功能簡介
長文檔信息抽取是基于深度學習的信息抽取自學習模型任務,支持用戶自定義抽取字段,通過平臺可視化引導,完成數據標注和模型訓練,實現對非結構化、多版式的文檔的高精度抽取。
在圖像質量較好情況下,通過100+訓練樣本標注,調優后模型識別準確率可超85%+。
功能優勢
高精度,基于阿里云強大的預訓練模型,經過調優訓練的多版式模型識別準確率可達85%以上。
少樣本,僅需標注少量數據即可完成模型優化迭代,且模型具有泛化性。
低門檻,無需代碼開發,開箱即用,可自主配置規則,交互友好可控。
高效率,提供智能預標注能力,多人協同標注耗時短。
應用場景
高性能模型:適用于文檔樣式/格式較為簡單的文檔。例如僅包含標題、段落的文檔;支持的文檔格式包括PDF/圖片。適用于證明、文書、文件、信件、公告等行業場景。
混合版面模型:適用于文檔樣式/格式較為豐富的文檔。例如包括標題,段落,表格、表單等內容的文檔;支持的文檔格式包括PDF/圖片。適用于合同、標書、保單、工程表單等行業場景。
模型有持續優化的需求,且有較多的數據樣本(大于20條)可用于模型訓練進行效果優化的長文檔數據。
相關鏈接
OCR文檔自學習:控制臺入口
長文檔信息抽取模型任務開發指南:在線調試,API 接口文檔(異步調用API接口文檔),SDK文檔
操作指南
「長文檔信息抽取接入視頻」參考:
創建「長文檔信息抽取」流程如下圖,需要超過20張圖片進行訓練才可完成模型創建。
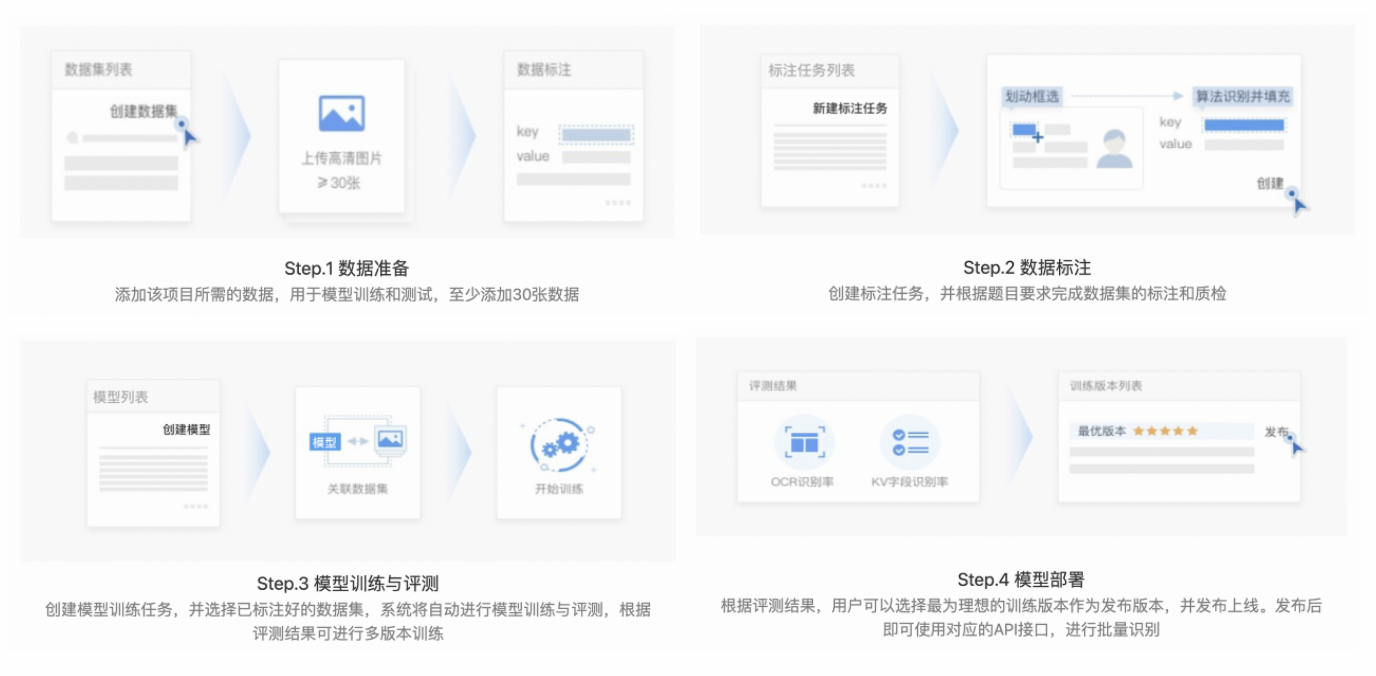
步驟一:數據準備
在「數據中心-數據集」中,用戶可進行上傳和管理模型任務所需數據。點擊添加數據集進入上傳界面,編輯數據集名稱并上傳相關業務數據。
長文檔信息抽取自定義模型至少需要50張訓練數據,才能獲得相對較好的識別抽取效果。
數據準備有什么具體要求?
數據集可上傳圖片、文檔、壓縮包;
文檔,支持不超過20M且后綴為pdf的文件,建議單pdf文件不超過5頁;
圖片,支持不超過10M且后綴為jpg、jpeg、png的文件;
壓縮包,僅支持zip格式,且單zip包不超過20M。
單張圖片最長邊不超過8192像素,最短邊不小于15像素。當長邊超過1024像素時,長寬比不超過50 :1。
至少準備50-60份以上同類任務的數據用于模型訓練與評測。
如何獲得更好識別效果?
在產品功能范圍的任務,數據質量越高,識別與抽取效果越好,字跡清晰端正的數據能有更高的準確率。
單字大小保持在10-50像素內,以獲得較好的識別效果。
數據來源于真實業務場景,且類型與版式完整覆蓋。
步驟二: 數據標注
數據標注劃分為標注創建環節、標注環節、質檢環節三大步驟;
標注任務創建
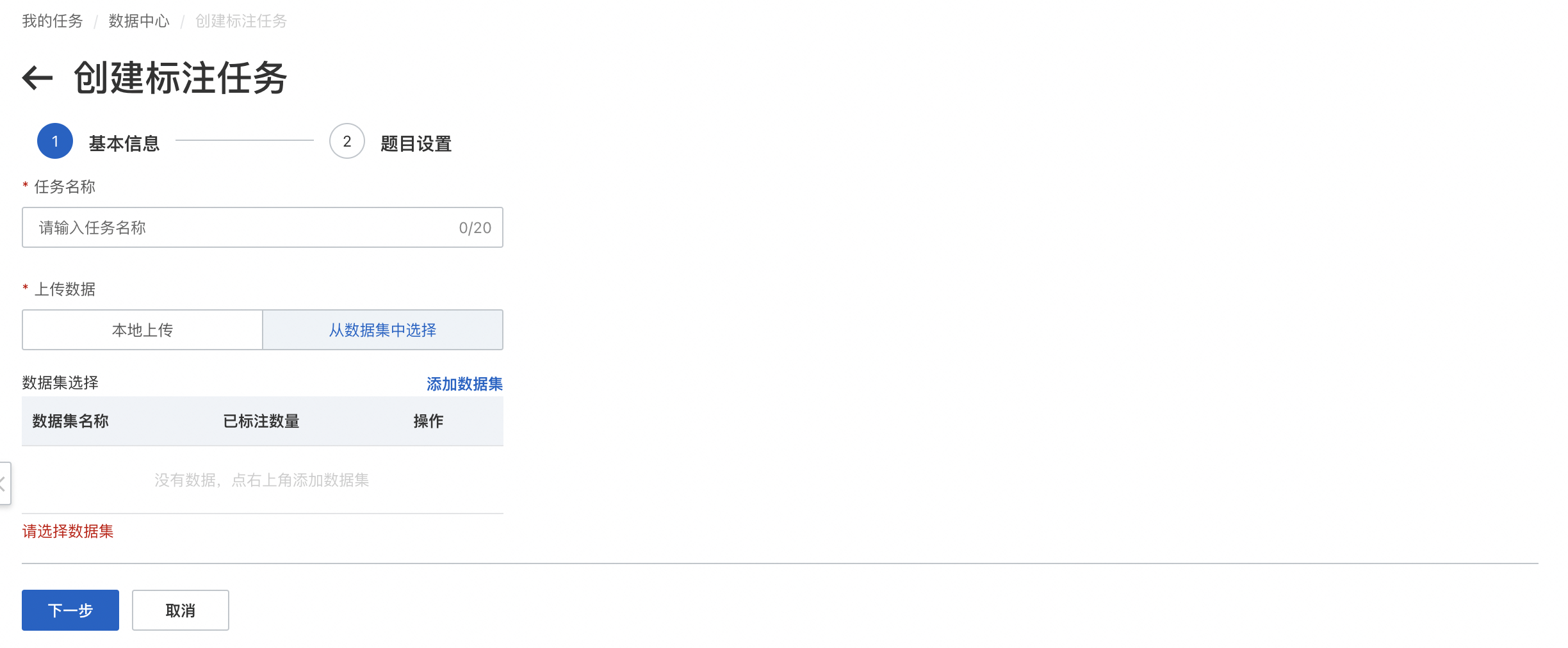
在「數據中心-標注任務」界面中,點擊創建標注任務進入創建界面,編輯任務名稱以及在上傳數據中選擇需要標注的數據集或直接本地上傳,完成后進入題目設置。
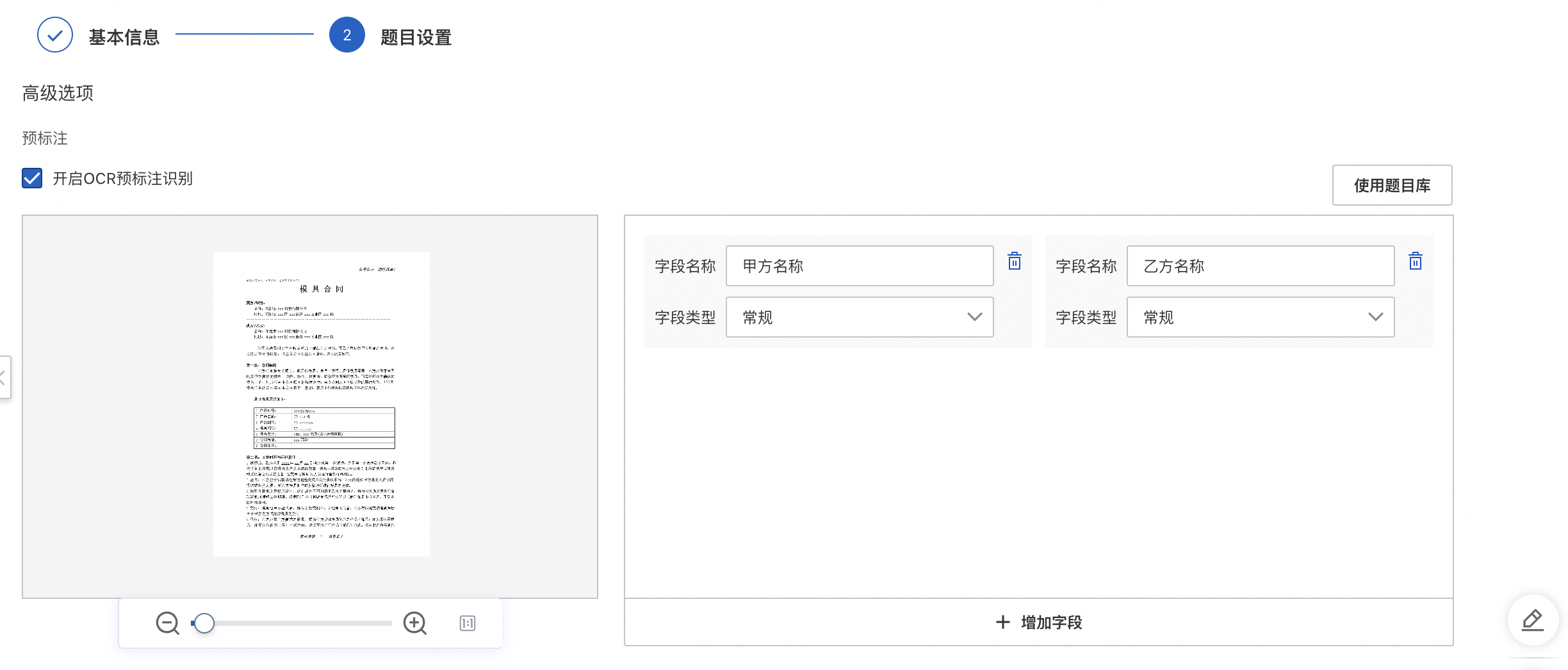
預標注:開啟OCR預標注識別后,在標注時畫框之后會自動識別出框內文字內容,提高標注效率。
題目庫:本任務中,已存在的題目,用戶可通過查看題目庫選擇合適的題目用于標注任務的制定。
字段名稱:識別字段對外透出的名稱,即API接口中對應的名稱,且字段名需全局唯一。
字段類型:字段屬性定義,選擇合適的字段類型可提升字段識別端到端效果,支持選擇通用字段或用戶自行添加自定義字段。無需后處理選擇常規字段類型即可。
標注任務如何上傳數據:
支持本地上傳和從數據集中選擇;若您預先將數據上傳至數據集,則可選擇從數據集中選擇,點擊列表上方「添加數據集」,選擇需要標注的數據集即可。
如何填寫KV信息抽取:
需要將需要標注的字段名稱全部填入內容框中。選擇相應的字段類型,可提高字段識別精準度。
可選擇已創建完成的「題目庫」引用其字段。對于同一模型建議選擇同一「題目庫」,可確保其字段設置完全相同。
標注
在「數據中心-標注任務」中,選擇已創建的標注任務,點擊去標注進入數據標注界面。在標注工具中,可通過框選按鈕進行待識別字段的框選標注,選擇對應的題目,并仔細檢查核對自動識別的文字內容。待所有圖片及其所有待識別字段都依次完成標注后,點擊提交任務完成該部分標注。
標注數據的質量(文字及位置)將直接影響模型訓練的效果與評測指標。
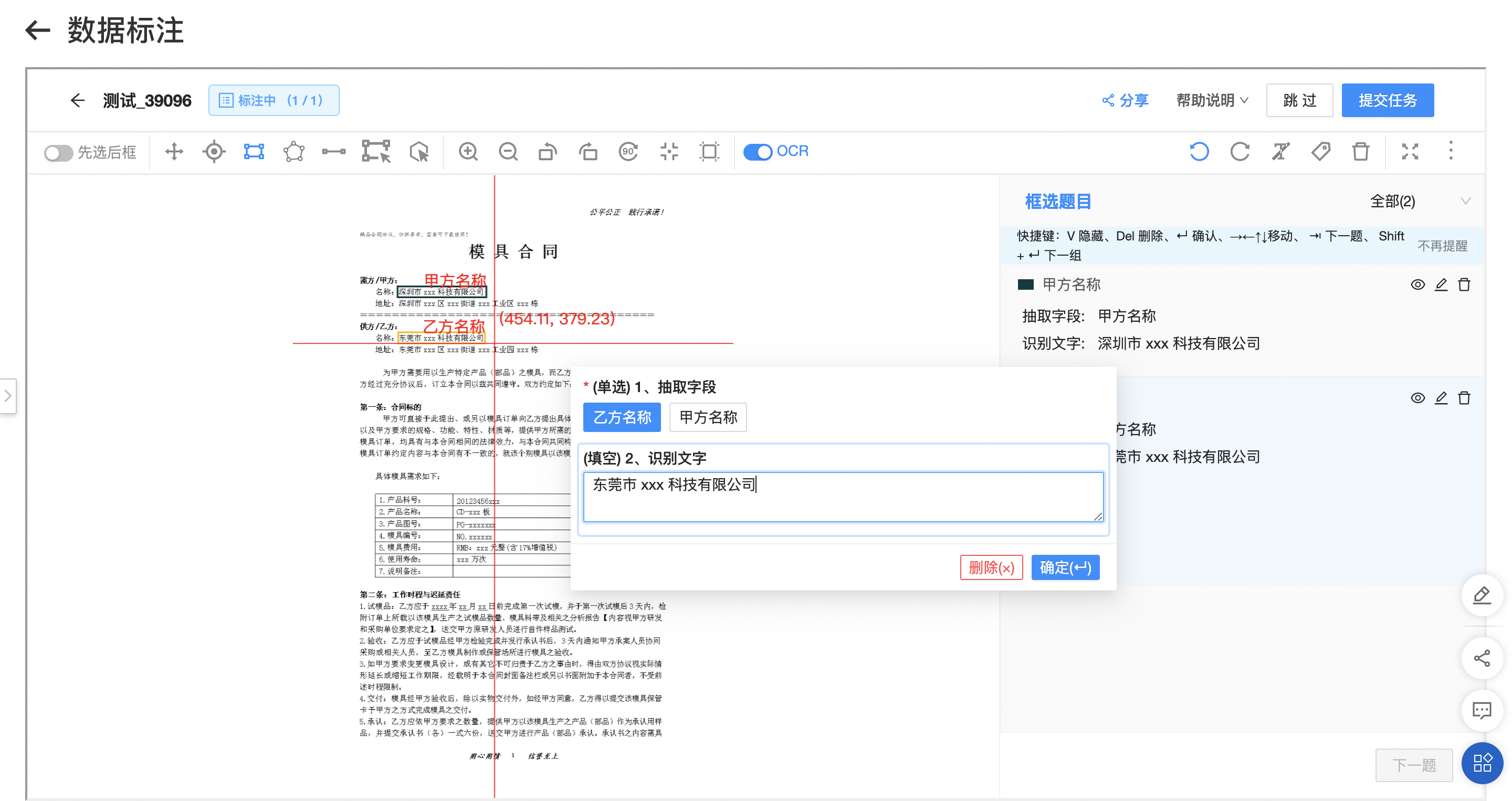
如遇見錯誤數據或不可標注數據,可選擇跳過該張圖片。
現長文檔信息抽取僅支持「四角框」對識別字段進行框選,框選時選框四角盡可能貼合文字。
盡可能保證數據清晰端正無遮擋物,以及數據版式類型覆蓋齊全。
「OCR預標注」支持印刷體文字識別,暫不支持手寫體識別。預標注自動識別的文字內容需仔細核對檢查,保證標注正確性。
如何實現跨行標注?
分別標注跨行對應的部分,并給予它們正確的題目。
按住「shift鍵」,點擊此前的兩個標注框的邊。
松開『shift鍵』,然后自動會把跨行數據合并,選擇對應的題目。
點擊確定,右邊就看到一個“組合”,單獨的小框無需刪除。
質檢
進入「數據中心-標注任務」界面,選擇已標注完成的任務進行質檢。質檢員可進行標注修改與駁回,完整當前所有標注任務后進行任務提交。注意核對所有字段是否均已完成標注。
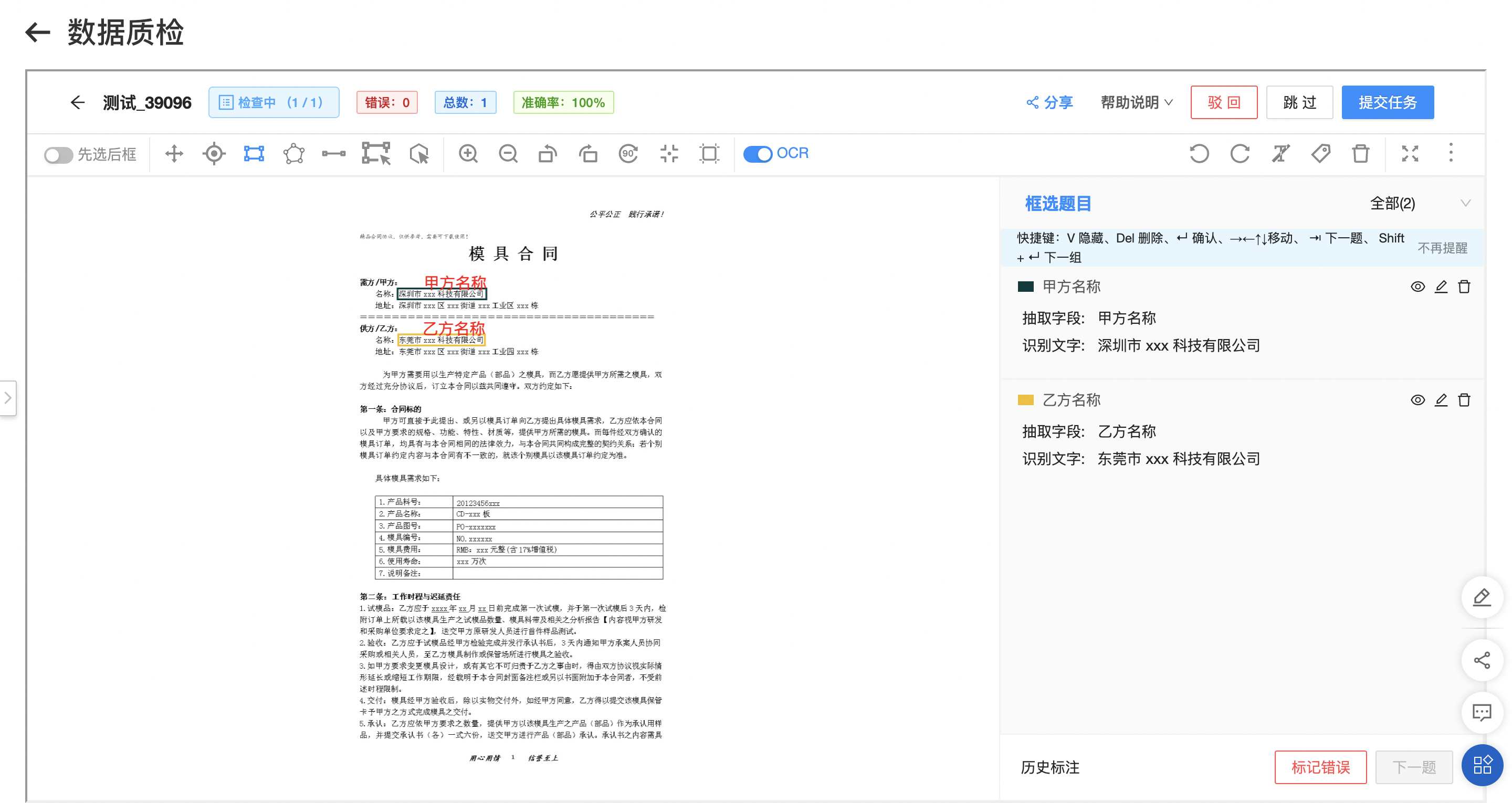
如何進行質檢?
質檢員可直接使用標注工具對標注信息進行增刪改操作。
質檢員選擇「提交」則所有圖片都完成質檢工作。
質檢過程中發現標注質量不高該怎么辦?
選擇對應的題目進行直接修改編輯。
選擇「駁回」則退回標注員重新標注處理。
步驟三: 模型訓練與測評
進入「模型中心」,點擊創建模型進入模型創建界面,進行訓練集標注結果和測試集標注結果選擇,同時完成和基本信息填寫。創建模型成功后自動進入模型訓練。
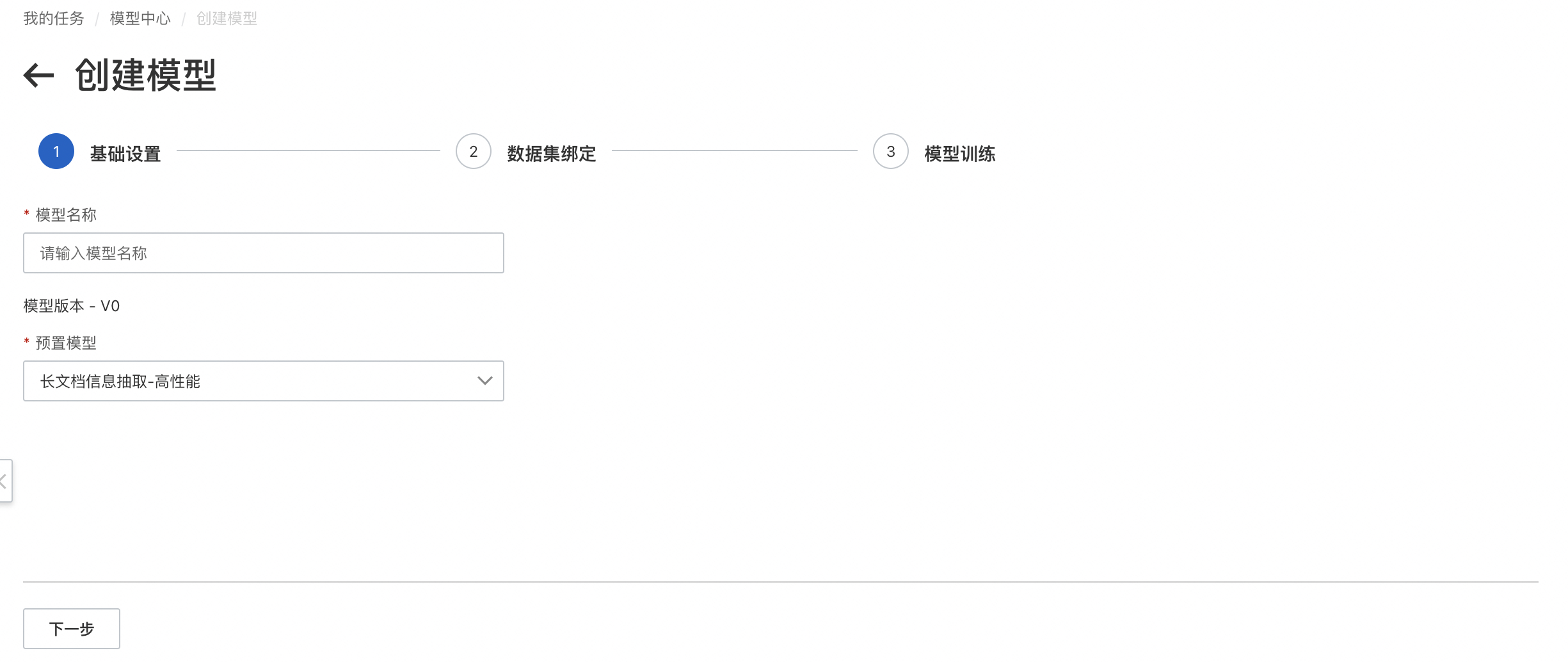
「預置模型」:長文檔現支持「高性能」和「混合版面」兩個版本。
「高性能模型」:適用于文檔樣式/格式較為簡單的文檔,例如僅包含標題、段落的文檔,支持的文檔格式包括PDF/圖片。
「混合版面模型」:適用于文檔樣式/格式較為豐富的文檔,例如包括標題,段落,表格、表單等內容的文檔,支持的文檔格式包括PDF/圖片。
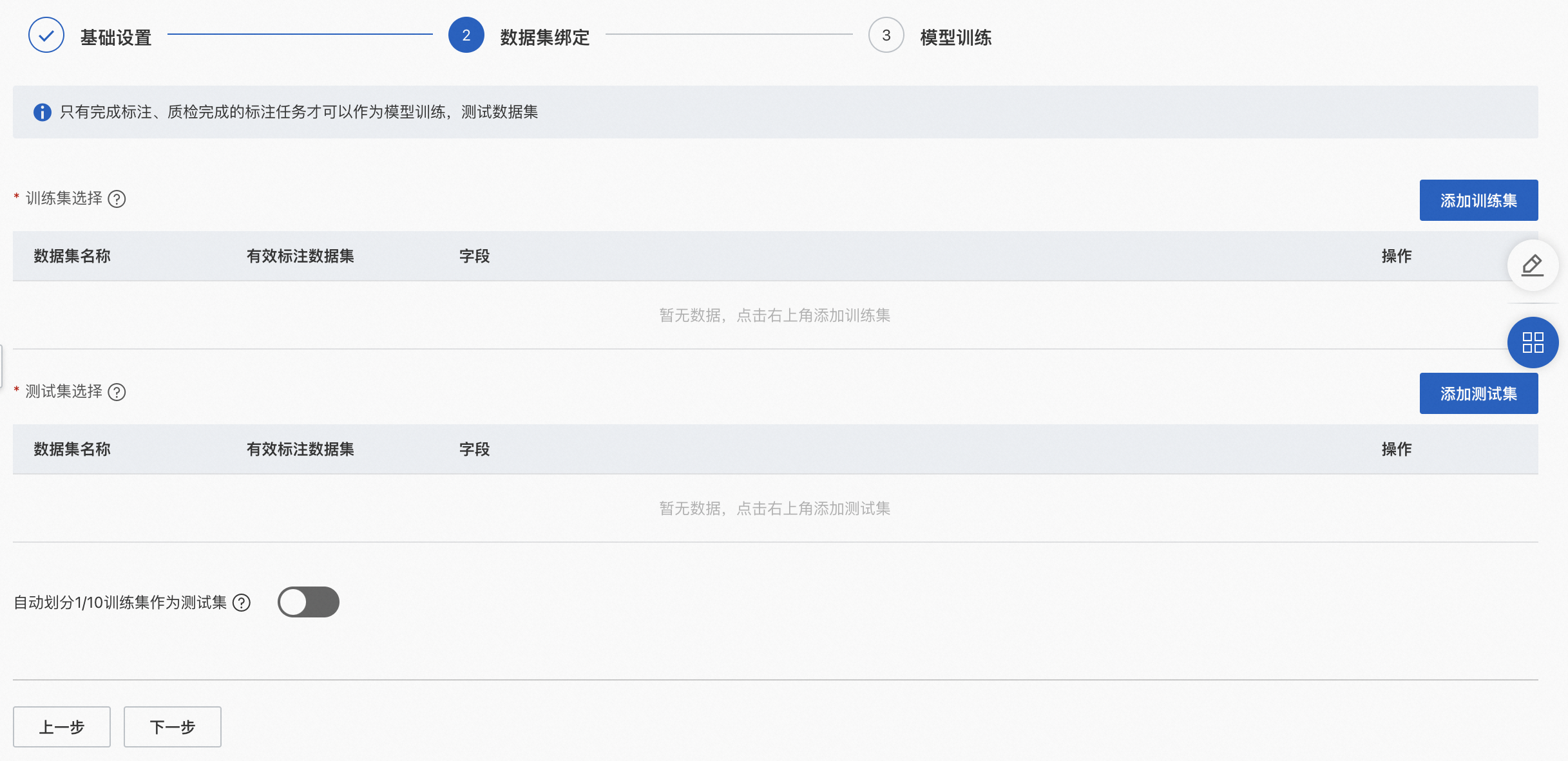
「訓練集」:用于訓練模型的數據源,只能選擇標注且質檢完成的數據集作為訓練集,且已被選為測試集的數據集不可再次選擇。建議選擇20張以上有效數據進行模型訓練。
「測試集」:用于測試模型的數據源,只能選擇標注且質檢完成的數據集作為測試集,且已被選為訓練集的數據集不可再次選擇。
「自動劃分1/10訓練集作為測試集」:若打開此按鈕,則無需手動再次選擇測試集,系統直接自動劃分1/10訓練集作為測試集。如打開自動劃分功能前已存在完成上傳測試集,打開開關后,系統將忽略此前手動上傳的測試集數據。
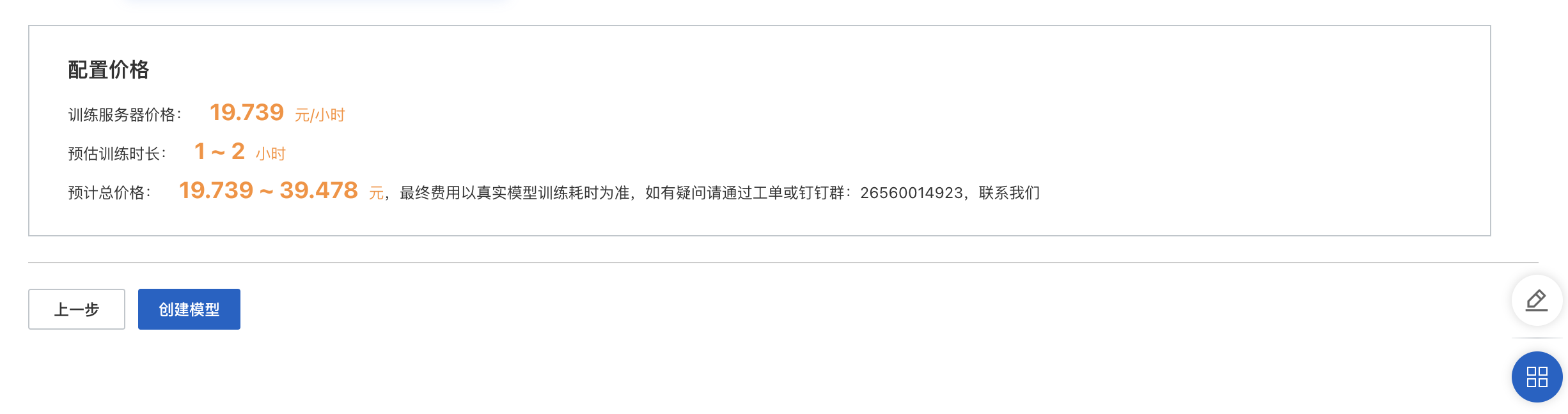
模型訓練費用及預估時長。根據任務類型及數量變動,以界面顯示數字為準。
「訓練時長」:由數據量、標注情況、機器資源等多種因素共同決定。如采用V100機器,6萬字數約需1分鐘訓練時長。
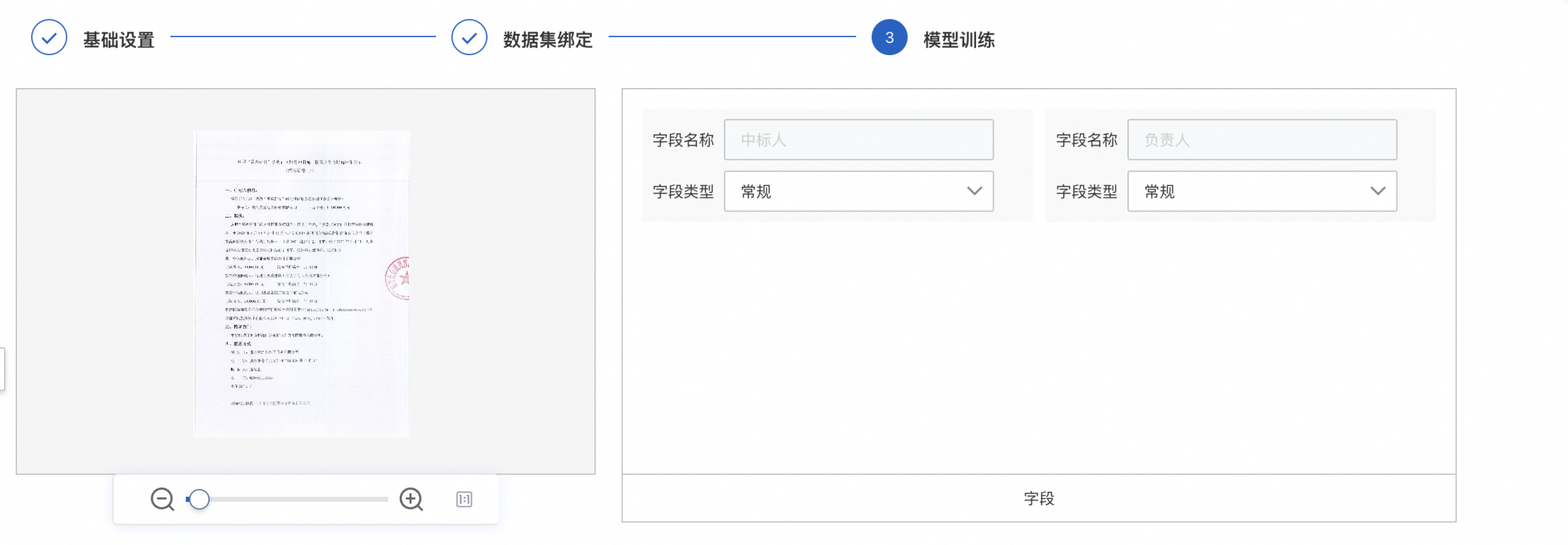
您需要校驗「測試集」和「訓練集」字段,各數據集字段內容需要保持一致。
「模型訓練」配置環節支持選擇字段對應的字段類型,或根據業務需求刪除字段,以提高訓練精準度。
建議數據量越大,標注越精確,模型訓練和評測的效果越好。
配置合適的字段類型,提升端到端準確率。
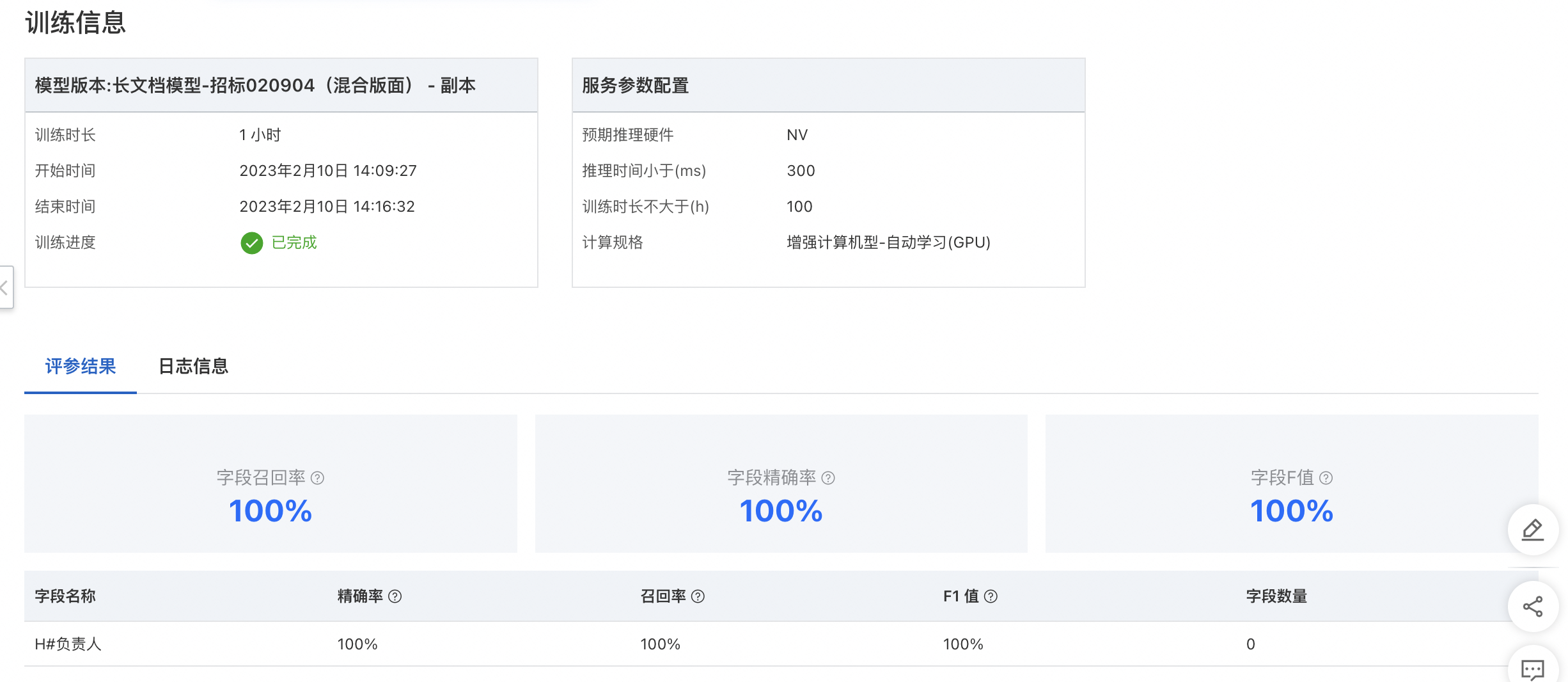
算法評估評價指標評:包括整體指標、字段指標兩個維度。
整體指標 - 均值
精確率:算法模型精確率(Precision),未經規則后處理修正,為被識別為正類別的樣本中,真實為正類別的比例,有正確預測的字段個數 / 所有預測的字段個數,即測試集中被識別出來的字段占該類字段標注框一致(內容+位置)比例。
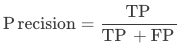
召回率:算法模型召回率(Recall),未經規則后處理修正,為所有真實為正類別的樣本中,被正確識別為正類別的比例,有正確預測的字段個數 / 所有真實正確的字段個數。
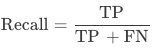
F值:綜合評價指標(F1-Measure),為精確率和召回率的加權調和平均,常用于評價分類模型的好壞。
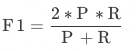
字段指標
精確率:算法模型精確率(Precision),未經規則后處理修正,測試集中該字段正確字段個數 / 該字段預測的總數。
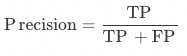
召回率:算法模型召回率(Recall),未經規則后處理修正,測試集中該字段正確字段個數 / 該字段真實正確的總數。
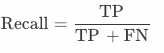
F1值:綜合評價指標(F1-Measure),未經規則后處理修正,測試集中為精確率和召回率的加權調和平均。
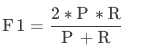
如何進行模型調優?
明確任務類型符合功能范圍,以及數據質量盡可能清晰端正。
數據標注需要將識別字段逐一標注完整,標注框盡量貼合字段文字。也可以調整字段類型或高級選項提高準確率。
數據量越大,模型訓練效果越好。一般模型數據量達200+份,會有一個較好的表現。
數據類型和版式分布符合真實業務場景,只有訓練過的數據類型和版式才能有較好的識別效果。
步驟四: 模型部署
模型訓練完成后,進入「模型中心-模型詳情」,點擊頁面底部「去部署」按鈕,即可開始模型部署。模型部署需要一定時間,部署成功后即可通過在線體驗可視化測試模型效果或直接使用API進行在線服務調用。
OCR文檔自學習自2023年8月23日開啟全面商業化,模型訓練按時長計費,模型推理調用按調用量計費,詳情可見OCR文檔自學習計費。
小工具-題目庫
題目庫:應用于「題目設置」環節,預先創建標注任務字段,此題目支持多次引用;即多標注任務若所需標注字段相同,可通過題目庫選擇,減少多次編輯題目人力成本并降低題目編輯錯誤可能性。
若重新修改題目庫,不會對已經發起的標注任務或模型產生影響。