Kafka數據源為您提供讀取和寫入Kafka的雙向通道,本文為您介紹DataWorks的Kafka數據同步的能力支持情況。
支持的版本
支持阿里云Kafka,以及=0.10.2且<=2.2.x的自建Kafka版本。
對于<0.10.2版本Kafka,由于Kafka不支持檢索分區數據offset,并且Kafka數據結構可能不支持時間戳,進而無法支持數據同步。
資源評估
實時讀取
使用包年包月Serverless資源組時,請提前預估Serverless資源組規格,避免資源組規格不足影響任務運行:
一個topic預估需要1 CU,除此之外,還需根據流量進行評估:
Kafka數據不壓縮,按10 MB/s預估需要1 CU。
Kafka數據壓縮,按10 MB/s預估需要2 CU。
Kafka數據壓縮并且進行JSON解析,按10MB/s預估需要3 CU。
使用包年包月Serverless資源組和舊版獨享數據集成資源組時:
對Failover容忍度高,集群槽位的水位建議不超過80%。
對Failover容忍度低,集群槽位的水位建議不超過70%。
實際占用和數據內容格式等相關,評估后您可以再根據實際運行情況進行調整。
使用限制
Kafka數據源目前支持使用Serverless資源組(推薦)和舊版獨享數據集成資源組。
單表離線讀
同時配置parameter.groupId和parameter.kafkaConfig.group.id時,parameter.groupId優先級高于kafkaConfig配置信息中的group.id。
單表實時寫
寫入數據不支持去重,即如果任務重置位點或者Failover后再啟動,會導致出現重復數據寫入。
整庫實時寫
實時數據同步任務支持使用Serverless資源組(推薦)和舊版獨享數據集成資源組。
對于源端同步表有主鍵的場景,同步時會使用主鍵值作為kafka記錄的key,確保同主鍵的變更有序寫入kafka的同一分區。
對于源端同步表無主鍵的場景,如果選擇了支持無主鍵表同步選項,則同步時kafka記錄的key為空。如果要確保表的變更有序寫入kafka,則選擇寫入的kafka topic必須是單分區。如果選擇了自定義同步主鍵,則同步時使用其他非主鍵的一個或幾個字段的聯合,代替主鍵作為kafka記錄的key。
如果在kafka集群發生響應異常的情況下,仍要確保有主鍵表同主鍵的變更有序寫入kafka的同一分區,則需要在配置kafka數據源時,在擴展參數表單中加入如下配置。
{"max.in.flight.requests.per.connection":1,"buffer.memory": 100554432}重要添加配置后同步性能會大幅下降,需要在性能和嚴格保序可靠性之間做好權衡。
實時同步寫入kafka的消息總體格式、同步任務心跳消息格式及源端更改數據對應的消息格式,詳情請參見:附錄:消息格式。
支持的字段類型
Kafka的數據存儲為非結構化的存儲,通常Kafka記錄的數據模塊有key、value、offset、timestamp、headers、partition。DataWorks在對Kafka數據進行讀寫時,會按照以下的策略進行數據處理。
離線讀數據
DataWorks讀取Kafka數據時,支持對Kafka數據進行JSON格式的解析,各數據模塊的處理方式如下。
Kafka記錄數據模塊 | 處理后的數據類型 |
key | 取決于數據同步任務配置的keyType配置項,keyType參數介紹請參見下文的全量參數說明章節。 |
value | 取決于數據同步任務配置的valueType配置項,valueType參數介紹請參見下文的全量參數說明章節。 |
offset | Long |
timestamp | Long |
headers | String |
partition | Long |
離線寫數據
DataWorks將數據寫入Kafka時,支持寫入JSON格式或text格式的數據,不同的數據同步方案往Kafka數據源中寫入數據時,對數據的處理策略不一致,詳情如下。
寫入text格式的數據時,不會寫入字段名數據,使用分隔符來分隔字段取值。
實時同步寫入數據到Kafka時,寫入的格式為內置的JSON格式,寫入數據為包含數據庫變更消息的數據、業務時間和DDL信息的所有數據,數據格式詳情請參見附錄:消息格式。
同步任務類型 | 寫入Kafka value的格式 | 源端字段類型 | 寫入時的處理方式 |
離線同步 DataStudio的離線同步節點 | json | 字符串 | UTF8編碼字符串 |
布爾 | 轉換為UTF8編碼字符串"true"或者"false" | ||
時間/日期 | yyyy-MM-dd HH:mm:ss格式UTF8編碼字符串 | ||
數值 | UTF8編碼數值字符串 | ||
字節流 | 字節流會被視為UTF8編碼的字符串,被轉換成字符串 | ||
text | 字符串 | UTF8編碼字符串 | |
布爾 | 轉換為UTF8編碼字符串"true"或者"false" | ||
時間/日期 | yyyy-MM-dd HH:mm:ss格式UTF8編碼字符串 | ||
數值 | UTF8編碼數值字符串 | ||
字節流 | 字節流會被視為UTF8編碼的字符串,被轉換成字符串 | ||
實時同步:ETL實時同步至Kafka DataStudio的實時同步節點 | json | 字符串 | UTF8編碼字符串 |
布爾 | json布爾類型 | ||
時間/日期 |
| ||
數值 | json數值類型 | ||
字節流 | 字節流會進行Base64編碼后轉換成UTF8編碼的字符串 | ||
text | 字符串 | UTF8編碼字符串 | |
布爾 | 轉換為UTF8編碼字符串"true"或者"false" | ||
時間/日期 | yyyy-MM-dd HH:mm:ss格式UTF8編碼字符串 | ||
數值 | UTF8編碼數值字符串 | ||
字節流 | 字節流會進行Base64編碼后轉換成UTF8編碼字符串 | ||
實時同步:整庫實時同步至Kafka 純實時同步增量數據 | 內置JSON格式 | 字符串 | UTF8編碼字符串 |
布爾 | json布爾類型 | ||
時間/日期 | 13位毫秒時間戳 | ||
數值 | json數值 | ||
字節流 | 字節流會進行Base64編碼后轉換成UTF8編碼字符串 | ||
同步解決方案:一鍵實時同步至Kafka 離線全量+實時增量 | 內置JSON格式 | 字符串 | UTF8編碼字符串 |
布爾 | json布爾類型 | ||
時間/日期 | 13位毫秒時間戳 | ||
數值 | json數值 | ||
字節流 | 字節流會進行Base64編碼后轉換成UTF8編碼字符串 |
數據同步任務開發
Kafka數據同步任務的配置入口和通用配置流程指導可參見下文的配置指導,詳細的配置參數解釋可在配置界面查看對應參數的文案提示。
創建數據源
在進行數據同步任務開發時,您需要在DataWorks上創建一個對應的數據源,操作流程請參見創建并管理數據源。
單表離線同步任務配置指導
操作流程請參見通過向導模式配置離線同步任務、通過腳本模式配置離線同步任務。
腳本模式配置的全量參數和腳本Demo請參見下文的附錄:腳本Demo與參數說明。
單表、整庫實時同步任務配置指導
操作流程請參見DataStudio側實時同步任務配置。
單表、整庫全增量實時同步任務配置指導
操作流程請參見數據集成側同步任務配置。
啟用認證配置說明
SSL
配置Kafka數據源時,特殊認證方式選擇SSL或者SASL_SSL時,表明Kafka集群開啟了SSL認證,您需要上傳客戶端truststore證書文件并填寫truststore證書密碼。
如果Kafka集群為alikafka實例,可以參考SSL證書算法升級說明下載正確的truststore證書文件,truststore證書密碼為KafkaOnsClient。
如果Kafka集群為EMR實例,可以參考使用SSL加密Kafka鏈接下載正確的truststore證書文件并獲取truststore證書密碼。
如果是自建集群,請自行上傳正確的truststore證書,填寫正確的truststore證書密碼。
keystore證書文件、keystore證書密碼和SSL密鑰密碼只有在Kafka集群開啟雙向SSL認證時才需要進行配置,用于Kafka集群服務端認證客戶端身份,Kafka集群server.properties中ssl.client.auth=required時開啟雙向SSL認證,詳情請參見使用SSL加密Kafka鏈接。
GSSAPI
配置Kafka數據源時,當Sasl機制選擇GSSAPI時,需要上傳三個認證文件,分別是JAAS配置文件、Kerberos配置文件以及Keytab文件,并在獨享資源組進行DNS/HOST設置,下面分別介紹三種文件以及獨享資源組DNS、HOST的配置方式。
JAAS配置文件
JAAS文件必須以KafkaClient開頭,之后使用一個大括號包含所有配置項:
大括號內第一行定義使用的登錄組件類,對于各類Sasl認證機制,登錄組件類是固定的,后續的每個配置項以key=value格式書寫。
除最后一個配置項,其他配置項結尾不能有分號。
最后一個配置項結尾必須有分號,在大括號"}"之后也必須加上一個分號。
不符合以上格式要求將導致JAAS配置文件解析出錯,典型的JAAS配置文件格式如下(根據實際情況替換以下內容中的xxx):
KafkaClient { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="xxx" storeKey=true serviceName="kafka-server" principal="kafka-client@EXAMPLE.COM"; };配置項
說明
登錄模塊
必須配置com.sun.security.auth.module.Krb5LoginModule。
useKeyTab
必須指定為true。
keyTab
可以指定任意路徑,在同步任務運行時會自動下載數據源配置時上傳的keyTab文件到本地,并使用本地文件路徑填充keyTab配置項。
storeKey
決定客戶端是否保存密鑰,配置true或者false均可,不影響數據同步。
serviceName
對應Kafka服務端server.properties配置文件中的sasl.kerberos.service.name配置項,請根據實際情況配置該項。
principal
Kafka客戶端使用的kerberos principal,請根據實際情況配置該項,并確保上傳的keyTab文件包含該principal的密鑰。
Kerberos配置文件
Kerberos配置文件必須包含兩個模塊[libdefaults]和[realms]
[libdefaults]模塊指定kerberos認證參數,模塊中每個配置項以key=value格式書寫。
[realms]模塊指定kdc地址,可以包含多個realm子模塊,每個realm子模塊以realm名稱=開頭。
后面緊跟一組用大括號包含配置項,每個配置項也以key=value格式書寫,典型的Kerberos配置文件格式如下(根據實際情況替換以下內容中的xxx):
[libdefaults] default_realm = xxx [realms] xxx = { kdc = xxx }配置項
說明
[libdefaults].default_realm
訪問Kafka集群節點時默認使用的realm,一般情況下與JAAS配置文件中指定客戶端principal所在realm一致。
[libdefaults]其他參數
[libdefaults]模塊可以指定其他一些kerberos認證參數,例如ticket_lifetime等,請根據實際需要配置。
[realms].realm名稱
需要與JAAS配置文件中指定客戶端principal所在realm,以及[libdefaults].default_realm一致,如果JAAS配置文件中指定客戶端principal所在realm和[libdefaults].default_realm不一致,則需要包含兩組realms子模塊分別對應JAAS配置文件中指定客戶端principal所在realm和[libdefaults].default_realm。
[realms].realm名稱.kdc
以ip:port格式指定kdc地址和端口,例如kdc=10.0.0.1:88,端口如果省略默認使用88端口,例如kdc=10.0.0.1。
Keytab文件
Keytab文件需要包含JAAS配置文件指定principal的密鑰,并且能夠通過kdc的驗證。例如本地當前工作目錄有名為client.keytab的文件,可以通過以下命令驗證Keytab文件是否包含指定principal的密鑰。
klist -ket ./client.keytab Keytab name: FILE:client.keytab KVNO Timestamp Principal ---- ------------------- ------------------------------------------------------ 7 2018-07-30T10:19:16 test@demo.com (des-cbc-md5)獨享資源組DNS、HOST配置
開啟Kerberos認證的Kafka集群,會使用Kafka集群中節點的hostname作為節點在kdc(Kerberos的服務端程序,即密鑰分發中心)中注冊的principal的一部分,而客戶端訪問Kafka集群節點時,會根據本地的DNS、HOST設置,推導Kafka集群節點的principal,進而從kdc獲取節點的訪問憑證。使用獨享資源組訪問開啟Kerberos認證的Kafka集群時,需要正確配置DNS、HOST,以確保順利從kdc獲取Kafka集群節點的訪問憑證:
DNS設置
當獨享資源組綁定的VPC中,使用PrivateZone實例進行了Kafka集群節點的域名解析設置,則可以在DataWorks管控臺,獨享資源組對應的VPC綁定項增加100.100.2.136和100.100.2.138兩個IP的自定義路由,即可使PrivateZone針對Kafka集群節點的域名解析設置對獨享資源組生效。
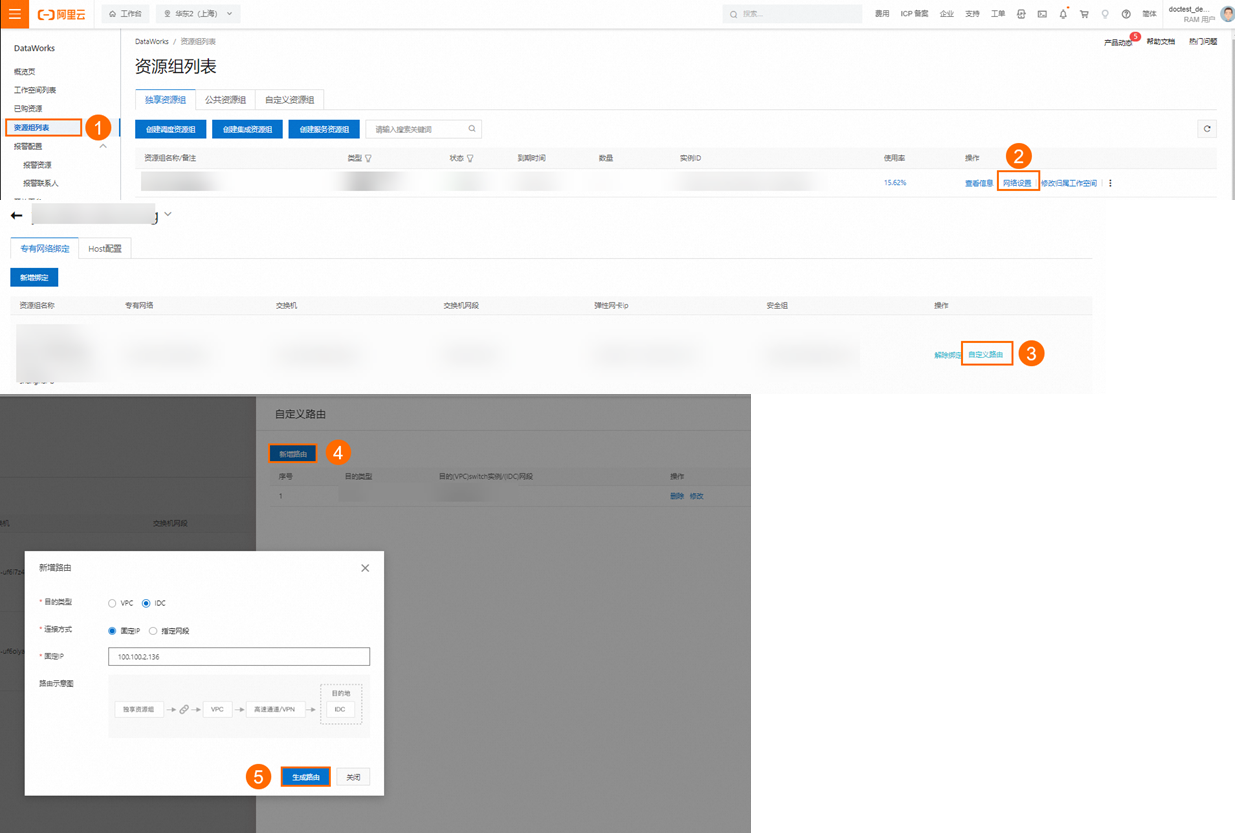
HOST設置
當獨享資源組綁定的VPC中,未使用PrivateZone實例進行了Kafka集群節點的域名解析設置,則需要在DataWorks管控臺,獨享資源組網絡設置中逐個將Kafka集群節點的IP地址與域名映射添加到Host配置中。
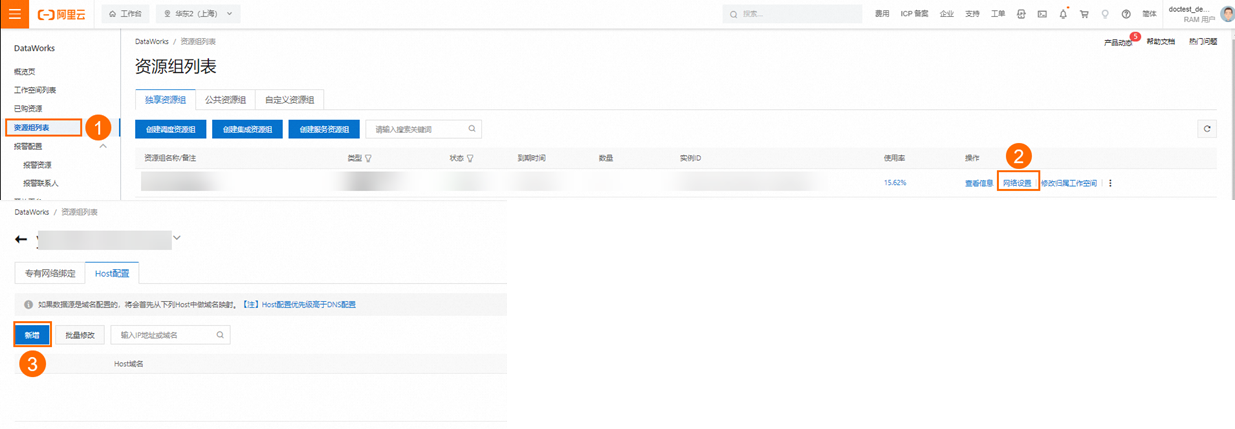
PLAIN
配置Kafka數據源時,當Sasl機制選擇PLAIN時,JAAS文件必須以KafkaClient開頭,之后使用一個大括號包含所有配置項。
大括號內第一行定義使用的登錄組件類,對于各類Sasl認證機制,登錄組件類是固定的,后續的每個配置項以key=value格式書寫。
除最后一個配置項,其他配置項結尾不能有分號。
最后一個配置項結尾必須有分號,在大括號"}"之后也必須加上一個分號。
不符合以上格式要求將導致JAAS配置文件解析出錯,典型的JAAS配置文件格式如下(根據實際情況替換以下內容中的xxx):
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="xxx"
password="xxx";
};配置項 | 說明 |
登錄模塊 | 必須配置org.apache.kafka.common.security.plain.PlainLoginModul |
username | 用戶名,請根據實際情況配置該項。 |
password | 密碼,請根據實際情況配置該項。 |
常見問題
附錄:腳本Demo與參數說明
附錄:離線任務腳本配置方式
如果您配置離線任務時使用腳本模式的方式進行配置,您需要在任務腳本中按照腳本的統一格式要求編寫腳本中的reader參數和writer參數,腳本模式的統一要求請參見通過腳本模式配置離線同步任務,以下為您介紹腳本模式下的數據源的Reader參數和Writer參數的指導詳情。
Reader腳本Demo
從Kafka讀取數據的JSON配置,如下所示。
{
"type": "job",
"steps": [
{
"stepType": "kafka",
"parameter": {
"server": "host:9093",
"column": [
"__key__",
"__value__",
"__partition__",
"__offset__",
"__timestamp__",
"'123'",
"event_id",
"tag.desc"
],
"kafkaConfig": {
"group.id": "demo_test"
},
"topic": "topicName",
"keyType": "ByteArray",
"valueType": "ByteArray",
"beginDateTime": "20190416000000",
"endDateTime": "20190416000006",
"skipExceedRecord": "true"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "stream",
"parameter": {
"print": false,
"fieldDelimiter": ","
},
"name": "Writer",
"category": "writer"
}
],
"version": "2.0",
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
},
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"throttle": true,//當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。
"concurrent": 1,//并發數
"mbps":"12"http://限流,此處1mbps = 1MB/s。
}
}
}Reader腳本參數
參數 | 描述 | 是否必選 |
datasource | 數據源名稱,腳本模式支持添加數據源,此配置項填寫的內容必須要與添加的數據源名稱保持一致。 | 是 |
server | Kafka的broker server地址,格式為ip:port。 您可以只配置一個server,但請務必保證Kafka集群中所有broker的IP地址都可以連通DataWorks。 | 是 |
topic | Kafka的Topic,是Kafka處理資源的消息源(feeds of messages)的聚合。 | 是 |
column | 需要讀取的Kafka數據,支持常量列、數據列和屬性列:
| 是 |
keyType | Kafka的Key的類型,包括BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。 | 是 |
valueType | Kafka的Value的類型,包括BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。 | 是 |
beginDateTime | 數據消費的開始時間位點,為時間范圍(左閉右開)的左邊界。yyyymmddhhmmss格式的時間字符串,可以配合調度參數使用。詳情請參見調度參數支持的格式。 說明 Kafka 0.10.2及以上的版本支持該功能。 | 需要和beginOffset二選一。 說明 beginDateTime和endDateTime配合使用。 |
endDateTime | 數據消費的結束時間位點,為時間范圍(左閉右開)的右邊界。yyyymmddhhmmss格式的時間字符串,可以配合調度參數使用。詳情請參見調度參數支持的格式。 說明 Kafka 0.10.2及以上的版本支持該功能。 | 需要和endOffset二選一。 說明 endDateTime和beginDateTime配合使用。 |
beginOffset | 數據消費的開始時間位點,您可以配置以下形式:
| 需要和beginDateTime二選一。 |
endOffset | 數據消費的結束位點,用于控制結束數據消費任務退出的時間。 | 需要和endDateTime二選一。 |
skipExceedRecord | Kafka使用
| 否,默認值為false。 |
partition | Kafka的一個Topic有多個分區(partition),正常情況下數據同步任務是讀取Topic(多個分區)一個點位區間的數據。您也可以指定partition,僅讀取一個分區點位區間的數據。 | 否,無默認值。 |
kafkaConfig | 創建Kafka數據消費客戶端KafkaConsumer可以指定擴展參數,例如bootstrap.servers、auto.commit.interval.ms、session.timeout.ms等,您可以基于kafkaConfig控制KafkaConsumer消費數據的行為。 | 否 |
encoding | 當keyType或valueType配置為STRING時,將使用該配置項指定的編碼解析字符串。 | 否,默認為UTF-8。 |
waitTIme | 消費者對象從Kafka拉取一次數據的最大等待時間,單位為秒。 | 否,默認為60。 |
stopWhenPollEmpty | 該配置項可選值為true/false。當配置為true時,如果消費者從Kafka拉取數據返回為空(一般是已經讀完主題中的全部數據,也可能是網絡或者Kafka集群可用性問題),則立即停止任務,否則持續重試直到再次讀到數據。 | 否,默認為true。 |
stopWhenReachEndOffset | 該配置項只在stopWhenPollEmpty為true時生效,可選值為true/false。
| 否,默認為false。 說明 兼容歷史邏輯,Kafka版本低于V0.10.2無法執行已經讀取Kafka Topic所有分區中的最新位點數據檢查,但線上可能存在個別腳本模式任務是讀取的版本低于V0.10.2的Kafka數據。 |
kafkaConfig參數說明如下。
參數 | 描述 |
fetch.min.bytes | 指定消費者從broker獲取消息的最小字節數,即有足夠的數據時,才將其返回給消費者。 |
fetch.max.wait.ms | 等待broker返回數據的最大時間,默認500毫秒。fetch.min.bytes和fetch.max.wait.ms先滿足哪個條件,便按照該方式返回數據。 |
max.partition.fetch.bytes | 指定broker從每個partition中返回給消費者的最大字節數,默認為1 MB。 |
session.timeout.ms | 指定消費者不再接收服務之前,可以與服務器斷開連接的時間,默認是30秒。 |
auto.offset.reset | 消費者在讀取沒有偏移量或者偏移量無效的情況下(因為消費者長時間失效,包含偏移量的記錄已經過時并被刪除)的處理方式。默認為none(意味著不會自動重置位點),您可以更改為earliest(消費者從起始位置讀取partition的記錄)。 |
max.poll.records | 單次調用poll方法能夠返回的消息數量。 |
key.deserializer | 消息Key的反序列化方法,例如org.apache.kafka.common.serialization.StringDeserializer。 |
value.deserializer | 數據Value的反序列化方法,例如org.apache.kafka.common.serialization.StringDeserializer。 |
ssl.truststore.location | SSL根證書的路徑。 |
ssl.truststore.password | 根證書Store的密碼。如果是Aliyun Kafka,則配置為KafkaOnsClient。 |
security.protocol | 接入協議,目前支持使用SASL_SSL協議接入。 |
sasl.mechanism | SASL鑒權方式,如果是Aliyun Kafka,使用PLAIN。 |
java.security.auth.login.config | SASL鑒權文件路徑。 |
Writer腳本Demo
向Kafka寫入數據的JSON配置,如下所示。
{
"type":"job",
"version":"2.0",//版本號。
"steps":[
{
"stepType":"stream",
"parameter":{},
"name":"Reader",
"category":"reader"
},
{
"stepType":"Kafka",//插件名。
"parameter":{
"server": "ip:9092", //Kafka的server地址。
"keyIndex": 0, //作為Key的列。需遵循駝峰命名規則,k小寫
"valueIndex": 1, //作為Value的某列。目前只支持取來源端數據的一列或者該參數不填(不填表示取來源所有數據)
//例如想取odps的第2、3、4列數據作為kafkaValue,請新建odps表將原odps表數據做清洗整合寫新odps表后使用新表同步。
"keyType": "Integer", //Kafka的Key的類型。
"valueType": "Short", //Kafka的Value的類型。
"topic": "t08", //Kafka的topic。
"batchSize": 1024 //向kafka一次性寫入的數據量,單位是字節。
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"http://錯誤記錄數。
},
"speed":{
"throttle":true,//當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。
"concurrent":1, //作業并發數。
"mbps":"12"http://限流,此處1mbps = 1MB/s。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}Writer腳本參數
參數 | 描述 | 是否必選 |
datasource | 數據源名稱,腳本模式支持添加數據源,此配置項填寫的內容必須要與添加的數據源名稱保持一致。 | 是 |
server | Kafka的server地址,格式為ip:port。 | 是 |
topic | Kafka的topic,是Kafka處理資源的消息源(feeds of messages)的不同分類。 每條發布至Kafka集群的消息都有一個類別,該類別被稱為topic,一個topic是對一組消息的歸納。 | 是 |
valueIndex | Kafka Writer中作為Value的那一列。如果不填寫,默認將所有列拼起來作為Value,分隔符為fieldDelimiter。 | 否 |
writeMode | 當未配置valueIndex時,該配置項決定將源端讀取記錄的所有列拼接作為寫入kafka記錄Value的格式,可選值為text和JSON,默認值為text。
例如源端記錄有三列,值為a、b和c,writeMode配置為text、fieldDelimiter配置為#時,寫入kafka的記錄Value為字符串a#b#c;writeMode配置為JSON、column配置為[{"name":"col1"},{"name":"col2"},{"name":"col3"}]時,寫入kafka的記錄Value為字符串{"col1":"a","col2":"b","col3":"c"}。 如果配置了valueIndex,該配置項無效。 | 否 |
column | 目標表需要寫入數據的字段,字段間用英文逗號分隔。例如:"column": ["id", "name", "age"]。 當未配置valueIndex,并且writeMode選擇JSON時,該配置項定義源端讀取記錄的列值在JSON結構中的字段名稱。例如,"column": [{"name":id"}, {"name":"name"}, {"name":"age"}]。
如果配置了valueIndex,或者writeMode配置為text,該配置項無效。 | 當未配置valueIndex,并且writeMode配置為JSON時必選 |
partition | 指定寫入Kafka topic指定分區的編號,是一個大于等于0的整數。 | 否 |
keyIndex | Kafka Writer中作為Key的那一列。 keyIndex參數取值范圍是大于等于0的整數,否則任務會出錯。 | 否 |
keyIndexes | 源端讀取記錄中作為寫入kafka記錄Key的列的序號數組。 列序號從0開始,例如[0,1,2],會將配置的所有列序號的值用逗號連接作為寫入kafka記錄的Key。如果不填寫,寫入kafka記錄Key為null,數據輪流寫入topic的各個分區中,與keyIndex參數只能二選一。 | 否 |
fieldDelimiter | 當writeMode配置為text,并且未配置valueIndex時,將源端讀取記錄的所有列按照該配置項指定列分隔符拼接作為寫入kafka記錄的Value,支持配置單個或者多個字符作為分隔符,支持以\u0001格式配置unicode字符,支持\t、\n等轉義字符。默認值為\t。 如果writeMode未配置為text或者配置了valueIndex,該配置項無效。 | 否 |
keyType | Kafka的Key的類型,包括BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。 | 是 |
valueType | Kafka的Value的類型,包括BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。 | 是 |
nullKeyFormat | keyIndex或者keyIndexes指定的源端列值為null時,替換為該配置項指定的字符串,如果不配置不做替換。 | 否 |
nullValueFormat | 當源端列值為null時,組裝寫入kafka記錄Value時替換為該配置項指定的字符串,如果不配置不做替換。 | 否 |
acks | 初始化Kafka Producer時的acks配置,決定寫入成功的確認方式。默認acks參數為all。acks取值如下:
| 否 |
附錄:寫入Kafka消息格式定義
完成配置實時同步任務的操作后,執行同步任務會將源端數據庫讀取的數據,以JSON格式寫入到Kafka topic中。除了會將設置的源端表中已有數據全部寫入Kafka對應Topic中,還會啟動實時同步將增量數據持續寫入Kafka對應Topic中,同時源端表增量DDL變更信息也會以JSON格式寫入Kafka對應Topic中。您可以通過附錄:消息格式獲取寫入Kafka的消息的狀態及變更等信息。
通過離線同步任務寫入Kafka的數據JSON結構中的payload.sequenceId、payload.timestamp.eventTIme和payload.timestamp.checkpointTime字段均設置為-1。