本文為您介紹在實際的電商業務中,通過將商品圖片集合的向量化結果存儲在云原生數據倉庫AnalyticDB PostgreSQL版向量檢索引擎中,實現以文搜圖的高效準確檢索。
背景信息
在現實世界中,絕大多數的數據都是以非結構化數據的形式存在,如圖片,音頻,視頻,文本等。這些非結構化數據隨著智慧城市、短視頻、商品個性化推薦、視覺商品搜索等應用的出現而爆發式增長。為了能夠處理這些非結構化數據,通常會使用人工智能技術提取這些非結構化數據的特征,并將其轉化為特征向量,再對這些特征向量進行分析和檢索以實現對非結構化數據的處理。通過構建云原生數據倉庫AnalyticDB PostgreSQL版向量檢索引擎和中文CLIP模型組成以文搜圖的方案體驗,實現高性能圖文多模態檢索,從而體驗向量檢索在業務場景的能力和高性能。
多模態檢索在電商場景中扮演重要的角色,是滿足用戶需求、促成點擊交易不可缺少的一環。 圖文檢索場景中,通過自然語言形式的檢索,從給定的商品圖片池中檢索出相關圖片,是衡量模型多模態理解與匹配的能力。
使用場景
通過AnalyticDB PostgreSQL版向量分析,您可以非常容易地搭建各種智能化應用。
以文搜圖服務,即通過文字檢索圖片的應用服務。
視頻檢索服務,即通過視頻中的某些幀圖片進行視頻圖片檢索。
聲紋檢索服務,即通過音頻匹配音頻的應用服務。
推薦系統服務,即通過用戶特征實現推薦匹配的功能。
基于語義的文本檢索和推薦,通過文本檢索近似文本。
問答機器人,通過與大模型結合搭建高效的問答機器人服務。
文件去重,通過文件指紋特征來去除重復文件。
前提條件
AnalyticDB PostgreSQL版實例資源類型為存儲彈性模式。
注意事項
本方案采用預置數據集的方式進行以文搜圖的方案體驗,不支持通過上傳自有圖片進行搜索體驗。預置數據集詳情,請參見數據集。
在釋放AnalyticDB PostgreSQL版實例時,AnalyticDB PostgreSQL版創建的安全組無法釋放,需要在實例釋放6個小時后釋放安全組。即通過本解決方案創建的資源在一鍵釋放后,在ECS上會有一個安全組的殘留。
說明殘留安全組不會帶來業務影響,本方案涉及到的云資源已經釋放,您可以在后續合適的時間(即6個小時后)登錄ECS控制臺刪除該安全組。
檢索架構
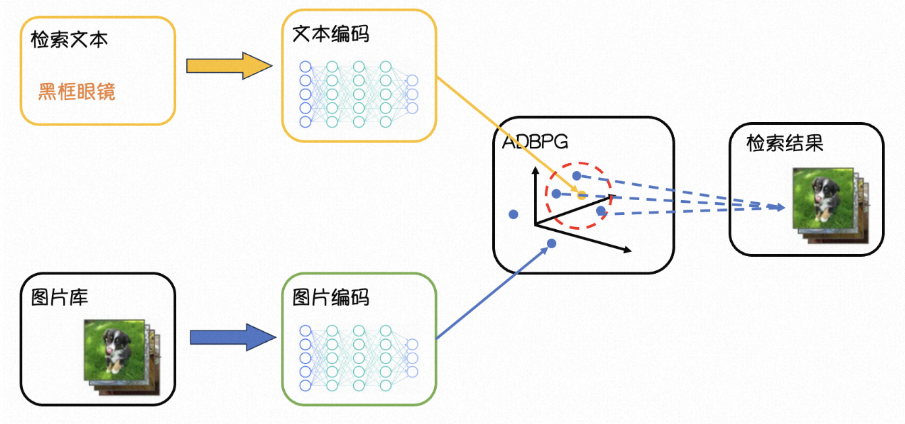
為了建立圖像和自然語言的聯系,本解決方案采用CLIP模型對文本圖片編碼。CLIP模型是一種基于自然語言處理和計算機視覺的神經網絡模型,可以同時理解文本和圖像,并在二者之間建立聯系。
在以文搜圖方案中,CLIP模型作用主要是文本和圖像的匹配。CLIP模型可以將文本和圖像進行編碼,并計算它們之間的相似度。該相似度可以用來評估一個圖像是否與輸入的文本描述相匹配。在以文搜圖中,用戶可以輸入文本描述,CLIP模型自動匹配相關的圖像。
本解決?案將基于AnalyticDB PostgreSQL版的向量檢索引擎,實現?本向量到圖?向量的快速檢索。
向量數據集,表結構如下:
CREATE TABLE IF NOT EXISTS public.text_search_graphic ( id INTEGER NOT NULL, path TEXT, image_vector REAL[], PRIMARY KEY(id) ) DISTRIBUTED BY(id); ALTER TABLE public.text_search_graphic ALTER COLUMN image_vector SET STORAGE PLAIN;向量索引結構如下:
CREATE INDEX ON public.text_search_graphic USING ann (image_vector) WITH (dim = '1000', hnsw_m = '100', pq_enable='0');使?如下SQL語句完成對?本向量的最近鄰查詢:
SELECT id, path, l2_distance({image_vector}, Array{text_embedding}::real[]) AS similarity FROM public.text_search_graphic ORDER BY {image_vector} <-> Array{text_embedding}::real[] LIMIT {top_k};其中
image_vector為存儲向量數據的列名,text_embedding為 ?本的編碼向量。l2_distance函數計算圖像向量與?本描述向量的歐式距離,并重命名為similarity列。該SQL按照圖像向量與?本描述向量的距離進?排序,以便將相似的圖像放在前 ?,并返回最相似的top_k張圖像。