ack-koordinator以數據安全的方式將綁核應用遠端NUMA上的內存遷移至本地,提高本地訪存命中率,為內存密集型的工作負載提供更好的訪存性能。本文介紹如何使用內存就近訪問加速功能,并驗證其對密集型應用性能的提升。
索引
前提條件
已創建ACK Pro集群,且集群版本為1.18及以上版本。具體操作,請參見創建Kubernetes托管版集群。
已通過kubectl連接Kubernetes集群。具體操作,請參見獲取集群KubeConfig并通過kubectl工具連接集群。
已安裝ack-koordinator組件(原ack-slo-manager),且組件版本為v1.2.0-ack1.2及以上版本。關于安裝ack-koordinator組件的具體操作,請參見ack-koordinator(ack-slo-manager)。
說明ack-koordinator適配了原resource-controller組件的所有功能。如果您正在使用resource-controller,請您先卸載resource-controller,再安裝ack-koordinator。關于卸載組件的具體操作,請參見卸載resource-controller。
已確保多NUMA機型為神龍裸金屬ecs.ebmc、ecs.ebmg、ecs.ebmgn、ecs.ebmr、ecs.ebmhfc、ecs.scc等五、 六、七、八代機型。
說明內存就近訪問加速功能尤其對ecs.ebmc8i.48xlarge、ecs.c8i.32xlarge、ecs.g8i.48xlarge的八代機型提供更好的支持。關于ECS實例規格族,請參見ECS實例規格。
已確保應用運行在多NUMA機型上,且已通過CPU拓撲感知調度等功能實現綁核。更多信息,請參見CPU拓撲感知調度。
費用說明
ack-koordinator組件本身的安裝和使用是免費的,不過需要注意的是,在以下場景中可能產生額外的費用:
ack-koordinator是非托管組件,安裝后將占用Worker節點資源。您可以在安裝組件時配置各模塊的資源申請量。
ack-koordinator默認會將資源畫像、精細化調度等功能的監控指標以Prometheus的格式對外透出。若您配置組件時開啟了ACK-Koordinator開啟Prometheus監控指標選項并使用了阿里云Prometheus服務,這些指標將被視為自定義指標并產生相應費用。具體費用取決于您的集群規模和應用數量等因素。建議您在啟用此功能前,仔細閱讀阿里云Prometheus計費說明,了解自定義指標的免費額度和收費策略。您可以通過賬單和用量查詢,監控和管理您的資源使用情況。
內存就近訪問加速功能的優勢
多個非一致性內存訪問NUMA(Non-uniform memory access)架構下,當內存與CPU不在同一個NUMA時, 進程在跨NUMA讀取遠端內存時需要經過QPI總線,相對于內存與CPU在相同NUMA的本地內存訪問場景,跨NUMA場景訪存耗時更多。遠端內存的分布會降低應用的本地訪存命中率,影響內存密集型容器應用訪存性能。
以內存密集型應用Redis為例,Redis對所有CPU親和時,進程在運行過程中可能發生NUMA的切換。此時,以多NUMA機型ecs.ebmc8i.48xlarge為例,部分內存分布在遠端NUMA上,內存分布如下方左圖所示。redis-server的內存全本地分布相對于內存隨機分布和全遠端分布的場景,在壓測中,QPS性能分別提升10.52%和26.12%,如下方右圖所示。
本文中提供的測試數據僅為理論值(參考值),實際數據以您的操作環境為準。
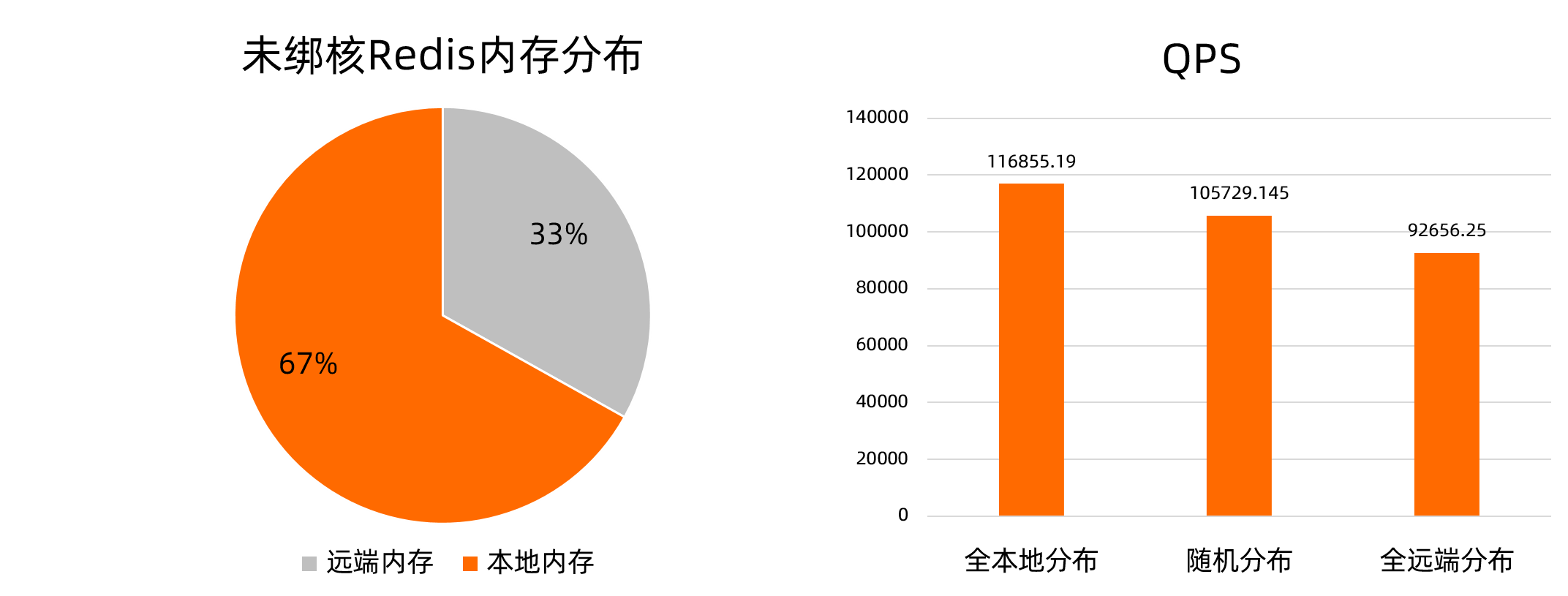
為提高訪存性能,ack-koordinator提供容器內存就近訪問加速功能。對基于CPU拓撲感知調度等功能實現綁核的應用,在確保數據安全的前提下盡可能地將遠端內存遷移至所在NUMA,且遷移過程中無需中斷業務。
使用場景
內存就近訪問加速功能的使用場景如下。
工作負載為內存密集型,例如大型內存數據庫Redis。
運行在配置英特爾?DSA(Data Streaming Accelerator)數據流加速器硬件的機器上,DSA可以提升內存就近訪問加速功能的速度,并降低CPU消耗。
使用內存就近訪問加速功能
步驟一:通過Policy開啟內存就近訪問加速功能
您可以通過以下兩種方式開啟內存就近訪問加速功能。
通過配置
metadata.annotations/koordinator.sh/memoryLocality,為單個Pod開啟內存就近訪問加速功能。具體操作,請參見下文為單個Pod開啟內存就近訪問加速。通過配置
configmap/ack-slo-config的指定QoS的memoryLocality,為指定QoS下所有Pod開啟內存就近訪問加速功能。具體操作,請參見下文為指定QoS下所有Pod開啟內存就近訪問加速。
為單個Pod開啟內存就近訪問加速功能
使用以下命令,為已綁核的Redis Pod開啟內存就近訪問加速功能。
kubectl annotate pod <pod-name> koordinator.sh/memoryLocality='{"policy": "bestEffort"}' --overwritepolicy參數取值說明:
bestEffort:立即執行單次內存就近訪問加速。none:關閉內存就近訪問加速功能。
為指定QoS下所有Pod開啟內存就近訪問加速功能
使用以下內容,創建ml-config.yaml文件。
apiVersion: v1 data: resource-qos-config: |- { "clusterStrategy": { "lsClass": { "memoryLocality": { "policy": "bestEffort" } } } } kind: ConfigMap metadata: name: ack-slo-config namespace: kube-system執行以下命令,檢查kube-system命名空間下,是否存在
configmap/ack-slo-config。為避免影響原有的QoS配置,需要進行
ack-slo-config的檢查操作。kubectl get cm ack-slo-config -n kube-system若
configmap/ack-slo-config不存在,則使用以下命令創建。kubectl apply -f ml-config.yaml若
configmap/ack-slo-config已存在,則使用以下命令,配置內存就近訪問加速。kubectl patch cm -n kube-system ack-slo-config --patch "$(cat ml-config.yaml)"
步驟二:通過Event查看內存就近訪問加速結果
使用以下命令,查看內存就近訪問加速的結果。
kubectl describe pod <pod-name>預期輸出1:
Normal MemoryLocalityCompleted 6s koordlet Container <container-name-1> completed: migrated memory from remote numa: 1 to local numa: 0 Container <container-name-2> completed: migrated memory from remote numa: 0 to local numa: 1 Total: 2 container(s) completed, 0 failed, 0 skipped; cur local memory ratio 100, rest remote memory pages 0預期輸出1
completed表明,內存就近訪問加速成功。Event記錄各個容器內存的遷移方向及本地化后Pod的總內存頁分布比例。預期輸出2:
Normal MemoryLocalityCompleted 6s koordlet Container <container-name-1> completed: migrated memory from remote numa: 1 to local numa: 0 Container <container-name-2> completed: failed to migrate the following processes: failed pid: 111111, error: No such process,from remote numa: 0 to local numa: 1 Total: 2 container(s) completed, 0 failed, 0 skipped; cur local memory ratio 100, rest remote memory pages 0預期輸出2
completed表明,部分內存就近訪問加速失敗,例如遷移過程中,進程終止。Event記錄失敗進程號。預期輸出3:
Normal MemoryLocalitySkipped 1s koordlet no target numa預期輸出3表明,沒有遠端NUMA時(例如機型為非NUMA架構或進程分布在所有NUMA時),Event告知內存就近訪問加速已跳過。
預期輸出4:
其他非預期錯誤,Pod報出MemoryLocalityFailed的Event,并提示Message錯誤信息。
(可選)步驟三:開啟多次內存就近訪問加速
若已進行過單次內存就近訪問加速,開啟多次內存訪問加速前,請確認前一次加速已完成。
多次內存就近訪問加速時,只有當內存就近訪問加速的結果發生改變,或本地化后內存頁分布比例發生超出10%的改變時,加速的結果才會記錄在Event中。
執行以下命令,開啟多次內存就近訪問加速。
kubectl annotate pod <pod-name> koordinator.sh/memoryLocality='{"policy": "bestEffort","migrateIntervalMinutes":10}' --overwritemigrateIntervalMinutes為兩次內存就近訪問加速的最小執行間隔,單位為分鐘。參數取值說明:
0:立即執行單次內存就近訪問加速。> 0:立即執行內存就近訪問加速。none:關閉內存就近訪問功能。
驗證內存就近訪問加速功能對應用性能的提升
測試環境
一臺多NUMA架構的物理機或虛擬機:用于部署內存密集型應用的測試機,本文測試選用ecs.ebmc8i.48xlarge和ecs.ebmg7a.64xlarge機型。
一臺能訪問測試機的壓測機:用于進行服務壓測。
測試的應用:4 Core 32 GB的多線程Redis。
說明若選用的測試機型規格較小,可改用單線程Redis并降低CPU和內存規格。
測試流程 測試步驟
測試步驟
使用以下YAML內容,創建并部署Redis應用。
以下代碼中
redis-config字段的內容,請根據測試機型規格修改配置。--- kind: ConfigMap apiVersion: v1 metadata: name: example-redis-config data: redis-config: | maxmemory 32G maxmemory-policy allkeys-lru io-threads-do-reads yes io-threads 4 --- kind: Service apiVersion: v1 metadata: name: redis spec: type: NodePort ports: - port: 6379 targetPort: 6379 nodePort: 32379 selector: app: redis --- apiVersion: v1 kind: Pod metadata: name: redis annotations: cpuset-scheduler: "true" # 通過CPU拓撲感知調度實現綁核。 labels: app: redis spec: containers: - name: redis image: redis:6.0.5 command: ["bash", "-c", "redis-server /redis-master/redis.conf"] ports: - containerPort: 6379 resources: limits: cpu: "4" # 根據測試機型規格修改配置。 volumeMounts: - mountPath: /redis-master-data name: data - mountPath: /redis-master name: config volumes: - name: data emptyDir: {} - name: config configMap: name: example-redis-config items: - key: redis-config path: redis.conf模擬內存增壓。
往Redis中寫入業務數據。
參考以下Shell腳本,通過管道方式向redis-server批量寫入數據。在以下腳本中,
<max-out-cir>和<max-out-cir>用來控制寫入的數據量。本文測試用例在4 Core 32 GB的Redis應用中寫入數據,本次參數設置為max-our-cir=300、max-in-cir=1000000。說明數據量較大時,數據寫入時間較長。為提高寫入速度,建議在測試機本地進行數據寫入。
for((j=1;j<=<max-out-cir>;j++)) do echo "set k$j-0 v$j-0" > data.txt for((i=1;i<=<max-in-cir>;i++)) do echo "set k$j-$i v$j-$i" >> data.txt done echo "$j" unix2dos data.txt # pipe方式需要dos格式文件。 cat data.txt | redis-cli --pipe -h <redis-server-IP> -p <redis-server-port> done在寫入過程中,對Redis所在的NUMA部署高內存占用的混部業務(例如FFmpeg)進行內存增壓,模擬Redis在運行過程中,因內存壓力突發導致內存漂移到其他NUMA的現象。
在測試機上,可使用
numactl --membind命令,限制部署業務內存所在的NUMA。使用以下stress命令進行增壓。
其中
<workers-num>用于分配內存的進程數,<malloc-size-per-workers>為每個進程分配的內存大小。說明由于Redis處于綁核狀態,在本地內存未達到100%時,內存會優先寫入到本地。請根據節點當前負載情況設置
workers-num及malloc-size-per-workers參數。各NUMA內存負載情況可通過numactl -H命令查詢。numactl --membind=<numa-id> stress -m <workers-num> --vm-bytes <malloc-size-per-workers>
在內存就近訪問加速前后進行redis-benchmark壓測并對比。
內存就近訪問加速前壓測
數據寫入完成后,在壓測機上使用redis-benchmark對測試機redis-server進行適中壓力及高壓力壓測。
執行以下適中壓力壓測命令,并發數為500。
redis-benchmark -t GET -c 500 -d 4096 -n 2000000 -h <redis-server-IP> -p <redis-server-port>執行以下高壓力壓測命令,并發數為10000。
redis-benchmark -t GET -c 10000 -d 4096 -n 2000000 -h <redis-server-IP> -p <redis-server-port>
為Redis開啟內存加速訪問功能
執行以下命令,為Redis進行內存就近訪問加速。
kubectl annotate pod redis koordinator.sh/memoryLocality='{"policy": "BestEffort"}' --overwrite執行以下命令,查看內存就近訪問加速結果。
若遠端內存量較大,內存就近訪問加速需要一定時間。
kubectl describe pod redis內存就近訪問加速完成后,預期輸出:
Normal MemoryLocalitySuccess 0s koordlet-resmanager migrated memory from remote numa: 0 to local numa: 1, cur local memory ratio 98, rest remote memory pages 28586
內存就近訪問加速后壓測
重復執行中壓力和高壓力壓測命令,進行內存就近訪問加速后壓測。
結果分析
本文測試分別采用ecs.ebmc8i.48xlarge和ecs.ebmg7a.64xlarge機型的測試機,對內存就近訪問加速前后進行多次壓測取平均值,數據對比如下。
采用不同的工具進行測試,測試結果會存在差異。本文中的測試數據僅為ecs.ebmc8i.48xlarge和ecs.ebmg7a.64xlarge機型的測試機獲得的測試結果。
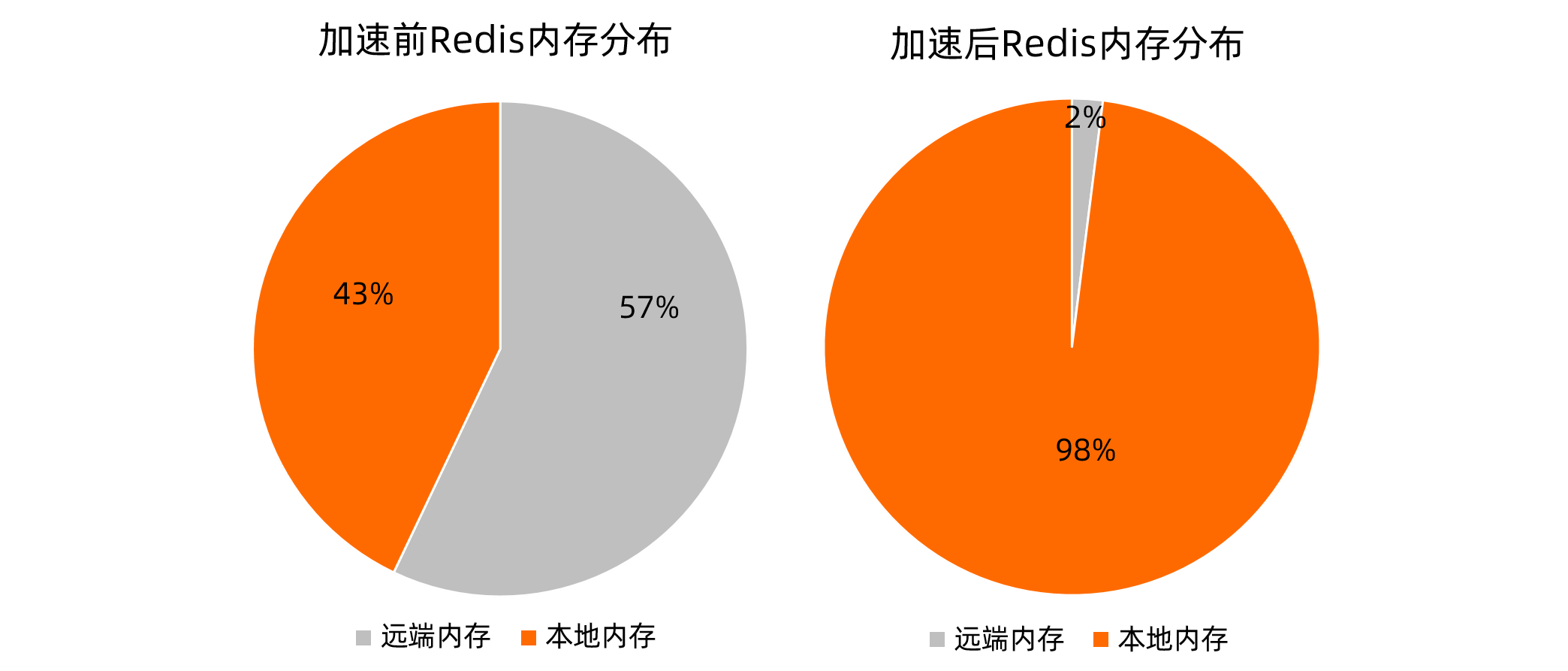
內存分布對比
內存就近訪問加速前,Redis內存分布如下方左圖所示,本地內存頁占比為43%。內存就近訪問加速后,Redis內存分布如下方右圖所示,本地內存頁占比為98%。
壓測結果對比
500并發場景
測試場景
P99 ms
P99.99 ms
QPS
內存就近訪問加速前
3
9.6
122139.91
內存就近訪問加速后
3
8.2
129367.11
10000并發場景
測試場景
P99 ms
P99.99 ms
QPS
內存就近訪問加速前
115
152.6
119895.56
內存就近訪問加速后
101
145.2
125401.44
以上壓測結果表明:
適中并發(500并發):P99無變化(時延小,變動不明顯),P99.99提升14.58%,QPS提升5.917%。
高并發(10000并發):P99提升12.17%,P99.99提升4.85%,QPS提升4.59%。
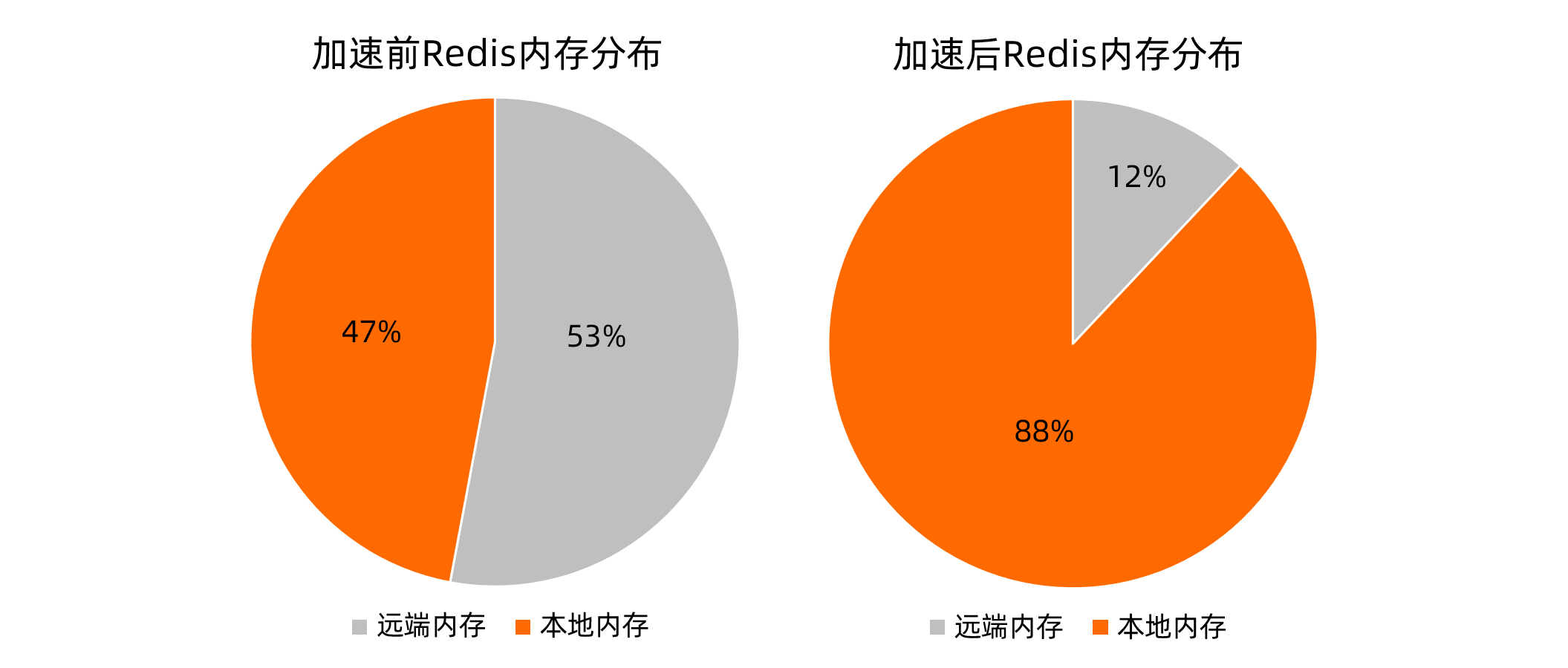
內存分布對比
內存就近訪問加速前,Redis內存分布如下方左圖所示,本地內存頁占比為47%。內存就近訪問加速后,Redis內存分布如下方右圖所示,本地內存頁占比為88%。
壓測結果對比
500并發場景
測試場景
P99 ms
P99.99 ms
QPS
內存就近訪問加速前
2.4
4.4
135180.99
內存就近訪問加速后
2.2
4.4
136296.37
10000并發場景
測試場景
P99 ms
P99.99 ms
QPS
內存就近訪問加速前
58.2
80.4
95757.10
內存就近訪問加速后
56.6
76.8
97015.50
以上壓測結果表明:
適中并發(500并發):P99提升8.33%,P99.99無變化(時延小,變動不明顯),QPS提升0.83%。
高并發(10000并發):P99提升2.7%,P99.99提升4.4%,QPS提升1.3%。
結果說明:在一定內存壓力下,應用的數據寫入到遠端內存,本地內存占比影響了訪存性能。在綁核基礎上進行內存就近訪問加速后,在兩種壓測場景下的Redis時延和吞吐指標都得到一定的改善。