歷史版本的SmartData(3.0.x~3.5.x)服務存在已知缺陷可能會造成緩存數據出現損壞,導致讀取數據內容發生異常。本文為您介紹缺陷影響,缺陷方案以及缺陷修復流程。
缺陷影響
- 缺陷影響的組件:打開SmartData數據緩存功能的所有組件。
重要 如果集群部署了SmartData,但確定不會使用緩存可以忽略本缺陷。
SmartData支持JindoFS Cache模式和JindoFS Block模式兩種緩存模式。
- 缺陷影響的版本:
- EMR版本:3.30.x、4.5.x、3.32.x、4.6.x、3.33.x、4.7.x、3.34.x、4.8.x、3.35.x、4.9.x。
- SmartData版本:3.0.x、3.1.x、3.2.x、3.3.x、3.4.x、3.5.x。
- 缺陷級別:嚴重,建議修復,概率性發生時會出現數據正確性問題。
- 缺陷發生現象:如果集群啟用JindoFS Cache模式(即設置數據緩存參數jfs.cache.data-cache.enable為true)或者使用了JindoFS Block模式(Block模式默認啟用緩存),則數據緩存會出現小概率數據污染的情況,從而導致作業讀取數據時報錯。例如,作業對源數據讀取報數據內容不正確的錯誤(ORC或Parquet文件格式無法解析)或HBase報HFile格式錯誤等。
缺陷修復方案
由于歷史版本緩存損壞問題是由于Storage Service的小文件合并(compaction)流程的缺陷導致,通過修改compaction配置關閉該優化路徑并重啟SmartData服務,即可避免該問題的產生。如果已發生該問題,優先關閉緩存開關及時止損,以消除緩存數據的影響,盡快恢復線上業務;如果您僅啟用了Cache模式,沒用使用Block模式,則可以使用工具對集群全部緩存進行全量清理,徹底格式化緩存系統,從而清除集群中所有可能損壞的緩存塊,清理完成后可以重新啟用緩存。
修復流程
常規修復
如果所在集群尚未發生該問題,則可以通過關閉小文件合并的優化路徑,徹底避免該問題。
- 在EMR控制臺SmartData服務頁面,添加自定義配置。
- 在SmartData服務的storage配置頁,單擊自定義配置。

- 在新增配置項對話框中,添加Key為storage.compaction.enable,Value為false的配置項。
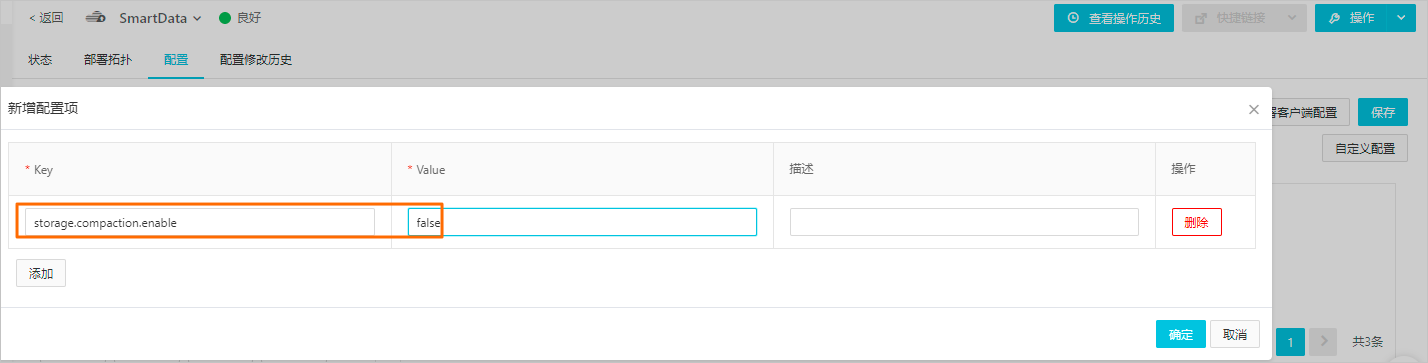
- 在SmartData服務的storage配置頁,單擊自定義配置。
- 重啟Jindo Storage Service。
- 在SmartData服務頁面,選擇。
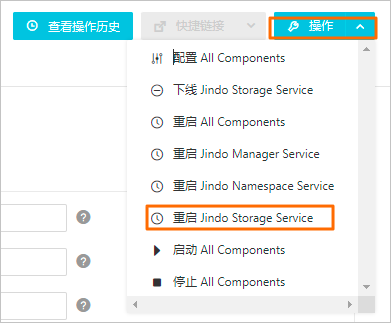
- 在SmartData服務頁面,選擇。
緊急修復
對于已發生該問題的情況,請按以下步驟及時恢復業務,并進行緩存修復: