本文介紹在阿里云E-MapReduce創建的包含kafka服務的DataFlow集群中,如何使用Spark Streaming作業從Kafka中實時消費數據。
前提條件
已注冊阿里云賬號。
已開通E-MapReduce服務。
已完成云賬號的授權,詳情請參見角色授權。
步驟一:創建DataLake和DataFlow集群
創建同一個安全組下的DataLake和DataFlow集群(包含Kafka服務)。創建詳情請參見創建集群。
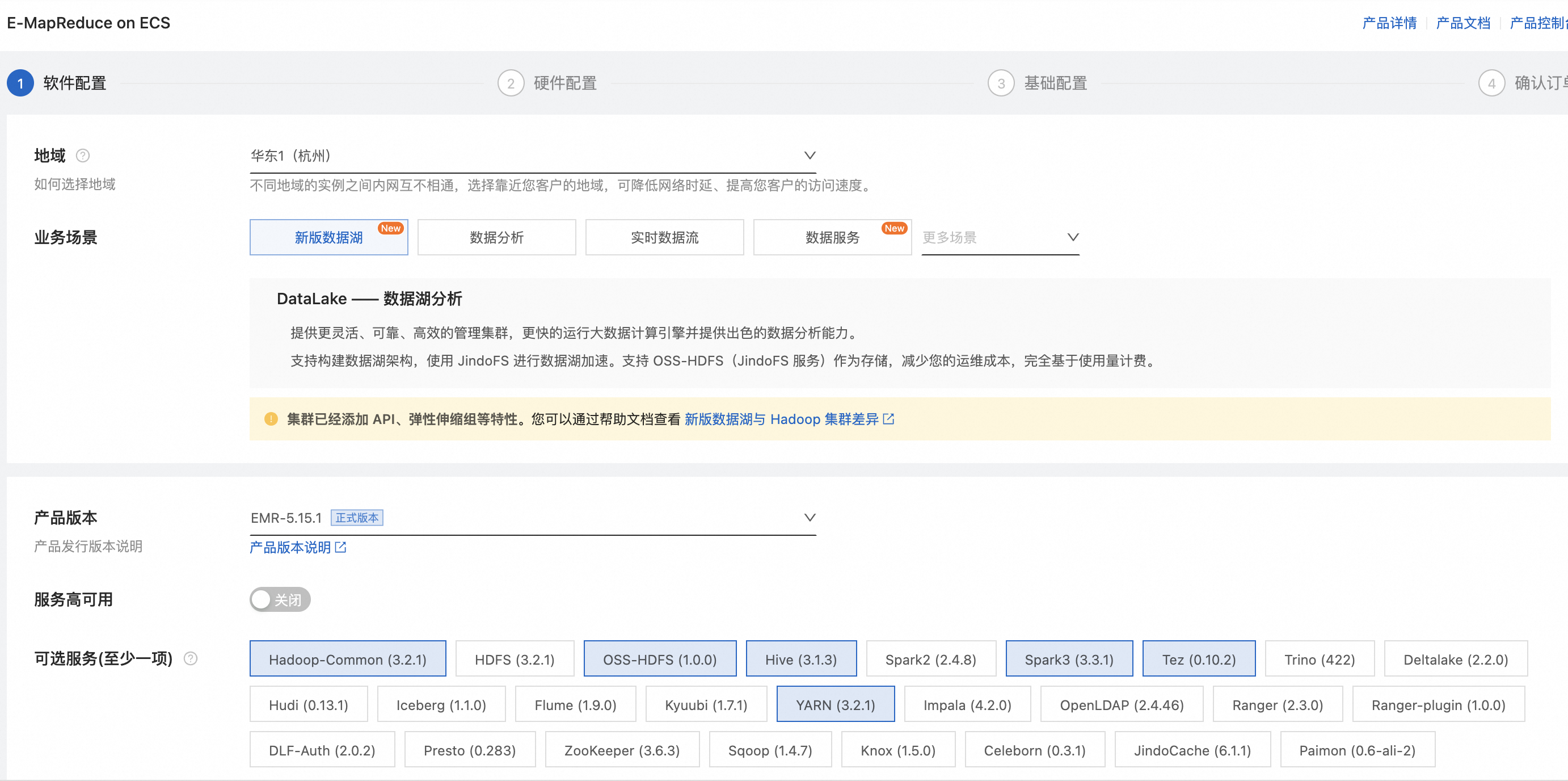
創建DataLake集群。
說明本文以Spark 3為例。
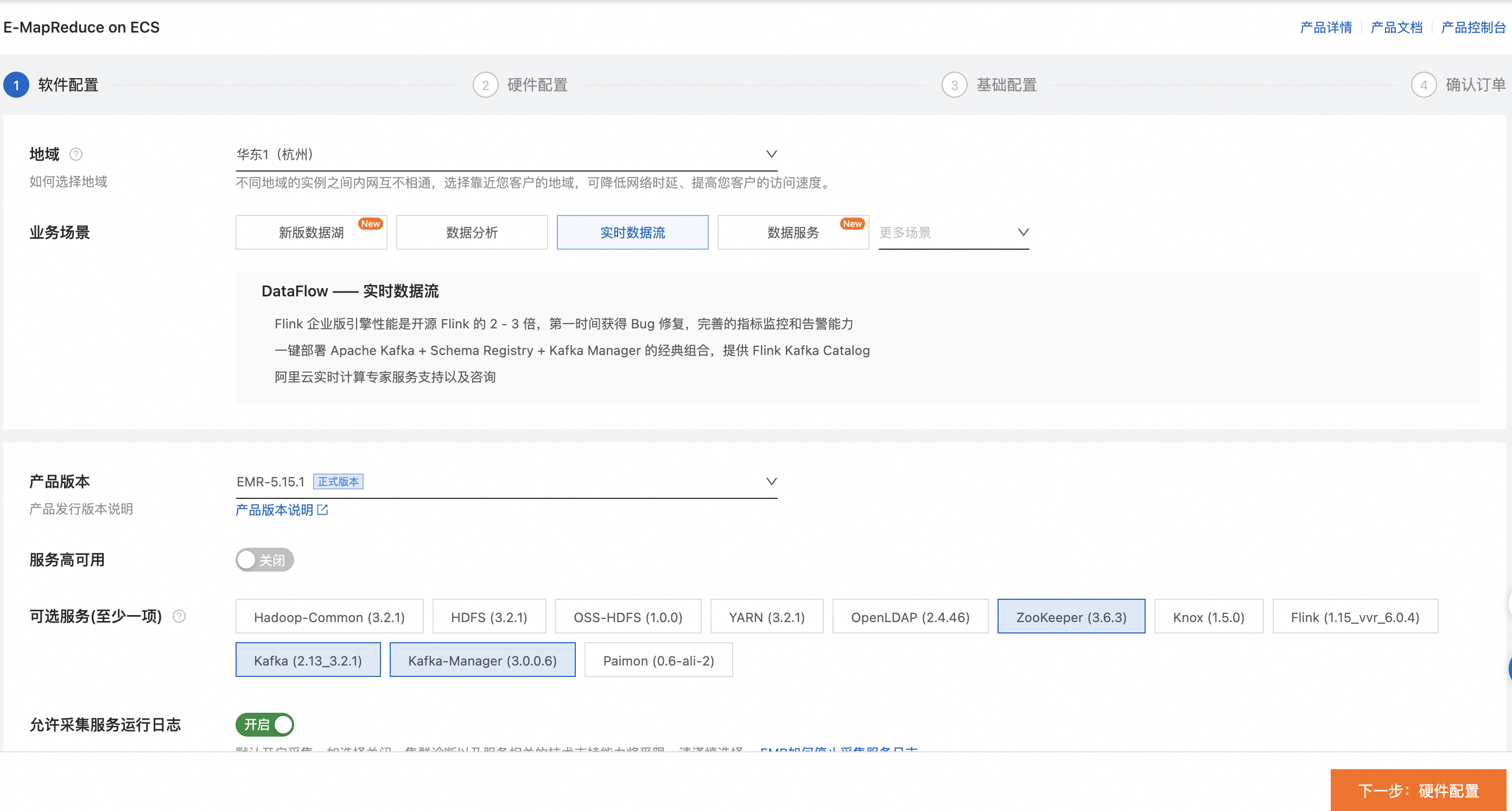
創建DataFlow。
說明務必確認已選擇Kafka服務。系統會自動選擇其依賴的Kafka-Manager和Zookeeper服務。
步驟二:獲取JAR包并上傳到DataLake集群
獲取JAR包(spark-streaming-demo-1.0.jar)。
上傳JAR包至DataLake集群Master節點的
/home/emr-user路徑下。
步驟三:在DataFlow集群上創建Topic
本示例將創建一個名稱為test的Topic。
登錄DataFlow集群的Master節點,詳情請參見登錄集群。
執行以下命令,創建Topic。
kafka-topics.sh --create --bootstrap-server core-1-1:9092,core-1-2:9092,core-1-3:9092 --replication-factor 2 --partitions 2 --topic demo說明創建Topic后,請保留該登錄窗口,后續步驟仍將使用。
步驟四:運行Spark Streaming作業
本示例將運行一個流式單詞統計(WordCount)的作業。
登錄DataLake集群的Master節點,詳情請參見登錄集群。
執行以下命令,進入emr-user目錄。
cd /home/emr-user執行以下命令,進行流式單詞統計(WordCount)。
spark-submit --class com.aliyun.emr.KafkaApp1 ./spark-streaming-demo-1.0.jar <Kafka broker的內網IP地址>:9092 demogroup1 demo關鍵參數如下表所示。
參數
描述
<Kafka broker的內網IP地址>:9092DataFlow集群中Broker節點的內網IP地址和端口號,端口號默認為9092。例如,
172.16.**.**:9092,172.16.**.**:9092,172.16.**.**:9092。您可以在DataFlow集群Kafka服務的狀態頁簽,單擊KafkaBroker組件前的
 圖標,查看所有節點的內網IP地址。
圖標,查看所有節點的內網IP地址。demogroup1指定Kafka消費組的名稱。您也可以根據實際情況修改。
demoTopic名稱。
步驟五:使用Kafka發布消息
在DataFlow集群的命令行窗口,執行如下命令運行Kafka的生產者。
kafka-topics.sh --create --bootstrap-server core-1-1:9092,core-1-2:9092,core-1-3:9092 --replication-factor 2 --partitions 2 --topic demokafka-console-producer.sh --topic demo --broker-list core-1-1:9092在DataFlow集群的登錄窗口中輸入文本,在DataLake集群的登錄窗口中,會實時顯示文本的統計信息。
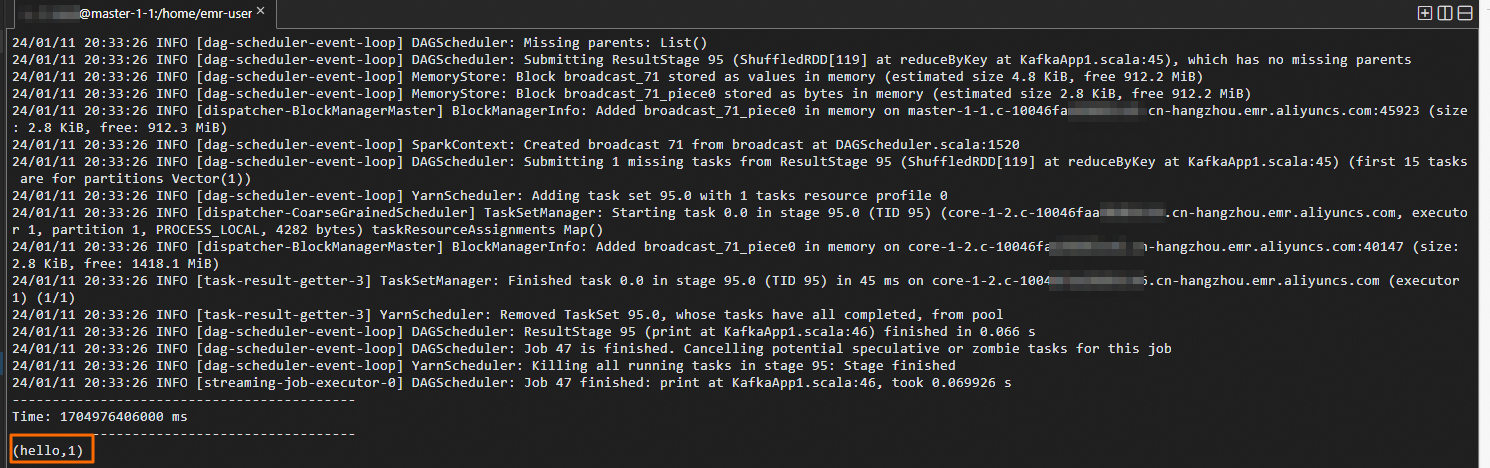
例如,在DataFlow集群的登錄窗口輸入如下信息。

DataLake集群的登錄窗口會輸出如下信息。
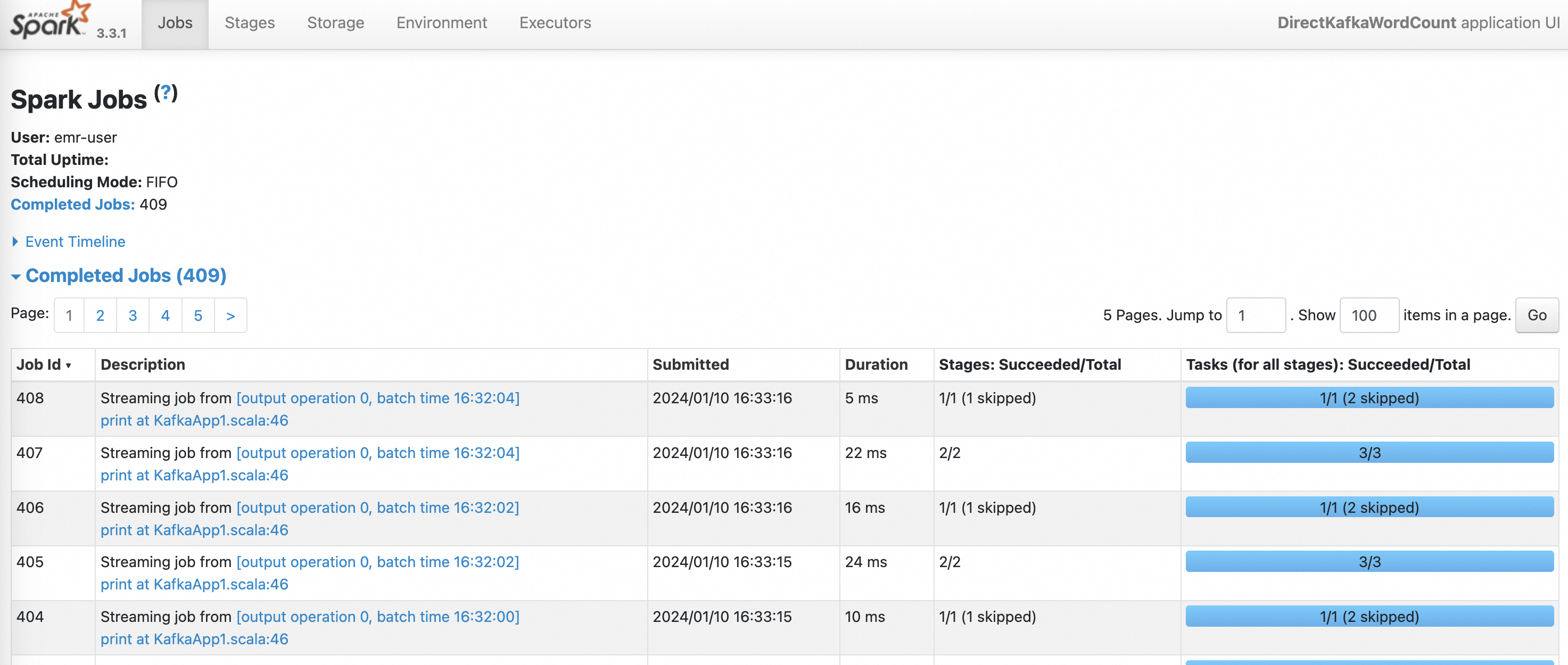
步驟六:查看Spark Streaming作業狀態
在EMR on ECS頁面,單擊DataLake集群的名稱。
單擊訪問鏈接與端口頁簽。
訪問SPARK UI,詳情請參見訪問鏈接與端口。
在History Server頁面,單擊待查看的App ID。
您可以查看Spark Streaming作業的狀態。