通過共享GPU調(diào)度實現(xiàn)多卡共享
ACK集群Pro版支持共享GPU,共享GPU能夠在Kubernetes上實現(xiàn)共享GPU調(diào)度和顯存隔離。本文介紹如何設(shè)置共享GPU調(diào)度的多卡共享策略。
前提條件
多卡共享信息介紹
目前多卡共享僅支持顯存隔離且算力共享的場景,不支持顯存隔離且算力分配的場景。
模型開發(fā)階段,有可能需要使用多張GPU卡,但無需使用大量GPU資源。如果將多張GPU卡全部分配給開發(fā)平臺,有可能造成資源浪費。此時,共享GPU調(diào)度的多卡共享將發(fā)揮作用。
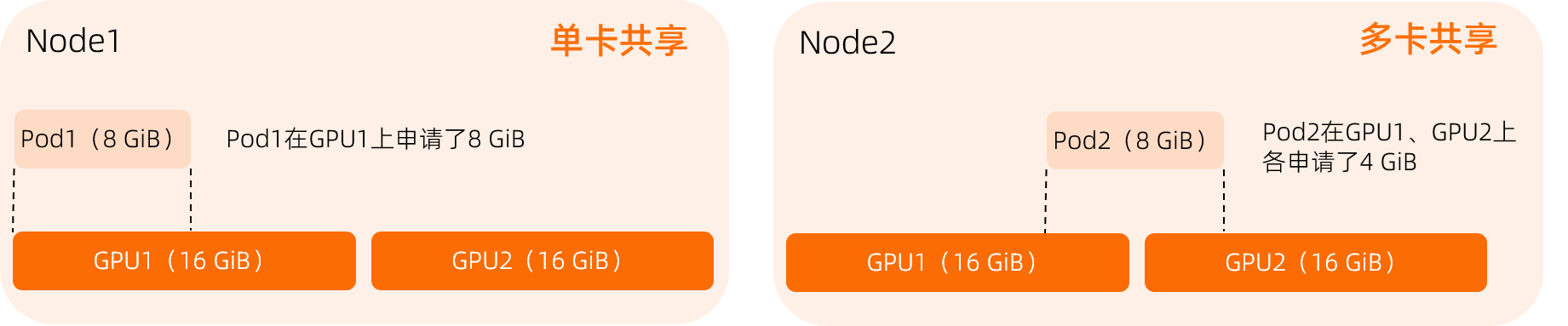
多卡共享策略指的是某個應(yīng)用申請了N個GiB的顯存,并指定了這N個GiB的顯存由M塊GPU卡分配,每塊GPU卡分配的顯存為N/M(目前N/M必須為整數(shù),并且這M張GPU卡必須在同一個Kubernetes節(jié)點上)。例如,某個應(yīng)用申請了8 GiB顯存,并指定了GPU卡個數(shù)為2,那么某個節(jié)點需分配2塊GPU卡給該應(yīng)用,每塊GPU卡分配4 GiB顯存。單卡共享和多卡共享的區(qū)別:
單卡共享:一個Pod僅申請一張GPU卡,占用該GPU部分資源。
多卡共享:一個Pod申請多張GPU卡,每張GPU提供部分資源,且每張GPU提供的資源量相同。
設(shè)置多卡共享策略
登錄容器服務(wù)管理控制臺,在左側(cè)導(dǎo)航欄選擇集群。
在集群列表頁面,單擊目標集群名稱,然后在左側(cè)導(dǎo)航欄,選擇。
在頁面右上角,單擊使用YAML創(chuàng)建資源。將以下內(nèi)容拷貝至模板區(qū)域,然后單擊創(chuàng)建。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-mnist-multigpu spec: parallelism: 1 template: metadata: labels: app: tensorflow-mnist-multigpu # 在Pod label中申明8 GiB顯存,由2塊GPU卡提供,每塊提供4 GiB顯存。 aliyun.com/gpu-count: "2" spec: containers: - name: tensorflow-mnist-multigpu image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - python - tensorflow-sample-code/tfjob/docker/mnist/main.py - --max_steps=100000 - --data_dir=tensorflow-sample-code/data resources: limits: aliyun.com/gpu-mem: 8 # 總共申請8 GiB顯存。 workingDir: /root restartPolicy: NeverYAML文件說明如下:
該YAML定義一個使用TensorFlow mnist樣例的Job,任務(wù)申請8 GiB顯存,并申請2張GPU卡,每張GPU卡將提供4 GiB顯存。
申請2張GPU卡通過在Pod Label定義標簽
aliyun.com/gpu-count=2實現(xiàn)。申請8 GiB顯存通過在Pod resources.limits定義
aliyun.com/gpu-mem: 8實現(xiàn)。
驗證多卡共享策略
在集群列表頁面,單擊目標集群名稱,然后在左側(cè)導(dǎo)航欄,選擇。
在創(chuàng)建的容器所在行,例如tensorflow-mnist-multigpu-***,單擊操作列的終端,進入容器,執(zhí)行如下命令。
nvidia-smi預(yù)期輸出:
Wed Jun 14 03:24:14 2023 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.161.03 Driver Version: 470.161.03 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:09.0 Off | 0 | | N/A 38C P0 61W / 300W | 569MiB / 4309MiB | 2% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ | 1 Tesla V100-SXM2... On | 00000000:00:0A.0 Off | 0 | | N/A 36C P0 61W / 300W | 381MiB / 4309MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| +-----------------------------------------------------------------------------+預(yù)期輸出表明,容器內(nèi)部僅能夠使用2張GPU卡,每張卡的總顯存均為4309 MiB(也就是申請的4 GiB顯存,而每張卡真實顯存為16160 MiB)。
在創(chuàng)建的容器所在行,例如tensorflow-mnist-multigpu-***,單擊操作列的日志,查看容器日志,可以看到如下關(guān)鍵信息。
totalMemory: 4.21GiB freeMemory: 3.91GiB totalMemory: 4.21GiB freeMemory: 3.91GiB關(guān)鍵信息表明,應(yīng)用查詢到的設(shè)備信息中,每張卡的總顯存為4 GiB左右,而不是每張卡真實顯存16160 MiB,也就是應(yīng)用使用的顯存已被隔離。