DataWorks支持通過您提供的樣本字段,進行模型訓練,幫助您尋找目標字段的內容特征,生成相應的規則模型。該功能通常用于發現您的數據資產中與該特征內容相似的數據。本文為您介紹如何生成自定義的數據識別模型。
使用限制
DataWorks不支持對數據量小于10條,并且數據長度小于4大于40的樣本字段進行模型訓練。
DataWorks不支持對包含中文字符(包括中文標點符號)的樣本字段進行模型訓練。
創建模型
進入數據保護傘。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
單擊左上方的
 圖標,選擇,單擊立即體驗,進入數據保護傘。說明
圖標,選擇,單擊立即體驗,進入數據保護傘。說明若阿里云主賬號已授權,則直接進入數據保護傘的首頁。
若阿里云主賬號未授權,則進入數據保護傘的授權頁面。授權后才可使用保護傘的相關功能。
在左側導航欄單擊,進入敏感數據識別頁面。
新建模型并進行模型訓練。
在自生成數據識別模型頁簽單擊新建模型。
在新建模型對話框,配置模型名稱并選擇訓練樣本。
樣本字段:您可從指定工作空間下,選擇需要訓練的樣本字段,DataWorks將幫助您找到這些字段的內容特征,生成相應的規則模型。后續您可使用該規則模型發現您數據資產中與該模型的特征內容類似的數據。
說明DataWorks不支持對數據量小于10條,并且數據長度小于4大于40的樣本字段進行模型訓練。
DataWorks不支持對包含中文字符(包括中文標點符號)的樣本字段進行模型訓練。
排除字段:如果某些字段容易與樣本字段混淆,則您可在該規則模型中將其排除,排除后,使用該規則模型識別數據時,排除的字段將不會命中。同時,排除的字段將作為負向樣本加入模型訓練,以達到不命中混淆數據,提高識別準確率的效果。
單擊下一步。
勾選我接受數據保護傘抽樣用于模型訓練,單擊開始訓練,啟動模型訓練。
本次模型訓練將從您選的樣本字段中各隨機抽取不超過100條數據進行訓練,并根據您的樣本字段數量估算耗時。
說明模型訓練時間較長,請您等待。等待過程中,您也可以關閉訓練彈窗,操作其他功能,模型將在后臺自動運行訓練。
查看模型訓練結果。
在自生成數據識別模型頁面,您可查看目標模型的訓練狀態及訓練結果,并根據訓練結果判斷該模型是否符合上線使用標準,用于識別數據。
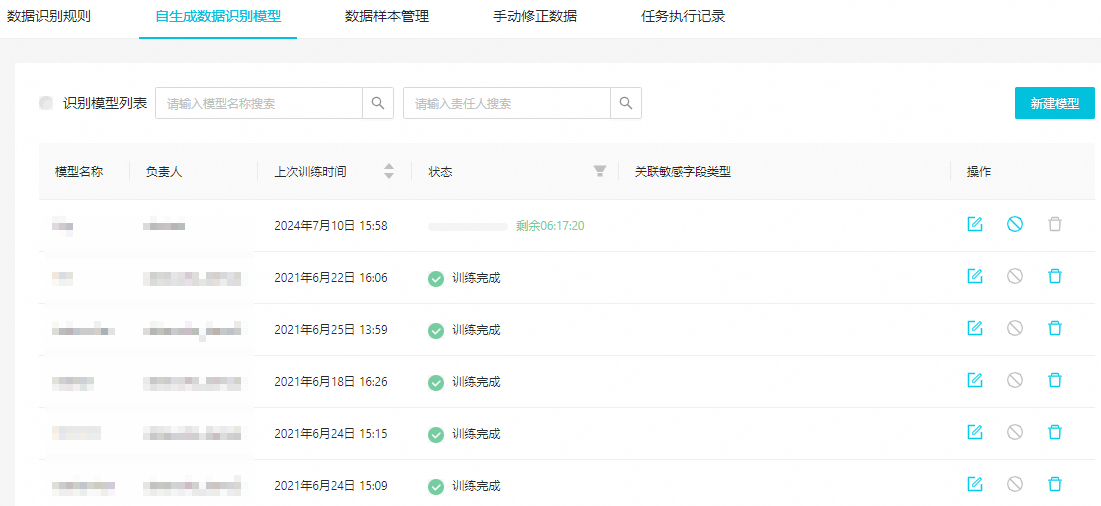
查看訓練狀態。
剩余hh:mm:ss:表示當前模型正在訓練中。
訓練完成:表示當前模型已完成訓練,您可以根據訓練結果,判斷該模型后續是否可用于識別數據。
草稿:表示該模型已創建,但未進行訓練,不能投入識別數據。
查看訓練結果。
單擊訓練完成的模型操作列的
 圖標,即可查看通過該模型提取的樣本特征對樣例數據識別的準確率。建議當準確率為100%時,再投入上線使用該模型。說明
圖標,即可查看通過該模型提取的樣本特征對樣例數據識別的準確率。建議當準確率為100%時,再投入上線使用該模型。說明如果模型訓練的評估結果準確率達不到100%,則投入上線使用識別的數據可能會有較大誤差。建議您增加樣本數據,重新訓練模型,直至準確率達到100%后再投入上線使用。
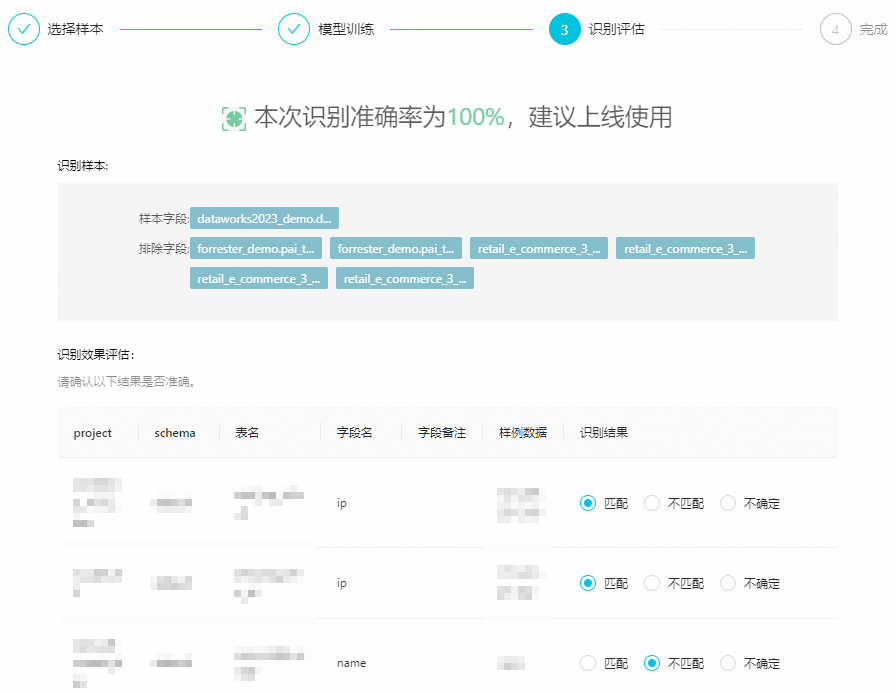
單擊確定創建,完成當前規則模型的創建。
后續步驟
成功創建規則模型后,您可以進入數據識別規則頁面,上線使用當前模型來識別數據。在數據識別規則中使用自定義的模型識別數據,詳情請參見配置數據識別規則并執行識別任務。