在AnalyticDB PostgreSQL版查詢執行過程中,當集群內存不足時,數據庫可能會選擇將臨時結果暫存到磁盤。由于磁盤操作相對內存訪問緩慢,避免查詢執行過程中的算子下盤有助于提高查詢效率。
算子下盤常見原因
在數據量較大的表上執行SORT、JOIN、HASH等操作時,可能由于內存不足導致臨時結果落盤。您通過觀察執行計劃(explain analyze)可以辨認發生了算子下盤:
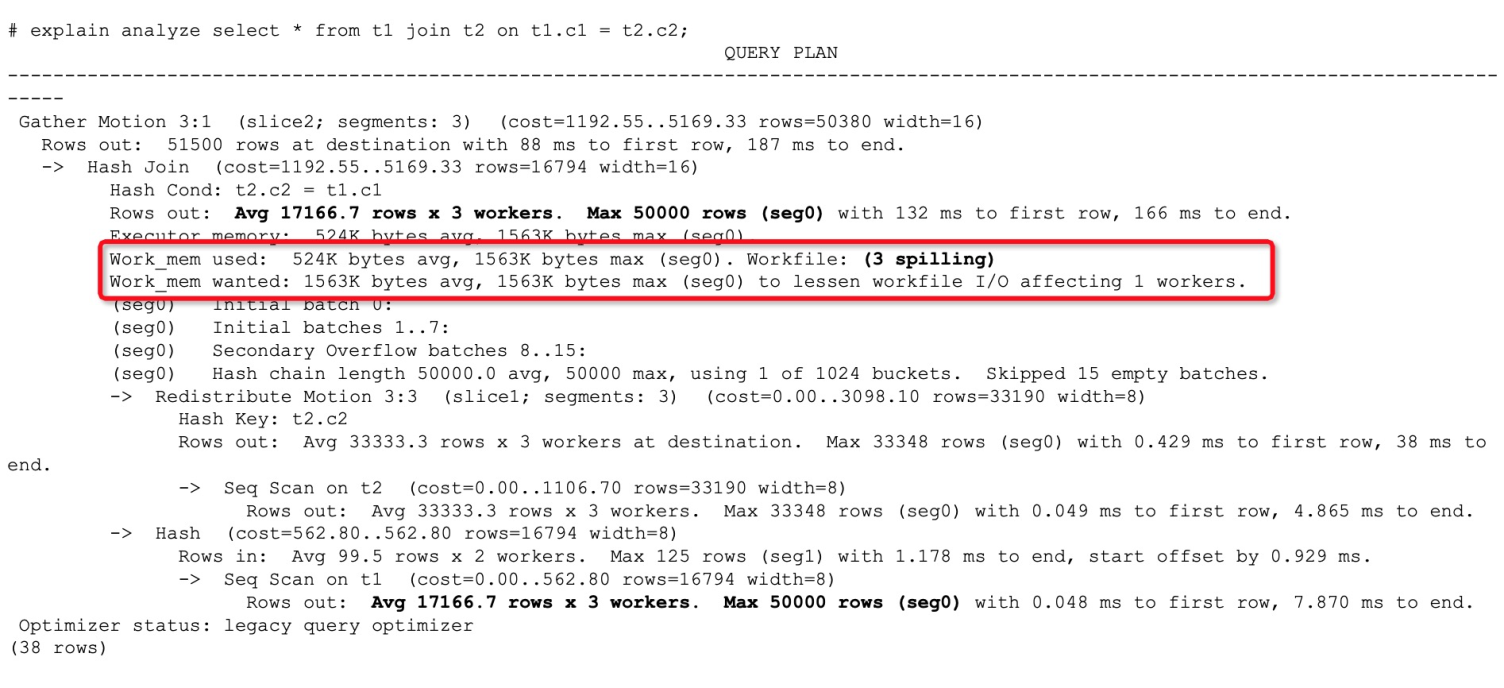
上圖是一個發生了算子落盤的查詢計劃例子,執行計劃中Workfile這一項顯示了是否發生了算子落盤。而不發生算子落盤的執行計劃對應項會顯示為0,如下圖所示:
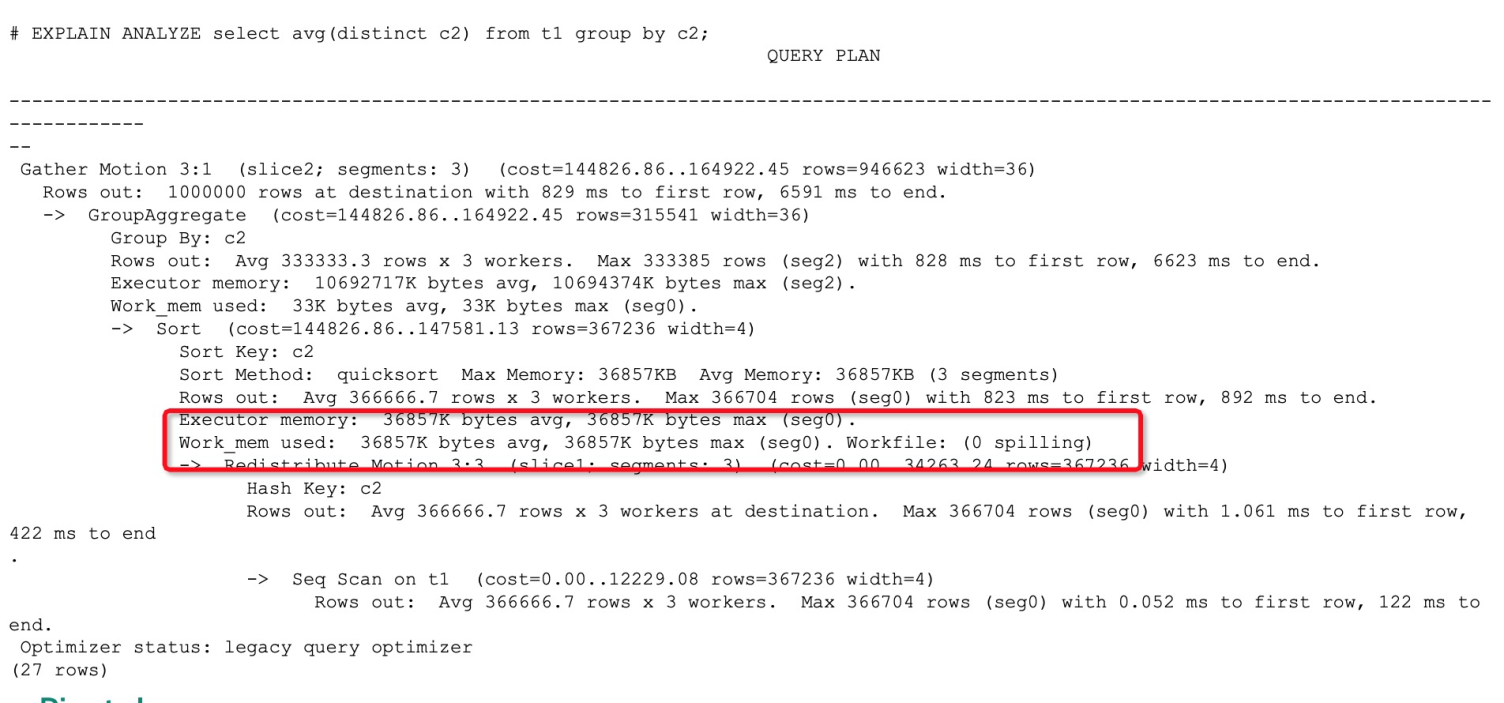
產生算子下盤的常見原因包括:
查詢能夠使用的內存太小。
查詢的計算量過大,需要的內存太大。
產生了數據傾斜。
下面詳細介紹三種原因導致的算子下盤場景及解決方法。
常見算子下盤場景及解決方法
查詢內存太小導致的算子下盤
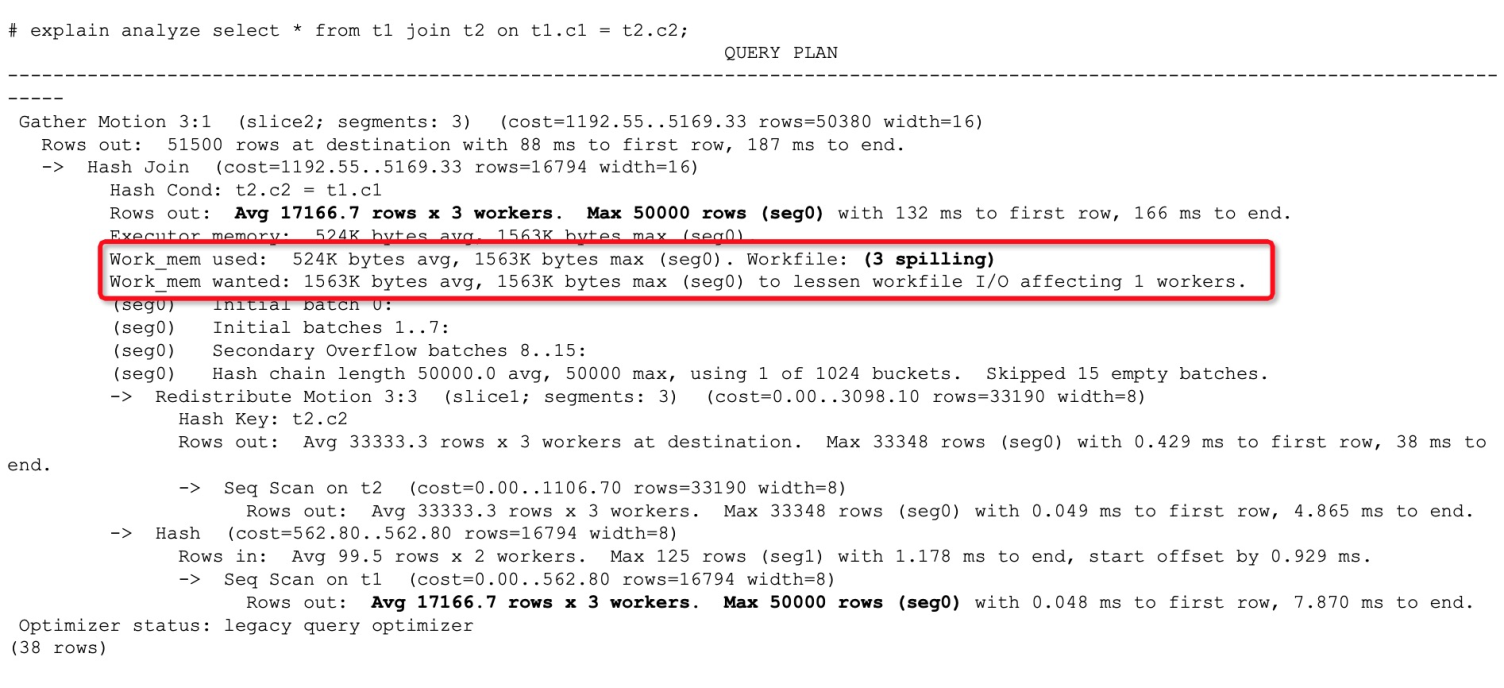
通過觀察執行計劃發現,算子需要的內存并不大,只有幾K或幾M,但還是發生了算子下盤。這種情況往往是查詢能夠使用的內存調小導致的,原因可能是受到了resource group或resource queue的限制,或者statement_mem參數本身設置的不合理。
對于這種情況,您可以通過調大statement_mem參數到一個合理的參數來避免算子下盤:
SET statement_mem TO '256MB';計算量過大導致的算子下盤
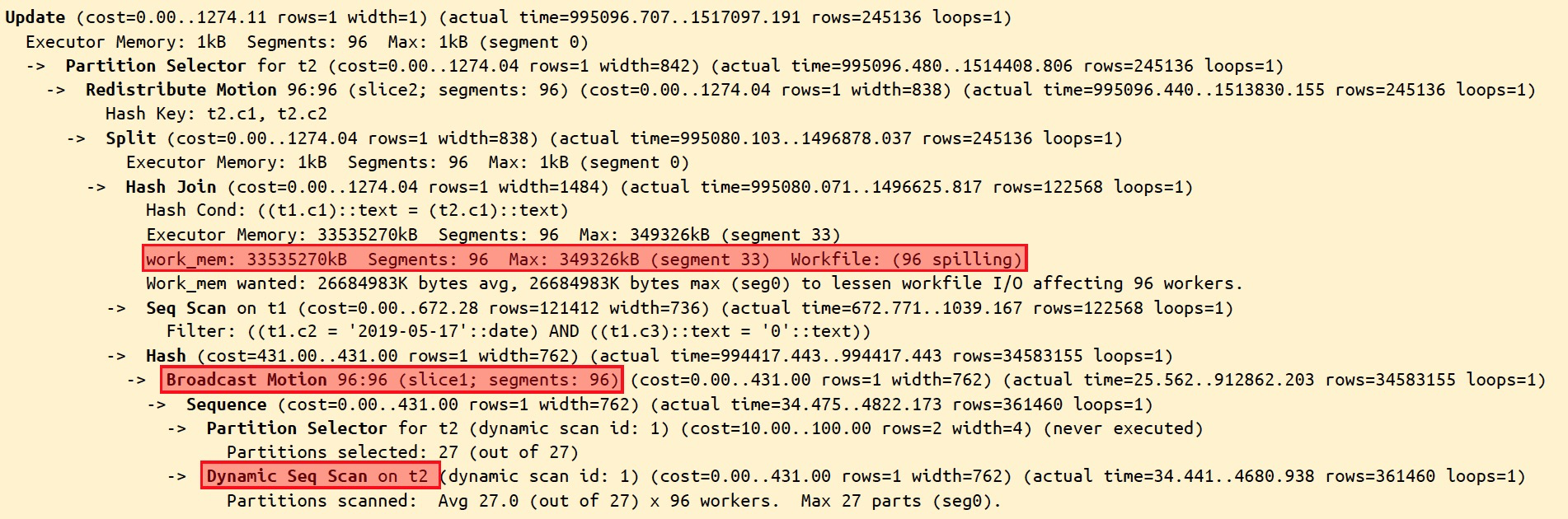
在某些時候,我們發現我們已經設置了較大的查詢內存(statement_mem),但我們通過執行計劃發現,算子執行過程中需要的內存遠遠大于我們設置的內存,這個時候往往是計算量過大導致的。這個時候我們需要考慮能夠執行analyze、建立索引等方式減少算子執行中的計算量。
以圖中的執行計劃為例,我們發現較大的算子落盤,進一步分析我們發現,在這個執行計劃中,錯誤了估計了t2子表的行數(rows),導致t2一個大表被估計為1行的小表,進行了broadcast,并做了hashjoin的內標,導致了巨大的計算量。我們對t2表執行了analyze之后,消除了算子下盤。
數據傾斜導致的算子下盤
數據傾斜也是一種常見的會導致算子下盤的因素,數據傾斜會導致單個Segment上的數據量和計算量遠遠超過其他Segment,導致可用內存不夠算子下盤。對于數據傾斜的檢測和消除,請參見數據傾斜診斷。