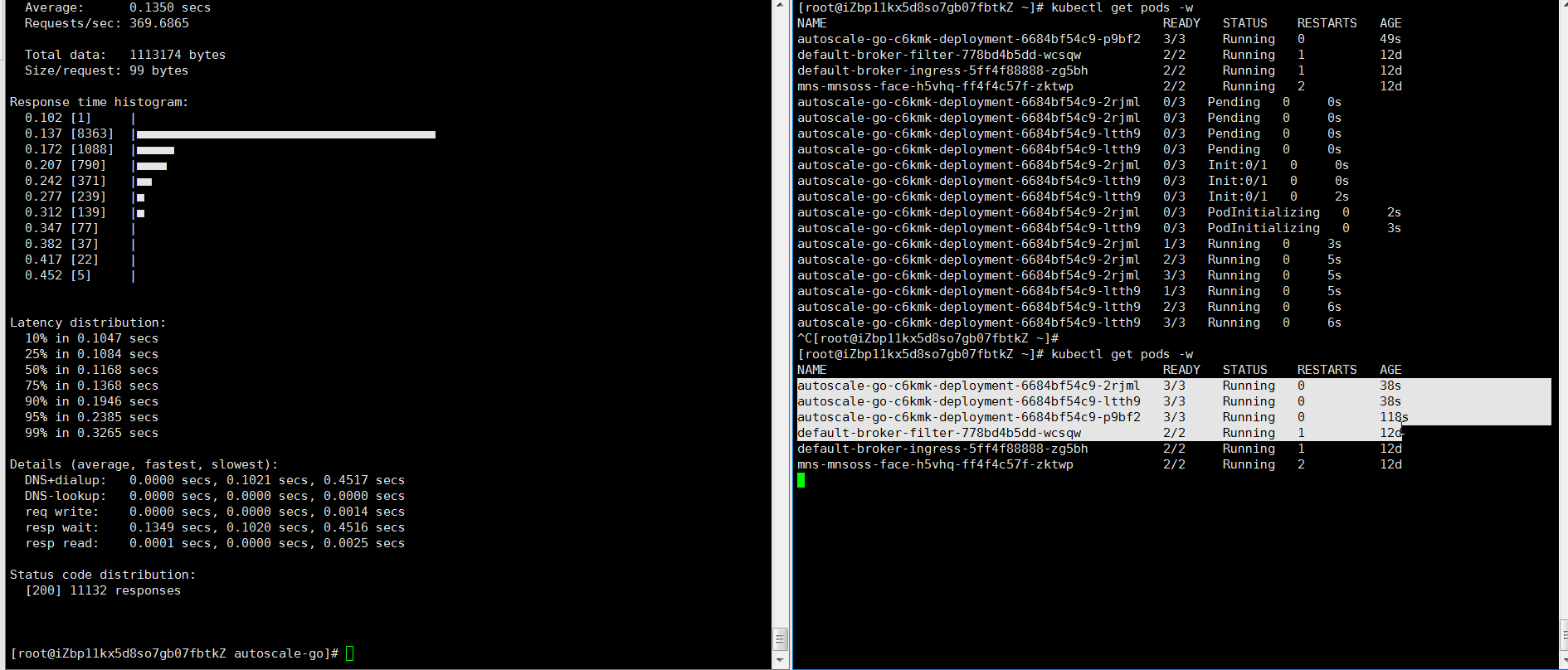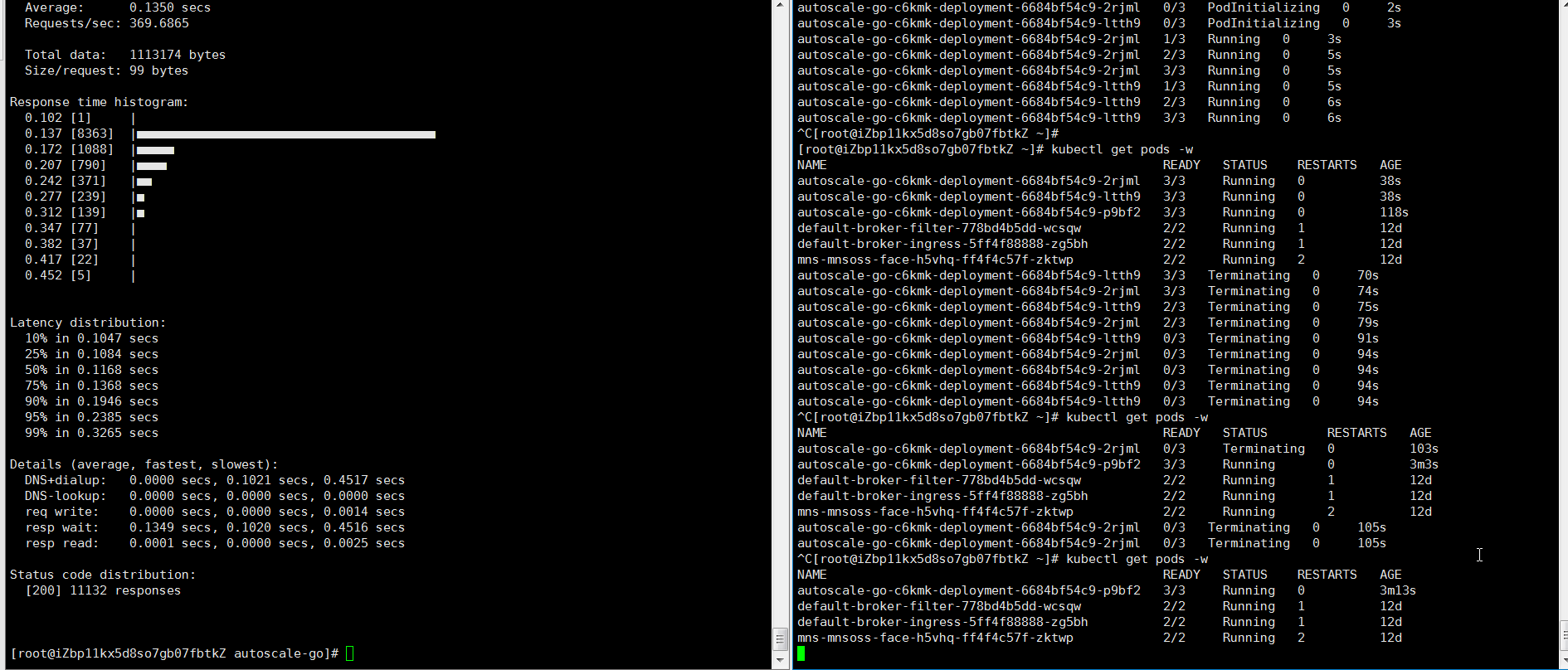
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49m使用Hey壓測工具,執(zhí)行30s內(nèi)保持50個并發(fā)請求。
說明Hey壓測工具的詳細介紹,請參見Hey。
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX?sleep=100&prime=10000&bloat=5" # 121.199.XXX.XXX為網(wǎng)關(guān)IP。預(yù)期輸出:
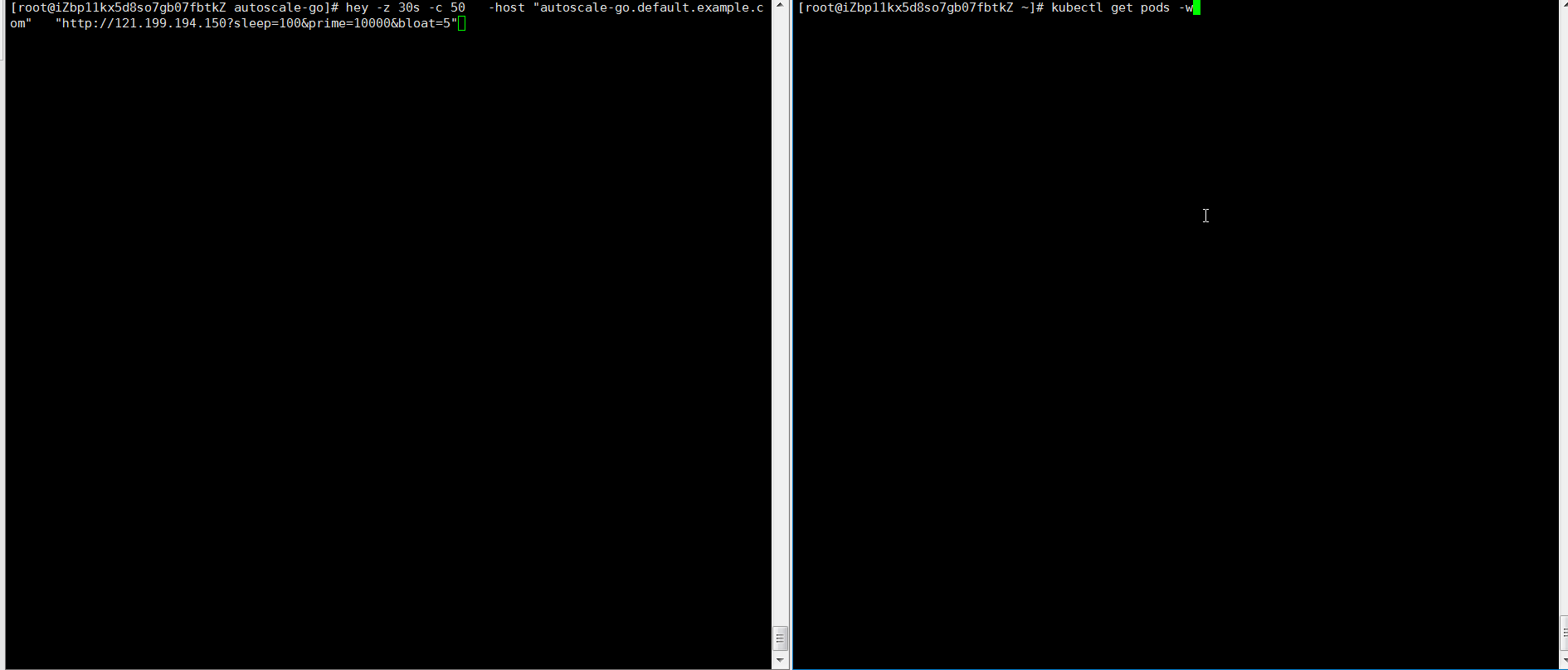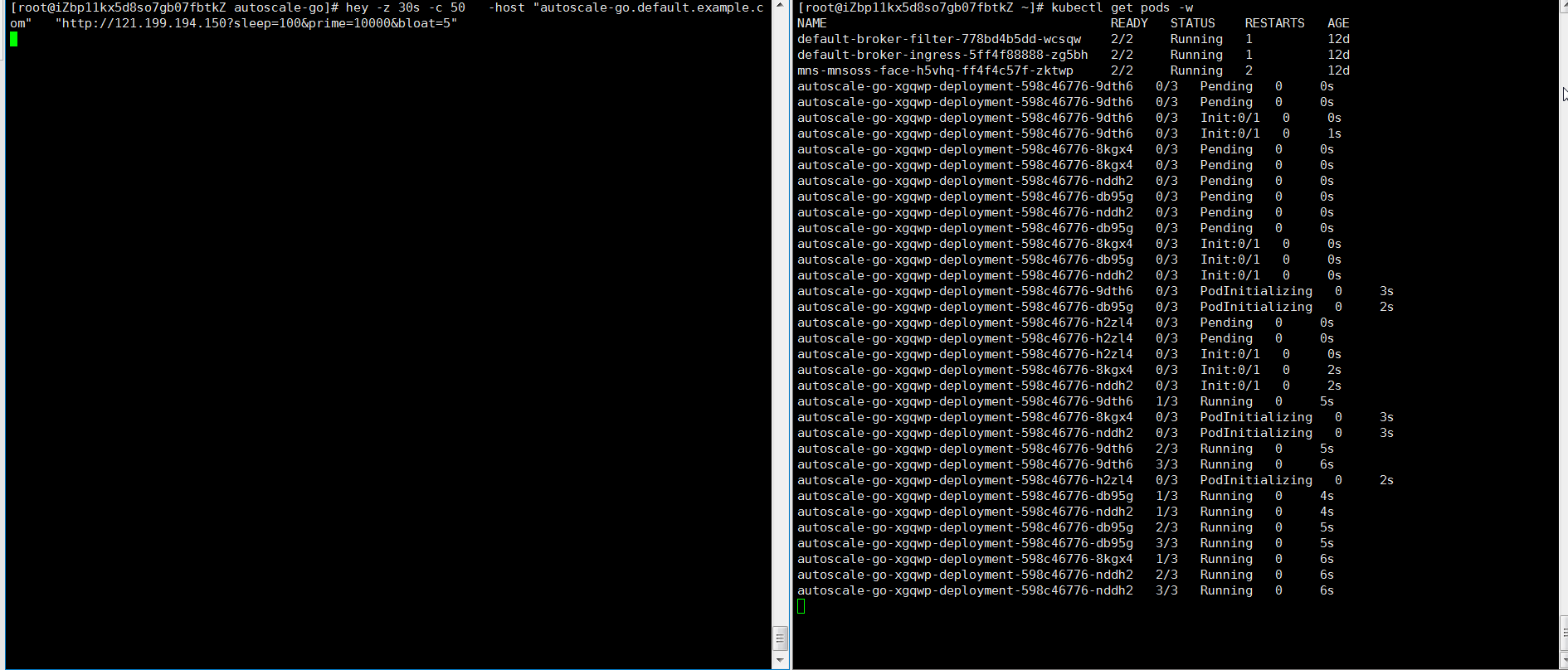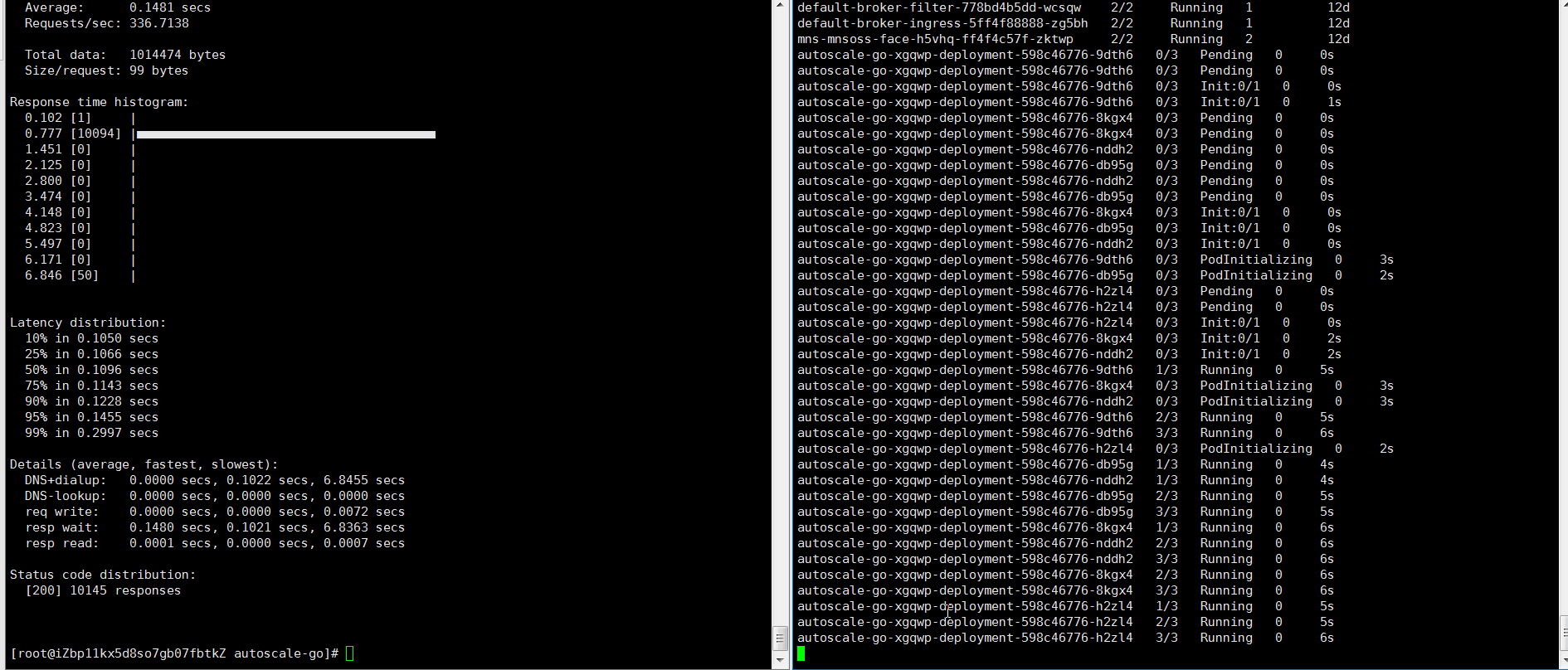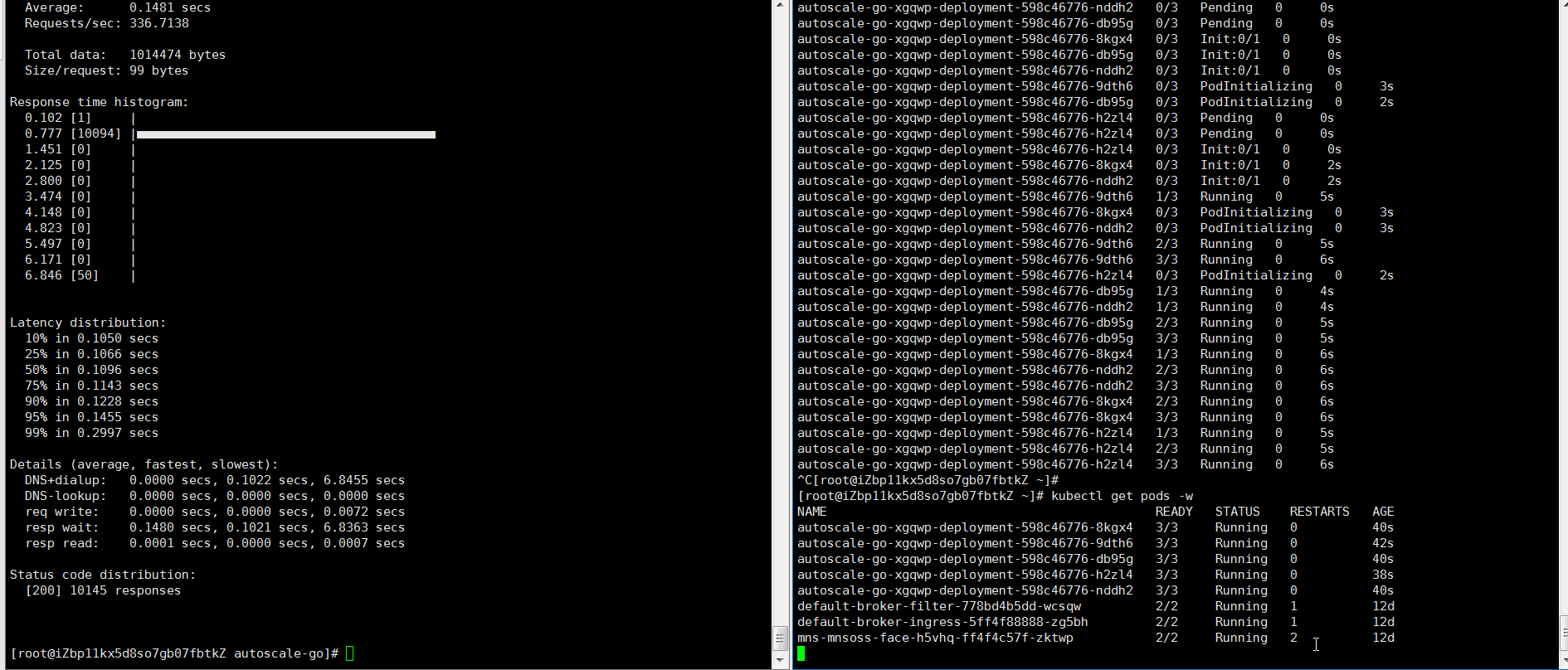
結(jié)果正如所預(yù)期的,擴容了5個Pod。
場景二:設(shè)置擴縮容邊界實現(xiàn)自動擴縮容
擴縮容邊界指應(yīng)用程序提供服務(wù)的最小和最大Pod數(shù)量。通過設(shè)置應(yīng)用程序提供服務(wù)的最小和最大Pod數(shù)量實現(xiàn)自動擴縮容。
為集群部署Knative,具體操作,請參見在ACK集群中部署Knative、在ACK Serverless集群中部署Knative。
創(chuàng)建autoscale-go.yaml。
設(shè)置最大并發(fā)請求數(shù)為10,
min-scale最小保留實例數(shù)為1,max-scale最大擴容實例數(shù)為3。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" autoscaling.knative.dev/min-scale: "1" autoscaling.knative.dev/max-scale: "3" spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1執(zhí)行以下命令,部署autoscale-go.yaml。
kubectl apply -f autoscale-go.yaml獲取服務(wù)訪問網(wǎng)關(guān)。
ALB
執(zhí)行以下命令,獲取服務(wù)訪問網(wǎng)關(guān)。
kubectl get albconfig knative-internet預(yù)期輸出:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
執(zhí)行以下命令,獲取服務(wù)訪問網(wǎng)關(guān)。
kubectl -n knative-serving get ing stats-ingress預(yù)期輸出:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
執(zhí)行以下命令,獲取服務(wù)訪問網(wǎng)關(guān)。
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"預(yù)期輸出:
121.XX.XX.XXKourier
執(zhí)行以下命令,獲取服務(wù)訪問網(wǎng)關(guān)。
kubectl -n knative-serving get svc kourier預(yù)期輸出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49m使用Hey壓測工具,執(zhí)行30s內(nèi)保持50個并發(fā)請求。
說明Hey壓測工具的詳細介紹,請參見Hey。
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX為網(wǎng)關(guān)IP。預(yù)期輸出:
結(jié)果正如所預(yù)期,最多擴容出來了3個Pod,并且即使在無訪問請求流量的情況下,保持了1個運行的Pod。