本文以MaxCompute離線同步寫入ClickHouse場景為例,為您介紹ClickHouse離線同步在數據源配置、網絡聯通、同步任務配置方面的最佳實踐。
背景信息
云數據庫ClickHouse是面向聯機分析處理的列式數據庫。數據集成支持從ClickHouse同步數據到其他目標端,也支持從其他目標端同步數據到ClickHouse。本文以MaxCompute離線同步寫入ClickHouse為例,為您介紹ClickHouse離線同步的完整流程。
使用限制
ClickHouse離線同步僅支持阿里云ClickHouse。
ClickHouse離線同步僅支持使用獨享數據集成資源組或新版資源組(通用型資源組)。
獲取ClickHouse集群信息
進入ClickHouse產品控制臺。找到您要進行數據同步的ClickHouse集群,在集群信息頁面獲取ClickHouse集群的外網地址、內網地址、HTTP端口號、VPC ID、Vswitch ID、可用區。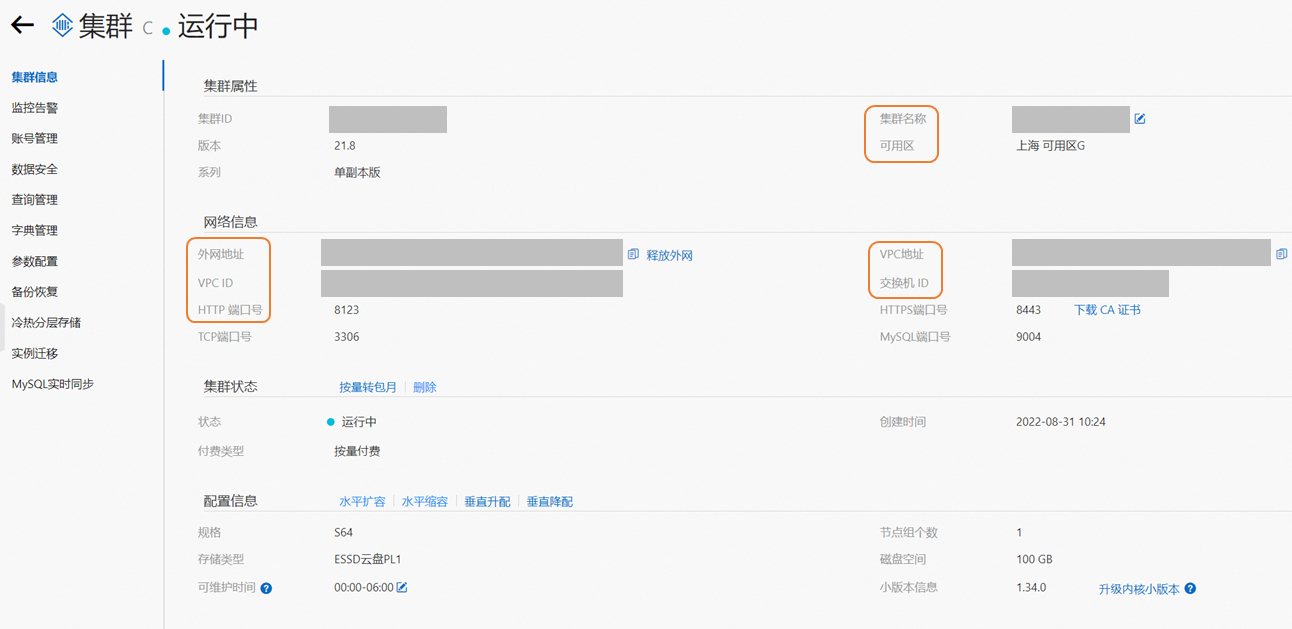
準備資源組并與ClickHouse網絡連通
在進行數據同步前,需要完成您的資源組和ClickHouse集群配置網絡連通。
添加數據源
新建MaxCompute數據源
創建MaxCompute數據源,操作詳情請參見創建MaxCompute數據源。
新建ClickHouse數據源
在DataWorks數據源管理頁面,單擊新建數據源,根據界面提示新建ClickHouse數據源。配置要點如下。
JDBC URL:格式為
jdbc:clickhouse://<ip>:<port>/<dbname>,其中:<ip>:需替換為您ClickHouse集群的內網地址或外網地址。如果您選擇使用VPC內網聯通資源組和ClickHouse,則此處填寫ClickHouse內網地址。
如果您選擇使用公網聯通資源組和ClickHouse,則此處填寫ClickHouse外網地址。
<port>:需替換為您ClickHouse集群的HTTP端口號(通常為8123)。<dbname>:需替換為您要同步的ClickHouse庫名。
用戶名、密碼:為對應ClickHouse庫有訪問權限的用戶名和密碼。
測試連通性:選擇您已經完成與ClickHouse網絡聯通的資源組,確保連通狀態為可連通。
說明如果您使用的是獨享數據集成資源組,完成上述步驟中的網絡連通后,僅可實現ClickHouse與對應獨享數據集成資源組的網絡聯通。如您期望完成ClickHouse與數據服務資源組、調度資源組的網絡聯通,需分別進行網絡連通的配置與連通測試。
新建離線同步任務
在數據開發(DataStudio)頁面的某個業務流程下,新建一個離線同步節點,根據界面提示配置節點的路徑、名稱等信息,操作詳情請參見通過向導模式配置離線同步任務。
配置數據來源:MaxCompute側參數
配置離線同步節點的數據來源相關參數。本實踐將MaxCompute數據增量同步至ClickHouse,數據來源為MaxCompute表,配置要點如下所示。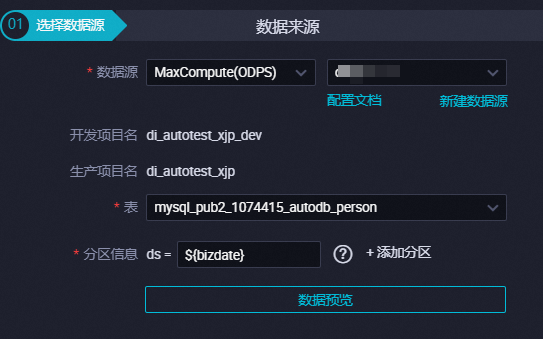
配置項 | 配置要點 |
數據源 | 選擇上述新建的MaxCompute數據源。如果您使用的是標準類型的DataWorks工作空間,會分別顯示開發和生產項目的名稱。 |
表 | 選擇待同步的MaxCompute表。如果您使用的是標準類型的DataWorks工作空間,請確保在MaxCompute的開發環境和生產環境中存在同名且表結構一致的MaxCompute表。 說明 如果:
|
分區信息 | 您可以填入分區列的取值。
|
其他參數保持默認即可。
配置數據去向:ClickHouse側參數
本實踐將數據同步至ClickHouse,數據去向是ClickHouse。配置要點如下。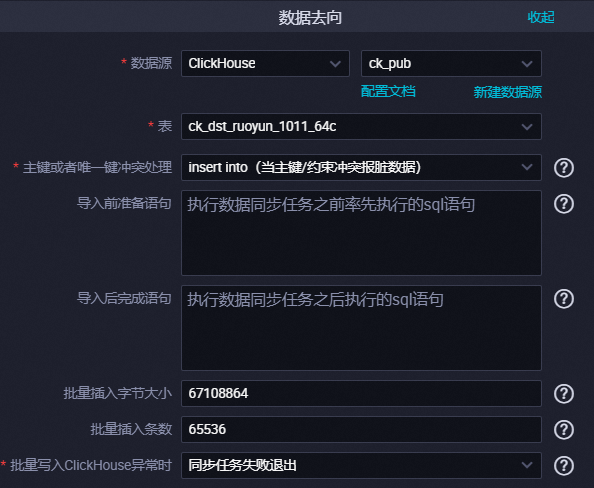
配置項 | 配置要點 |
數據源 | 選擇上述新建的ClickHouse數據源。 |
表 | 選擇待同步的Clickhouse表。建議對于要進行數據同步的表,ClickHouse數據源開發和生產環境保證具有相同的表結構。 說明 此處會展示ClickHouse數據源開發環境地的表列表和表結構,如果您的ClickHouse數據源開發和生產環境的表定義不同,則可能出現任務在開發環境配置正常但提交生產運行后報錯表不存在、列不存在的問題。 |
導入前準備語句、導入后完成語句 | 您可以在執行數據同步任務的前后按需執行SQL語句。比如在按天進行數據同步前清理對應天分區的數據,保證本次數據寫入前對應分區是無數據的。 |
批量插入字節大小、批量插入條數 | 數據同步寫入ClickHouse時采用攢批寫入方式,此處是攢批的字節數上限、條數上限。如果讀取到的數據達到攢批的字節數上限或條數上限,則認為攢夠一批,每攢夠一批則寫入一批數據到ClickHouse。 批量插入字節大小建議值為16777216(16MB),批量插入條數建議按照您單條記錄的大小調整為一個較大值,從而依靠批量插入字節大小觸發批次寫入。 例如單條記錄大小為1KB,批量插入字節大小設置為16777216(16MB),批量插入條數設置為20000(大于16MB/1KB=16384),則會通過批量插入字節大小觸發寫入,每達到16MB寫入一次。 |
批量寫入ClickHouse異常時 | 批量寫入ClickHouse異常時,可以選擇異常處理策略:
|
配置字段映射
選擇數據來源和數據去向后,需要指定讀取端和寫入端列的映射關系。您可以選擇同名映射、同行映射、取消映射或自動排版。
配置通道控制
設置任務同步并發數,可容忍的臟數據條數等。
調整內存參數
如果您在并發調大后同步速率增長不明顯,可以嘗試手工調整同步任務內存參數。調整方式如下。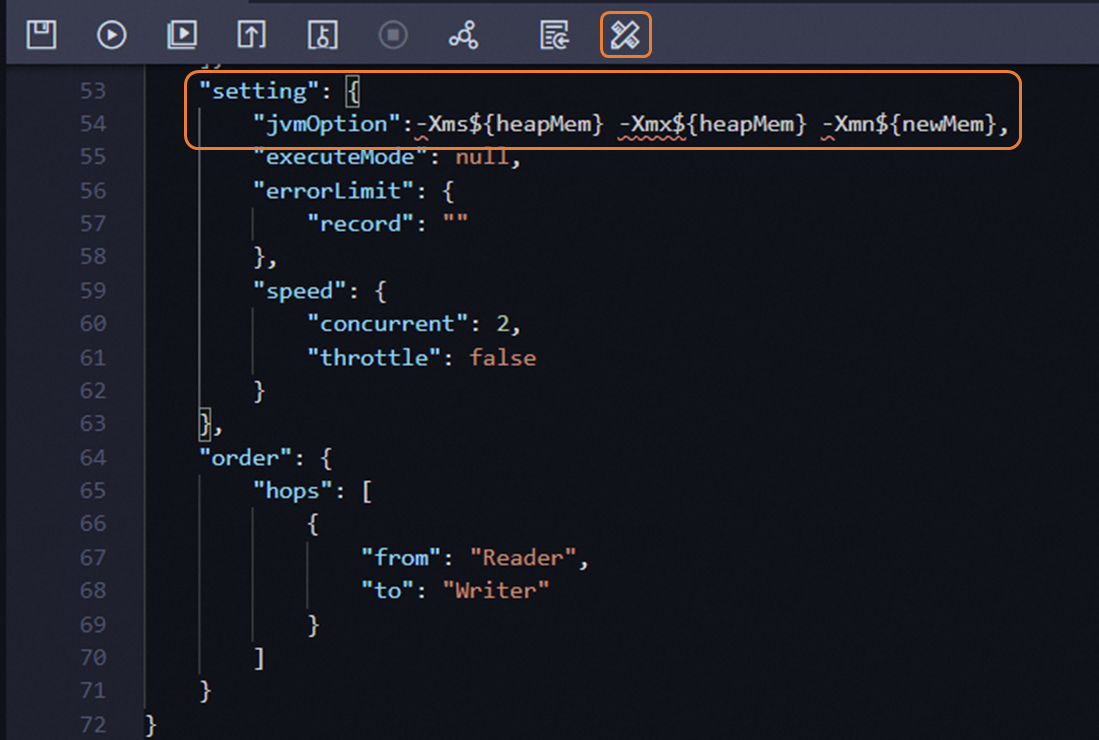
轉換任務為腳本模式。
在腳本JSON段的
setting中增加jvmOption參數,參數形如-Xms${heapMem} -Xmx${heapMem} -Xmn${newMem}。
向導模式下系統計算的${heapMem}的取值為768MB+(并發數-1)*256 MB。建議您在腳本模式中將${heapMem}設置為更大值,并將${newMem}設置為${heapMem}的三分之一。如并發數為8時,向導模式默認計算的${heapMem}為2560MB,腳本模式中可設置更大值,如設置jvmOption為-Xms3072m -Xmx3072m -Xmn1024m。
調度配置
單擊右側的調度配置,本實踐示例涉及的調度配置要點如下。通用的調度配置指導及全量調度相關參數的介紹請參見調度配置。
重跑屬性。
可根據業務需求設置不同的重跑策略,設置失敗可重跑策略可以有效降低因為網絡抖動等偶發問題導致的任務失敗。
配置調度依賴。
可根據業務需求設置不同的調度依賴。您可以通過設置依賴上一周期的本節點,保證本節點多個調度周期的任務實例是依次執行完成的,避免多任務實例同時調度運行。
數據集成資源組配置
選擇在創建數據源時,與ClickHouse數據源、MaxCompute數據源都完成連通性檢查的數據集成資源組。
試運行與提交執行任務
試運行
單擊頂部的![]() 運行或
運行或![]() 帶參運行,可以試運行并查看同步結果是否符合預期。
帶參運行,可以試運行并查看同步結果是否符合預期。
帶參運行可以針對任務配置中使用的調度系統參數進行替換。
如果是標準項目,此時會在開發環境運行同步任務,源端使用MaxCompute的開發項目開發表,目標端使用ClickHouse的開發環境JDBC URL和庫表。
提交和發布任務
試運行沒有問題后,您可以保存離線節點的配置,并提交發布至運維中心,后續離線同步任務將會周期性(分鐘或小時或天)將Kafka的數據寫入MaxCompute的表中。提交發布的操作請參見發布任務。
發布成功后,您可以在運維中心查看周期調度運行結果、進行補數據等操作。