本文說明如何創建MaxCompute Sink Connector將數據從云消息隊列 Kafka 版實例的數據源Topic導出至MaxCompute的表。
前提條件
在創建MaxCompute Sink Connector前,請確保您已完成以下操作:- 云消息隊列 Kafka 版
- 為云消息隊列 Kafka 版實例開啟Connector。更多信息,請參見開啟Connector。
- 為云消息隊列 Kafka 版實例創建數據源Topic。更多信息,請參見步驟一:創建Topic。
本文以名稱為maxcompute-test-input的Topic為例。
- 大數據計算服務(MaxCompute)
- 通過MaxCompute客戶端創建表。更多信息,請參見創建表。
本文以名稱為connector_test的項目下名稱為test_kafka的表為例。該表的建表語句如下:
CREATE TABLE IF NOT EXISTS test_kafka(topic STRING,partition BIGINT,offset BIGINT,key STRING,value STRING) PARTITIONED by (pt STRING);
- 通過MaxCompute客戶端創建表。更多信息,請參見創建表。
- 可選:事件總線EventBridge說明 僅在您創建的Connector任務所屬實例的地域為華東1(杭州)或西南1(成都)時,需要完成該操作。
注意事項
- 僅支持在同地域內,將數據從云消息隊列 Kafka 版實例的數據源Topic導出至MaxCompute。Connector的限制說明,請參見使用限制。
- 如果Connector所屬實例的地域為華東1(杭州)或西南1(成都),該功能會部署至事件總線EventBridge。
- 事件總線EventBridge目前免費供您使用。更多信息,請參見計費說明。
- 創建Connector時,事件總線EventBridge會為您自動創建服務關聯角色AliyunServiceRoleForEventBridgeSourceKafka和AliyunServiceRoleForEventBridgeConnectVPC。
- 如果未創建服務關聯角色,事件總線EventBridge會為您自動創建對應的服務關聯角色,以便允許事件總線EventBridge使用此角色訪問云消息隊列 Kafka 版和專有網絡VPC。
- 如果已創建服務關聯角色,事件總線EventBridge不會重復創建。
- 部署到事件總線EventBridge的任務暫時不支持查看任務運行日志。Connector任務執行完成后,您可以在訂閱數據源Topic的Group中,通過消費情況查看任務進度。具體操作,請參見查看消費狀態。
操作流程
使用MaxCompute Sink Connector將數據從云消息隊列 Kafka 版實例的數據源Topic導出至MaxCompute的表操作流程如下:
- 授予云消息隊列 Kafka 版訪問MaxCompute的權限。
- 可選:創建MaxCompute Sink Connector依賴的Topic和Group
如果您不需要自定義Topic和Group,您可以直接跳過該步驟,在下一步驟選擇自動創建。
重要 部分MaxCompute Sink Connector依賴的Topic的存儲引擎必須為Local存儲,大版本為0.10.2的云消息隊列 Kafka 版實例不支持手動創建Local存儲的Topic,只支持自動創建。 - 創建并部署MaxCompute Sink Connector
- 結果驗證
創建RAM角色
由于RAM角色不支持直接選擇云消息隊列 Kafka 版作為受信服務,您在創建RAM角色時,需要選擇任意支持的服務作為受信服務。RAM角色創建后,手動修改信任策略。
- 登錄訪問控制控制臺。
- 在左側導航欄,選擇。
- 在角色頁面,單擊創建角色。
- 在創建角色面板,執行以下操作。
- 選擇可信實體類型為阿里云服務,然后單擊下一步。
- 在角色類型區域,選擇普通服務角色,在角色名稱文本框,輸入AliyunKafkaMaxComputeUser1,從選擇受信服務列表,選擇大數據計算服務,然后單擊完成。
- 在角色頁面,找到AliyunKafkaMaxComputeUser1,單擊AliyunKafkaMaxComputeUser1。
- 在AliyunKafkaMaxComputeUser1頁面,單擊信任策略管理頁簽,單擊修改信任策略。
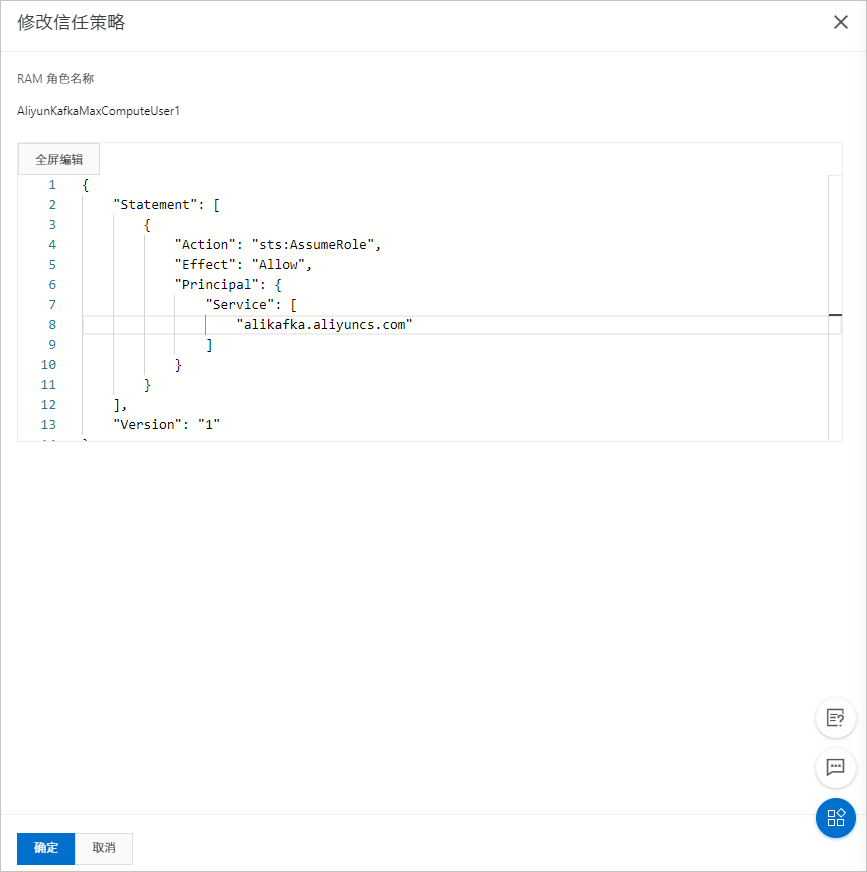
- 在修改信任策略面板,將腳本中odps替換為alikafka,單擊確定。
替換后的策略如下所示。
添加權限
為使Connector將消息同步到MaxCompute表,您需要為創建的RAM角色至少授予以下權限:
| 客體 | 操作 | 描述 |
|---|---|---|
| Project | CreateInstance | 在項目中創建實例。 |
| Table | Describe | 讀取表的元信息。 |
| Table | Alter | 修改表的元信息或添加刪除分區。 |
| Table | Update | 覆蓋或添加表的數據。 |
關于以上權限的詳細說明以及授權操作,請參見MaxCompute權限。
為本文創建的AliyunKafkaMaxComputeUser1添加權限的示例步驟如下:
- 登錄MaxCompute客戶端。
- 執行以下命令添加RAM角色為用戶。
add user `RAM$<accountid>:role/aliyunkafkamaxcomputeuser1`;說明 將<accountid>替換為您自己的阿里云賬號ID。 - 為RAM用戶授予訪問MaxCompute所需的最小權限。
創建MaxCompute Sink Connector依賴的Topic
您可以在云消息隊列 Kafka 版控制臺手動創建MaxCompute Sink Connector依賴的5個Topic,包括:任務位點Topic、任務配置Topic、任務狀態Topic、死信隊列Topic以及異常數據Topic。每個Topic所需要滿足的分區數與存儲引擎會有差異,具體信息,請參見配置源服務參數列表。
- 登錄云消息隊列 Kafka 版控制臺。
- 在概覽頁面的資源分布區域,選擇地域。重要 Topic需要在應用程序所在的地域(即所部署的ECS的所在地域)進行創建。Topic不能跨地域使用。例如Topic創建在華北2(北京)這個地域,那么消息生產端和消費端也必須運行在華北2(北京)的ECS。
- 在實例列表頁面,單擊目標實例名稱。
- 在左側導航欄,單擊Topic 管理。
- 在Topic 管理頁面,單擊創建 Topic。
- 在創建 Topic面板,設置Topic屬性,然后單擊確定。
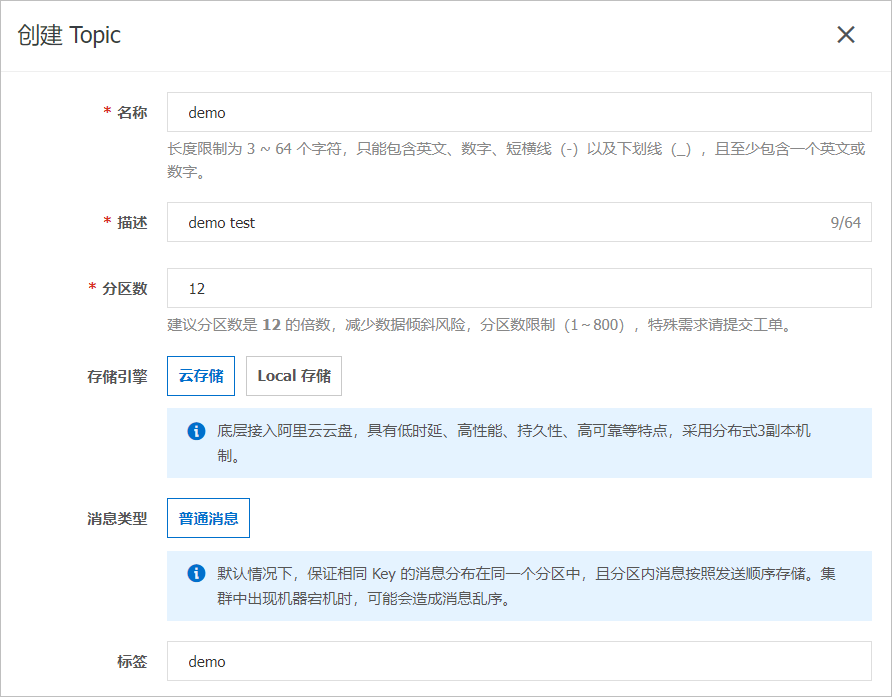
參數 說明 示例 名稱 Topic名稱。 demo 描述 Topic的簡單描述。 demo test 分區數 Topic的分區數量。 12 存儲引擎 說明 當前僅專業版實例支持選擇存儲引擎類型,標準版暫不支持,默認選擇為云存儲類型。Topic消息的存儲引擎。 云消息隊列 Kafka 版支持以下兩種存儲引擎。
- 云存儲:底層接入阿里云云盤,具有低時延、高性能、持久性、高可靠等特點,采用分布式3副本機制。實例的規格類型為標準版(高寫版)時,存儲引擎只能為云存儲。
- Local 存儲:使用原生Kafka的ISR復制算法,采用分布式3副本機制。
云存儲 消息類型 Topic消息的類型。 - 普通消息:默認情況下,保證相同Key的消息分布在同一個分區中,且分區內消息按照發送順序存儲。集群中出現機器宕機時,可能會造成消息亂序。當存儲引擎選擇云存儲時,默認選擇普通消息。
- 分區順序消息:默認情況下,保證相同Key的消息分布在同一個分區中,且分區內消息按照發送順序存儲。集群中出現機器宕機時,仍然保證分區內按照發送順序存儲。但是會出現部分分區發送消息失敗,等到分區恢復后即可恢復正常。當存儲引擎選擇Local 存儲時,默認選擇分區順序消息。
普通消息 日志清理策略 Topic日志的清理策略。 當存儲引擎選擇Local 存儲(當前僅專業版實例支持選擇存儲引擎類型為Local存儲,標準版暫不支持)時,需要配置日志清理策略。
云消息隊列 Kafka 版支持以下兩種日志清理策略。
- Delete:默認的消息清理策略。在磁盤容量充足的情況下,保留在最長保留時間范圍內的消息;在磁盤容量不足時(一般磁盤使用率超過85%視為不足),將提前刪除舊消息,以保證服務可用性。
- Compact:使用Kafka Log Compaction日志清理策略。Log Compaction清理策略保證相同Key的消息,最新的value值一定會被保留。主要適用于系統宕機后恢復狀態,系統重啟后重新加載緩存等場景。例如,在使用Kafka Connect或Confluent Schema Registry時,需要使用Kafka Compact Topic存儲系統狀態信息或配置信息。重要 Compact Topic一般只用在某些生態組件中,例如Kafka Connect或Confluent Schema Registry,其他情況的消息收發請勿為Topic設置該屬性。具體信息,請參見云消息隊列 Kafka 版Demo庫。
Compact 標簽 Topic的標簽。 demo 創建完成后,在Topic 管理頁面的列表中顯示已創建的Topic。
創建MaxCompute Sink Connector依賴的Group
您可以在云消息隊列 Kafka 版控制臺手動創建MaxCompute Sink Connector數據同步任務使用的Group。該Group的名稱必須為connect-任務名稱,具體信息,請參見配置源服務參數列表。
- 登錄云消息隊列 Kafka 版控制臺。
- 在概覽頁面的資源分布區域,選擇地域。
- 在實例列表頁面,單擊目標實例名稱。
- 在左側導航欄,單擊Group 管理。
- 在Group 管理頁面,單擊創建 Group。
- 在創建 Group面板的Group ID文本框輸入Group的名稱,在描述文本框簡要描述Group,并給Group添加標簽,單擊確定。創建完成后,在Group 管理頁面的列表中顯示已創建的Group。
創建并部署MaxCompute Sink Connector
創建并部署用于將數據從云消息隊列 Kafka 版同步至MaxCompute的MaxCompute Sink Connector。
- 登錄云消息隊列 Kafka 版控制臺。
- 在概覽頁面的資源分布區域,選擇地域。
- 在左側導航欄,單擊Connector 任務列表。
- 在Connector 任務列表頁面,從選擇實例的下拉列表選擇Connector所屬的實例,然后單擊創建 Connector。
- 在創建 Connector配置向導面頁面,完成以下操作。
- 創建完成后,在Connector 任務列表頁面,找到創建的Connector ,單擊其操作列的部署。
發送測試消息
部署MaxCompute Sink Connector后,您可以向云消息隊列 Kafka 版的數據源Topic發送消息,測試數據能否被同步至MaxCompute。
- 在Connector 任務列表頁面,找到目標Connector,在其右側操作列,單擊測試。
- 在發送消息面板,發送測試消息。
- 發送方式選擇控制臺。
- 在消息 Key文本框中輸入消息的Key值,例如demo。
- 在消息內容文本框輸入測試的消息內容,例如 {"key": "test"}。
- 設置發送到指定分區,選擇是否指定分區。
- 單擊是,在分區 ID文本框中輸入分區的ID,例如0。如果您需查詢分區的ID,請參見查看分區狀態。
- 單擊否,不指定分區。
- 發送方式選擇Docker,執行運行 Docker 容器生產示例消息區域的Docker命令,發送消息。
- 發送方式選擇SDK,根據您的業務需求,選擇需要的語言或者框架的SDK以及接入方式,通過SDK發送消息。
- 發送方式選擇控制臺。
查看表數據
向云消息隊列 Kafka 版的數據源Topic發送消息后,在MaxCompute客戶端查看表數據,驗證是否收到消息。
查看本文寫入的test_kafka的示例步驟如下:
- 登錄MaxCompute客戶端。
- 執行以下命令查看表的數據分區。
show partitions test_kafka;返回結果示例如下:pt=11-17-2020 15 OK - 執行以下命令查看分區的數據。
select * from test_kafka where pt ="11-17-2020 14";返回結果示例如下:+----------------------+------------+------------+-----+-------+---------------+ | topic | partition | offset | key | value | pt | +----------------------+------------+------------+-----+-------+---------------+ | maxcompute-test-input| 0 | 0 | 1 | 1 | 11-17-2020 14 | +----------------------+------------+------------+-----+-------+---------------+