本文介紹云消息隊列 Kafka 版的典型應用場景,包括網站活動跟蹤、日志聚合、數據處理、數據中轉樞紐。
網站活動跟蹤
成功的網站運營需要對站點的用戶行為進行分析。通過云消息隊列 Kafka 版的發布/訂閱模型,您可以實時收集網站活動數據(例如注冊、登錄、充值、支付、購買),根據業務數據類型將消息發布到不同的Topic,然后利用訂閱消息的實時投遞,將消息流用于實時處理、實時監控或者加載到Hadoop、MaxCompute等離線數據倉庫系統進行離線處理。
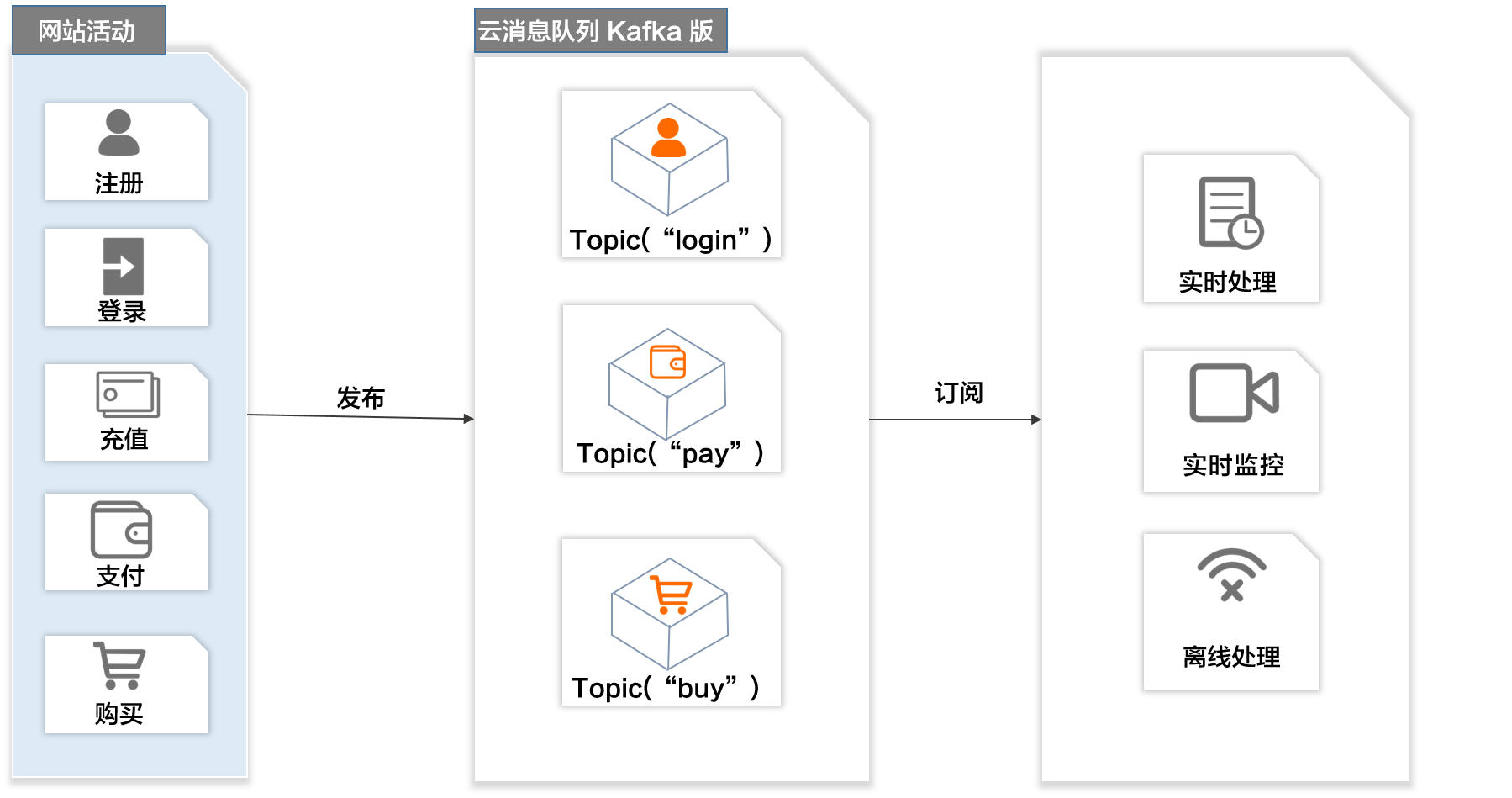
云消息隊列 Kafka 版用于網站活動跟蹤具備以下優勢:
高吞吐:網站用戶產生的行為信息較為龐大,需要較高的吞吐量來支持。
彈性擴容:網站活動導致行為數據激增,云平臺可以快速按需擴容。
大數據分析:可對接Storm、Spark等實時數據處理引擎,亦可對接Hadoop等離線數據倉庫系統。
日志聚合
許多公司,例如淘寶、天貓等,每天都會產生大量的日志(一般為流式數據,例如搜索引擎PV、查詢等)。相較于以日志為中心的系統,例如Scribe和Flume,云消息隊列 Kafka 版在具備高性能的同時,可以實現更強的數據持久化以及更短的端到端響應時間。云消息隊列 Kafka 版的這種特性決定它適合作為日志收集中心。云消息隊列 Kafka 版忽略掉文件的細節,可以將多臺主機或應用的日志數據抽象成一個個日志或事件的消息流,異步發送到云消息隊列 Kafka 版集群,從而實現非常低的RT。云消息隊列 Kafka 版客戶端可批量提交消息和壓縮消息,對生產者而言幾乎感覺不到性能的開支。消費者可以使用Hadoop、MaxCompute等離線倉庫存儲和Storm、Spark等實時在線分析系統對日志進行統計分析。
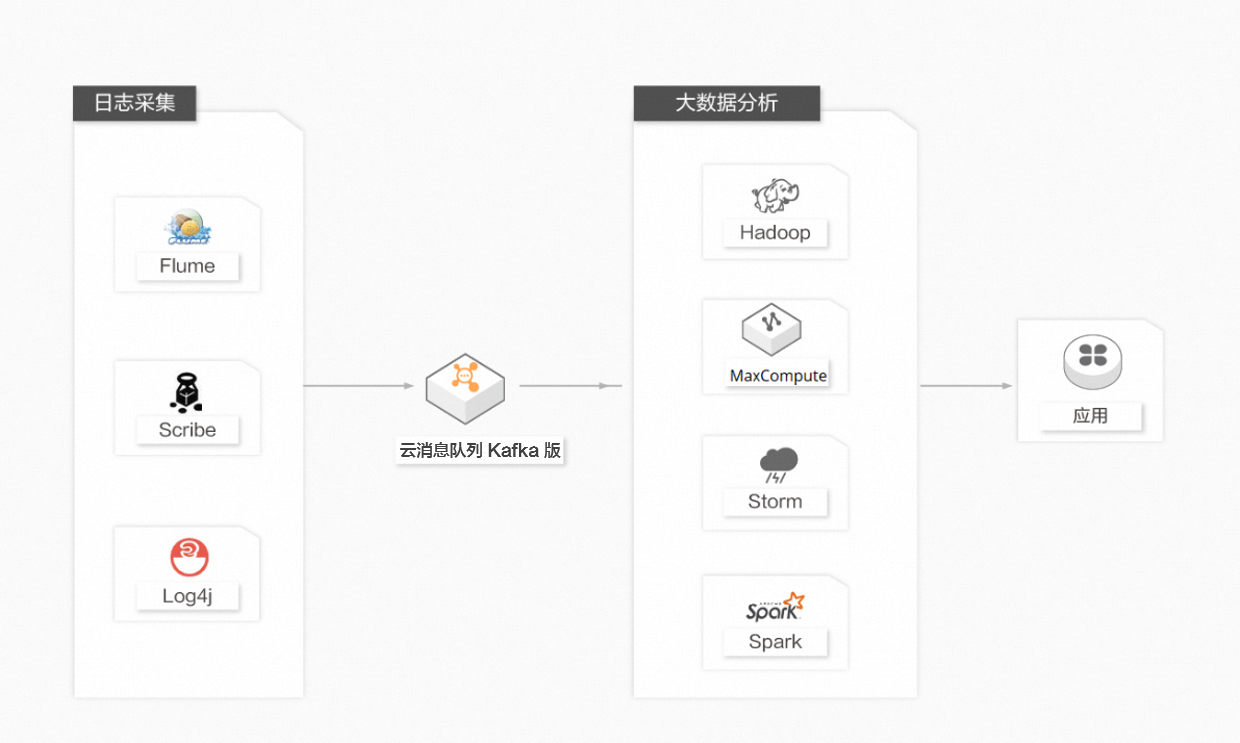
云消息隊列 Kafka 版用于數據聚合具備以下優勢:
應用與分析解耦:構建應用系統和分析系統的橋梁,并將它們之間的關聯解耦。
高可擴展性:具有高可擴展性,即當數據量增加時可通過增加節點快速水平擴展。
在線或離線分析系統:支持實時在線分析系統和類似于Hadoop的離線分析系統。
數據處理
在很多領域,如股市走向分析、氣象數據測控、網站用戶行為分析,由于數據產生快、實時性強且量大,您很難統一采集這些數據并將其入庫存儲后再做處理,這便導致傳統的數據處理架構不能滿足需求。與傳統架構不同,云消息隊列 Kafka 版以及Storm、Samza、Spark等數據處理引擎的出現,就是為了更好地解決這類數據在處理過程中遇到的問題,數據處理模型能實現在數據流動的過程中對數據進行實時地捕捉和處理,并根據業務需求進行計算分析,最終把結果保存或者分發給需要的組件。
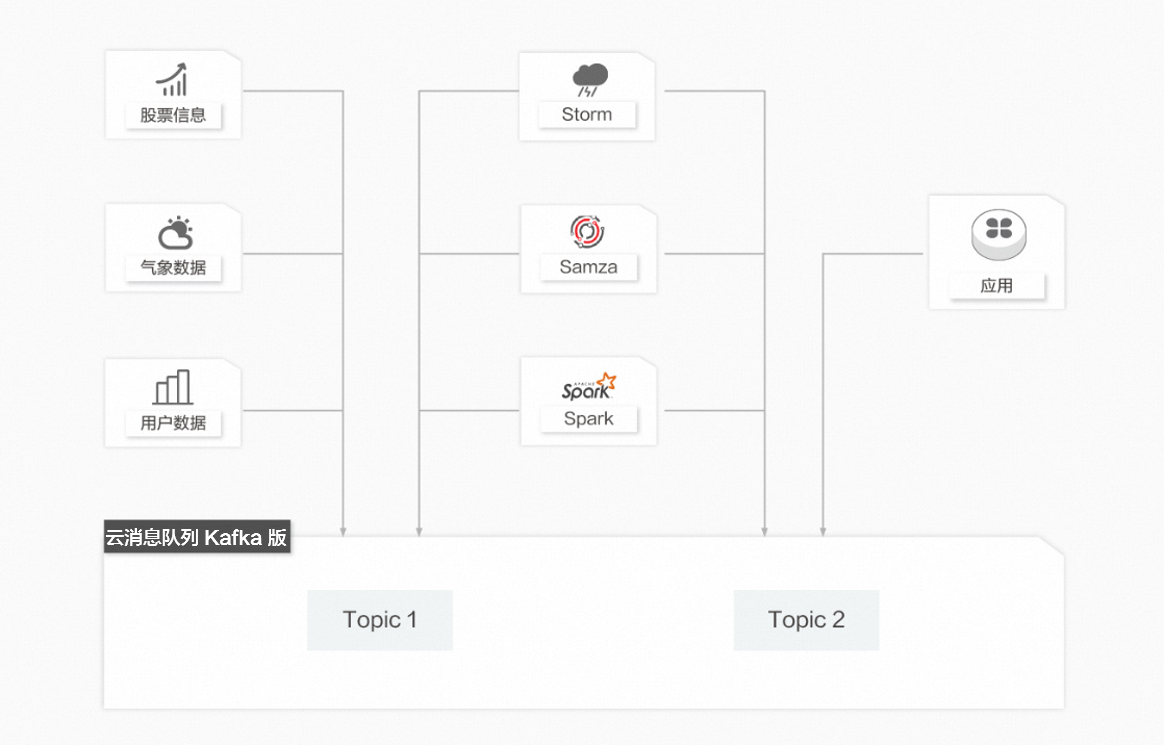
云消息隊列 Kafka 版用于數據處理具備以下優勢:
流動的數據:在數據流動的過程中對數據進行實時地捕捉和處理,并根據業務需求進行計算分析。
高可擴展性:由于數據產生的速度快且數據量大,需要高可擴展性。
數據處理引擎:可對接開源Storm、Samza、Spark以及EMR、Blink、StreamCompute等阿里云產品。
數據中轉樞紐
近10多年來,諸如KV存儲(HBase)、搜索(Elasticsearch)、流式處理(Storm、Spark、Samza)、時序數據庫(OpenTSDB)等專用系統應運而生。這些系統是為單一的目標而產生的,因其簡單性使得在商業硬件上構建分布式系統變得更加容易且性價比更高。通常,同一份數據集需要被注入到多個專用系統內。例如,當應用日志用于離線日志分析時,搜索單個日志記錄同樣不可或缺,而構建各自獨立的工作流來采集每種類型的數據再導入到各自的專用系統顯然不切實際,利用云消息隊列 Kafka 版作為數據中轉樞紐,同份數據可以被導入到不同專用系統中。
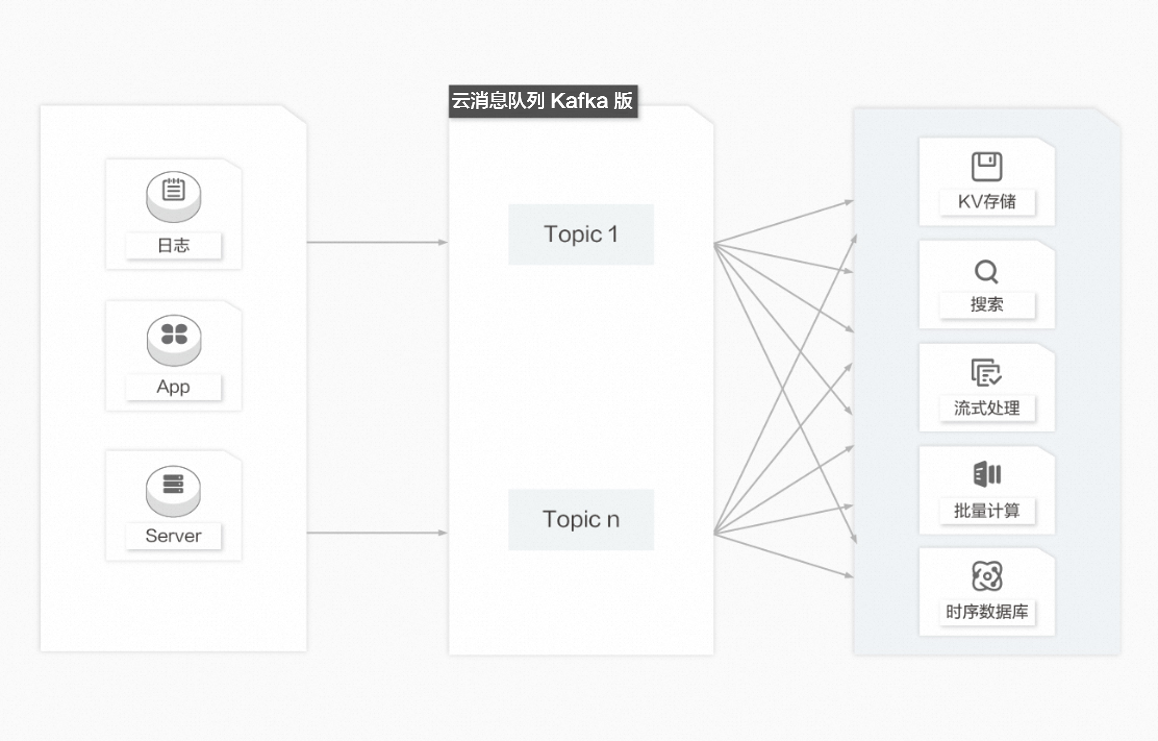
云消息隊列 Kafka 版作為數據中轉樞紐具備以下優勢:
高容量存儲:能在商業硬件上存儲高容量的數據,實現可橫向擴展的分布式系統。
一對多消費模型:發布/訂閱模型,支持同份數據集能同時被消費多次。
同時支持實時和批處理:支持本地數據持久化和Page Cache,在無性能損耗的情況下能同時傳送消息到實時和批處理的消費者。