容器智能運維平臺提供Pod診斷功能,幫助您診斷異常的Pod信息。本文介紹Pod診斷的檢查項以及對應的修復方案。
容器智能運維平臺構建了基于專家經驗的故障診斷系統,并基于海量數據訓練了AI智能故障診斷模型。Pod診斷融合了基于專家經驗和AI智能診斷兩種診斷模式,進一步深入定位問題根因。Pod診斷包括診斷檢查項和診斷根因。
診斷檢查項:包括Pod檢查、Node檢查、NodeComponent檢查、ClusterComponent檢查、ECSControllerManager檢查。
診斷根因:包括定位到的根因以及修復建議。Pod診斷會收集部分集群和節點信息并識別其中的異常,然后根據識別到的異常進行深入的異常診斷。
使用故障診斷功能時,系統將在您的集群節點上執行數據采集程序并收集檢查結果。采集的信息包括系統版本,以及負載、Docker、Kubelet等運行狀態及系統日志中關鍵錯誤信息。數據采集程序不會采集您的業務信息及敏感數據。
診斷支持的異常場景
Pod診斷覆蓋的典型異常場景和AI智能診斷支持場景如下表所示。
類別 | 支持的異常場景 |
Pod診斷 | Pod未被調度器處理。 |
Pod不滿足調度約束無法被調度。 | |
Pod已調度但未被Kubelet處理。 | |
Pod等待存儲卷就緒。 | |
Pod被驅逐。 | |
Pod因節點磁盤空間不足被驅逐。 | |
Pod因節點內存不足被驅逐。 | |
Pod因節點磁盤索引不足被驅逐。 | |
Pod的Sandbox容器創建失敗。 | |
Pod長期處于terminating狀態。 | |
Pod中容器發生OOM異常。 | |
Pod中容器異常退出。 | |
Pod中容器處于CrashLoopBackOff狀態。 | |
Pod中容器NotReady。 | |
Pod拉取鏡像出錯。 | |
Pod拉取鏡像超時。 | |
AI智能診斷 | Pod狀態異常。 |
Pod發生OOM異常。 | |
Pod容器異常退出。 | |
Pod ConfigMap或Secret配置異常。 | |
Pod健康檢查失敗。 | |
Pod PVC配置異常。 | |
Pod鏡像拉取異常。 |
診斷流程
集群診斷收集部分集群和節點信息并識別其中的異常,然后根據識別到的異常進行深入的異常診斷。診斷融合了基于專家經驗和AI智能診斷兩種診斷模式,進一步深入定位問題根因。發起診斷后,診斷會按照異常識別、數據采集、檢查項評估以及根因分析四個階段,完成后給出診斷結果。
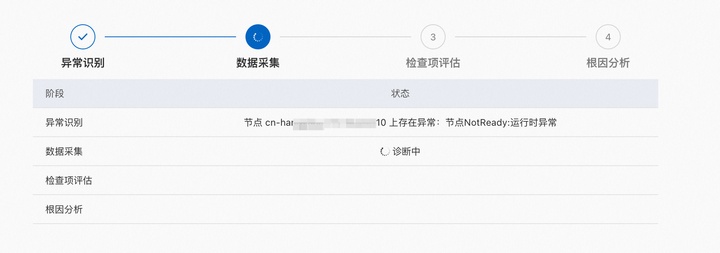
異常識別:采集基本數據,例如Node狀態、Pod狀態、集群Event事件流等,并快速分析當前的異常。
數據采集:根據異常識別結果采集和診斷上下文相關的數據。例如,節點診斷采集節點在K8s中的信息、節點對應的ECS信息、節點內Docker、Kubelet等進程運行狀態信息。
檢查項評估:根據采集到的數據,判斷關鍵指標是否正常。例如,節點診斷檢查項包括Docker進程狀態、ECS狀態等。不同的診斷類型對應不同的檢查項,并將針對檢查結果提供對應的檢查項列表和每個檢查項的含義。
根因分析:根據采集的數據和檢查項,部分問題可自動分析導致問題的原因。
診斷結果
診斷結果包括根因結果與檢查項。根因診斷結果部分包括識別到的異常、異常根因和修復建議。檢查項則按不同的類別對可能引起異常的點進行檢查,覆蓋根因未包括的部分,并對異常原因進一步補充。
根據集群配置,具體檢查項可能稍有不同。實際結果請以診斷頁面結果為準。
Pod診斷對應的檢查項
診斷項分組 | 說明 |
檢查Pod常見問題,檢查項包括Pod狀態、鏡像拉取、網絡連通性等。 | |
檢查節點實例常見問題,檢查項包括節點狀態、網絡狀態、內核日志、核心進程和服務可用性等。 | |
檢查節點核心組件狀態,檢查項包括網絡和存儲插件。 | |
檢查集群常見問題,檢查項包括API Service可用性、DNS可用性、NAT網關狀態等。 | |
檢查ECS實例常見問題,檢查項包括ECS實例狀態、網絡鏈路、操作系統、磁盤IO等。 |
Pod
檢查項名稱 | 檢查項說明 | 修復方案 |
Pod容器重啟次數統計 | 統計Pod中容器重啟次數。 | 請檢查Pod狀態及日志。更多信息,請參見Pod異常問題排查。 |
Pod容器鏡像下載阻塞情況 | 檢查Pod同節點是否有其他Pod的容器鏡像下載被阻塞。 | 請檢查Pod狀態及日志。更多信息,請參見Pod異常問題排查。 |
Pod容器鏡像Secrets有效性檢查 | 檢查Pod拉取鏡像的Secrets是否有效。 | 請檢查Pod狀態及日志。更多信息,請參見Pod異常問題排查。 |
GPU Pod的環境變量是否合法 | 檢查NVIDIA_VISIBLE_DEVICES是否位于Pod環境變量中,因為此變量可能與Kubelet沖突。 | 請檢查Pod狀態及日志。更多信息,請參見Pod異常問題排查。 |
Pod到CoreDNS Pods的連通性 | 檢查Pod到CoreDNS Pods連通性。 | 檢查Pod到CoreDNS Pods的連通性。 |
Pod到CoreDNS Service的連通性 | 檢查Pod到CoreDNS Service連通性。 | 檢查Pod到CoreDNS Pods的連通性。 |
Pod到主機網絡DNS服務器的連通性 | 檢查Pod到主機網絡DNS服務器的連通性。 | 檢查Pod到主機網絡DNS服務器的連通性。 |
Pod容器進程處于D狀態檢查 | 檢查Pod的容器進程是否處于D狀態。 | Pod的部分容器進程處于D狀態,通常為容器進程卡在磁盤IO中,請嘗試重啟宿主機ECS,如仍無法恢復,請提交工單處理。 |
Pod初始化狀態 | 檢查Pod是否正常初始化。 | 請檢查Pod狀態及日志。更多信息,請參見Pod異常問題排查。 |
Pod申請的GPU資源 | 檢查Pod是否申請GPU資源,排除因為未申請GPU資源導致的Pod無法使用GPU。 | 該Pod中沒有聲明GPU資源,如有需要,請檢查Pod配置是否規范。 |
Pod調度狀態 | 檢查Pod是否正常調度。 | 該Pod中沒有聲明GPU資源,如有需要,請檢查Pod配置是否規范。 |
Node
檢查項名稱 | 檢查項說明 | 修復方案 |
集群API Server連接狀態 | 檢查節點能否正常連接集群API Server。 | 請檢查集群相關配置。更多信息,請參見容器服務ACK集群故障排查。 |
節點AUFS mount hung情況 | 檢查節點系統AUFS mount是否出現hung。 | 節點系統出現AUFS mount hung問題,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點內核BufferIOError情況 | 檢查節點內核是否出現BufferIOError。 | 節點內核出現BufferIOError情況,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點cgroup泄露檢查 | 檢查節點是否出現cgroup泄露情況。 | 節點出現cgroup泄露情況,可能導致監控采集出錯,甚至導致容器無法啟動。請先嘗試登錄節點,刪除相應的cgroup目錄。若問題仍未解決,請提交工單處理。 |
節點Chronyd進程狀態 | 檢查節點Chronyd進程是否異常,該進程異常可能會影響系統時鐘同步。 | 節點Chronyd進程異常,可能影響節點系統時間同步。請嘗試通過命令 |
節點Containerd鏡像拉取狀態 | 檢查節點Containerd拉取鏡像是否正常。 | 請檢查節點網絡及鏡像配置。 |
節點Containerd狀態 | 檢查節點Containerd狀態。 | 節點Containerd狀態異常,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
集群CoreDNS Pod可用性 | 檢查節點能否正常訪問集群CoreDNS的Pod IP地址。 | 請檢查節點能否正常訪問CoreDNS的Pod IP地址。具體操作,請參見CoreDNS Pod負載不均。 |
節點鏡像狀態 | 檢查節點是否出現鏡像損壞。 | 節點鏡像出現損壞。請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點鏡像overlay2狀態 | 檢查節點是否出現鏡像overlay2文件系統損壞。 | 節點出現鏡像overlay2文件系統損壞,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點系統時間 | 檢查節點系統時間是否異常。 | 無。 |
節點Docker容器啟動狀態 | 檢查節點Docker容器是否出現啟動失敗。 | 節點Docker啟動狀態異常,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點Docker鏡像拉取狀態 | 檢查節點Docker拉取鏡像是否正常。 | 請檢查節點網絡及鏡像配置。 |
節點Docker狀態 | 檢查節點Dockerd狀態。 | 節點Docker狀態異常,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點Docker啟動時間 | 檢查節點Dockerd啟動時間。 | 無。 |
節點Docker hang情況 | 檢查節點是否出現Docker hang的情況。 | 請嘗試登錄節點,通過命令 |
ECS實例是否存在 | 檢查ECS實例是否存在。 | 檢查ECS實例狀態。更多信息,請參見節點與節點池FAQ。 |
ECS實例狀態 | 檢查ECS實例狀態。 | 檢查ECS實例狀態,更多信息,請參見節點與節點池FAQ。 |
節點內核Ext4FsError情況 | 檢查節點內核是否出現Ext4FsError。 | 節點內核出現Ext4FsError情況,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點文件系統只讀狀態 | 節點出現文件系統只讀,通常是因為磁盤故障,會導致節點無法寫入數據,可能造成業務異常。 | 請嘗試在節點上使用fsck命令修復文件系統,然后重啟節點。 |
節點硬件時間 | 檢查節點硬件時鐘與系統時間是否一致,時間相差超過2分鐘可能引起組件異常。 | 請嘗試登錄節點,通過命令 |
節點DNS服務 | 檢查節點能否正常使用主機DNS服務。 | 請檢查主機DNS服務是否正常。更多信息,請參見DNS解析異常問題排查。 |
節點內核Oops情況 | 檢查節點內核是否出現Oops。 | 節點內核出現Oops,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點內核版本 | 檢查節點內核版本是否過低,內核版本過低可能造成系統異常。 | 請嘗試更換節點升級內核。更多信息,請參見節點與節點池FAQ。 |
集群DNS服務可用性 | 檢查節點能否正訪問集群kube-dns服務的Cluster IP,正常使用集群的DNS服務。 | 請檢查CoreDNS Pod運行狀態和運行日志。更多信息,請參見DNS解析異常問題排查。 |
節點Kubelet狀態 | 檢查節點Kubelet狀態。 | 請檢查節點Kubelet日志。更多信息,請參見容器服務ACK集群故障排查。 |
節點Kubelet啟動時間 | 檢查節點Kubelet啟動時間。 | 無。 |
節點CPU使用率 | 檢查節點CPU負載是否過高。 | 無。 |
節點內存使用率 | 檢查節點內存負載是否過高。 | 無。 |
節點內存碎片化檢查 | 檢查節點是否出現內存碎片化。 | 節點出現內存碎片化,請先嘗試登錄節點,執行命令 |
節點內存交換區開啟情況 | 檢查節點內存交換區 (Memory Swap) 功能是否開啟。 | 當前節點內存交換區 (Memory Swap) 功能不支持開啟,請登錄節點關閉該功能。 |
節點網絡設備驅動加載情況 | 檢查節點的網絡設備virtio驅動加載情況。 | 節點的網絡設備出現virtio驅動加載異常,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點CPU水位過高 | 檢查節點過去一周CPU使用率。節點CPU水位過高時如部署較多Pod會導致資源爭搶,可能會影響業務的正常運行。 | 為避免業務受到影響,請設置合理的Pod request和limit,避免一個節點上運行的Pod過多。 |
節點內網IP是否存在 | 檢查節點內網IP是否存在。 | 節點內網IP不存在,請嘗試移除節點后重新導入,移除時需保留ECS。有關移除節點的操作,請參見移除節點。有關導入添加節點操作,請參見添加已有節點。 |
節點內存水位過高 | 檢查節點過去一周內存利用率。節點內存水位過高時如部署較多Pod會導致資源爭搶,可能產生OOM影響業務的正常運行。 | 為避免業務受到影響,請設置合理的Pod request和limit,避免一個節點上運行的Pod過多。 |
節點狀態 | 檢查集群節點狀態是否Ready。 | 請嘗試重啟節點。更多信息,請參見節點與節點池FAQ。 |
節點是否不可調度 | 檢查節點是否不可調度。 | 節點不可調度,請檢查節點調度設置。具體操作,請參見設置節點調度狀態。 |
節點OOM情況 | 檢查節點是否出現OOM。 | 節點出現OOM問題,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
集群運行時檢查 | 檢查節點運行時和集群運行時是否一致。 | 更多信息,請參見創建集群選擇了containerd容器運行時,是否可以改為Docker?。 |
節點OS版本過低 | 檢查是否使用已知缺陷的OS版本,操作系統版本過低,存在穩定性風險,可能導致Docker、Containerd等組件無法正常運行。 | 請及時更新操作系統版本。 |
節點公網訪問情況 | 檢查節點能否正常訪問公網。 | 請檢查集群是否開啟SNAT公網訪問。具體操作,請參見為已有集群開啟公網訪問能力。 |
節點內核RCUStallError情況 | 檢查節點內核是否出現RCUStallError。 | 節點內核出現RCUStallError情況,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點操作系統版本 | 檢查節點操作系統版本,系統版本過低可能造成集群功能異常。 | 無。 |
節點runc進程泄露情況 | 檢查節點runc進程是否發生泄露,runc進程泄露可能會導致節點間歇性地處于NotReady狀態。 | 節點runc進程泄露,請檢查并手動關閉泄露的runc進程。 |
節點內核SoftLockupError情況 | 檢查節點內核是否出現SoftLockupError。 | 節點內核出現SoftLockupError情況,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
節點Systemd hung情況 | 檢查節點是否出現Systemd hung情況。 | 節點出現Systemd hung異常,請嘗試登錄節點,通過命令 |
節點Systemd版本過低 | 檢查是否使用已知缺陷的Systemd版本。Systemd版本過低存在穩定性風險,可能導致docker/containerd等組件無法正常運行。 | 請及時更新Systemd版本。更多信息,請參見Systemd。 |
節點進程Hung情況 | 檢查節點進程是否出現Hung。 | 節點出現進程Hung問題,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
存在unregister_netdevice | 檢查內核是否出現unregister_netdevice。 | 節點存在unregister_netdevice問題,請收集節點日志并提交工單處理。關于收集節點日志操作,請參見一鍵采集節點的診斷日志。 |
NodeComponent
檢查項名稱 | 檢查項說明 | 修復方案 |
節點CNI組件狀態 | 檢查節點CNI組件是否正常。 | 請檢查集群網絡組件狀態。具體操作,請參見網絡管理FAQ。 |
節點CSI組件狀態 | 檢查節點CSI組件是否正常。 | 請檢查集群件存儲組件狀態。具體操作,請參見存儲FAQ-CSI。 |
ClusterComponent
檢查項名稱 | 檢查項說明 | 修復方案 |
集群免密插件版本檢查 | 檢查集群免密插件版本是否過低。 | 集群免密插件版本檢查過低,請盡快升級版本。具體操作,請參見使用免密組件拉取容器鏡像。 |
集群APIService可用狀態 | 檢查集群APIService是否可用。 | 請嘗試通過命令 |
集群Pod網段余量緊張 | 檢查Flannel集群剩余可用PodCIDR網段是否少于5個。每個節點消耗一個PodCIDR網段,Pod網段耗盡后,新添加的節點將無法正常工作。 | 請提交工單處理。 |
DNS 服務后端服務端點 | 檢查集群DNS服務Endpoints數。 | 請檢查CoreDNS Pod運行狀態和運行日志。更多信息,請參見DNS解析異常問題排查。 |
DNS 服務 ClusterIP | 檢查集群DNS服務的Cluster IP是否正常分配,集群DNS服務異常會造成集群功能異常,影響業務。 | 請檢查CoreDNS Pod運行狀態和運行日志。更多信息,請參見DNS解析異常問題排查。 |
集群NAT網關狀態 | 檢查集群NAT網關狀態。 | 請登錄NAT網關管理控制臺,檢查集群的NAT網關是否因欠費而處于欠費鎖定狀態。 |
集群NAT網關并發超規格丟棄速率 | 檢查NAT網關會話并發超規格丟棄速率是否過高。 | 集群NAT網關會話并發超規格丟棄速率過高,請嘗試通過升級NAT網關的規格解決該問題。更多信息,請參見普通型公網NAT網關升級至增強型公網NAT網關FAQ。 |
ECSControllerManager
檢查項名稱 | 檢查項說明 | 修復方案 |
ECS實例的組件欠費情況 | 檢查ECS實例的云盤或網絡帶寬是否因賬號欠費而無法正常使用。 | ECS實例的云盤或網絡帶寬因賬號欠費而無法正常使用,您需要充值進行恢復。更多信息,請參見續費概述。 |
ECS實例欠費情況 | 檢查按量計費的ECS實例是否因為欠費導致停服。 | ECS實例服務欠費,您需要充值后重新開機才能恢復實例。更多信息,請參見續費概述。 |
ECS實例網卡鏈路層狀態 | 檢查ECS實例網卡鏈路層是否出現異常。 | ECS實例未正常啟動或網絡配置有問題,您可以嘗試通過重啟實例進行恢復。 |
ECS實例啟動狀態 | 檢查ECS實例的boot操作是否能正常執行加載。 | ECS實例無法正常啟動,您需要創建一個新的實例。 |
ECS實例管控系統狀態 | 檢查ECS實例的后臺管控系統是否正常工作。 | 后臺管控系統未正常工作,可能會導致實例運行異常,您可以嘗試通過重啟實例進行恢復。 |
ECS實例CPU狀態 | 檢查ECS實例底層是否存在CPU爭搶或CPU綁定失敗。 | ECS實例存在CPU爭搶,可能導致實例無法獲得CPU或出現其他異常,您可以嘗試通過重啟實例進行恢復。 |
ECS實例CPU是否存在Split Lock問題 | 檢查ECS實例CPU是否存在Split Lock問題。 | ECS實例CPU出現Split Lock。更多信息,請參見Split lock檢測與處理。 |
ECS實例DDos攻擊的防護狀態 | 檢查該實例的IP地址是否受到了DDoS攻擊。 | ECS實例的IP遭受DDoS攻擊,您可以視情況購買其他DDoS防護產品抵御DDoS攻擊。更多信息,請參見阿里云DDoS防護方案對比。 |
ECS實例云盤讀寫受限情況 | 檢查實例云盤讀寫是否受限。 | ECS實例云盤讀寫IOPS超過上限讀寫受限,請您降低磁盤的讀寫頻率或升級為更高性能的云盤類型,有關云盤的讀寫性能指標,請參見塊存儲性能。 |
ECS實例磁盤加載情況 | 檢查ECS實例在啟動時云盤是否能正常掛載。 | 云盤掛載失敗,導致實例無法正常啟動,請停止實例后再次啟動實例。 |
ECS實例是否已到期 | 檢查以包年包月方式購買的ECS實例是否已到期。 | ECS實例服務到期,您需要續費來恢復服務。更多信息,請參見續費概述。 |
ECS實例操作系統Crash情況 | 檢查ECS實例內操作系統是否出現Crash。 | ECS實例的操作系統在過去48小時內出現了Crash情況,建議通過排查系統日志分析原因。具體操作,請參見查看實例的系統日志和屏幕截圖。 |
ECS實例所在宿主機狀態 | 檢查ECS實例所在的底層物理機是否有故障。 | ECS實例底層物理機存在故障,可能會影響實例的運行狀態或性能,您可以嘗試通過重啟實例進行恢復。 |
ECS實例鏡像加載狀態 | 檢查ECS實例在啟動時所使用的鏡像是否能正常加載。 | 鏡像可能因為系統原因、鏡像問題等加載失敗,您可以嘗試通過重啟實例進行恢復。 |
ECS實例磁盤IO hang情況 | 檢查ECS實例的系統盤是否存在IO hang的情況。 | ECS實例云盤出現IO hang,請查看云盤的性能指標。具體操作,請參見查看云盤監控信息。如果您使用的是Alibaba Cloud Linux 2操作系統,檢測IO hang的操作,請參見檢測文件系統和塊層的IO hang。 |
ECS實例網絡帶寬是否到達上限 | 檢查ECS實例網絡帶寬是否到達上限。 | ECS實例帶寬總量已超過實例規格對應的網絡基礎帶寬上限,請您將實例升級至網絡帶寬能力更高的實例規格。具體操作,請參見升降配方式概述。 |
ECS實例的突發網絡帶寬是否受限 | 檢查ECS實例的網絡突發帶寬是否受到限制。 | ECS實例突發網絡帶寬已超過實例規格對應的網絡突發帶寬上限,請您將實例升級至網絡帶寬能力更高的實例規格。具體操作,請參見升降配方式概述。 |
ECS實例網卡加載狀態 | 檢查ECS實例的網卡是否能正常加載。 | 如果網卡無法正常加載,將影響實例的網絡連通性,您可以嘗試通過重啟實例進行恢復。 |
ECS實例網卡會話建立檢查 | 檢查ECS實例的網卡是否能正常建立會話。 | 如果網卡無法建立會話或已建立的會話超過限制,將影響實例的網絡連通性或網絡吞吐,您可以嘗試通過重啟實例進行恢復。 |
ECS實例核心操作執行情況 | 檢查您對ECS實例最近執行的管理操作,例如,開機、關機、升配等是否執行成功。 | 您最近發起的管理操作,例如開機、關機、升配執行失敗,您需要重新發起該操作。 |
ECS實例網卡丟包檢查 | 檢查ECS實例的網卡入方向或出方向是否存在丟包現象。 | ECS實例發現網卡丟包現象,您可以嘗試通過重啟實例進行恢復。 |
ECS實例性能是否短暫受損 | 檢查實例是否存在因底層軟硬件問題導致的性能受損。 | 如果存在性能受損,會提示發生時間,請您檢查ECS實例的歷史系統事件或者系統日志進行確認。具體操作,請參見查看歷史系統事件。 |
ECS實例性能是否受限 | 檢查ECS實例性能是否受限。 | ECS實例的CPU積分不足以支付維持高性能所需的積分,只能使用基準性能。 |
ECS實例磁盤擴縮容情況 | 檢查ECS實例的系統盤擴縮容情況。 | ECS實例磁盤擴縮容后,操作系統調整文件系統的大小失敗。新擴縮容的磁盤無法使用,請重新發起擴縮容操作。 |
ECS實例資源申請 | 檢查ECS實例所需要的CPU、內存等物理資源是否充足。 | 物理資源不足導致實例無法啟動,您可以等待幾分鐘后重新嘗試開機,或者在其他地域或可用區嘗試重新創建實例。 |
ECS實例操作系統狀態 | 檢查ECS實例的操作系統是否存在內核Panic、OOM異常或內部宕機等故障。 | 此類故障可能是由于ECS實例配置不當或用戶空間的程序配置不當導致的,您可以嘗試通過重啟實例進行恢復。 |
ECS實例虛擬化狀態 | 檢查ECS實例底層虛擬化層核心服務是否出現異常。 | 出現此類異常可能會導致ECS實例崩潰或出現異常暫停,您可以嘗試通過重啟實例進行恢復。 |