本文介紹如何使用DataWorks數據同步功能,將云消息隊列 Kafka 版集群上的數據遷移至阿里云大數據計算服務MaxCompute,方便您對離線數據進行分析加工。
背景信息
大數據計算服務MaxCompute(原ODPS)是一種大數據計算服務,能提供快速、完全托管免運維的EB級云數據倉庫解決方案。
DataWorks基于MaxCompute計算和存儲,提供工作流可視化開發、調度運維托管的一站式海量數據離線加工分析平臺。在數加(一站式大數據平臺)中,DataWorks控制臺即為MaxCompute控制臺。MaxCompute和DataWorks一起向用戶提供完善的數據處理和數倉管理能力,以及SQL、MR、Graph等多種經典的分布式計算模型,能夠更快速地解決用戶海量數據計算問題,有效降低企業成本,保障數據安全。
本教程旨在幫助您使用DataWorks,將云消息隊列 Kafka 版中的數據導入至MaxCompute,來進一步探索大數據的價值。
前提條件
云消息隊列 Kafka 版實例版本需要大于等于0.10.2小于等于2.2.x。
1.準備云消息隊列 Kafka 版數據
向Topic testkafka中寫入數據,以作為遷移至MaxCompute中的數據。由于云消息隊列 Kafka 版用于處理流式數據,您可以持續不斷地向其中寫入數據。為保證測試結果,建議您寫入10條以上的數據。
在概覽頁面的資源分布區域,選擇地域。
在實例列表頁面,單擊目標實例名稱。
在左側導航欄,單擊Topic 管理。
在Topic 管理頁面,找到目標Topic,在其操作列中,選擇。
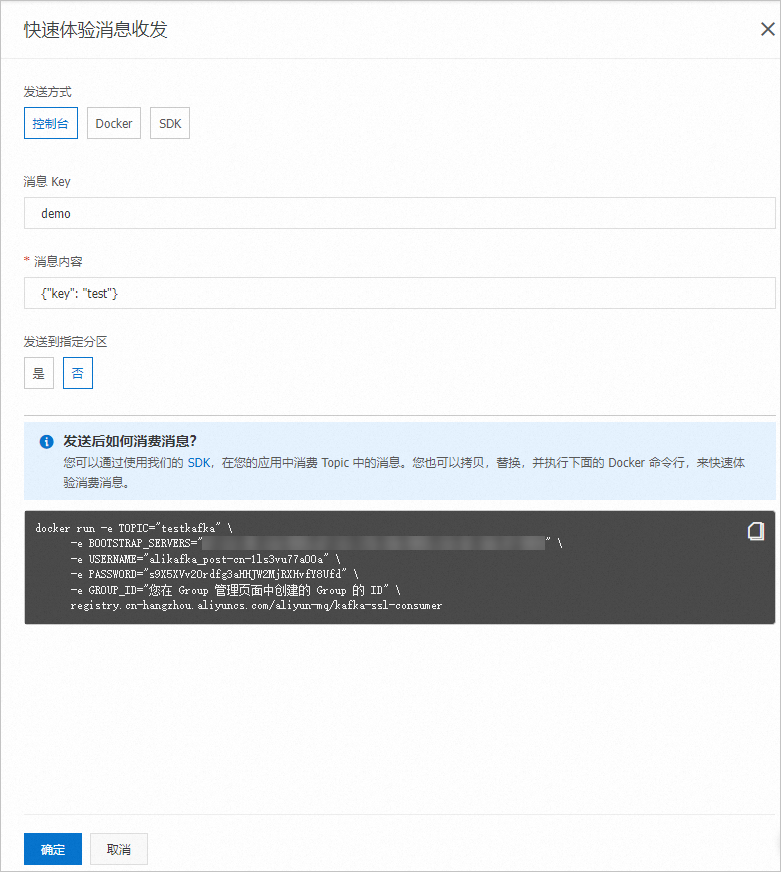
在快速體驗消息收發面板,發送如下的測試消息。
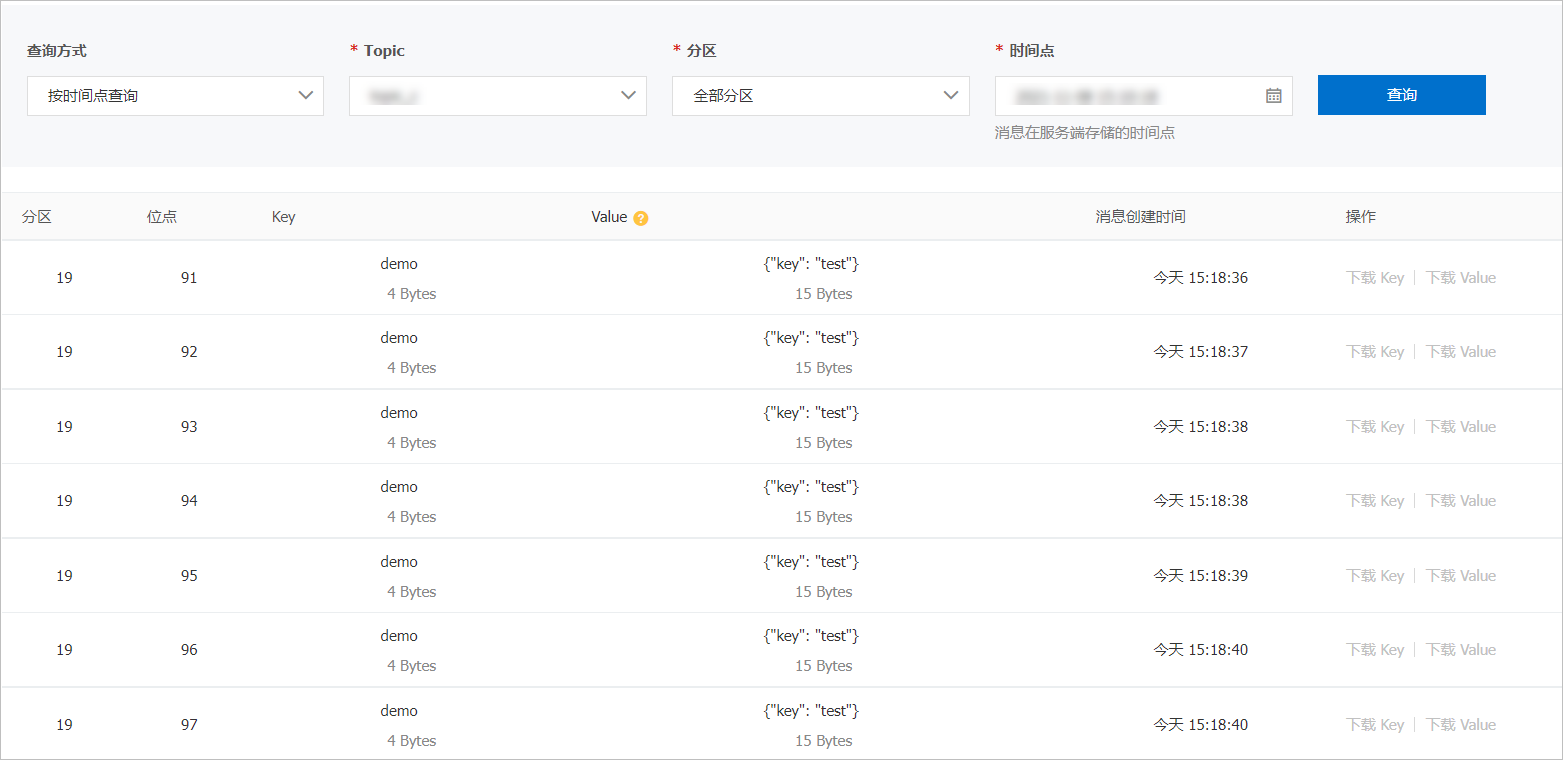
在左側導航欄,單擊消息查詢,然后在消息查詢頁面,選擇查詢方式、所屬的Topic、分區等信息,單擊查詢,查看之前寫入的Topic的數據。
關于消息查詢的更多信息,請參見消息查詢。以按時間查詢為例,查詢的一部分消息如下截圖:
2.創建MaxCompute項目
2.1.開通MaxCompute(可選)
只有開通了MaxCompute,才可以在MaxCompute中執行創建項目等操作。具體操作,請參見開通MaxCompute。
2.2.創建MaxCompute項目
本文以在華東1(杭州)地域創建名為kafka_bigdata_doc的項目為例。具體操作,請參見通過MaxCompute控制臺創建項目。
3.創建DataWorks工作空間
3.1.開通DataWorks(可選)
當前所在地域首次開通DataWorks服務時,必須購買DataWorks任意產品版本和按量付費新版資源組,才能開通并使用DataWorks。具體操作,請參見開通DataWorks服務。
3.2.創建工作空間
本文以在華東1(杭州)地域創建名為kafka_workspace的工作空間為例。具體操作,請參見創建工作空間。
4.添加數據源
4.1.創建獨享數據集成資源組
創建一個名為kafka_dx的獨享數據集成資源組。具體操作,請參見購買資源組。
綁定3.創建DataWorks工作空間步驟中創建的名為kafka_workspace的工作空間。具體操作,請參見綁定歸屬工作空間。
4.2.創建MaxCompute數據源
登錄DataWorks控制臺,切換至目標地域后,選擇左側導航欄的,在下拉框中選擇對應工作空間后單擊進入管理中心。
進入工作空間管理中心頁面后,選擇左側導航欄的,進入數據源頁面。
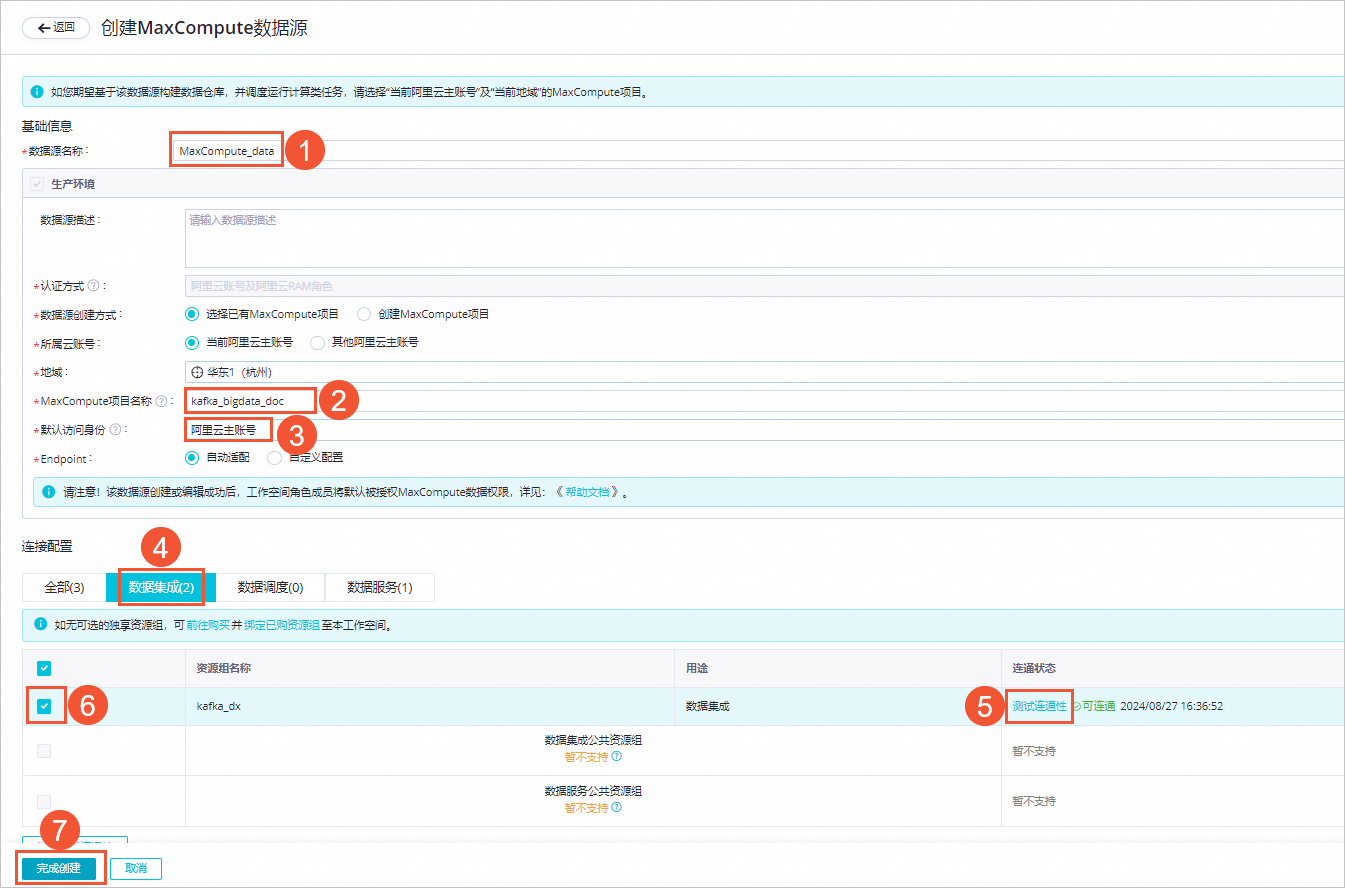
單擊新增數據源,選擇MaxCompute,根據界面指引創建數據源。如下圖所示,創建一個名為MaxCompute_data的數據源:
4.3.創建Kafka數據源
登錄DataWorks控制臺,切換至目標地域后,選擇左側導航欄的,在下拉框中選擇對應工作空間后單擊進入管理中心。
進入工作空間管理中心頁面后,選擇左側導航欄的,進入數據源頁面。
單擊新增數據源,選擇Kafka,根據界面指引創建數據源。如下圖所示,創建一個名為kafka_data的數據源:
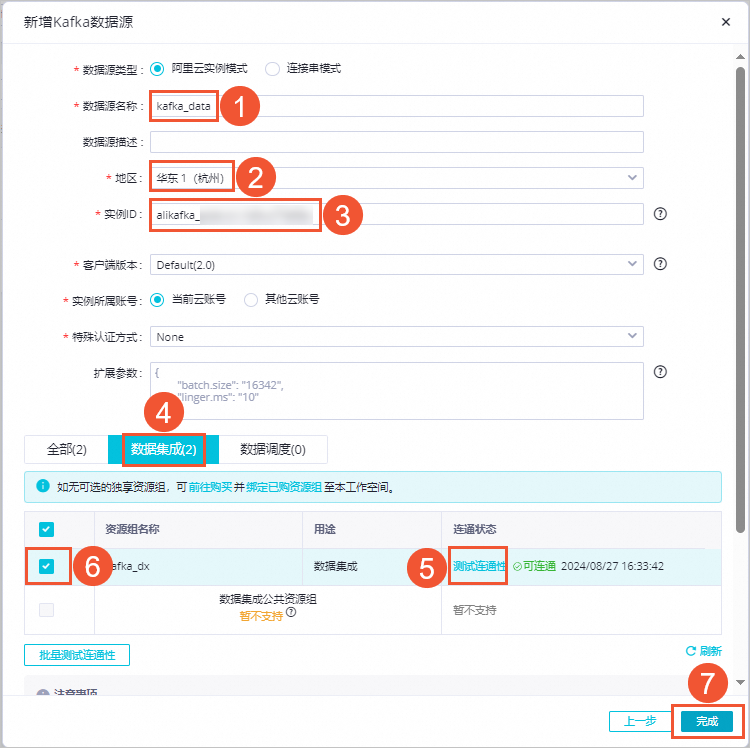 說明
說明實例ID填寫已部署的云消息隊列 Kafka 版的實例ID。
測試連通性時,如果出現無法連通的情況,單擊自助排查解決,在連通性診斷工具面板中,按照指引完成測試即可。
5.創建DataWorks表
您需創建DataWorks表,以保證大數據計算服務MaxCompute可以順利接收云消息隊列 Kafka 版數據。為測試便利,本文以使用非分區表為例。
進入數據開發頁面。
登錄DataWorks控制臺。
在左側導航欄,單擊工作空間。
在目標工作空間的操作列中,單擊快速進入,選擇數據開發。
在數據開發頁面,右鍵單擊目標業務名稱,選擇。
在新建表頁面,選擇引擎類型并輸入表名為testkafka。
在DDL對話框中,輸入如下建表語句,單擊生成表結構。
CREATE TABLE testkafka ( key string, value string, partition string, headers string, offset string, timestamp string ) ;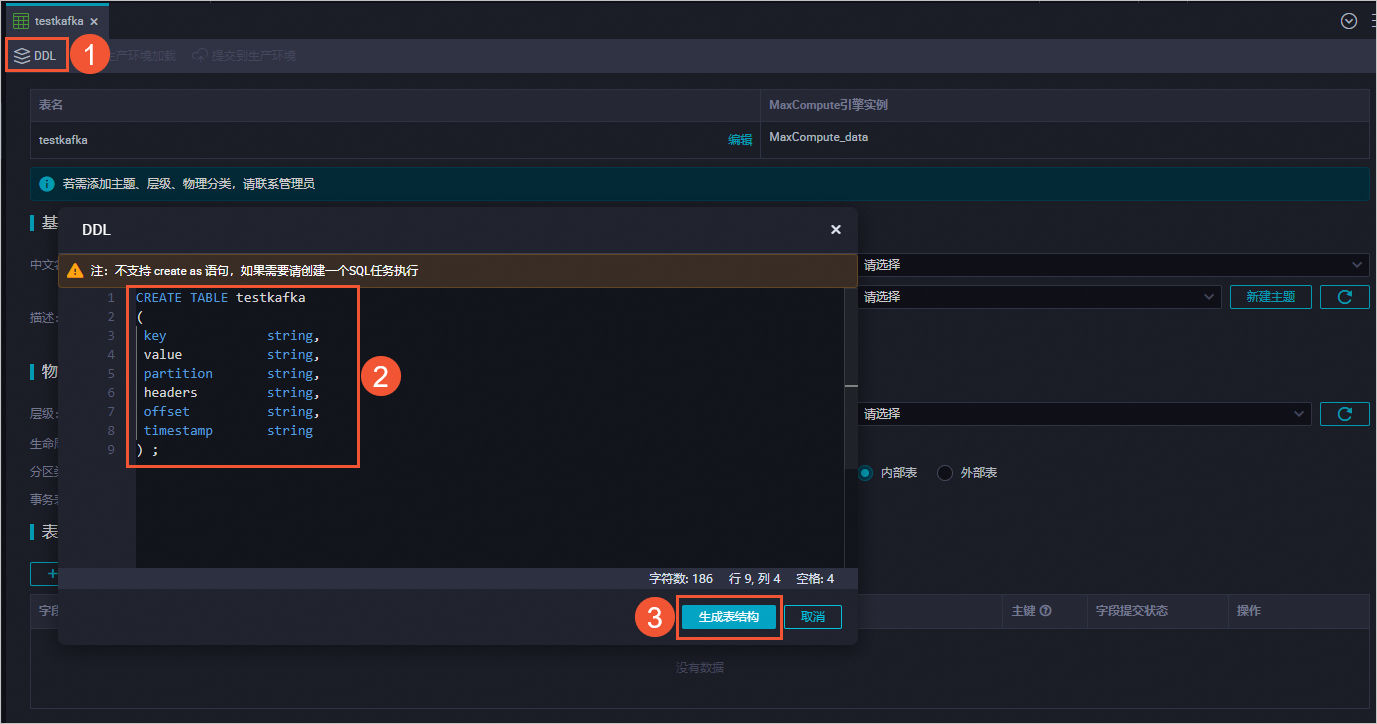
單擊提交到生產環境并確認。
6.創建并啟動離線同步任務
進入數據開發頁面。
登錄DataWorks控制臺。
在左側導航欄,單擊工作空間。
在目標工作空間的操作列中,單擊快速進入,選擇數據開發。
在數據開發頁面,右鍵單擊業務名稱,選擇。
在新建節點對話框,輸入節點名稱(即數據同步任務名稱),然后單擊確認。
在創建的節點頁面,填寫網絡與資源配置信息。
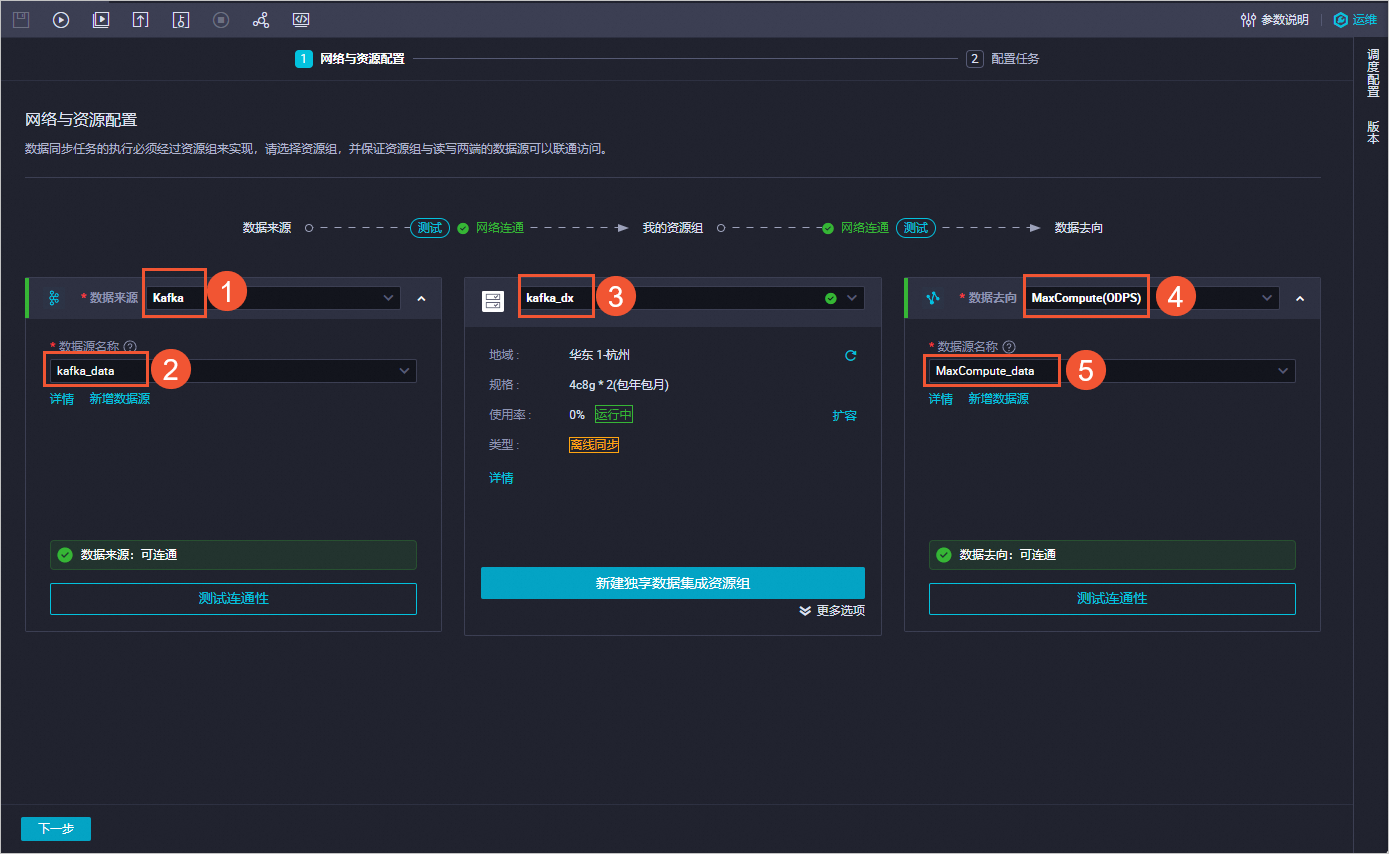
單擊下一步,填寫配置任務信息,單擊
 圖標,運行任務。
圖標,運行任務。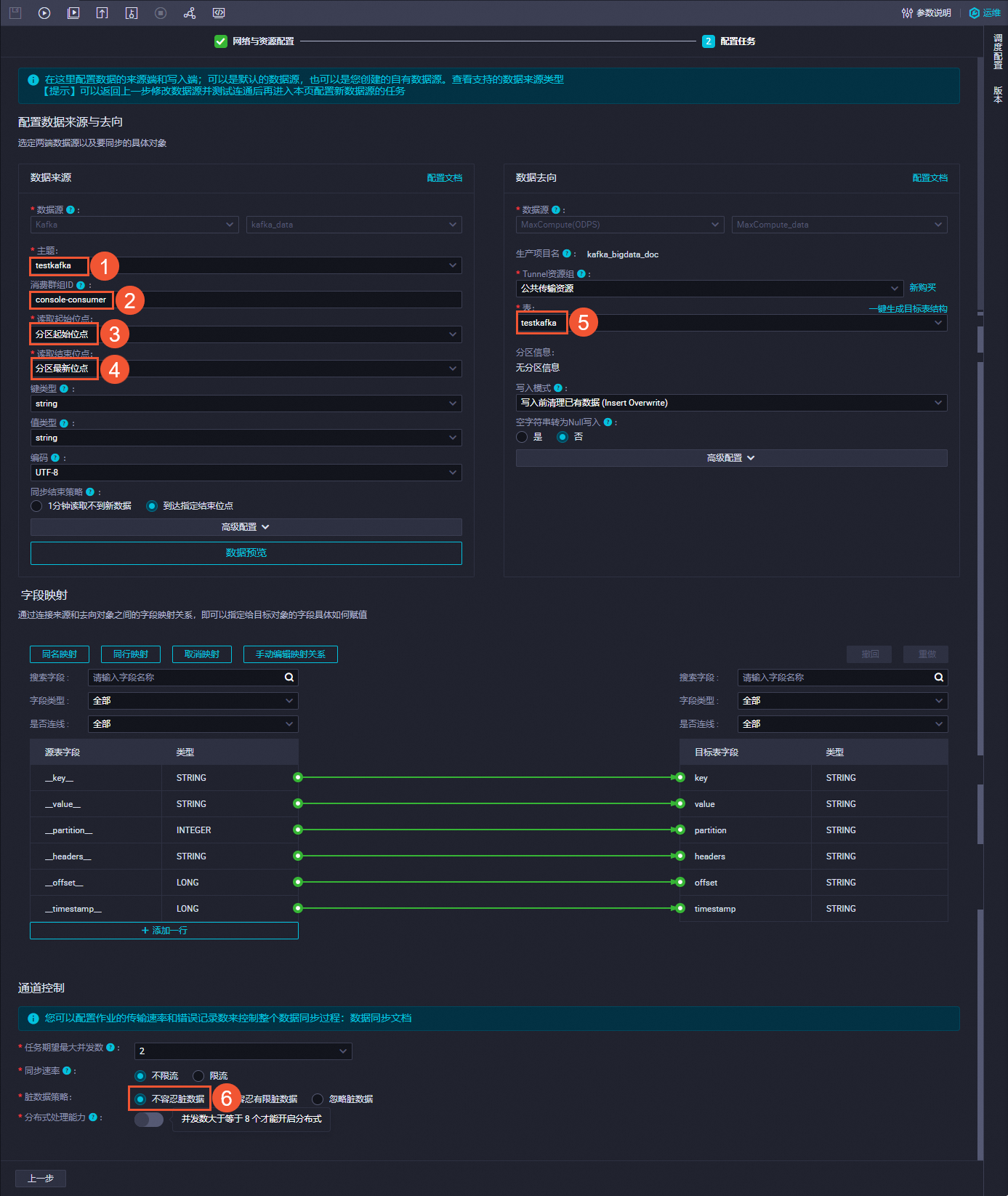
7.結果驗證
7.1驗證離線同步任務運行結果
完成運行后,運行日志中顯示運行成功。

7.2驗證數據同步結果
進入數據開發頁面。
登錄DataWorks控制臺。
在左側導航欄,單擊工作空間。
在目標工作空間的操作列中,單擊快速進入,選擇數據開發。
在臨時查詢面板,右鍵單擊臨時查詢,選擇。
在新建節點對話框中,輸入名稱。
單擊確認。
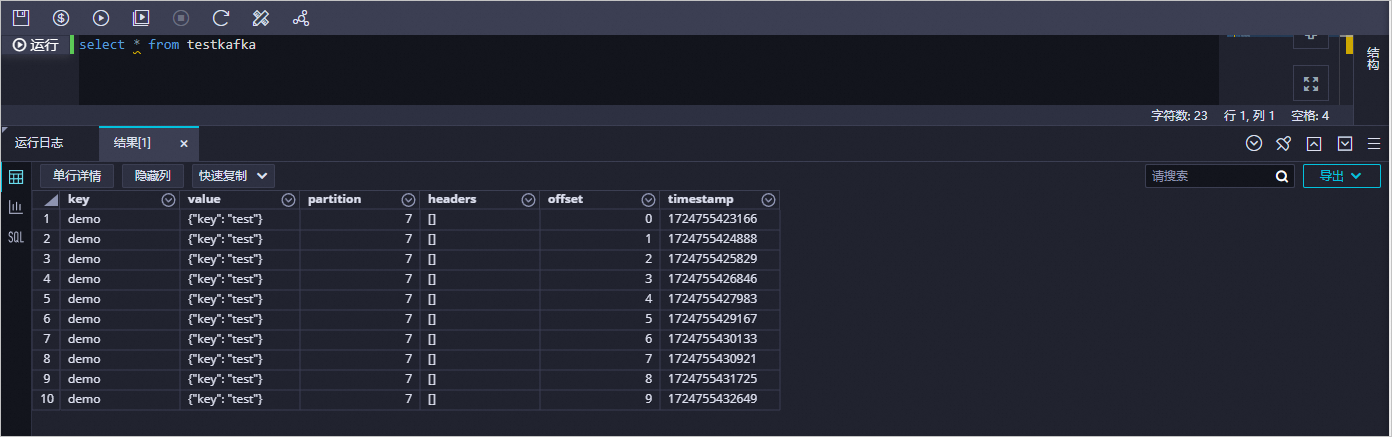
在創建的節點頁面,輸入
select * from testkafka,單擊圖標,運行完成后,查看運行日志。