本文介紹關于Nginx Ingress異常問題的診斷流程、排查思路、常見檢查方法和解決方案。
本文目錄
類別 | 內容 |
診斷流程 | |
排查思路 | |
常見排查方法 | |
常見問題及解決方案 |
|
背景信息
當前Kubernetes官方維護的是Nginx Ingress Controller,ACK基于社區版的Nginx Ingress Controller進行了優化。ACK的Nginx Ingress Controller與社區Nginx Ingress Controller完全兼容,支持社區所有的Annotation。您在ACK集群或ACK Serverless集群中選擇安裝的Nginx Ingress Controller組件,即為定制版的Nginx Ingress Controller組件。關于如何安裝Nginx Ingress Controller組件,請參見安裝Nginx Ingress Controller組件。
為了使得Nginx Ingress資源正常工作,集群中必須要有一個Nginx Ingress Controller來解析Nginx Ingress的轉發規則。Nginx Ingress Controller收到請求,匹配Nginx Ingress轉發規則轉發到后端Service所對應的Pod,由Pod處理請求。Kubernetes中的Service、Nginx Ingress與Nginx Ingress Controller有著以下關系:
Service是后端真實服務的抽象,一個Service可以代表多個相同的后端服務。
Nginx Ingress是反向代理規則,用來規定HTTP/HTTPS請求應該被轉發到哪個Service所對應的Pod上。例如根據請求中不同的Host和URL路徑,讓請求落到不同的Service所對應的Pod上。
Nginx Ingress Controller是Kubernetes集群中的一個組件,負責解析Nginx Ingress的反向代理規則。如果Nginx Ingress有增刪改的變動,Nginx Ingress Controller會及時更新自己相應的轉發規則,當Nginx Ingress Controller收到請求后就會根據這些規則將請求轉發到對應Service的Pod上。
Nginx Ingress Controller通過API Server獲取Ingress資源的變化,動態地生成Load Balancer(例如Nginx)所需的配置文件(例如nginx.conf),然后重新加載Load Balancer(例如執行nginx -s reload重新加載Nginx)來生成新的路由轉發規則。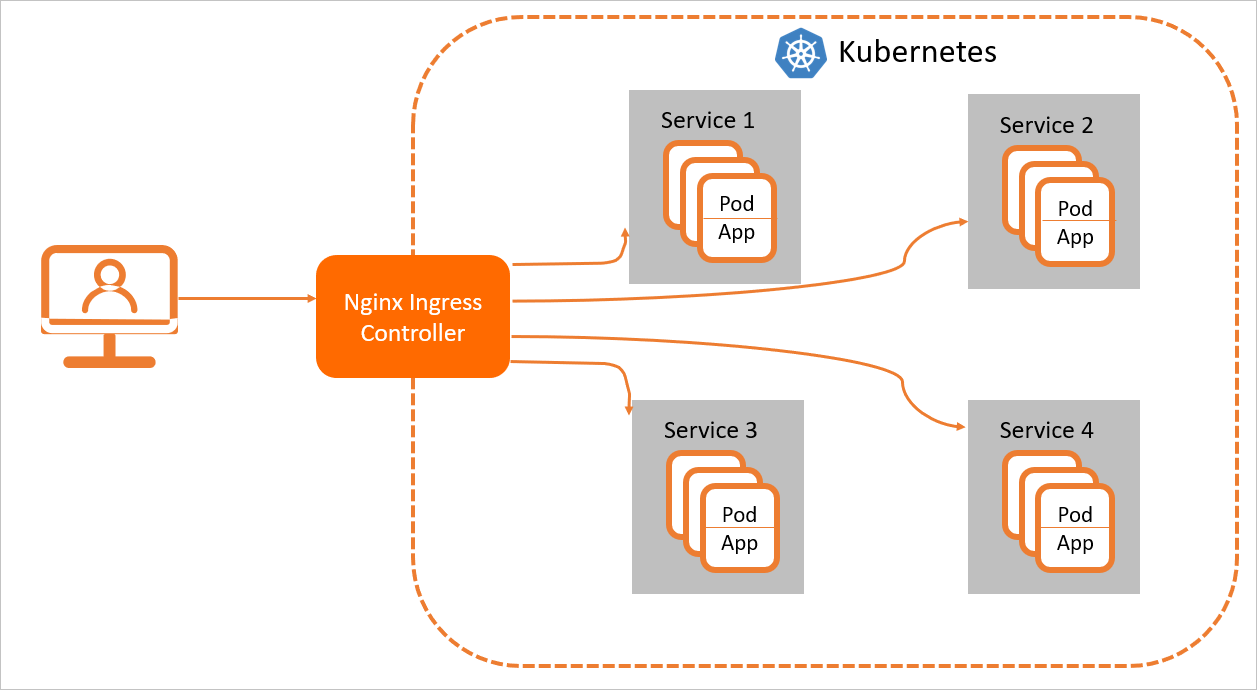
診斷流程
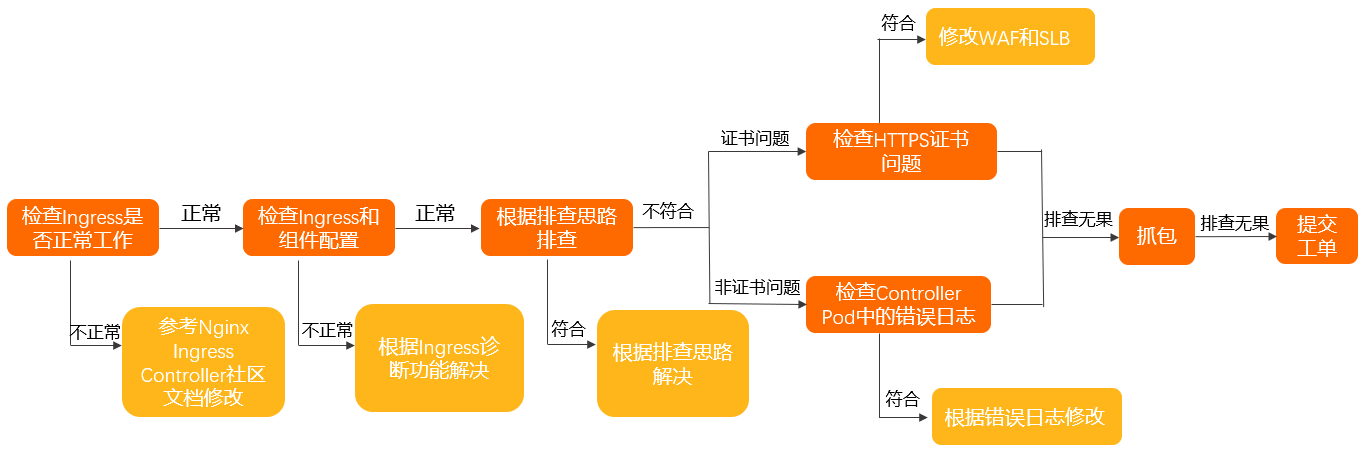
按照以下步驟,檢查是否是由于Ingress所導致的問題,確保Ingress Controller的配置正確。
在Controller Pod中確認訪問是否符合預期。具體操作,請參見在Controller Pod中手動訪問Ingress和后端Pod。
確認Nginx Ingress Controller使用方法正確。具體操作,請參見Nginx Ingress社區使用文檔。
使用Ingress診斷功能檢查Ingress和組件配置,并且根據相關提示進行修改。關于Ingress診斷功能具體操作,請參見使用Ingress診斷功能。
按照排查思路,確認相關問題及解決方案。
如果以上排查無果,請按照以下步驟排查:
針對HTTPS證書問題:
檢查域名上是否啟用了WAF接入或WAF透明接入。
如果啟用了,請確認WAF或透明WAF沒有設置TLS證書。
如果沒啟用,請執行下一步。
檢查SLB是否為七層監聽。
如果是,請確認SLB七層監聽上沒有設置TLS證書。
如果不是,請執行下一步。
非HTTPS證書問題,檢查Controller Pod中錯誤日志。具體操作,請參見檢查Controller Pod中錯誤日志。
如果以上排查無果,請在Controller Pod和對應后端的業務Pod中進行抓包,確認問題。具體操作,請參見抓包。
如果以上排查無果,請提交工單排查。
排查思路
排查思路 | 問題現象 | 解決方案 |
訪問不通 | 集群內部Pod到Ingress訪問不通 | |
Ingress訪問自己不通 | ||
無法訪問TCP、UDP服務 | ||
HTTPS訪問出現問題 | 證書未更新或返回默認證書 | |
返回 | ||
添加Ingress資源時出現問題 | 報錯failed calling webhook... | |
添加了Ingress,但是沒有生效 | ||
訪問不符合預期 | 無法獲得客戶端源IP | |
IP白名單不生效或不按預期生效 | ||
無法連接到通過Ingress暴露的gRPC服務 | ||
灰度不生效 | ||
灰度規則錯誤或影響到別的流量 | ||
出現 | ||
出現502、503、413、499等錯誤 | ||
加載頁面時部分資源加載不出來 | 配置了 | |
資源訪問時出現 |
常見檢查方法
使用Ingress診斷功能
登錄容器服務管理控制臺,在左側導航欄選擇集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在故障診斷頁面,單擊Ingress診斷。
在Ingress診斷面板,輸入出現問題的URL,例如https://www.example.com。選中我已知曉并同意,然后單擊發起診斷。
診斷完成后,根據診斷結果解決問題。
通過日志服務SLS的Controller Pod查看訪問日志
Ingress Controller訪問日志格式可以在ConfigMap中看到(默認ConfigMap為kube-system命名空間下的nginx-configuration)。
ACK Ingress Controller默認的日志格式為:
$remote_addr - [$remote_addr] - $remote_user [$time_local]
"$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_length
$request_time [$proxy_upstream_name] $upstream_addr $upstream_response_length
$upstream_response_time $upstream_status $req_id $host [$proxy_alternative_upstream_name]改動日志格式后,SLS的日志收集規則也需要做相應改動,否則無法在SLS日志控制臺看到正確日志信息,請您謹慎修改日志格式。
日志服務控制臺的Ingress Controller日志如下圖所示。具體操作,請參見步驟四:查看日志。
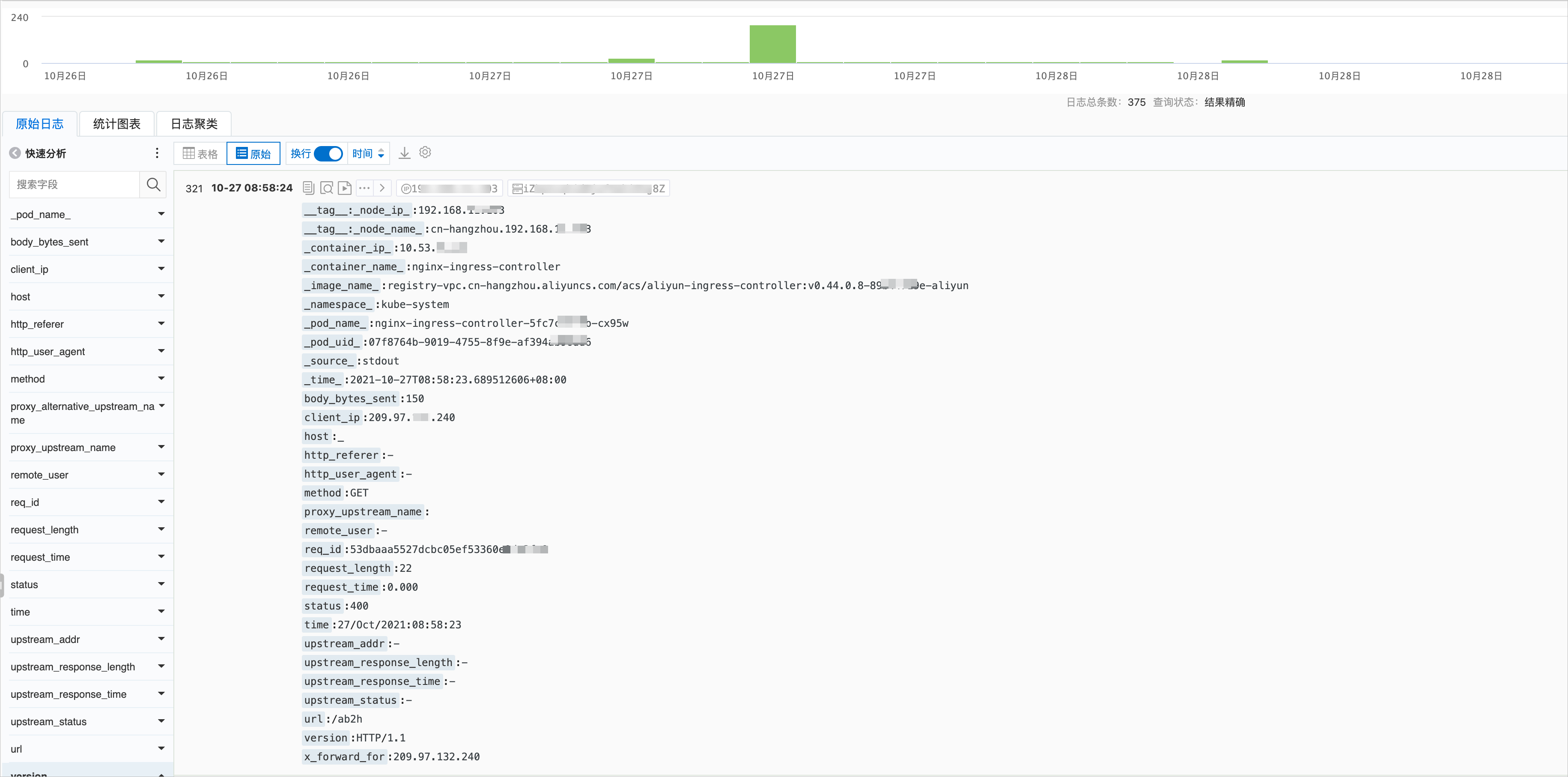
日志服務控制臺的日志和實際日志字段名稱會有部分不同,已在下表列出,字段解釋如下表所示。
字段 | 說明 |
| 客戶端的真實IP。 |
| 請求的信息。包括請求的方法、URL以及HTTP版本。 |
| 本次請求的時間。從接收客戶端請求起,到發送完響應數據的總時間。該值可能會受到客戶端網絡條件等因素的影響,無法代表請求真實的處理速度。 |
| 后端upstream的地址,如果該請求沒有到后端,則該值為空。當后端因為失敗請求多個upstream時,該值為半角逗號(,)分隔列表。 |
| 后端upstream返回的http code。如果該值為正常http status code,代表該值由后端upstream返回。當沒有后端可以訪問時,該值為502。有多個值時由半角逗號(,)分開。 |
| 后端upstream的響應時間,單位為秒。 |
| 后端upstream的名稱。命名規則為 |
| 后端alternative upstream的名稱。當該請求轉發到alternative upstream(例如使用Canary設置的灰度服務)時,該值不為空。 |
默認情況下,執行以下命令,您也可以直接在容器中看到近期的訪問日志。
kubectl logs <controller pod name> -n <namespace> | less預期輸出:
42.11.**.** - [42.11.**.**]--[25/Nov/2021:11:40:30 +0800]"GET / HTTP/1.1" 200 615 "_" "curl/7.64.1" 76 0.001 [default-nginx-svc-80] 172.16.254.208:80 615 0.000 200 46b79dkahflhakjhdhfkah**** 47.11.**.**[]
42.11.**.** - [42.11.**.**]--[25/Nov/2021:11:40:31 +0800]"GET / HTTP/1.1" 200 615 "_" "curl/7.64.1" 76 0.001 [default-nginx-svc-80] 172.16.254.208:80 615 0.000 200 fadgrerthflhakjhdhfkah**** 47.11.**.**[]檢查Controller Pod中錯誤日志
您可以根據Ingress Controller Pod中的日志,進一步縮小問題范圍。Controller Pod中錯誤日志分為以下兩種:
Controller錯誤日志:一般在Ingress配置錯誤時產生,可以執行以下命令過濾出Controller錯誤日志。
kubectl logs <controller pod name> -n <namespace> | grep -E ^[WE]說明Ingress Controller在啟動時會產生若干條W(Warning)等級錯誤,屬于正常現象。例如未指定kubeConfig或未指定Ingress Class等Warning信息,這些Warning信息不影響Ingress Controller的正常運行,因此可以忽略。
Nginx錯誤日志:一般在處理請求出現錯誤時產生,可以執行以下命令過濾出Nginx錯誤日志。
kubectl logs <controller pod name> -n <namespace> | grep error
在Controller Pod中手動訪問Ingress和后端Pod
執行以下命令,進入Controller Pod。
kubectl exec <controller pod name> -n <namespace> -it -- bashPod中已預裝好了curl、OpenSSL等工具,您可以通過該工具測試連通性、證書配置的正確性等。
執行以下命令,測試能否通過Ingress訪問到后端。
# 請將your.domain.com替換為實際要測試的域名。 curl -H "Host: your.domain.com" http://127.0.**.**/ # for http curl --resolve your.domain.com:443:127.0.0.1 https://127.0.0.1/ # for https執行以下命令,驗證證書信息。
openssl s_client -servername your.domain.com -connect 127.0.0.1:443訪問后端Pod測試的正確性。
說明Ingress Controller不會通過Service Cluster IP的形式來訪問后端Pod,而是直接訪問后端Pod IP。
執行以下命令,通過kubectl獲得后端Pod IP。
kubectl get pod -n <namespace> <pod name> -o wide預期輸出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-dp-7f5fcc7f-**** 1/1 Running 0 23h 10.71.0.146 cn-beijing.192.168.**.** <none> <none>由預期輸出獲得,后端Pod IP為10.71.0.146。
執行以下命令,在Controller Pod中訪問該Pod,確認Controller Pod到后端Pod能夠正常連通。
curl http://<your pod ip>:<port>/path
Nginx ingress排查相關命令
kubectl-plugin
Kubernetes官方Ingress控制器原先基于Nginx,但自0.25.0版本起改用OpenResty。控制器通過監聽API Server上Ingress資源的更改,自動產生相應的Nginx配置,然后Reload重新加載配置以使之生效。更多詳情,請參見官方文檔。
隨著Ingress數量增加,所有配置匯聚于單一的Nginx.conf文件,造成配置文件過長且難以調試。尤其是從0.14.0版本開始,Upstream部分采用Lua-resty-balancer動態生成,增加了調試難度。因此,社區貢獻了一個Kubectl插件Ingress-nginx,以簡化Ingress-nginx配置的調試過程。相關操作,請參見kubectl-plugin。
執行以下命令,獲取Ingress-nginx控制器當前已知后端的服務信息。
kubectl ingress-nginx backends -n ingress-nginxdbg命令
除了Kubectl-plugin插件方式外,也可以使用
dbg命令來進行相關信息的查看和診斷。執行以下命令,進入Nginx Ingress容器。
kubectl exec -itn kube-system <nginx-ingress-pod-name> bash執行
/dbg命令可看到如下輸出。nginx-ingress-controller-69f46d8b7-qmt25:/$ /dbg dbg is a tool for quickly inspecting the state of the nginx instance Usage: dbg [command] Available Commands: backends Inspect the dynamically-loaded backends information certs Inspect dynamic SSL certificates completion Generate the autocompletion script for the specified shell conf Dump the contents of /etc/nginx/nginx.conf general Output the general dynamic lua state help Help about any command Flags: -h, --help help for dbg --status-port int Port to use for the lua HTTP endpoint configuration. (default 10246) Use "dbg [command] --help" for more information about a command.
查看某個域名對應的證書是否存在。
/dbg certs get <hostname>查看當前所有后端服務信息。
/dbg backends all
Nginx Ingress狀態
Nginx包含一個自檢模塊,可輸出運行統計信息;在Nginx Ingress容器中,通過Curl訪問10246端口的nginx_status,可以查看Nginx的請求和連接統計數據。
執行以下命令,進入Nginx Ingress容器。
kubectl exec -itn kube-system <nginx-ingress-pod-name> bash執行以下命令,查看當前Nginx的請求、連接相關統計狀態信息。
nginx-ingress-controller-79c5b4d87f-xxx:/etc/nginx$ curl localhost:10246/nginx_status Active connections: 12818 server accepts handled requests 22717127 22717127 823821421 Reading: 0 Writing: 382 Waiting: 12483自Nginx啟動以來,它接受并處理了22717127個連接,且每個連接都成功處理,未出現立即關閉的情況。這22717127個連接共處理了823821421個請求,意味著每個連接平均處理約36.2個請求。
Active connections:表示當前Nginx服務器上的活躍連接總數為12818個。
Reading:表示Nginx當前正在讀取請求頭的連接數是0。
Writing:表示Nginx當前正在發送響應的連接數是382。
Waiting:表示保持長連接(keep-alive)的連接數12483個。
抓包
當無法定位問題時,需要抓包進行輔助診斷。
根據初步問題定位結果,簡單判斷網絡問題出現在Ingress Pod還是業務Pod。如果信息不足,可以兩方的包都進行抓取。
登錄出現異常的業務Pod或Ingress Pod所在節點。
在ECS(非容器內)執行以下命令,可以將Ingress流量信息抓取到文件中。
tcpdump -i any host <業務Pod IP或Ingress Pod IP> -C 20 -W 200 -w /tmp/ingress.pcap觀察日志,當出現預期錯誤時,結束抓包。
結合業務日志的報錯,定位到精準的報錯時間的報文信息。
說明在正常情況下,抓包對業務無影響,僅會增加小部分的CPU負載和磁盤寫入。
以上命令會對抓取到的包進行rotate,最多可以寫200個20 MB的.pcap文件。
集群內訪問集群LoadBalancer暴露的SLB地址不通
問題現象
在Kubernetes集群中有部分節點能訪問集群暴露出去的Local類型SLB,但是也有部分節點不能訪問。
問題原因
SLB設置了externalTrafficPolicy: Local類型,這種類型的SLB地址只有在Node中部署了對應的后端Pod,才能被訪問。因為SLB的地址是集群外使用,如果集群節點和Pod不能直接訪問,請求不會到SLB,會被當作Service的擴展IP地址,被kube-proxy的iptables或ipvs轉發。
如果剛好集群節點或者Pod所在的節點上沒有相應的后端服務Pod,就會發生網絡不通的問題,而如果有相應的后端服務Pod,是可以正常訪問。有關external-lb的更多信息,請參見kube-proxy將external-lb的地址添加到節點本地iptables規則。
解決方案
(推薦)在Kubernetes集群內通過ClusterIP或者Ingress的服務名去訪問。
其中Ingress的服務名為
nginx-ingress-lb.kube-system。執行
kubectl edit svc nginx-ingress-lb -n kube-system命令,修改Ingress的服務。將LoadBalancer的Service中externalTrafficPolicy修改為Cluster,但應用中會丟失源IP。如果是Terway的ENI或者ENI多IP的集群,將LoadBalancer的Service中
externalTrafficPolicy修改為Cluster,并且添加ENI直通的Annotation,可以保留源IP,并且集群內訪問也沒有問題。示例如下:
apiVersion: v1 kind: Service metadata: annotations: service.beta.kubernetes.io/backend-type: eni # 直通ENI。 labels: app: nginx-ingress-lb name: nginx-ingress-lb namespace: kube-system spec: externalTrafficPolicy: Cluster關于Service的Annotation的更多信息,請參見通過Annotation配置傳統型負載均衡CLB。
無法訪問Ingress Controller自己
問題現象
對于Flannel集群,在Ingress Pod中通過域名、SLB IP、Cluster IP訪問Ingress自己時,出現部分請求或全部請求不成功的情況。
問題原因
Flannel目前的默認配置不允許回環訪問。
解決方案
(推薦)如果條件允許,建議您重建集群,并使用Terway的網絡插件,將現有集群業務遷移至Terway模式集群中。
如果沒有重建集群的條件,可以通過修改Flannel配置,開啟
hairpinMode解決。配置修改完成后,重建Flannel Pod使修改生效。執行以下命令,編輯Flannel。
kubectl edit cm kube-flannel-cfg -n kube-system在返回結果cni-conf.json中的
delegate增加"hairpinMode": true。示例如下:
cni-conf.json: | { "name": "cb0", "cniVersion":"0.3.1", "type": "flannel", "delegate": { "isDefaultGateway": true, "hairpinMode": true } }執行以下命令,刪除重建Flannel。
kubectl delete pod -n kube-system -l app=flannel
集群中添加或修改了TLS證書,但是訪問時還是默認證書或舊的證書
問題現象
您已經在集群中添加或修改Secret并在Ingress中指定secretName后,訪問集群仍使用了默認的證書(Kubernetes Ingress Controller Fake Certificate)或舊的證書。
問題原因
證書不是由集群內Ingress Controller返回的。
證書無效,未能被Controller正確加載。
Ingress Controller根據SNI來返回對應證書,TLS握手時可能未攜帶SNI。
解決方案
通過以下任一方式,確認建立TLS連接時是否攜帶了SNI字段:
使用支持SNI的較新版本瀏覽器。
使用
openssl s_client命令測試證書時,攜帶-servername參數。使用
curl命令時,添加hosts或使用--resolve參數映射域名,而不是使用IP+Host請求頭的方式。
確認WAF、WAF透明接入或SLB七層監聽上沒有設置TLS證書,TLS證書應該由集群內Ingress Controller返回的。
在智能運維控制臺進行Ingress診斷,觀察是否存在配置錯誤和錯誤日志。具體操作,請參見使用Ingress診斷功能。
執行以下命令,手動查看Ingress Pod錯誤日志,根據錯誤日志中相關提示進行修改。
kubectl logs <ingress pod name> -n <pod namespace> | grep -E ^[EW]
無法連接到通過Ingress暴露的gRPC服務
問題現象
通過Ingress無法訪問到其后的gRPC服務。
問題原因
未在Ingress資源中設置Annotation,指定后端協議類型。
gRPC服務只能通過TLS端口進行訪問。
解決方案
在對應Ingress資源中設置Annotation:
nginx.ingress.kubernetes.io/backend-protocol:"GRPC"。確認客戶端發送請求時使用的是TLS端口,并且將流量加密。
無法連接到后端HTTPS服務
問題現象
通過Ingress無法訪問到其后的HTTPS服務。
訪問時回復可能為400,并提示
The plain HTTP request was sent to HTTPS port。
問題原因
Ingress Controller到后端Pod請求使用了默認的HTTP請求。
解決方案
在Ingress資源中設置Annotation:nginx.ingress.kubernetes.io/backend-protocol:"HTTPS"。
Ingress Pod中無法保留源IP
問題現象
Ingress Pod中無法保留真實客戶端IP,顯示為節點IP或100.XX.XX.XX網段或其他地址。
問題原因
Ingress所使用的Service中
externalTrafficPolicy設為了Cluster。SLB上使用了七層代理。
使用了WAF接入或WAF透明接入服務。
解決方案
對于設置
externalTrafficPolicy為Cluster,且前端使用了四層SLB的情況。可以將
externalTrafficPolicy改為Local。但可能會導致集群內部使用SLB IP訪問Ingress不通,具體解決方案,請參見集群內訪問集群LoadBalancer暴露的SLB地址不通。對于使用了七層代理(七層SLB、WAF、透明WAF)的情況,可以按以下步驟解決:
確保使用的七層代理且開啟了X-Forwarded-For請求頭。
在Ingress Controller的ConfigMap中(默認為kube-system命名空間下的nginx-configuration)添加
enable-real-ip: "true"。觀察日志,驗證是否可以獲取到源IP。
對于鏈路較長,存在多次轉發的情況(例如在Ingress Controller前額外配置了反向代理服務),可以在開啟
enable-real-ip時通過觀察日志中remote_addr的值,來確定真實IP是否是以X-Forwarded-For請求頭傳遞到Ingress容器中。若不是,請在請求到達Ingress Controller之前利用X-Forwarded-For等方式攜帶客戶端真實IP。
灰度規則不生效
問題現象
在集群內設置了灰度,但是灰度規則不生效。
問題原因
可能原因有兩種:
在使用
canary-*相關Annotation時,未設置nginx.ingress.kubernetes.io/canary: "true"。在使用
canary-*相關Annotation時,0.47.0版本前的Nginx Ingress Controller,需要在Ingress規則里的Host字段中填寫您的業務域名,不能為空。
解決方案
根據上述原因,修改
nginx.ingress.kubernetes.io/canary: "true"或Ingress規則里的Host字段。詳細信息,請參見路由規則。如果上述情況不符合,請參見流量分發與灰度規則不一致或其他流量進入灰度服務。
流量分發與灰度規則不一致或其他流量進入灰度服務
問題現象
設置了灰度規則,但是流量沒有按照灰度規則進行分發,或者有其他正常Ingress的流量進入灰度服務。
問題原因
Nginx Ingress Controller中,灰度規則不是應用單個Ingress上,而是會應用在所有使用同一個Service的Ingress上。
關于產生該問題的詳情,請參見帶有灰度規則的Ingress將影響所有具有相同Service的Ingress。
解決方案
針對需要開啟灰度的Ingress(包括使用service-match和canary-*相關Annotation),創建獨立的Service(包括正式和灰度兩個Service)指向原有的Pod,然后再針對該Ingress啟用灰度。更多詳情,請參見通過Nginx Ingress實現灰度發布和藍綠發布。
創建Ingress資源時報錯 "failed calling webhook"
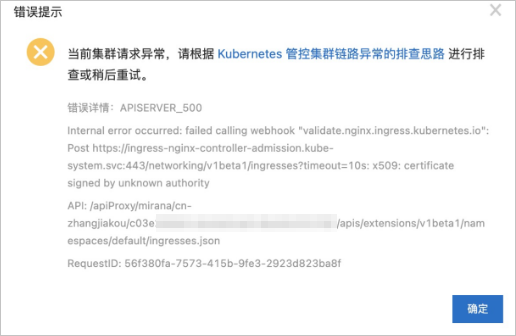
問題現象
添加Ingress資源時顯示"Internal error occurred: failed calling webhook...",如下圖所示。

問題原因
在添加Ingress資源時,需要通過服務(默認為ingress-nginx-controller-admission)驗證Ingress資源的合法性。如果鏈路出現問題,(例如服務被刪除,Ingress controller被刪除時),會導致驗證失敗,拒絕添加Ingress資源。
解決方案
按照Webhook鏈路檢查資源是否均存在且正常工作,鏈路為ValidatingWebhookConfiguration->Service->Pod。
確認Ingress Controller Pod的admission功能已打開,且能夠正常從外部訪問到該Pod。
如果Ingress Controller已被刪除或不需要Webhook功能,可以直接將ValidatingWebhookConfiguration資源刪除。
HTTPS訪問報SSL_ERROR_RX_RECORD_TOO_LONG錯誤
問題現象
訪問HTTPS時報錯SSL_ERROR_RX_RECORD_TOO_LONG或routines:CONNECT_CR_SRVR_HELLO:wrong version number。
問題原因
HTTPS請求訪問到了非HTTPS端口,例如HTTP端口。
常見的原因如下:
SLB的443端口綁定了Ingress Pod的80端口。
Ingress Controller所對應服務的Service 443端口映射到了Ingress Pod的80端口。
解決方案
根據實際情況修改SLB設置或Service設置,使得HTTPS能夠訪問到正確的端口。
出現常見HTTP錯誤碼
問題現象
請求出現非2xx、非3xx錯誤,例如502、503、413、499等錯誤。
問題原因及解決方案
查看日志,判斷是否為Ingress Controller返回的錯誤。具體方法,請參見通過日志服務SLS的Controller Pod查看訪問日志。若是,請參考以下解決方案:
413錯誤
問題原因:請求大小超過了最大限制。
解決方案:在ConfigMap中調大proxy-body-size的值(組件默認為1 M,ACK Ingress Controller中默認設置了20 M)
499錯誤
問題原因:客戶端由于某些原因提前斷開了連接,不一定是組件或者后端業務問題。
解決方案:
有少量499錯誤時,取決于業務,可能為正常現象,可以忽略。
有大量499錯誤時,請檢查后端業務處理時間和前端請求超時時間是否符合預期。
502錯誤
問題原因:Ingress Controller無法正常連接到后端。
解決方案:
偶發情況
檢查后端業務負載是否正常,若負載過高,嘗試對后端業務進行擴容。
Ingress Controller默認使用HTTP1.1請求訪問后端服務,且默認開啟長連接,請確認配置的后端長連接的連接空閑超時時間大于Ingress Controller的連接空閑超時時間(默認900s)。
必現情況
檢查后端Service端口配置是否正確,能否在Controller Pod中手動訪問到。
以上方法都無法確定問題的情況下,請進行抓包分析,并提交工單處理。
503錯誤
問題原因:Ingress Controller沒有找到后端Pod,或所有Pod均無法訪問。
解決方案:
偶發情況
查看502錯誤解決方案。
檢查后端業務就緒狀態,配置合理健康檢查。
必現情況
檢查后端Service配置是否正確,是否存在Endpoint。
以上方法都無法確定問題的情況下,請提交工單處理。
出現net::ERR_HTTP2_SERVER_REFUSED_STREAM錯誤
問題現象
訪問網頁時,部分資源無法正確加載,控制臺中有net::ERR_HTTP2_SERVER_REFUSED_STREAM或net::ERR_FAILED報錯。
問題原因
資源并行請求數較多,達到HTTP2最大流數限制。
解決方案
(推薦)在ConfigMap中根據實際需要,調整
http2-max-concurrent-streams至更大值(默認128)。具體操作,請參見http2-max-concurrent-streams。在ConfigMap中直接關閉HTTP2支持,設置
use-http2為false。具體操作,請參見use-http2。
出現報錯“The param of ServerGroupName is illegal”
問題原因
ServerGroupName的生成格式是namespace+svcName+port。服務器組名稱為長度為2~128個字符,必須以大小寫字母或中文開頭,可包含數字、半角句號(.)、下劃線(_)和短劃線(-)。
解決方案
按照服務器組名稱的格式要求修改。
創建Ingress時報錯“certificate signed by unknown authority”
問題原因
創建Ingress時,出現上圖報錯,原因是布置了多套Ingress,而各Ingress之間使用了相同的資源 (可能包括Secret、服務、Webhook配置等),導致Webhook執行時與后端服務通信時使用的SSL證書不一致,從而出現錯誤。
解決方案
重新部署兩套Ingress,兩套Ingress包含的資源不能重復。關于Ingress中包含的資源信息,請參見在ACK組件管理中升級Nginx Ingress Controller組件時,系統所做的更新是什么?。
Ingress Pod健康檢查失敗導致重啟
問題現象
Controller Pod出現健康檢查失敗導致Pod重啟。
問題原因
Ingress Pod或所在節點負載較高,導致健康檢查失敗。
集群節點上設置了
tcp_tw_reuse或tcp_tw_timestamps內核參數,可能會導致健康檢查失敗。
解決方案
對Ingress Pod進行擴容,觀察是否還有該現象。具體操作,請參見部署高可靠的Ingress接入層。
關閉
tcp_tw_reuse或設置為2,且同時關閉tcp_tw_timestamps,觀察是否還有該現象。
添加TCP、UDP服務
在對應ConfigMap中(默認為kube-system命名空間下的tcp-services和udp-services)添加對應條目。
例如default空間下example-go的8080端口映射到9000端口,示例如下。
apiVersion: v1 kind: ConfigMap metadata: name: tcp-services namespace: ingress-nginx data: 9000: "default/example-go:8080" # 8080端口映射到9000端口。在Ingress Deployment中(默認為kube-system命名空間下的nginx-ingress-controller)添加所映射的端口。
在Ingress對應的Service中添加所映射的端口。
apiVersion: v1 kind: Service metadata: name: ingress-nginx namespace: ingress-nginx labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx spec: type: LoadBalancer ports: - name: http port: 80 targetPort: 80 protocol: TCP - name: https port: 443 targetPort: 443 protocol: TCP - name: proxied-tcp-9000 port: 9000 targetPort: 9000 protocol: TCP selector: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx關于添加TCP和UDP服務的更多信息,請參見暴露TCP和UDP服務。
Ingress規則沒有生效
問題現象
添加或修改了Ingress規則,但是沒有生效。
問題原因
Ingress配置出現錯誤,導致新的Ingress規則無法被正確加載。
Ingress資源配置錯誤,與預期配置不相符。
Ingress Controller的權限出現問題,導致無法正常監視Ingress資源變動。
舊的Ingress使用了
server-alias配置了域名,與新的Ingress沖突,導致規則被忽略。
解決方案
使用智能運維控制臺的Ingress診斷工具進行診斷,并按照提示進行操作。具體操作,請參見使用Ingress診斷功能。
檢查舊的Ingress有無配置錯誤或配置沖突問題:
針對非
rewrite-target,且路徑中使用了正則表達式的情況,確認Annotation中配置了nginx.ingress.kubernetes.io/use-regex: "true"。檢查PathType是否與預期相符(
ImplementationSpecific默認與Prefix作用相同)。
確認與Ingress Controller相關聯的ClusterRole、ClusterRoleBinding、Role、RoleBinding、ServiceAccount都存在。默認名稱均為ingress-nginx。
進入Controller Pod容器,查看nginx.conf文件中已添加了規則。
執行以下命令,手動查看容器日志,確定問題。
kubectl logs <ingress pod name> -n <pod namespace> | grep -E ^[EW]
重寫到根目錄后部分資源無法加載或白屏
問題現象
通過Ingress rewrite-target annotation重寫訪問后,頁面部分資源無法加載,或出現白屏。
問題原因
rewrite-target可能沒有使用正則表達式進行配置。業務中請求資源路徑寫死在根目錄。
解決方案
檢查
rewrite-target是否配合正則表達式以及捕獲組一起使用。具體操作,請參見Rewrite。檢查前端請求是否訪問到了正確的路徑。
當版本升級后SLS解析日志不正常怎樣修復
問題現象
ingress-nginx-controller組件當前主要有0.20和0.30兩個版本,當通過控制臺的組件管理從0.20升級到0.30版本后 ,在使用Ingress的灰度或藍綠發布功能時,Ingress Dashboard會出現無法正確展示實際后端服務訪問的情況。
問題原因
由于0.20和0.30默認輸出格式不同,在使用Ingress的灰度或藍綠發布功能時,Ingress Dashboard會出現無法正確展示實際后端服務訪問的情況。
解決方案
執行以下操作步驟進行修復,更新nginx-configuration configmap和k8s-nginx-ingress配置。
更新
nginx-configuration configmap。如果您沒有修改過
nginx-configuration configmap,保存以下內容為nginx-configuration.yaml, 然后執行kubectl apply -f nginx-configuration.yaml命令進行部署。apiVersion: v1 kind: ConfigMap data: allow-backend-server-header: "true" enable-underscores-in-headers: "true" generate-request-id: "true" ignore-invalid-headers: "true" log-format-upstream: $remote_addr - [$remote_addr] - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_length $request_time [$proxy_upstream_name] $upstream_addr $upstream_response_length $upstream_response_time $upstream_status $req_id $host [$proxy_alternative_upstream_name] max-worker-connections: "65536" proxy-body-size: 20m proxy-connect-timeout: "10" reuse-port: "true" server-tokens: "false" ssl-redirect: "false" upstream-keepalive-timeout: "900" worker-cpu-affinity: auto metadata: labels: app: ingress-nginx name: nginx-configuration namespace: kube-system如果您修改過
nginx-configuration configmap,為了避免覆蓋您的配置,執行以下命令進行修復:kubectl edit configmap nginx-configuration -n kube-system
在
log-format-upstream字段末尾,添加[$proxy_alternative_upstream_name], 然后保存退出。更新
k8s-nginx-ingress配置。將以下內容保存為
k8s-nginx-ingress.yaml文件,然后執行kubectl apply -f k8s-nginx-ingress.yaml命令進行部署。apiVersion: log.alibabacloud.com/v1alpha1 kind: AliyunLogConfig metadata: namespace: kube-system # your config name, must be unique in you k8s cluster name: k8s-nginx-ingress spec: # logstore name to upload log logstore: nginx-ingress # product code, only for k8s nginx ingress productCode: k8s-nginx-ingress # logtail config detail logtailConfig: inputType: plugin # logtail config name, should be same with [metadata.name] configName: k8s-nginx-ingress inputDetail: plugin: inputs: - type: service_docker_stdout detail: IncludeLabel: io.kubernetes.container.name: nginx-ingress-controller Stderr: false Stdout: true processors: - type: processor_regex detail: KeepSource: false Keys: - client_ip - x_forward_for - remote_user - time - method - url - version - status - body_bytes_sent - http_referer - http_user_agent - request_length - request_time - proxy_upstream_name - upstream_addr - upstream_response_length - upstream_response_time - upstream_status - req_id - host - proxy_alternative_upstream_name NoKeyError: true NoMatchError: true Regex: ^(\S+)\s-\s\[([^]]+)]\s-\s(\S+)\s\[(\S+)\s\S+\s"(\w+)\s(\S+)\s([^"]+)"\s(\d+)\s(\d+)\s"([^"]*)"\s"([^"]*)"\s(\S+)\s(\S+)+\s\[([^]]*)]\s(\S+)\s(\S+)\s(\S+)\s(\S+)\s(\S+)\s*(\S*)\s*\[*([^]]*)\]*.* SourceKey: content
常見Controller錯誤日志
問題現象
通過檢查Controller Pod中錯誤日志中所述方法發現Pod內存在Controller錯誤日志。類似如下:
User "system:serviceaccount:kube-system:ingress-nginx" cannot list/get/update resource "xxx" in API group "xxx" at the cluster scope/ in the namespace "kube-system"問題原因
Nginx Ingress Controller缺少對應權限更新對應資源。
解決方案
根據日志確認問題是由于ClusteRole還是Role產生的。
日志中包含
at the cluster scope,問題則產生自ClusterRole(ingress-nginx)。日志中包含
in the namespace "kube-system",問題則產生自Role(kube-system/ingrerss-nginx)。
確認對應權限以及權限綁定是否完整。
對于ClusterRole:
確保ClusterRole
ingress-nginx以及ClusterRoleBindingingress-nginx存在。若不存在,可以考慮自行新建恢復、卸載組件重裝或者提交工單尋求幫助。確保ClusterRole
ingress-nginx中包含日志中所對應的權限(圖例中為networking.k8s.io/ingresses的List權限)。若權限不存在,可以手動添加至ClusterRole中。
對于Role:
確認Role
kube-system/ingress-nginx以及RoleBindingkube-system/ingress-nginx存在。若不存在,可以考慮自行新建恢復、卸載組件重裝或者提交工單尋求幫助。確認Role
ingress-nginx中包含日志中所對應權限(圖例中為ConfigMapingress-controller-leader-nginx的Update權限)。若權限不存在,可以手動添加至Role中。
問題現象
通過檢查Controller Pod中錯誤日志中所述方法發現Pod內存在Controller錯誤日志。類似如下:
requeuing……nginx: configuration file xxx test failed(多行內容)問題原因
配置錯誤,導致Nginx配置reload失敗,一般為Ingress規則或ConfigMap中插入的Snippet語法錯誤導致的。
解決方案
查看日志中錯誤提示(warn等級的提示可忽略),大體定位問題位置。若錯誤提示不夠清晰,可以根據錯誤提示中文件的行數,進入Pod中查看對應文件。以下圖為例,文件為/tmp/nginx/nginx-cfg2825306115的第449行。
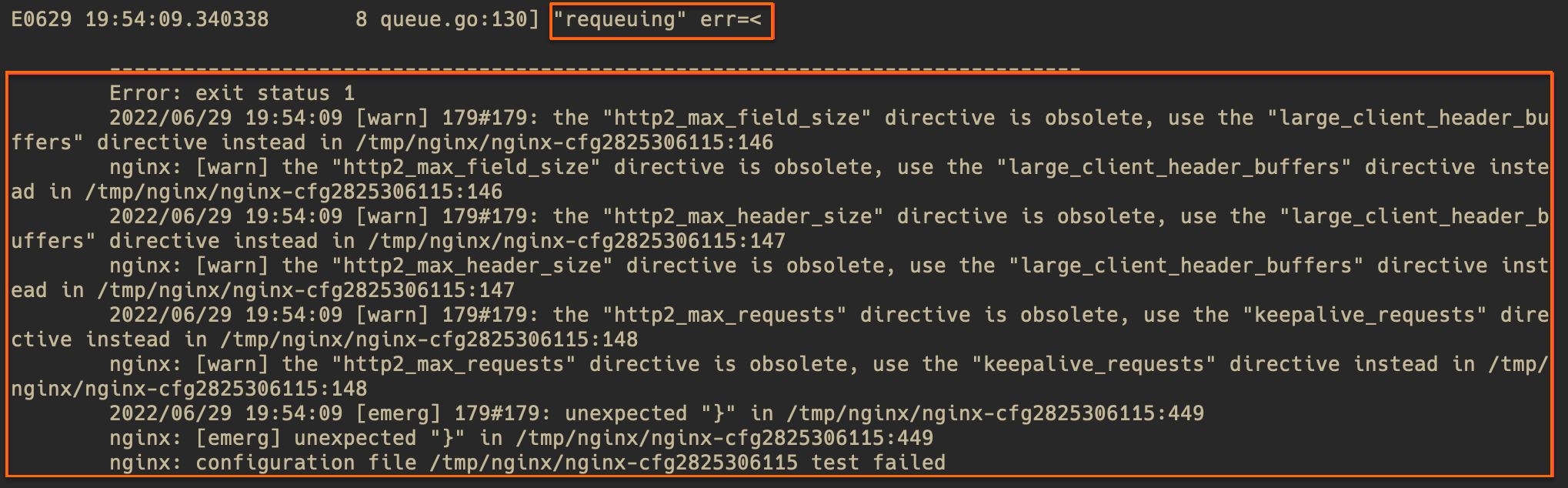
執行如下命令,查看對應行附近的配置有無錯誤。
# 進入Pod執行命令。 kubectl exec -n <namespace> <controller pod name> -it -- bash # 帶行數信息查看出錯的文件,在輸出中查看對應行附近的配置有無錯誤。 cat -n /tmp/nginx/nginx-cfg2825306115根據錯誤提示和配置文件,根據自身實際配置,定位錯誤原因并修復。
問題現象
通過檢查Controller Pod中錯誤日志中所述方法發現Pod內存在Controller錯誤日志。類似如下:
Unexpected error validating SSL certificate "xxx" for server "xxx"
問題原因
證書配置錯誤,常見的原因有證書所包含域名與Ingress中配置域名不一致。部分Warning等級日志不會影響到證書的正常使用(如證書中未攜帶SAN擴展等),請根據實際情況判斷是否出現問題。
解決方案
根據錯誤內容檢查集群中證書問題。
證書的cert和key格式和內容是否正確。
證書所包含域名與Ingress中所配置域名是否一致。
證書有無過期。