您可以通過新建開發環境場景,并在開發環境場景畫布中編排節點工作流、配置運行參數,來驗證數據處理流程的正確性。本文以MaxCompute節點搭建流程為例介紹如何新建開發環境場景并運行。
前提條件
已創建相關的云計算資源,具體操作,請參見新建云計算資源。
背景信息
節點流程定義了一段處理邏輯,通過有向無環圖DAG(Directed Acyclic Graph)描述。節點流程中所有節點的輸入、輸出數據都是具體的數據表、文件、數據流。
步驟一:新建開發環境場景
登錄數據資源平臺控制臺。
在頁面左上角,單擊
 圖標,選擇協同。
圖標,選擇協同。在頂部菜單欄,單擊
 圖標,選擇目標工作組,單擊資產加工 。說明
圖標,選擇目標工作組,單擊資產加工 。說明若您已在資產加工頁面,請跳過“單擊資產加工”的操作。
在左側導航欄,單擊
 圖標,選擇場景模式。
圖標,選擇場景模式。單擊
 圖標,在開發環境頁簽,單擊新建場景。
圖標,在開發環境頁簽,單擊新建場景。在新建場景對話框,填寫場景名稱和場景標識,單擊確認。
步驟二:添加計算類節點并配置
計算類節點包括:計算節點和公共節點。請根據需要添加一個或者多個計算節點或者公共節點或者二者的混用。
計算節點:主要適用于某個特定場景,或針對某張表的邏輯處理,這些節點不需要復用,在場景中直接創建。
公共節點:主要是用于計算邏輯的復用,在不同的場景中,通過引用公共節點并調整參數的方式,完成符合場景業務要求的計算邏輯,提升開發效率。在公共節點頁面創建,場景中引用。例如:1分鐘流量估計、2分鐘流量估計、5分鐘流量估計,其計算邏輯一樣,只是運行時的參數不一樣。
1.在場景畫布中添加計算節點。
計算節點包含多種類型,這里以添加MaxCompute SQL類型的計算節點為例介紹添加計算節點的示例操作。
如果不需要添加計算節點,則直接執行6.添加公共節點并配置。
在開發環境場景畫布頁面,將左側需要類型的計算節點拖入到開發環境場景畫布,更多信息,請參見計算節點配置說明。
2.在計算節點編輯頁面,配置節點的基本信息。
雙擊拖入的計算節點。
在節點編輯頁面右側的節點屬性頁簽,自定義輸入節點名稱和節點描述等。
配置項
說明
節點名稱
節點的名稱,支持用戶自定義。
節點描述
節點的描述性信息,方便用戶理解和查找。
在節點編輯頁面,輸入算法語句,單擊
 圖標。
圖標。(條件必選)當需要在算法語句中使用自定義函數時,單擊引用函數頁簽,在自定義函數列表找到需要的自定義函數,再返回編輯頁面輸入。若函數列表為空,則需要先新建函數,更多操作請參見新建自定義函數。
在確認節點信息對話框中,確認節點標識、節點名稱以及節點目錄信息設置無誤后,單擊確認。
3.在計算節點編輯頁面,配置節點的運行配置信息。
單擊頁面右側運行配置頁簽,選擇需要的開發和生產計算引擎。
(條件必選)在運行配置頁簽,手動添加節點的輸入、節點輸出和節點變量,或通過單擊編輯頁面的
 圖標,自動解析節點的輸入、節點輸出和節點變量,參數設置的更多信息,請參見計算節點配置說明。這里以解析為例介紹。
圖標,自動解析節點的輸入、節點輸出和節點變量,參數設置的更多信息,請參見計算節點配置說明。這里以解析為例介紹。單擊編輯頁面的
圖標。在節點編輯頁面的運行配置頁簽,打開節點輸入后面的
 開關,查看節點輸入。
開關,查看節點輸入。在節點編輯頁面的運行配置頁簽,打開節點輸出后面的
開關,查看節點輸出。填寫節點變量值。
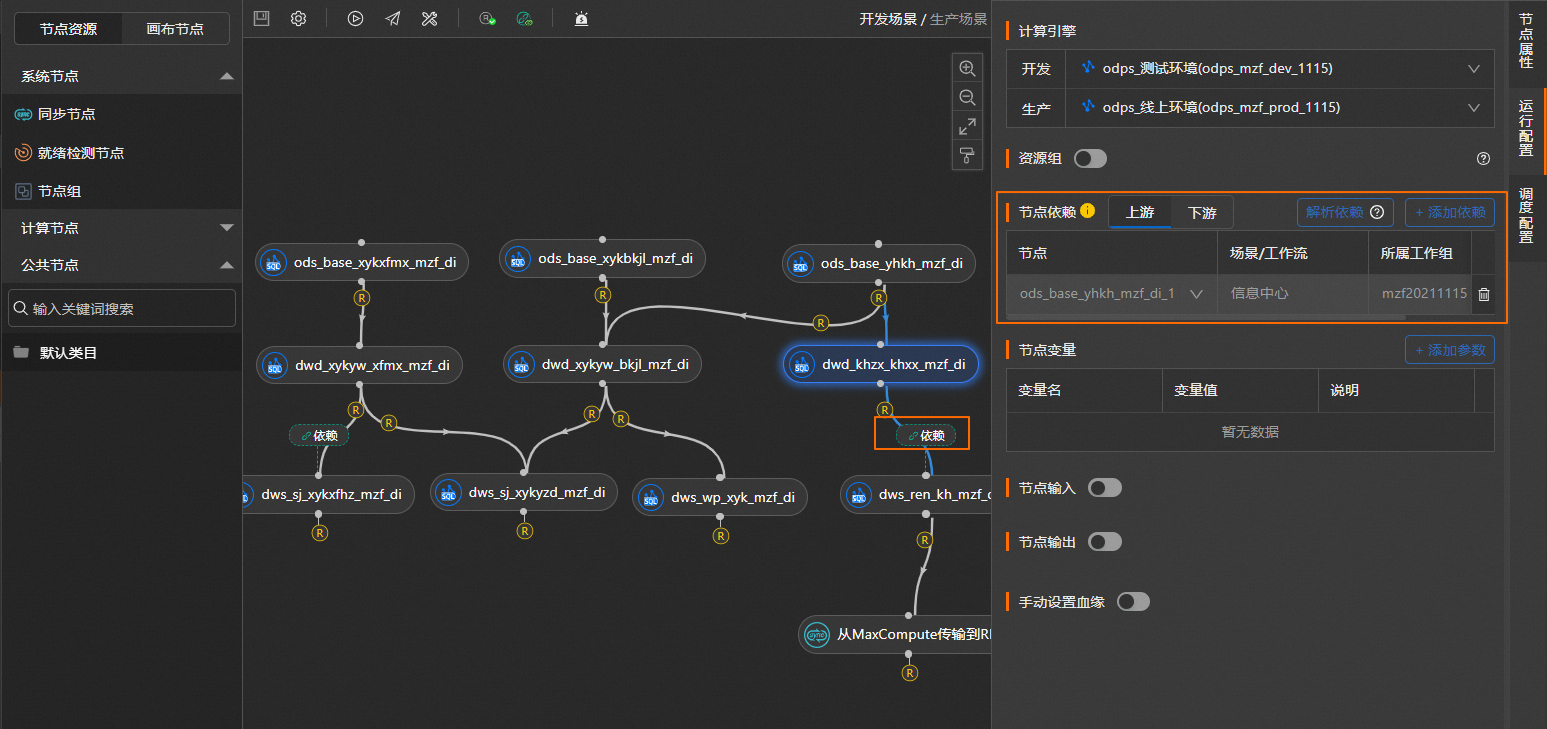
如果業務有依賴關系時,配置依賴信息。
單擊解析依賴,當存在依賴節點時,系統會自動解析依賴節點信息并呈現在依賴節點區域,并生成依賴圖標呈現在場景畫布中。
在節點編輯頁面,單擊左上角
 圖標。
圖標。
在節點編輯頁面,單擊左上角
圖標。(可選)配置字段血緣關系。
說明針對不能自動解析輸入和輸出的節點類型,當需要了解資產中字段血緣關系時或者自動解析的節點類型中解析存在差異,需要修改字段映射關系時,在配置好輸入和輸出參數后,單擊手動配置血緣,手動配置輸入和輸出表的字段映射關系。
其中不能自動解析輸入和輸出參數的節點包括:MaxCompute MR、Hadoop、Elastic Job、Spark Batch、Spark Stream,Elastic Service、Flink Vvp Stream、Flink Vvr Stream。
單擊手動配置血緣。
在血緣配置對話框中,單擊輸出表待配置的目標字段后的
 圖標,下拉選擇對應的輸入表以及輸入表的字段,單擊保存。
圖標,下拉選擇對應的輸入表以及輸入表的字段,單擊保存。
說明配置完字段血緣關系并上線后,可至資產中心查看該節點輸出表和輸入的字段映射關系,具體操作,請參見查看表資產詳情的血緣關聯內容。
4.運行計算節點
單擊
 圖標,出現節點變量頁面,確認參數類型和默認值無誤后,單擊確定。說明
圖標,出現節點變量頁面,確認參數類型和默認值無誤后,單擊確定。說明如果計算節點類型為在線節點或者流式節點,則不需要運行,跳過本步驟和查看運行結果和日志的步驟。
查看運行結果和日志,當結果顯示如下所示“Current task status:SUCCESS”,則表示節點運行成功。
關閉當前計算節點編輯頁面。
5.在場景編輯頁面,配置計算節點信息。
在場景畫布中,單擊拖入的計算節點。
(可選)在開發環境場景編輯頁面的右側的節點屬性頁簽,可修改節點名稱、描述和版本說明。
說明如果需要復用當前計算節點的計算邏輯時,可以將該計算節點發布為公共節點,在開發環境場景編輯頁面的右側的節點屬性頁簽,單擊發布為公共節點。
單擊頁面右側運行配置頁簽,選擇計算節點的開發和生產計算引擎。
如果業務有依賴關系時,需要設置上游依賴節點信息。
支持通過自動解析依賴節點和在場景畫布中拖入依賴節點兩種方式設置依賴信息,其中拖入依賴節點的操作,更多信息,請參見步驟三:(可選)添加系統節點并配置。以下以自動解析依賴節點為例介紹。
在運行配置頁簽的節點依賴區域,單擊解析依賴,參數說明的更多信息,請參見計算節點配置說明。
若存在依賴節點,則解析完成后,在依賴節點區域的上游頁簽中,會自動顯示該節點的依賴節點相關信息,并在場景畫布中自動生成對應依賴節點圖標。
6.添加公共節點并配置。
將左側公共節點區域下已新建的公共節點拖入到畫布。公共節點的創建方法,具體操作,請參見添加MaxCompute SQL類型的公共節點~添加Spark Stream類型的公共節點。
說明如果公共節點較多,您可在左側導航欄的搜索框,輸入關鍵詞,進行搜索。
如果不需要添加公共節點,則直接執行步驟四:連接各節點。
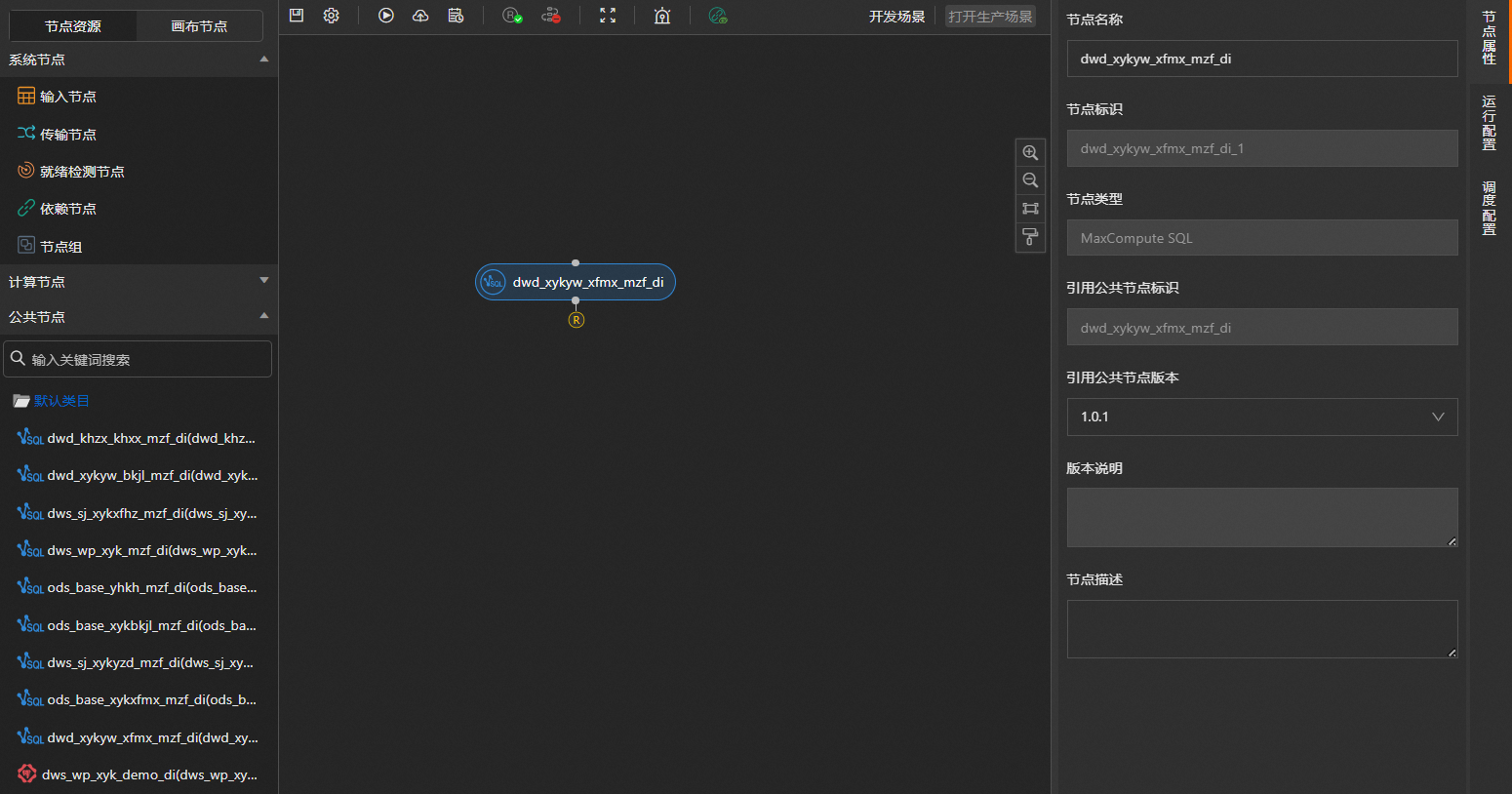
單擊拖入的公共節點,在右側的節點屬性頁簽,查看節點名稱等信息。
單擊頁面右側運行配置頁簽,選擇公共節點的開發和生產計算引擎,關于參數配置的更多信息,請參見下表。
參數
說明
計算引擎
開發
開發環境場景使用資源,用于在開發環境中運行。
生產
生產場景使用資源,用于在生產環境中運行。
資源組
資源組是發布任務的資源池。設置后,可查看當前公共節點所屬的開發資源組和生產資源組,請至系統設置 > 資源組管理中設置。
節點輸入
輸入標識
節點的輸入參數標識。
數據結構
輸入表的數據格式,由數據模型定義,在下拉列表中選擇,表示該計算資源中提供數據的數據表的結構。
當選擇數據表時,需保證輸入的模型與上游節點的輸出數據模型相同,物理表名可以自定義。
當選擇星號(*)時,代表數據結構為任意結構,用于對未創建數據模型的表進行操作,此時物理表必須選擇已經存在的表。
開發環境
云計算資源
開發環境中節點輸入使用的物理表所在資源。
表名
開發環境中節點輸入參數的物理表名,可自定義新建物理表名或者選擇已物理化至資源庫中的物理表名。
當輸入數據結構為星號(*)時,輸入物理表名必須選擇已經存在的物理表。
當輸入數據結構為具體的模型結構時,填寫物理表名,系統會自動執行物理化。
當打開依賴上游開關時,且本節點輸入參數連接到上游節點輸出參數時,則本節點輸入參數對應的物理表依賴上游輸出,為上游節點輸出物理表,不能手動再修改。
生產環境
云計算資源
生產環境中節點輸入使用的物理表所在資源。
表名
生產環境中節點輸入的物理表名,可自定義新建物理表名或者選擇已物理化至資源庫中的物理表名。
當輸入數據結構為星號(*)時,輸入物理表名必須選擇已經存在的物理表。
當輸入數據結構為具體的模型結構時,填寫物理表名,系統會自動執行物理化。
當打開依賴上游開關時,且本節點輸入參數連接到上游節點輸出參數時,則本節點輸入參數對應的物理表依賴上游輸出,為上游節點輸出物理表,不能手動再修改
節點輸出
輸出標識
節點的輸出參數標識。
數據結構
輸出表的數據格式,由數據模型定義,在下拉列表中選擇,表示該計算資源中輸出數據的數據表的結構。
當選擇數據表時,需保證節點輸出的模型與下游節點的輸入數據模型相同,物理表名可以自定義。
當選擇星號(*)時,代表數據結構為任意結構,以輸出表為準,此時物理表必須選擇已經存在的表。
開發環境
云計算資源
開發環境中節點輸出使用的物理表所在資源。
表名
開發環境節點輸出的物理表名,可自定義新建物理表或者選擇已物理化至資源庫中的物理表名。
當輸出數據結構為星號(*)時,物理表必須選擇資源庫中已經存在的物理表。
當輸出數據結構為具體的模型結構時,填寫物理表名,系統會自動執行物理化。
當輸出數據結構為具體的模型結構且數據資源類型為MaxCompute、Hive、AnalyticDB PostgreSQL、PostgreSQL時,系統會自動生成節點的輸出物理表,當需要修改時,可打開自定義開關以后修改。
生產環境
云計算資源
生產環境中節點輸入使用的物理表所在資源。
表名
生產環境節點輸出的物理表名,可自定義新建物理表或者選擇已物理化至資源庫中的物理表名。
當輸出數據結構為星號(*)時,物理表必須選擇資源庫中已經存在的物理表。
當輸出數據結構為具體的模型結構時,填寫物理表名,系統會自動執行物理化。
當輸出數據結構為具體的模型結構且數據資源類型為MaxCompute、Hive、AnalyticDB PostgreSQL、PostgreSQL時,系統會自動生成節點的輸出物理表,當需要修改時,可打開自定義開關以后修改。
節點變量
變量名
算法參數的名稱,用戶自定義。
變量值
設置參數的值,為字符串(String)類型。
說明
參數的說明信息。
如果業務有依賴關系時,需要設置上游依賴節點信息。
支持通過自動解析依賴節點和手動添加依賴節點,其中拖入依賴節點的操作,更多信息,請參見步驟三:(可選)添加系統節點并配置。以下以自動解析依賴節點為例介紹。
在運行配置頁簽的依賴節點區域,單擊解析依賴。
若該節點存在依賴節點,解析完成后,在依賴節點區域會自動顯示依賴節點的詳細信息,并在場景畫布中自動生成對應依賴節點圖標。
參數
說明
依賴節點
上游
說明查看當前節點依賴的節點信息。
解析依賴
當配置完節點輸入信息后,單擊解析依賴,可自動解析該節點的依賴節點,并將依賴信息展示在場景畫布運行配置的依賴節點區域中。
節點
該依賴節點的名稱。
場景/工作流
該依賴節點的所屬場景或者任務流的名稱及標識。
所屬工作區組
該依賴節點的所屬工作區。
依賴關系
依賴節點的類型。
強依賴:若依賴節點運行失敗,調度阻塞,當前節點無法執行,等待依賴節點恢復成功。
弱依賴:若依賴節點運行失敗,調度不阻塞,當前節點繼續按照計劃繼續觸發執行
下游
說明在下游節點頁簽中,查看當前節點被哪些節點或者任務依賴,即展示依賴當前節點的其他節點信息。無需配置。
節點
依賴當前節點的節點名稱。
場景/工作流
當前節點作為依賴節點的其他節點所屬場景的場景名稱及標識以及工作流名稱及標識。
所屬工作組
把當前節點作為依賴節點的其他節點的所屬工作組。
步驟四:連接各節點
請根據算法流程的數據流向連接算法流程中的各節點。
將鼠標指向上游節點下部的圓圈。
當圓圈點亮時按下鼠標左鍵并拖拽到下游節點上部的圓圈上。
當下游節點上部的圓圈點亮時松開鼠標。
說明當畫布工具欄中,單擊打開連線模式時,則連接各節點時,直接單擊對應節點連線即可,不需要將鼠標指向各節點的圓圈。
雙擊連線可查看連線詳情,連線過程中保證輸出標識-數據類型和輸入標識-數據類型一致。
說明在搭建節點流程的過程中,如果上游節點和下游節點需要連線(即上游節點的輸出數據要作為下游節點的輸入數據),則要求上游節點的輸出數據與下游節點的輸入數據的數據格式和云計算資源類型必須一致,任意結構(星號(*))和為空的除外。
步驟五:運行開發環境場景
單擊
 圖標。
圖標。在確認對話框中,單擊確定。
在物理化預分析對話框中,確認待物理化的邏輯表無誤后,單擊確定,等待部署成功。
在設置業務日期對話框,選擇日期,單擊確定,等待運行成功。
說明日期只能選擇T-1之前的日期。T表示今天(Today)。
當僅需要運行場景中的部分節點時,按住Shift+鼠標框選需要運行的節點,即可運行已選擇的節點,節省運行時間。
如果您需要查看之前日期的運行結果,可以通過補數據功能實現,具體操作,請參見新建補數據計劃。
如果場景運行失敗,您可將鼠標移動至狀態,單擊后面的查看日志,通過運行日志定位失敗原因,更多詳情,請參見查看開發環境場景運維信息。
相關操作
操作 | 說明 |
刪除開發環境場景 | 在開發環境場景列表中,選擇待刪除的開發環境場景,單擊刪除。在彈出對話框中,單擊確認。 說明 如果待刪除的開發環境場景已發布了生產場景,則您需要預先下線該生產場景,具體操作,請參見下線生產環境場景。 重要 場景刪除后不可恢復,請謹慎操作。 |
修改開發環境場景所屬目錄 | 在開發環境場景列表中,選中需要修改所屬目錄的場景,單擊修改所屬目錄,選擇需要歸屬的目錄,單擊確定。 說明 不支持將開發環境場景的所屬目錄修改為默認目錄,只可從默認類目改成其他目錄。 |
發布計算節點為公共節點 | 如果需要復用當前計算節點的計算邏輯時,可以將該計算節點發布為公共節點。操作方法如下:
|
后續步驟
開發環境場景運行后,需要將開發環境場景上線至生產場景,才能提供生產服務,具體操作,請參見上線開發環境場景。