kube-controller-manager組件監(jiān)控指標(biāo)及大盤(pán)使用說(shuō)明
kube-controller-manager是管理多種Kubernetes控制器的控制面組件,例如負(fù)責(zé)節(jié)點(diǎn)管理的Node Controller、管理有狀態(tài)應(yīng)用的控制器StatefulSet Controller、處理無(wú)狀態(tài)應(yīng)用的Deployment Controller等。本文介紹kube-controller-manager組件的指標(biāo)清單和對(duì)應(yīng)大盤(pán)的使用指導(dǎo)。
相關(guān)概念
Workqueue
kube-controller-manager管理的Controller,例如Node Controller、StatefulSet Controller、Deployment Controller等,通常通過(guò)工作隊(duì)列Workqueue機(jī)制來(lái)安全、并發(fā)地處理資源對(duì)象的更新。每當(dāng)有新的事件發(fā)生時(shí)(例如Pod的創(chuàng)建、更新、刪除等),相應(yīng)的Controller會(huì)收到事件通知,將關(guān)聯(lián)的資源標(biāo)識(shí)符(例如Pod的名稱、命名空間等)放入Workqueue中。Controller的工作循環(huán)會(huì)不斷從Workqueue中取出這些資源標(biāo)識(shí)符,并執(zhí)行相應(yīng)的邏輯來(lái)處理資源。
使用前須知
操作入口
請(qǐng)參見(jiàn)查看集群控制面組件監(jiān)控大盤(pán)。
指標(biāo)清單
指標(biāo)是組件對(duì)外透出狀態(tài)和參數(shù)的方式之一,kube-controller-manager組件使用的指標(biāo)清單如下。
指標(biāo) | 類型 | 說(shuō)明 |
workqueue_adds_total | Counter | Workqueue處理的新增事件(Adds)數(shù)量。 |
workqueue_depth | Gauge | Workqueue當(dāng)前隊(duì)列深度。如果隊(duì)列深度長(zhǎng)時(shí)間保持在較高水平,表明Controller不能及時(shí)處理隊(duì)列中的任務(wù),導(dǎo)致任務(wù)堆積。 |
workqueue_queue_duration_seconds_bucket | Histogram | 任務(wù)在Workqueue中存在的時(shí)長(zhǎng)。Bucket閾值為{10-8, 10-7, 10-6, 10-5, 10-4, 10-3, 10-2, 10-1, 1, 10}。單位:秒。 |
memory_utilization_byte | Gauge | 內(nèi)存使用量。單位:字節(jié)(Byte)。 |
cpu_utilization_core | Gauge | CPU使用量。單位:核(Core)。 |
rest_client_requests_total | Counter | 從狀態(tài)值(Status Code)、方法(Method)和主機(jī)(Host)維度分析HTTP請(qǐng)求次數(shù)。 |
rest_client_request_duration_seconds_bucket | Histogram | 從方法(Verb)和URL維度分析HTTP請(qǐng)求時(shí)延。 |
如下資源使用率指標(biāo)已廢棄,請(qǐng)及時(shí)去除依賴該指標(biāo)的告警和監(jiān)控。
cpu_utilization_ratio:CPU使用率。
memory_utilization_ratio:內(nèi)存使用率。
大盤(pán)使用指導(dǎo)
您可以配置大盤(pán)觀測(cè)請(qǐng)求的分位數(shù)quantile和PromQL的采樣時(shí)長(zhǎng)interval。大盤(pán)基于組件指標(biāo)和相關(guān)PromQL繪制,大盤(pán)的可觀測(cè)性展示和功能解析如下。
Workqueue
可觀測(cè)性展示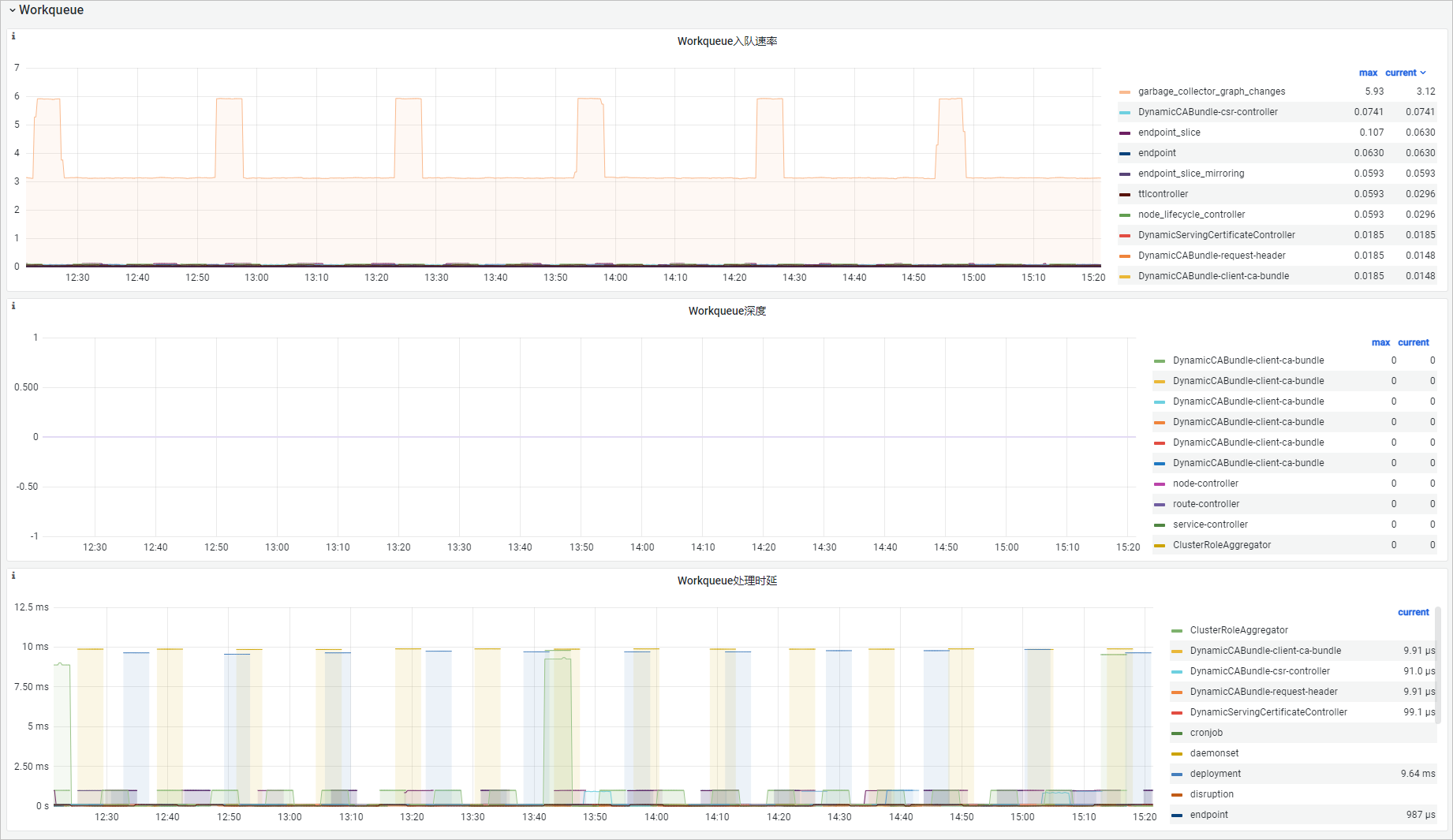
功能解析
名稱 | PromQL | 說(shuō)明 |
Workqueue入隊(duì)速率 | sum(rate(workqueue_adds_total{job="ack-kube-controller-manager"}[$interval])) by (name) | Workqueue在單位時(shí)間內(nèi)新增事件(Adds)的數(shù)量。 |
Workqueue深度 | sum(rate(workqueue_depth{job="ack-kube-controller-manager"}[$interval])) by (name) | Workqueue深度在單位時(shí)間內(nèi)的變化。 |
Workqueue處理時(shí)延 | histogram_quantile($quantile, sum(rate(workqueue_queue_duration_seconds_bucket{job="ack-kube-controller-manager"}[5m])) by (name, le)) | 事件在Workqueue中存在的時(shí)長(zhǎng)。 |
資源
可觀測(cè)性展示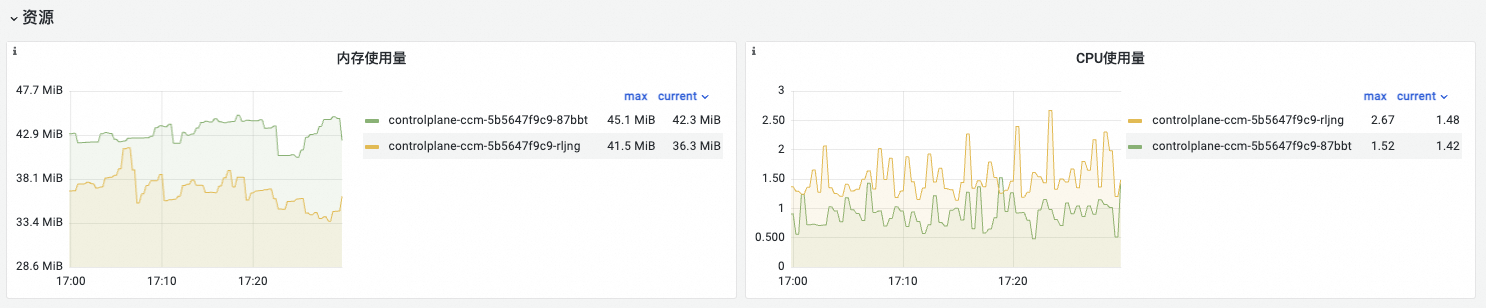
功能解析
大盤(pán)名稱 | PromQL | 說(shuō)明 |
內(nèi)存使用量 | memory_utilization_byte{container="kube-controller-manager"} | 內(nèi)存使用量。單位:字節(jié)。 |
CPU使用量 | cpu_utilization_core{container="kube-controller-manager"}*1000 | CPU使用量。單位:毫核。 |
Kube API
可觀測(cè)性展示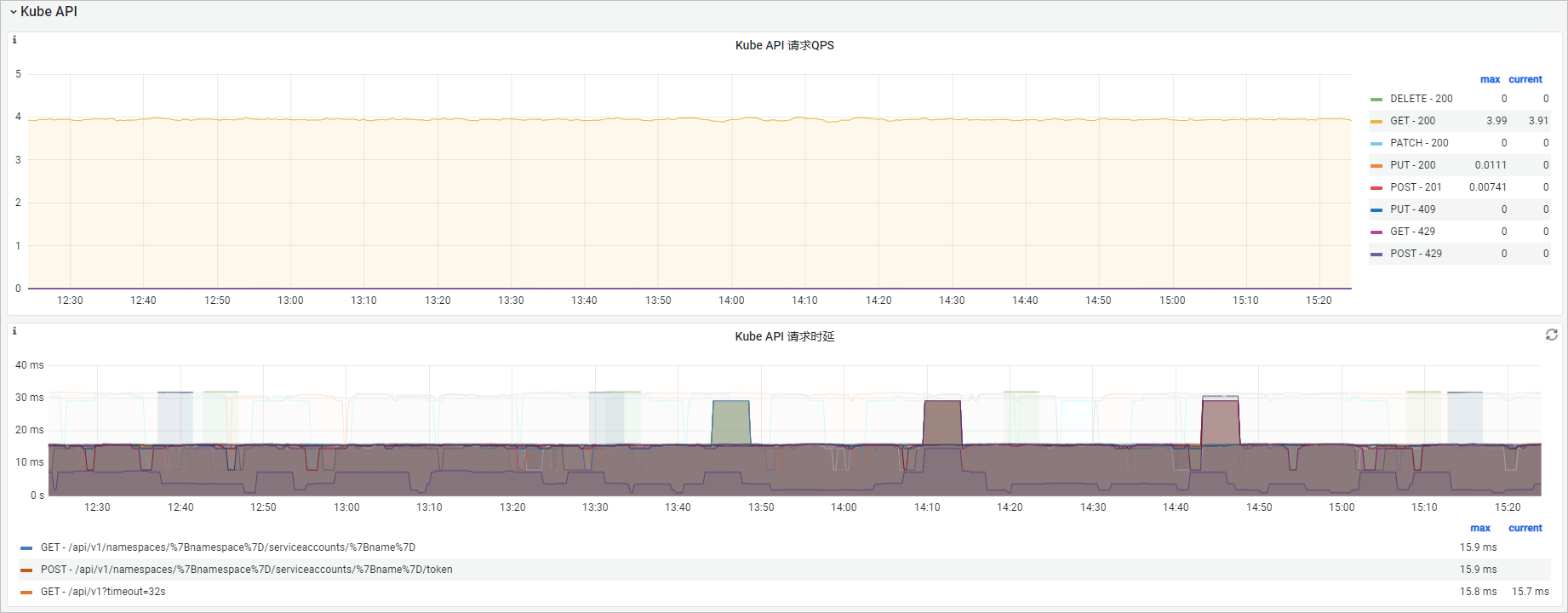
功能解析
大盤(pán)名稱 | PromQL | 說(shuō)明 |
Kube API請(qǐng)求QPS |
| kube-controller-manager對(duì)kube-apiserver發(fā)起的HTTP請(qǐng)求,從方法(Method)和返回值(Code)維度分析。 |
Kube API請(qǐng)求時(shí)延 | histogram_quantile($quantile, sum(rate(rest_client_request_duration_seconds_bucket{job="ack-kube-controller-manager"}[$interval])) by (verb,url,le)) | kube-controller-manager對(duì)kube-apiserver發(fā)起的HTTP請(qǐng)求時(shí)延,從方法(Verb)和請(qǐng)求URL維度進(jìn)行分析。 |
相關(guān)文檔
關(guān)于其他集群控制面組件監(jiān)控的指標(biāo)詳情、大盤(pán)使用指引和常見(jiàn)指標(biāo)異常說(shuō)明,請(qǐng)參見(jiàn)kube-apiserver組件監(jiān)控指標(biāo)說(shuō)明、etcd組件監(jiān)控指標(biāo)說(shuō)明、kube-scheduler組件監(jiān)控指標(biāo)說(shuō)明、cloud-controller-manager組件監(jiān)控指標(biāo)說(shuō)明。