本文以開源數據集fashion-mnist任務為例,介紹開發者如何利用云原生AI套件,在ACK集群運行深度學習任務,優化分布式訓練性能,調試模型效果,并最終把模型部署到ACK集群中。
背景信息
云原生AI套件包括一系列可單獨部署的組件(K8s Helm Chart),輔助AI工程加速。
云原生AI套件的用戶角色包括:管理員和開發者。
管理員:負責管理用戶及其權限,分配集群資源,配置外部存儲,管理數據集,并通過集群大盤觀測集群使用情況。
開發者:主要使用集群資源提交任務,開發者需要由管理員創建并分配權限,之后便可以選擇使用Arena命令行、Jupyter Notebook等工具進行日常開發。
前提條件
管理員已完成以下操作:
已創建Kubernetes集群。具體操作,請參見創建ACK托管集群。
集群每個節點的磁盤空間大于等于300 GB。
若希望取得最佳的數據加速對比效果,可以選擇4機8卡v100機型進行實驗。
若希望取得最佳的拓撲感知效果,可以選擇兩臺v100機型進行實驗。
已安裝云原生AI套件并部署所有組件。具體操作,請參見安裝云原生AI套件。
可訪問AI運維控制臺。關于如何配置AI運維控制臺,請參見訪問AI運維控制臺。
可訪問AI開發控制臺。關于如何配置AI開發控制臺,請參見訪問AI開發控制臺。
下載Fashion MNIST數據集,并上傳至OSS。關于如何將模型上傳到OSS上,請參見控制臺上傳文件。
已獲取測試代碼的Git倉庫地址,及用戶名和密碼。
已通過Kubectl工具連接Kubernetes集群。具體操作,請參見獲取集群KubeConfig并通過kubectl工具連接集群。
已安裝命令行提交工具Arena。具體操作,請參見配置Arena客戶端。
實驗環境
本文通過開發、訓練、加速、管理、評測和部署一個fashion-mnist任務,來介紹AI開發者如何使用云原生AI套件。
首先需要管理員執行,步驟一:為開發者創建賬號并分配資源、步驟二:創建數據集。其余步驟可由開發者完成。
開發者需要在Jupyter Notebook中新建Terminal或使用集群中的跳板機提交Arena命令行,推薦使用Jupyter Notebook。
本實驗的集群信息如下所示:
主機名 | IP | 角色 | GPU卡數 | CPU核數 | Memory |
cn-beijing.192.168.0.13 | 192.168.0.13 | 跳板機 | 1 | 8 | 30580004 KiB |
cn-beijing.192.168.0.16 | 192.168.0.16 | Worker | 1 | 8 | 30580004 KiB |
cn-beijing.192.168.0.17 | 192.168.0.17 | Worker | 1 | 8 | 30580004 KiB |
cn-beijing.192.168.0.240 | 192.168.0.240 | Worker | 1 | 8 | 30580004 KiB |
cn-beijing.192.168.0.239 | 192.168.0.239 | Worker | 1 | 8 | 30580004 KiB |
實驗目標
通過本文操作,可實現以下目標:
數據集管理
使用Jupyter Notebook搭建開發環境
提交單機訓練任務
提交分布式訓練任務
使用Fluid加速訓練任務
使用ACK AI任務調度器加速訓練任務
模型管理
模型評測
部署推理服務
步驟一:為開發者創建賬號并分配資源
開發者請聯系管理員獲取以下資源:
用戶賬號和密碼。關于如何新增用戶,請參見管理用戶。
資源配額。關于如何分配資源配額,請參見管理彈性配額組。
若通過AI開發控制臺提交任務,請獲取AI開發控制臺的訪問地址。關于如何訪問AI開發控制臺,請參見訪問AI開發控制臺。
若通過Arena命令行提交任務,請獲取訪問集群的kube.config。關于如何獲取訪問集群的kube.config,請參見步驟二:選擇集群憑證類型。
步驟二:創建數據集
數據集需要由管理員角色來管理。本示例使用fashion-mnist數據集。
步驟一:創建fashion-mnist數據集
根據以下YAML示例創建fashion-mnist.yaml文件。
本示例創建OSS類型的PV及PVC。
apiVersion: v1 kind: PersistentVolume metadata: name: fashion-demo-pv spec: accessModes: - ReadWriteMany capacity: storage: 10Gi csi: driver: ossplugin.csi.alibabacloud.com volumeAttributes: bucket: fashion-mnist otherOpts: "" url: oss-cn-beijing.aliyuncs.com akId: "AKID" akSecret: "AKSECRET" volumeHandle: fashion-demo-pv persistentVolumeReclaimPolicy: Retain storageClassName: oss volumeMode: Filesystem --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: fashion-demo-pvc namespace: demo-ns spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi selector: matchLabels: alicloud-pvname: fashion-demo-pv storageClassName: oss volumeMode: Filesystem volumeName: fashion-demo-pv執行以下命令創建fashion-mnist數據集。
kubectl create -f fashion-mnist.yaml查看PV及PVC的狀態。
執行以下命令,查看PV的狀態。
kubectl get pv fashion-mnist-jackwg預期輸出:
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE fashion-mnist-jackwg 10Gi RWX Retain Bound ns1/fashion-mnist-jackwg-pvc oss 8h執行以下命令,查看PVC的狀態。
kubectl get pvc fashion-mnist-jackwg-pvc -n ns1預期輸出:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE fashion-mnist-jackwg-pvc Bound fashion-mnist-jackwg 10Gi RWX oss 8h
從預期輸出可得,PV及PVC的狀態均為Bound。
步驟二:創建加速數據集
管理員可通過AI運維控制臺創建加速數據集。
- 使用管理員賬號訪問AI運維控制臺。
- 在AI運維控制臺左側導航欄中,選擇。
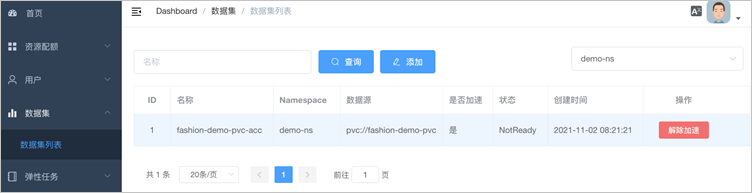
在數據集列表頁面,單擊目標數據集右側操作列的一鍵加速。
加速后的數據集如下圖所示:
步驟三:模型開發
本節介紹如何使用Jupyter Notebook搭建開發環境。整體流程為:
使用自定義鏡像創建Jupyter Notebook(可選)。
通過Jupyter Notebook開發測試。
在Jupyter Notebook中提交代碼至Git倉庫。
使用Arena SDK提交訓練任務。
(可選)步驟一:使用自定義鏡像創建Jupyter Notebook
AI開發控制臺的Jupyter Notebook,默認提供了TensorFlow及PyTorch不同版本的鏡像,若均不滿足需求可考慮自定義鏡像。
使用以下Dockerfile模板樣例,創建名為Dockerfile的文件。
關于自定義鏡像的規范,請參見創建并使用Notebook。
cat<<EOF >dockerfile FROM tensorflow/tensorflow:1.15.5-gpu USER root RUN pip install jupyter && \ pip install ipywidgets && \ jupyter nbextension enable --py widgetsnbextension && \ pip install jupyterlab && jupyter serverextension enable --py jupyterlab EXPOSE 8888 #USER jovyan CMD ["sh", "-c", "jupyter-lab --notebook-dir=/home/jovyan --ip=0.0.0.0 --no-browser --allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*' --NotebookApp.base_url=${NB_PREFIX} --ServerApp.authenticate_prometheus=False"] EOF執行以下命令,使用Dockerfile構建鏡像。
docker build -f dockerfile .預期輸出:
Sending build context to Docker daemon 9.216kB Step 1/5 : FROM tensorflow/tensorflow:1.15.5-gpu ---> 73be11373498 Step 2/5 : USER root ---> Using cache ---> 7ee21dc7e42e Step 3/5 : RUN pip install jupyter && pip install ipywidgets && jupyter nbextension enable --py widgetsnbextension && pip install jupyterlab && jupyter serverextension enable --py jupyterlab ---> Using cache ---> 23bc51c5e16d Step 4/5 : EXPOSE 8888 ---> Using cache ---> 76a55822ddae Step 5/5 : CMD ["sh", "-c", "jupyter-lab --notebook-dir=/home/jovyan --ip=0.0.0.0 --no-browser --allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*' --NotebookApp.base_url=${NB_PREFIX} --ServerApp.authenticate_prometheus=False"] ---> Using cache ---> 3692f04626d5 Successfully built 3692f04626d5執行以下命令,推送鏡像到您的Docker鏡像倉庫。
docker tag ${IMAGE_ID} registry-vpc.cn-beijing.aliyuncs.com/${DOCKER_REPO}/jupyter:fashion-mnist-20210802a docker push registry-vpc.cn-beijing.aliyuncs.com/${DOCKER_REPO}/jupyter:fashion-mnist-20210802a創建拉取鏡像所需Docker倉庫的Secret。
更多信息,請參見在集群中創建保存授權令牌的Secret。
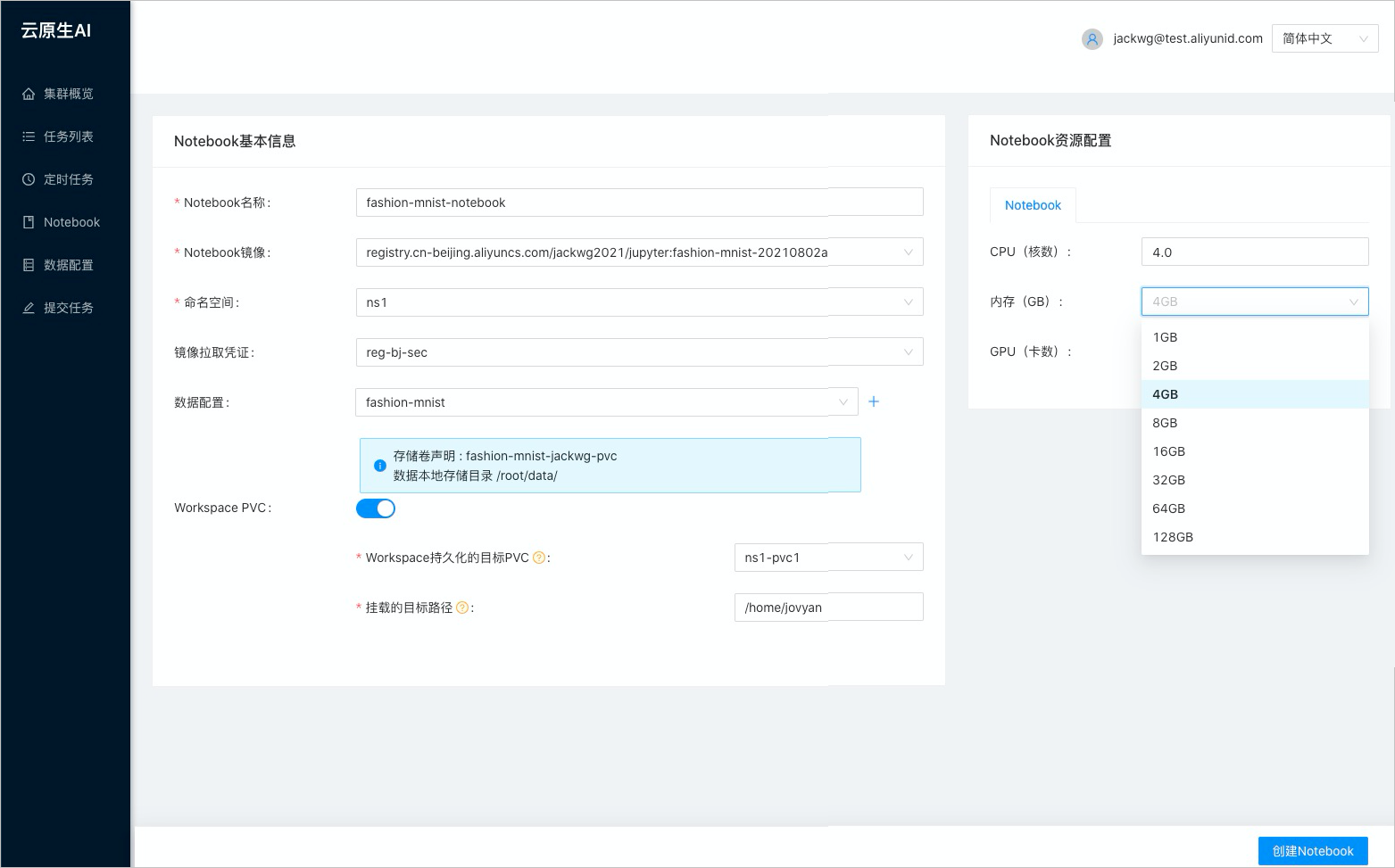
kubectl create secret docker-registry regcred \ --docker-server=<您的鏡像倉庫服務器> \ --docker-username=<您的用戶名> \ --docker-password=<您的密碼> \ --docker-email=<您的郵箱地址>在AI開發控制臺創建Jupyter Notebook。
關于如何創建Jupyter Notebook,請參見創建并使用Notebook。
創建Jupyter Notebook的相關參數配置請參見下圖:
步驟二:通過Jupyter Notebook開發測試
- 訪問AI開發控制臺。
- 在AI開發控制臺的左側導航欄中,單擊Notebook。
在Notebook頁面,單擊狀態為Running的目標Jupyter Notebook。
新建命令行Launcher,確認數據是否掛載成功。
pwd /root/data ls -alh預期輸出:
total 30M drwx------ 1 root root 0 Jan 1 1970 . drwx------ 1 root root 4.0K Aug 2 04:15 .. drwxr-xr-x 1 root root 0 Aug 1 14:16 saved_model -rw-r----- 1 root root 4.3M Aug 1 01:53 t10k-images-idx3-ubyte.gz -rw-r----- 1 root root 5.1K Aug 1 01:53 t10k-labels-idx1-ubyte.gz -rw-r----- 1 root root 26M Aug 1 01:54 train-images-idx3-ubyte.gz -rw-r----- 1 root root 29K Aug 1 01:53 train-labels-idx1-ubyte.gz創建供開發fashion-mnist模型使用的Jupyter Notebook,初始化內容如下所示:
#!/usr/bin/python # -*- coding: UTF-8 -*- import os import gzip import numpy as np import tensorflow as tf from tensorflow import keras print('TensorFlow version: {}'.format(tf.__version__)) dataset_path = "/root/data/" model_path = "./model/" model_version = "v1" def load_data(): files = [ 'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz', 't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz' ] paths = [] for fname in files: paths.append(os.path.join(dataset_path, fname)) with gzip.open(paths[0], 'rb') as labelpath: y_train = np.frombuffer(labelpath.read(), np.uint8, offset=8) with gzip.open(paths[1], 'rb') as imgpath: x_train = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28) with gzip.open(paths[2], 'rb') as labelpath: y_test = np.frombuffer(labelpath.read(), np.uint8, offset=8) with gzip.open(paths[3], 'rb') as imgpath: x_test = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(y_test), 28, 28) return (x_train, y_train),(x_test, y_test) def train(): (train_images, train_labels), (test_images, test_labels) = load_data() # scale the values to 0.0 to 1.0 train_images = train_images / 255.0 test_images = test_images / 255.0 # reshape for feeding into the model train_images = train_images.reshape(train_images.shape[0], 28, 28, 1) test_images = test_images.reshape(test_images.shape[0], 28, 28, 1) class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'] print('\ntrain_images.shape: {}, of {}'.format(train_images.shape, train_images.dtype)) print('test_images.shape: {}, of {}'.format(test_images.shape, test_images.dtype)) model = keras.Sequential([ keras.layers.Conv2D(input_shape=(28,28,1), filters=8, kernel_size=3, strides=2, activation='relu', name='Conv1'), keras.layers.Flatten(), keras.layers.Dense(10, activation=tf.nn.softmax, name='Softmax') ]) model.summary() testing = False epochs = 5 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) logdir = "/training_logs" tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir) model.fit(train_images, train_labels, epochs=epochs, callbacks=[tensorboard_callback], ) test_loss, test_acc = model.evaluate(test_images, test_labels) print('\nTest accuracy: {}'.format(test_acc)) export_path = os.path.join(model_path, model_version) print('export_path = {}\n'.format(export_path)) tf.keras.models.save_model( model, export_path, overwrite=True, include_optimizer=True, save_format=None, signatures=None, options=None ) print('\nSaved model success') if __name__ == '__main__': train()重要代碼中的dataset_path及model_path需要指定為Notebook掛載的數據源路徑,Notebook就可以訪問掛載到本地文件中的數據集。
在目標Notebook中單擊
 圖標。
圖標。預期輸出:
TensorFlow version: 1.15.5 train_images.shape: (60000, 28, 28, 1), of float64 test_images.shape: (10000, 28, 28, 1), of float64 Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= Conv1 (Conv2D) (None, 13, 13, 8) 80 _________________________________________________________________ flatten_2 (Flatten) (None, 1352) 0 _________________________________________________________________ Softmax (Dense) (None, 10) 13530 ================================================================= Total params: 13,610 Trainable params: 13,610 Non-trainable params: 0 _________________________________________________________________ Train on 60000 samples Epoch 1/5 60000/60000 [==============================] - 3s 57us/sample - loss: 0.5452 - acc: 0.8102 Epoch 2/5 60000/60000 [==============================] - 3s 52us/sample - loss: 0.4103 - acc: 0.8555 Epoch 3/5 60000/60000 [==============================] - 3s 55us/sample - loss: 0.3750 - acc: 0.8681 Epoch 4/5 60000/60000 [==============================] - 3s 55us/sample - loss: 0.3524 - acc: 0.8757 Epoch 5/5 60000/60000 [==============================] - 3s 53us/sample - loss: 0.3368 - acc: 0.8798 10000/10000 [==============================] - 0s 37us/sample - loss: 0.3770 - acc: 0.8673 Test accuracy: 0.8672999739646912 export_path = ./model/v1 Saved model success
步驟三:在Jupyter Notebook中提交代碼至Git倉庫
Jupyter Notebook創建完成后,可以直接在Notebook中提交代碼到您的Git庫。
執行以下命令,安裝Git。
apt-get update apt-get install git執行以下命令,初始化配置Git并保存用戶名密碼至Notebook。
git config --global credential.helper store git pull ${YOUR_GIT_REPO}執行以下命令,推送代碼到Git庫。
git push origin fashion-test預期輸出:
Total 0 (delta 0), reused 0 (delta 0) To codeup.aliyun.com:60b4cf5c66bba1c04b442e49/tensorflow-fashion-mnist-sample.git * [new branch] fashion-test -> fashion-test
步驟四:使用Arena SDK提交訓練任務
安裝Arena SDK的依賴。
!pip install coloredlogs根據以下示例新建Python文件,初始化代碼如下所示:
import os import sys import time from arenasdk.client.client import ArenaClient from arenasdk.enums.types import * from arenasdk.exceptions.arena_exception import * from arenasdk.training.tensorflow_job_builder import * from arenasdk.logger.logger import LoggerBuilder def main(): print("start to test arena-python-sdk") client = ArenaClient("","demo-ns","info","arena-system") # demo-ns是提交到的namespace。 print("create ArenaClient succeed.") print("start to create tfjob") job_name = "arena-sdk-distributed-test" job_type = TrainingJobType.TFTrainingJob try: # build the training job job = TensorflowJobBuilder().with_name(job_name)\ .witch_workers(1)\ .with_gpus(1)\ .witch_worker_image("tensorflow/tensorflow:1.5.0-devel-gpu")\ .witch_ps_image("tensorflow/tensorflow:1.5.0-devel")\ .witch_ps_count(1)\ .with_datas({"fashion-demo-pvc":"/data"})\ .enable_tensorboard()\ .with_sync_mode("git")\ .with_sync_source("https://codeup.aliyun.com/60b4cf5c66bba1c04b442e49/tensorflow-fashion-mnist-sample.git")\ #Git倉庫地址。 .with_envs({\ "GIT_SYNC_USERNAME":"USERNAME", \ #Git倉庫用戶名。 "GIT_SYNC_PASSWORD":"PASSWORD",\ #Git倉庫密碼。 "TEST_TMPDIR":"/",\ })\ .with_command("python code/tensorflow-fashion-mnist-sample/tf-distributed-mnist.py").build() # if training job is not existed,create it if client.training().get(job_name, job_type): print("the job {} has been created, to delete it".format(job_name)) client.training().delete(job_name, job_type) time.sleep(3) output = client.training().submit(job) print(output) count = 0 # waiting training job to be running while True: if count > 160: raise Exception("timeout for waiting job to be running") jobInfo = client.training().get(job_name,job_type) if jobInfo.get_status() == TrainingJobStatus.TrainingJobPending: print("job status is PENDING,waiting...") count = count + 1 time.sleep(5) continue print("current status is {} of job {}".format(jobInfo.get_status().value,job_name)) break # get the training job logs logger = LoggerBuilder().with_accepter(sys.stdout).with_follow().with_since("5m") #jobInfo.get_instances()[0].get_logs(logger) # display the training job information print(str(jobInfo)) # delete the training job #client.training().delete(job_name, job_type) except ArenaException as e: print(e) main()namespace:本示例是將訓練任務提交到demo-ns命名空間下。with_sync_source:Git倉庫地址。with_envs:Git倉庫用戶名和密碼。
在目標Notebook中單擊
圖標。預期輸出:
2021-11-02/08:57:28 DEBUG util.py[line:19] - execute command: [arena get --namespace=demo-ns --arena-namespace=arena-system --loglevel=info arena-sdk-distributed-test --type=tfjob -o json] 2021-11-02/08:57:28 DEBUG util.py[line:19] - execute command: [arena submit --namespace=demo-ns --arena-namespace=arena-system --loglevel=info tfjob --name=arena-sdk-distributed-test --workers=1 --gpus=1 --worker-image=tensorflow/tensorflow:1.5.0-devel-gpu --ps-image=tensorflow/tensorflow:1.5.0-devel --ps=1 --data=fashion-demo-pvc:/data --tensorboard --sync-mode=git --sync-source=https://codeup.aliyun.com/60b4cf5c66bba1c04b442e49/tensorflow-fashion-mnist-sample.git --env=GIT_SYNC_USERNAME=kubeai --env=GIT_SYNC_PASSWORD=kubeai@ACK123 --env=TEST_TMPDIR=/ python code/tensorflow-fashion-mnist-sample/tf-distributed-mnist.py] start to test arena-python-sdk create ArenaClient succeed. start to create tfjob 2021-11-02/08:57:29 DEBUG util.py[line:19] - execute command: [arena get --namespace=demo-ns --arena-namespace=arena-system --loglevel=info arena-sdk-distributed-test --type=tfjob -o json] service/arena-sdk-distributed-test-tensorboard created deployment.apps/arena-sdk-distributed-test-tensorboard created tfjob.kubeflow.org/arena-sdk-distributed-test created job status is PENDING,waiting... 2021-11-02/09:00:34 DEBUG util.py[line:19] - execute command: [arena get --namespace=demo-ns --arena-namespace=arena-system --loglevel=info arena-sdk-distributed-test --type=tfjob -o json] current status is RUNNING of job arena-sdk-distributed-test { "allocated_gpus": 1, "chief_name": "arena-sdk-distributed-test-worker-0", "duration": "185s", "instances": [ { "age": "13s", "gpu_metrics": [], "is_chief": false, "name": "arena-sdk-distributed-test-ps-0", "node_ip": "192.168.5.8", "node_name": "cn-beijing.192.168.5.8", "owner": "arena-sdk-distributed-test", "owner_type": "tfjob", "request_gpus": 0, "status": "Running" }, { "age": "13s", "gpu_metrics": [], "is_chief": true, "name": "arena-sdk-distributed-test-worker-0", "node_ip": "192.168.5.8", "node_name": "cn-beijing.192.168.5.8", "owner": "arena-sdk-distributed-test", "owner_type": "tfjob", "request_gpus": 1, "status": "Running" } ], "name": "arena-sdk-distributed-test", "namespace": "demo-ns", "priority": "N/A", "request_gpus": 1, "tensorboard": "http://192.168.5.6:31068", "type": "tfjob" }
步驟四:模型訓練
根據以下示例提交Tensorflow單機訓練任務、Tensorflow分布式訓練任務、Fluid加速訓練任務及ACK AI任務調度器加速分布式訓練任務。
示例一:提交Tensorflow單機訓練任務
Notebook開發完成并保存代碼后,可通過Arena命令行或AI開發控制臺兩種方式提交訓練任務。
方式一:通過Arena命令行提交訓練任務
arena \
submit \
tfjob \
-n ns1 \
--name=fashion-mnist-arena \
--data=fashion-mnist-jackwg-pvc:/root/data/ \
--env=DATASET_PATH=/root/data/ \
--env=MODEL_PATH=/root/saved_model \
--env=MODEL_VERSION=1 \
--env=GIT_SYNC_USERNAME=<GIT_USERNAME> \
--env=GIT_SYNC_PASSWORD=<GIT_PASSWORD> \
--sync-mode=git \
--sync-source=https://codeup.aliyun.com/60b4cf5c66bba1c04b442e49/tensorflow-fashion-mnist-sample.git \
--image="tensorflow/tensorflow:2.2.2-gpu" \
"python /root/code/tensorflow-fashion-mnist-sample/train.py --log_dir=/training_logs"方式二:通過AI開發控制臺提交訓練任務
配置數據源。具體操作,請參見配置訓練數據。
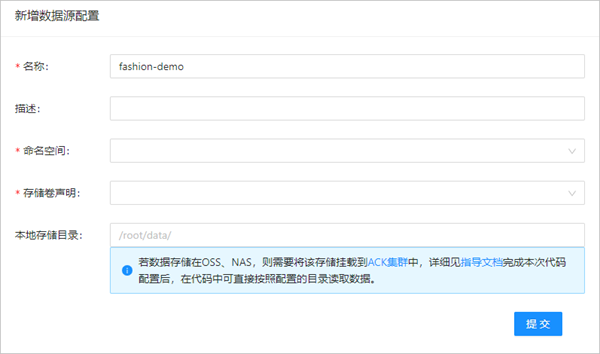
部分配置參數說明如下所示:
參數名
示例值
是否必填
名稱
fashion-demo
是
命名空間
demo-ns
是
存儲卷聲明
fashion-demo-pvc
是
本地存儲目錄
/root/data
否
配置代碼源。具體操作,請參見配置訓練代碼。
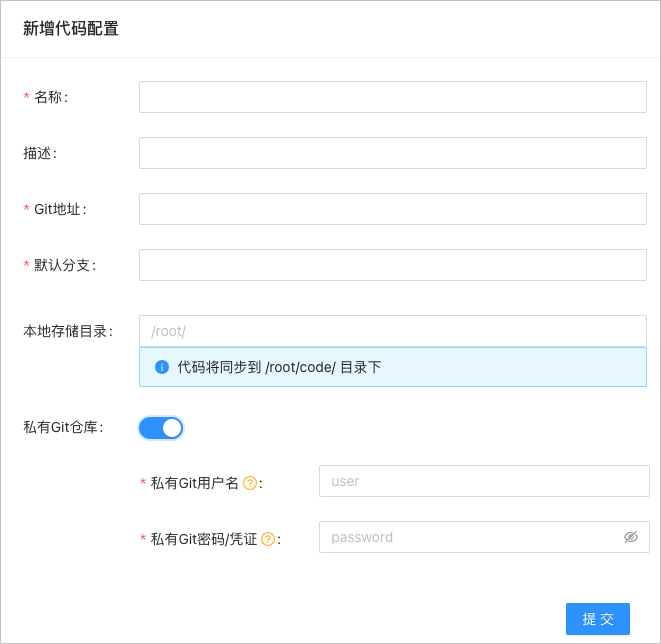
參數名
示例值
是否必填
名稱
fashion-git
是
Git地址
https://codeup.aliyun.com/60b4cf5c66bba1c04b442e49/tensorflow-fashion-mnist-sample.git
是
默認分支
master
否
本地存儲目錄
/root/
否
私有Git用戶名
您的私有Git倉庫的用戶名
否
私有Git密碼/憑證
您的私有Git倉庫的密碼
否
提交單機訓練任務。具體操作,請參見提交Tensorflow訓練任務。
配置訓練參數后,單擊提交,然后即可在任務列表查看到訓練任務。提交Job的參數如下所示:
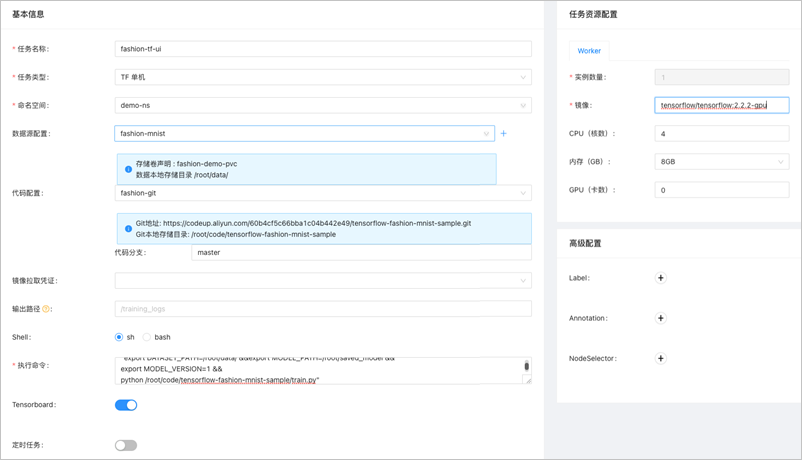
參數名
說明
任務名稱
本示例的任務名稱為fashion-tf-ui。
任務類型
本示例選擇Tensorflow單機。
命名空間
本示例為demo-ns。與數據集所在命名空間必須相同。
數據源配置
本示例為fashion-demo,選擇步驟1中的配置。
代碼配置
本示例為fashion-git,選擇步驟2中的配置。
代碼分支
本示例為master。
執行命令
本示例為
"export DATASET_PATH=/root/data/ &&export MODEL_PATH=/root/saved_model &&export MODEL_VERSION=1 &&python /root/code/tensorflow-fashion-mnist-sample/train.py"。私有Git倉庫
若需要使用私有的代碼庫,需要配置私有Git倉庫的用戶名和密碼。
實例數量
默認為1。
鏡像
本示例為
tensorflow/tensorflow:2.2.2-gpu。鏡像拉取憑證
若需要使用私有的鏡像倉庫,需要提前創建Secret。
CPU(核數)
默認為4。
內存(GB)
默認為8。
關于更多的Arena命令行參數,請參見Arena提交TFJob。
任務提交完成后,查看任務日志。
在AI開發控制臺的左側導航欄中,單擊任務列表。
在任務列表頁面,單擊目標任務名稱。
在目標任務詳情頁面,單擊實例頁簽,然后單擊目標實例右側操作列的日志。
本示例的日志信息如下所示:
train_images.shape: (60000, 28, 28, 1), of float64 test_images.shape: (10000, 28, 28, 1), of float64 Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= Conv1 (Conv2D) (None, 13, 13, 8) 80 _________________________________________________________________ flatten (Flatten) (None, 1352) 0 _________________________________________________________________ Softmax (Dense) (None, 10) 13530 ================================================================= Total params: 13,610 Trainable params: 13,610 Non-trainable params: 0 _________________________________________________________________ Epoch 1/5 2021-08-01 14:21:17.532237: E tensorflow/core/profiler/internal/gpu/cupti_tracer.cc:1430] function cupti_interface_->EnableCallback( 0 , subscriber_, CUPTI_CB_DOMAIN_DRIVER_API, cbid)failed with error CUPTI_ERROR_INVALID_PARAMETER 2021-08-01 14:21:17.532390: I tensorflow/core/profiler/internal/gpu/device_tracer.cc:216] GpuTracer has collected 0 callback api events and 0 activity events. 2021-08-01 14:21:17.533535: I tensorflow/core/profiler/rpc/client/save_profile.cc:168] Creating directory: /training_logs/train/plugins/profile/2021_08_01_14_21_17 2021-08-01 14:21:17.533928: I tensorflow/core/profiler/rpc/client/save_profile.cc:174] Dumped gzipped tool data for trace.json.gz to /training_logs/train/plugins/profile/2021_08_01_14_21_17/fashion-mnist-arena-chief-0.trace.json.gz 2021-08-01 14:21:17.534251: I tensorflow/core/profiler/utils/event_span.cc:288] Generation of step-events took 0 ms 2021-08-01 14:21:17.534961: I tensorflow/python/profiler/internal/profiler_wrapper.cc:87] Creating directory: /training_logs/train/plugins/profile/2021_08_01_14_21_17Dumped tool data for overview_page.pb to /training_logs/train/plugins/profile/2021_08_01_14_21_17/fashion-mnist-arena-chief-0.overview_page.pb Dumped tool data for input_pipeline.pb to /training_logs/train/plugins/profile/2021_08_01_14_21_17/fashion-mnist-arena-chief-0.input_pipeline.pb Dumped tool data for tensorflow_stats.pb to /training_logs/train/plugins/profile/2021_08_01_14_21_17/fashion-mnist-arena-chief-0.tensorflow_stats.pb Dumped tool data for kernel_stats.pb to /training_logs/train/plugins/profile/2021_08_01_14_21_17/fashion-mnist-arena-chief-0.kernel_stats.pb 1875/1875 [==============================] - 3s 2ms/step - loss: 0.5399 - accuracy: 0.8116 Epoch 2/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.4076 - accuracy: 0.8573 Epoch 3/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3727 - accuracy: 0.8694 Epoch 4/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3512 - accuracy: 0.8769 Epoch 5/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3351 - accuracy: 0.8816 313/313 [==============================] - 0s 1ms/step - loss: 0.3595 - accuracy: 0.8733 2021-08-01 14:21:34.820089: W tensorflow/python/util/util.cc:329] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/resource_variable_ops.py:1817: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version. Instructions for updating: If using Keras pass *_constraint arguments to layers. Test accuracy: 0.8733000159263611 export_path = /root/saved_model/1 Saved model success
查看Tensorboard。
需要通過Kubectl的port-forward代理到Tensorboard Service。具體操作如下所示:
執行以下命令,獲取Tensorboard Service的地址。
kubectl get svc -n demo-ns預期輸出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tf-dist-arena-tensorboard NodePort 172.16.XX.XX <none> 6006:32226/TCP 80m執行以下命令,通過Kubectl代理Tensorboard端口。
kubectl port-forward svc/tf-dist-arena-tensorboard -n demo-ns 6006:6006預期輸出:
Forwarding from 127.0.0.1:6006 -> 6006 Forwarding from [::1]:6006 -> 6006 Handling connection for 6006 Handling connection for 6006在瀏覽器地址欄輸入
http://localhost:6006/,即可查看TensorBoard。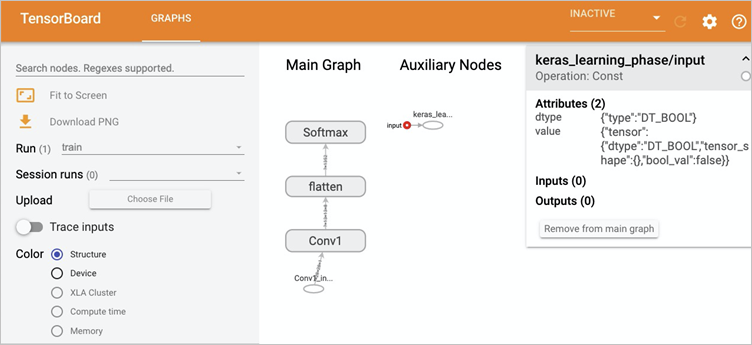
示例二:提交Tensorflow分布式訓練任務
方式一:通過Arena命令行提交訓練任務
執行以下命令,通過Arena命令行提交訓練任務。
arena submit tf \ -n demo-ns \ --name=tf-dist-arena \ --working-dir=/root/ \ --data fashion-mnist-pvc:/data \ --env=TEST_TMPDIR=/ \ --env=GIT_SYNC_USERNAME=kubeai \ --env=GIT_SYNC_PASSWORD=kubeai@ACK123 \ --env=GIT_SYNC_BRANCH=master \ --gpus=1 \ --workers=2 \ --worker-image=tensorflow/tensorflow:1.5.0-devel-gpu \ --sync-mode=git \ --sync-source=https://codeup.aliyun.com/60b4cf5c66bba1c04b442e49/tensorflow-fashion-mnist-sample.git \ --ps=1 \ --ps-image=tensorflow/tensorflow:1.5.0-devel \ --tensorboard \ "python code/tensorflow-fashion-mnist-sample/tf-distributed-mnist.py --log_dir=/training_logs"執行以下命令,獲取Tensorboard Service的地址。
kubectl get svc -n demo-ns預期輸出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tf-dist-arena-tensorboard NodePort 172.16.204.248 <none> 6006:32226/TCP 80m執行以下命令,通過Kubectl代理Tensorboard的庫。
查看Tensorboard需要通過Kubectl的port-forward代理到Tensorboard Service。
kubectl port-forward svc/tf-dist-arena-tensorboard -n demo-ns 6006:6006預期輸出:
Forwarding from 127.0.0.1:6006 -> 6006 Forwarding from [::1]:6006 -> 6006 Handling connection for 6006 Handling connection for 6006在瀏覽器地址欄輸入
http://localhost:6006/即可查看TensorBoard。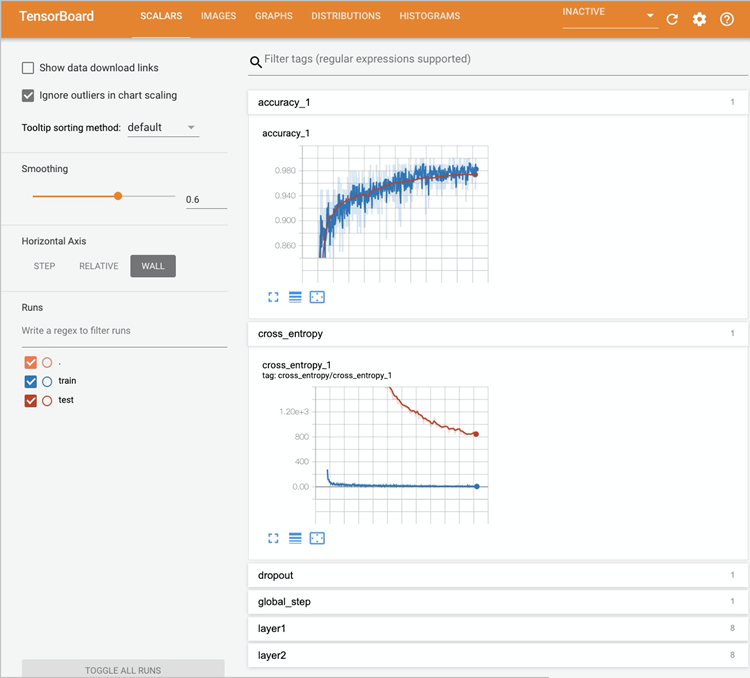
方式二:通過AI開發控制臺提交訓練任務
配置數據源。具體操作,請參見配置訓練數據。
本示例復用1的數據,不再重復配置。
配置代碼源。具體操作,請參見配置訓練代碼。
本示例復用2的代碼,不再重復配置。
提交Tensorflow分布式訓練任務。具體操作,請參見提交Tensorflow訓練任務。
配置訓練參數后,單擊提交,然后即可在任務列表查看到訓練任務。提交Job的參數如下所示:
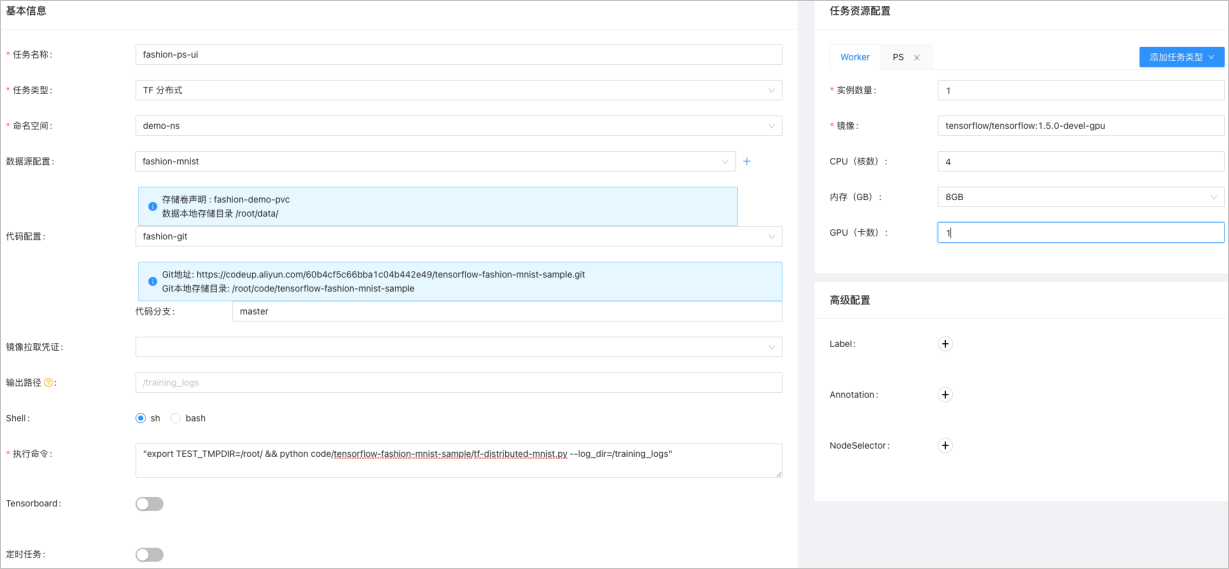
參數名
說明
任務名稱
本示例為fashion-ps-ui。
任務類型
本示例選擇TF分布式。
命名空間
本示例為demo-ns,與數據集所在命名空間必須相同。
數據源配置
本示例為fashion-demo,選擇步驟1中的配置。
代碼配置
本示例為fashion-git,選擇步驟2中的配置。
執行命令
本示例為
"export TEST_TMPDIR=/root/ && python code/tensorflow-fashion-mnist-sample/tf-distributed-mnist.py --log_dir=/training_logs"。鏡像
任務資源配置下Worker頁簽的鏡像,本示例配置為
tensorflow/tensorflow:1.5.0-devel-gpu。任務資源配置下的PS頁簽的鏡像,本示例配置為
tensorflow/tensorflow:1.5.0-devel。
關于更多的Arena命令行參數,請參見Arena提交TFJob。
示例三:提交Fluid加速訓練任務
以下示例介紹如何通過AI運維控制臺,一鍵加速現有數據集,并通過提交使用加速數據集的任務,與未使用加速數據集的任務對比,體驗加速效果。整體操作流程如下所示:
管理員在運維控制臺,一鍵加速現有數據集。
開發者使用Arena提交使用加速數據集的任務。
Arena list對比Job運行時長。
一鍵加速現有數據集。
提交使用加速數據集的任務。
開發者在命名空間demo-ns下,提交使用加速數據集的訓練任務。加速數據集的任務與不使用加速數據集的任務主要區別在于:
--data:加速后的PVC名稱,本示例為fashion-demo-pvc-acc。--env=DATASET_PATH:代碼中讀取數據的路徑,為Mount Path(本示例為--data中的/root/data/)+ PVC名稱(本示例為fashion-demo-pvc-acc)。
arena \ submit \ tfjob \ -n demo-ns \ --name=fashion-mnist-fluid \ --data=fashion-demo-pvc-acc:/root/data/ \ --env=DATASET_PATH=/root/data/fashion-demo-pvc-acc \ --env=MODEL_PATH=/root/saved_model \ --env=MODEL_VERSION=1 \ --env=GIT_SYNC_USERNAME=${GIT_USERNAME} \ --env=GIT_SYNC_PASSWORD=${GIT_PASSWORD} \ --sync-mode=git \ --sync-source=https://codeup.aliyun.com/60b4cf5c66bba1c04b442e49/tensorflow-fashion-mnist-sample.git \ --image="tensorflow/tensorflow:2.2.2-gpu" \ "python /root/code/tensorflow-fashion-mnist-sample/train.py --log_dir=/training_logs"執行以下命令對比兩次訓練任務的執行速度。
arena list -n demo-ns預期輸出:
NAME STATUS TRAINER DURATION GPU(Requested) GPU(Allocated) NODE fashion-mnist-fluid SUCCEEDED TFJOB 33s 0 N/A 192.168.5.7 fashion-mnist-arena SUCCEEDED TFJOB 3m 0 N/A 192.168.5.8通過Arena List兩次訓練結果可以看出,在相同的訓練代碼和節點資源下,使用Fluid加速之后的訓練任務耗時33秒,不采用加速的訓練任務耗時3分鐘。
示例四:使用ACK AI任務調度器加速分布式訓練任務
ACK AI任務調度器是阿里云ACK為云原生AI和大數據定制的優化調度器插件,支持Gang Scheduling,Capacity Scheduling和拓撲感知調度等。這里以GPU的拓撲感知調度為例,查看其加速效果。
ACK AI任務調度器基于節點異構資源的拓撲信息,例如GPU卡之間的Nvlink、PcleSwitch等通信方式,或者CPU的NUMA拓撲結構,在集群維度進行最佳的調度選擇,提供給AI作業更好的性能。關于GPU拓撲感知調度的更多信息,請參見GPU拓撲感知調度概述。關于CPU拓撲感知調度的更多信息,請參見CPU拓撲感知調度。
根據以下示例介紹如何開啟GPU拓撲感知調度,并對比加速效果。
執行以下命令,創建不開啟拓撲感知調度的訓練任務。
arena submit mpi \ --name=tensorflow-4-vgg16 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=vgg16 --batch_size=64 --variable_update=horovod"創建開啟拓撲感知調度的訓練任務。
為節點打標簽,下面以cn-beijing.192.168.XX.XX的節點為例,實際操作時,需要替換為您的集群節點名稱。
kubectl label node cn-beijing.192.168.XX.XX ack.node.gpu.schedule=topology --overwrite執行以下命令,創建開啟拓撲感知調度的訓練任務,并打開Arena拓撲感知開關
--gputopology=true。arena submit mpi \ --name=tensorflow-topo-4-vgg16 \ --gpus=1 \ --workers=4 \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=vgg16 --batch_size=64 --variable_update=horovod對比兩次訓練任務的執行速度。
執行以下命令,對比兩次訓練任務的執行速度。
arena list -n demo-ns預期輸出:
NAME STATUS TRAINER DURATION GPU(Requested) GPU(Allocated) NODE tensorflow-topo-4-vgg16 SUCCEEDED MPIJOB 44s 4 N/A 192.168.4.XX1 tensorflow-4-vgg16-image-warned SUCCEEDED MPIJOB 2m 4 N/A 192.168.4.XX0執行以下命令,查看未開啟拓撲感知調度的訓練任務的總處理速度。
arena logs tensorflow-topo-4-vgg16 -n demo-ns預期輸出:
100 images/sec: 251.7 +/- 0.1 (jitter = 1.2) 7.262 ---------------------------------------------------------------- total images/sec: 1006.44執行以下命令,查看開啟拓撲感知調度的訓練任務的總處理速度。
arena logs tensorflow-4-vgg16-image-warned -n demo-ns預期輸出:
100 images/sec: +/- 0.2 (jitter = 1.5) 7.261 ---------------------------------------------------------------- total images/sec: 225.50
根據上述預期輸出可得,開啟拓撲感知調度的訓練任務與未開啟拓撲感知調度的訓練任務的執行速度如下所示:
訓練任務 | 單卡處理速度(ns) | 總處理速度(ns) | 運行時長(秒) |
開啟拓撲感知調度 | 56.4 | 225.50 | 44 |
未開啟拓撲感知調度 | 251.7 | 1006.44 | 120 |
當節點激活GPU拓撲感知調度后,不再支持普通GPU資源調度。可通過執行以下命令更改節點標簽,恢復普通GPU資源調度功能。
kubectl label node cn-beijing.192.168.XX.XX0 ack.node.gpu.schedule=default --overwrite步驟五:模型管理
- 訪問AI開發控制臺。
- 在AI開發控制臺的左側導航欄中,單擊模型管理。
單擊模型管理頁面的創建模型。
在創建對話框中,配置需要創建的模型名稱、模型版本以及該模型對應關聯的訓練的Job。
本示例的模型名稱為fsahion-mnist-demo,模型版本為v1,訓練的Job選擇為tf-single。
單擊確定后,即可看到新增的模型。
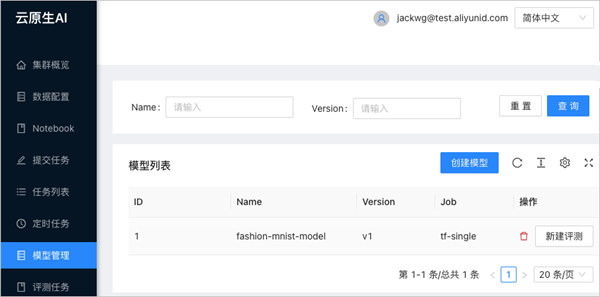
如果需要評測新增的模型,可在相應的模型后單擊新增評測。
步驟六:模型評測
云原生AI套件也支持提交模型評測類任務,可通過Arena和開發控制臺兩種方式提交。本示例介紹如何評測訓練Fashion-mnist過程中保存的Checkpoint。整體操作流程如下所示:
通過Arena提交開啟Checkpoint的訓練任務。
通過Arena提交評測任務。
通過AI開發控制臺對比不同評測的效果。
提交開啟Checkpoint的訓練任務。
執行以下命令,通過Arena提交開啟輸出Checkpoint的訓練任務,并保存Checkpoint到fashion-demo-pvc中。
arena \ submit \ tfjob \ -n demo-ns \ #您可根據需要配置命名空間。 --name=fashion-mnist-arena-ckpt \ --data=fashion-demo-pvc:/root/data/ \ --env=DATASET_PATH=/root/data/ \ --env=MODEL_PATH=/root/data/saved_model \ --env=MODEL_VERSION=1 \ --env=GIT_SYNC_USERNAME=${GIT_USERNAME} \ #輸入您的Git用戶名。 --env=GIT_SYNC_PASSWORD=${GIT_PASSWORD} \ #輸入您的Git密碼。 --env=OUTPUT_CHECKPOINT=1 \ --sync-mode=git \ --sync-source=https://codeup.aliyun.com/60b4cf5c66bba1c04b442e49/tensorflow-fashion-mnist-sample.git \ --image="tensorflow/tensorflow:2.2.2-gpu" \ "python /root/code/tensorflow-fashion-mnist-sample/train.py --log_dir=/training_logs"提交評測任務。
制作評測鏡像。
獲取模型評估代碼,在kubeai-sdk目錄執行以下命令,構建并推送鏡像。
docker build . -t ${DOCKER_REGISTRY}:fashion-mnist docker push ${DOCKER_REGISTRY}:fashion-mnist執行以下命令,獲取AI套件部署的Mysql。
kubectl get svc -n kube-ai ack-mysql預期輸出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ack-mysql ClusterIP 172.16.XX.XX <none> 3306/TCP 28h執行以下命令,通過Arena提交評測任務。
arena evaluate model \ --namespace=demo-ns \ --loglevel=debug \ --name=evaluate-job \ --image=registry.cn-beijing.aliyuncs.com/kube-ai/kubeai-sdk-demo:fashion-minist \ --env=ENABLE_MYSQL=True \ --env=MYSQL_HOST=172.16.77.227 \ --env=MYSQL_PORT=3306 \ --env=MYSQL_USERNAME=kubeai \ --env=MYSQL_PASSWORD=kubeai@ACK \ --data=fashion-demo-pvc:/data \ --model-name=1 \ --model-path=/data/saved_model/ \ --dataset-path=/data/ \ --metrics-path=/data/output \ "python /kubeai/evaluate.py"說明MYSQL的IP地址和端口可從上一步獲取。
對比評測結果。
在AI開發控制臺的左側導航欄中,單擊模型管理。
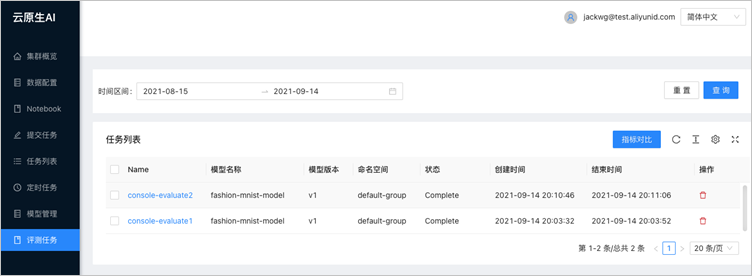
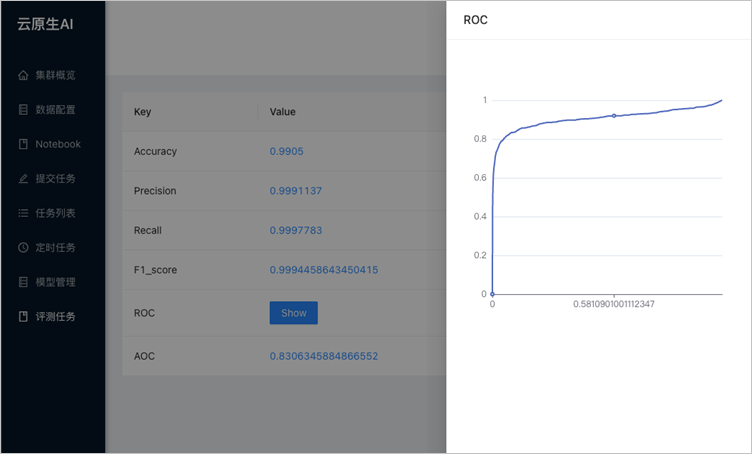
在任務列表中單擊目標評測任務的名稱,即可看到對應評測任務的指標。
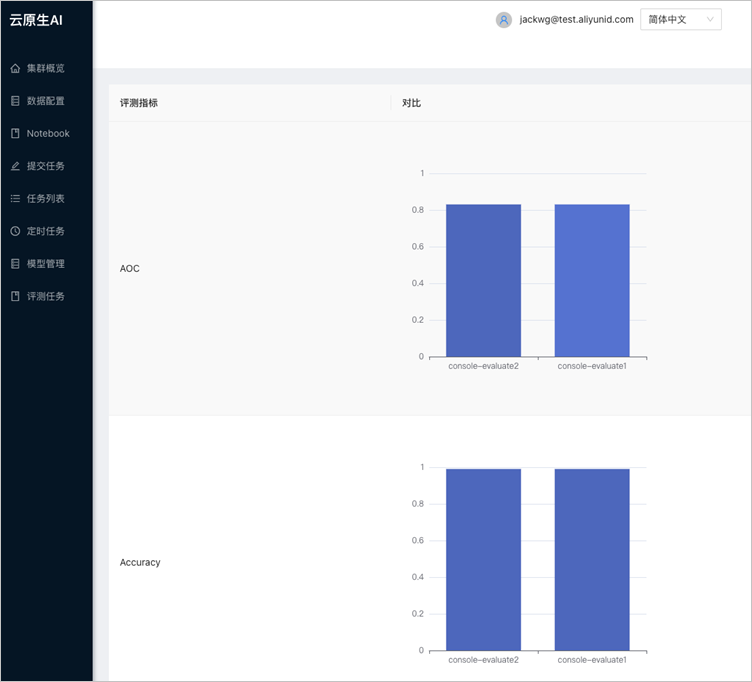
也可選擇多個任務對比指標:
步驟七:模型部署
模型開發、評測完成之后,需要發布為服務,供業務系統調用。以下內容介紹如何將上述步驟生成的模型發布為tf-serving服務。Arena同時支持Triton及Seldon等服務框架。更多信息,請參見Arena serve文檔。
以下示例使用步驟四:模型訓練訓練產出的模型,并將模型存儲在步驟二:創建數據集的PVC下(即fashion-minist-demo PVC)。若您的模型來自其他存儲類型,則需要先在集群中創建相應的PVC。
執行以下命令,通過Arena將TensorFlow模型部署到TensorFlow Serving上。
arena serve tensorflow \ --loglevel=debug \ --namespace=demo-ns \ --name=fashion-mnist \ --model-name=1 \ --gpus=1 \ --image=tensorflow/serving:1.15.0-gpu \ --data=fashion-demo-pvc:/data \ --model-path=/data/saved_model/ \ --version-policy=latest執行以下命令,獲取部署的推理服務名。
arena serve list -n demo-ns預期輸出:
NAME TYPE VERSION DESIRED AVAILABLE ADDRESS PORTS GPU fashion-mnist Tensorflow 202111031203 1 1 172.16.XX.XX GRPC:8500,RESTFUL:8501 1預期輸出中的ADDRESS和PORTS可用于集群內調用。
在Jupyter中新建Jupyter Notebook文件,作為請求tf-serving HTTP協議服務的Client。
本示例使用步驟三:模型開發中創建的Jupyter Notebook來發起請求。
本示例初始化代碼中的
server_ip替換為上一步獲取的ADDRESS(172.16.XX.XX)。本示例初始化代碼中的
server_http_port為上一步中獲取的RESTFUL端口(8501)。
Notebook文件的初始化代碼如下所示:
import os import gzip import numpy as np # import matplotlib.pyplot as plt import random import requests import json server_ip = "172.16.XX.XX" server_http_port = 8501 dataset_dir = "/root/data/" def load_data(): files = [ 'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz', 't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz' ] paths = [] for fname in files: paths.append(os.path.join(dataset_dir, fname)) with gzip.open(paths[0], 'rb') as labelpath: y_train = np.frombuffer(labelpath.read(), np.uint8, offset=8) with gzip.open(paths[1], 'rb') as imgpath: x_train = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28) with gzip.open(paths[2], 'rb') as labelpath: y_test = np.frombuffer(labelpath.read(), np.uint8, offset=8) with gzip.open(paths[3], 'rb') as imgpath: x_test = np.frombuffer(imgpath.read(), np.uint8, offset=16).reshape(len(y_test), 28, 28) return (x_train, y_train),(x_test, y_test) def show(idx, title): plt.figure() plt.imshow(test_images[idx].reshape(28,28)) plt.axis('off') plt.title('\n\n{}'.format(title), fontdict={'size': 16}) class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'] (train_images, train_labels), (test_images, test_labels) = load_data() train_images = train_images / 255.0 test_images = test_images / 255.0 # reshape for feeding into the model train_images = train_images.reshape(train_images.shape[0], 28, 28, 1) test_images = test_images.reshape(test_images.shape[0], 28, 28, 1) print('\ntrain_images.shape: {}, of {}'.format(train_images.shape, train_images.dtype)) print('test_images.shape: {}, of {}'.format(test_images.shape, test_images.dtype)) rando = random.randint(0,len(test_images)-1) #show(rando, 'An Example Image: {}'.format(class_names[test_labels[rando]])) # !pip install -q requests # import requests # headers = {"content-type": "application/json"} # json_response = requests.post('http://localhost:8501/v1/models/fashion_model:predict', data=data, headers=headers) # predictions = json.loads(json_response.text)['predictions'] # show(0, 'The model thought this was a {} (class {}), and it was actually a {} (class {})'.format( # class_names[np.argmax(predictions[0])], np.argmax(predictions[0]), class_names[test_labels[0]], test_labels[0])) def request_model(data): headers = {"content-type": "application/json"} json_response = requests.post('http://{}:{}/v1/models/1:predict'.format(server_ip, server_http_port), data=data, headers=headers) print('=======response:', json_response, json_response.text) predictions = json.loads(json_response.text)['predictions'] print('The model thought this was a {} (class {}), and it was actually a {} (class {})'.format(class_names[np.argmax(predictions[0])], np.argmax(predictions[0]), class_names[test_labels[0]], test_labels[0])) #show(0, 'The model thought this was a {} (class {}), and it was actually a {} (class {})'.format( # class_names[np.argmax(predictions[0])], np.argmax(predictions[0]), class_names[test_labels[0]], test_labels[0])) # def request_model_version(data): # headers = {"content-type": "application/json"} # json_response = requests.post('http://{}:{}/v1/models/1/version/1:predict'.format(server_ip, server_http_port), data=data, headers=headers) # print('=======response:', json_response, json_response.text) # predictions = json.loads(json_response.text) # for i in range(0,3): # show(i, 'The model thought this was a {} (class {}), and it was actually a {} (class {})'.format( # class_names[np.argmax(predictions[i])], np.argmax(predictions[i]), class_names[test_labels[i]], test_labels[i])) data = json.dumps({"signature_name": "serving_default", "instances": test_images[0:3].tolist()}) print('Data: {} ... {}'.format(data[:50], data[len(data)-52:])) #request_model_version(data) request_model(data)單擊Jupyter Notebook的
圖標,即可看到以下執行結果:train_images.shape: (60000, 28, 28, 1), of float64 test_images.shape: (10000, 28, 28, 1), of float64 Data: {"signature_name": "serving_default", "instances": ... [0.0], [0.0], [0.0], [0.0], [0.0], [0.0], [0.0]]]]} =======response: <Response [200]> { "predictions": [[7.42696e-07, 6.91237556e-09, 2.66364452e-07, 2.27735413e-07, 4.0373439e-07, 0.00490919966, 7.27086217e-06, 0.0316713452, 0.0010733594, 0.962337255], [0.00685342, 1.8516447e-08, 0.9266119, 2.42278338e-06, 0.0603800081, 4.01338771e-12, 0.00613868702, 4.26091073e-15, 1.35764185e-05, 3.38685469e-10], [1.09047969e-05, 0.999816835, 7.98738e-09, 0.000122893631, 4.85748023e-05, 1.50353979e-10, 3.57102294e-07, 1.89657579e-09, 4.4604468e-07, 9.23274524e-09] ] } The model thought this was a Ankle boot (class 9), and it was actually a Ankle boot (class 9)
常見問題
如何在Jupyter Notebook控制臺安裝常用軟件?
答:可通過執行以下命令在Jupyter Notebook控制臺安裝軟件。
apt-get install ${您需要的軟件}如何解決Jupyter Notebook控制臺字符集亂碼問題?
答:根據以下示例編輯/etc/locale文件后,重新打開Terminal。
LC_CTYPE="da_DK.UTF-8" LC_NUMERIC="da_DK.UTF-8" LC_TIME="da_DK.UTF-8" LC_COLLATE="da_DK.UTF-8" LC_MONETARY="da_DK.UTF-8" LC_MESSAGES="da_DK.UTF-8" LC_PAPER="da_DK.UTF-8" LC_NAME="da_DK.UTF-8" LC_ADDRESS="da_DK.UTF-8" LC_TELEPHONE="da_DK.UTF-8" LC_MEASUREMENT="da_DK.UTF-8" LC_IDENTIFICATION="da_DK.UTF-8" LC_ALL=