數(shù)據(jù)同步
數(shù)據(jù)同步是指數(shù)倉或者數(shù)據(jù)湖內(nèi)的數(shù)據(jù)與上游業(yè)務(wù)庫內(nèi)的數(shù)據(jù)保持同步的狀態(tài)。當(dāng)上游業(yè)務(wù)庫內(nèi)的數(shù)據(jù)發(fā)生變更之后,下游的數(shù)倉/數(shù)據(jù)湖立即感知到數(shù)據(jù)變化,并將數(shù)據(jù)變化同步過來。在數(shù)據(jù)庫中,這類場景稱為Change Data Capture(CDC)場景。
背景信息
CDC的實(shí)現(xiàn)方案比較多,但是大多是在數(shù)據(jù)庫領(lǐng)域,相應(yīng)的工具也比較多。在大數(shù)據(jù)領(lǐng)域,這方面的實(shí)踐較少,也缺乏相應(yīng)的標(biāo)準(zhǔn)和技術(shù)實(shí)現(xiàn)。通常您需要選擇已有的引擎,利用它們的能力自己搭建一套CDC方案。常見的方案大概分為下面兩類:
定期批量Merge方式:上游原始表捕獲增量更新,將更新的數(shù)據(jù)輸出到一個新的表中,下游倉庫利用MERGE或UPSERT語法將增量表與已有表進(jìn)行合并。這種方式要求表具有主鍵或者聯(lián)合主鍵,且實(shí)時(shí)性也較差。另外,這種方法一般不能處理DELETE的數(shù)據(jù),實(shí)際上用刪除原表重新寫入的方式支持了DELETE,但是相當(dāng)于每次都重新寫一次全量表,性能不可取,還需要有一個特殊字段來標(biāo)記數(shù)據(jù)是否屬于增量更新數(shù)據(jù)。
上游源表輸出binlog(這里我們指廣義的binlog,不限于MySQL),下游倉庫進(jìn)行binlog的回放。這種方案一般需要下游倉庫能夠具有實(shí)時(shí)回放的能力。但是可以將row的變化作為binlog輸出,這樣,只要下游具備INSERT、UPDATE、DELETE的能力就可以了。不同于第一種方案,這種方案可以和流式系統(tǒng)結(jié)合起來。binlog可以實(shí)時(shí)地流入注入Kafka的消息分發(fā)系統(tǒng),下游倉庫訂閱相應(yīng)的Topic,實(shí)時(shí)拉取并進(jìn)行回放。
批量更新方式
此方案適用于沒有Delete且實(shí)時(shí)性要求不高的場景。
建立一張MySQL表,插入一部分?jǐn)?shù)據(jù)。
CREATE TABLE sales(id LONG, date DATE, name VARCHAR(32), sales DOUBLE, modified DATETIME); INSERT INTO sales VALUES (1, '2019-11-11', 'Robert', 323.00, '2019-11-11 12:00:05'), (2, '2019-11-11', 'Lee', 500.00, '2019-11-11 16:11:46'), (3, '2019-11-12', 'Robert', 136.00, '2019-11-12 10:23:54'), (4, '2019-11-13', 'Lee', 211.00, '2019-11-13 11:33:27'); SELECT * FROM sales;+------+------------+--------+-------+---------------------+ | id | date | name | sales | modified | +------+------------+--------+-------+---------------------+ | 1 | 2019-11-11 | Robert | 323 | 2019-11-11 12:00:05 | | 2 | 2019-11-11 | Lee | 500 | 2019-11-11 16:11:46 | | 3 | 2019-11-12 | Robert | 136 | 2019-11-12 10:23:54 | | 4 | 2019-11-13 | Lee | 211 | 2019-11-13 11:33:27 | +------+------------+--------+-------+---------------------+說明modified就是我們上文提到的用于標(biāo)識數(shù)據(jù)是否屬于增量更新數(shù)據(jù)的字段。將MySQL表的內(nèi)容全量導(dǎo)出到HDFS。
sqoop import --connect jdbc:mysql://emr-header-1:3306/test --username root --password EMRroot1234 -table sales -m1 --target-dir /tmp/cdc/staging_sales hdfs dfs -ls /tmp/cdc/staging_sales Found 2 items -rw-r----- 2 hadoop hadoop 0 2019-11-26 10:58 /tmp/cdc/staging_sales/_SUCCESS -rw-r----- 2 hadoop hadoop 186 2019-11-26 10:58 /tmp/cdc/staging_sales/part-m-00000建立delta表,并導(dǎo)入MySQL表的全量數(shù)據(jù)。
執(zhí)行以下命令,啟動streaming-sql。
streaming-sql建立delta表。
-- `LOAD DATA INPATH`語法對delta table不可用,先建立一個臨時(shí)外部表。 CREATE TABLE staging_sales (id LONG, date STRING, name STRING, sales DOUBLE, modified STRING) USING csv LOCATION '/tmp/cdc/staging_sales/'; CREATE TABLE sales USING delta LOCATION '/user/hive/warehouse/test.db/test' SELECT * FROM staging_sales; SELECT * FROM sales; 1 2019-11-11 Robert 323.0 2019-11-11 12:00:05.0 2 2019-11-11 Lee 500.0 2019-11-11 16:11:46.0 3 2019-11-12 Robert 136.0 2019-11-12 10:23:54.0 4 2019-11-13 Lee 211.0 2019-11-13 11:33:27.0 --刪除臨時(shí)表。 DROP TABLE staging_sales;切換到命令行刪除臨時(shí)目錄。
hdfs dfs -rm -r -skipTrash /tmp/cdc/staging_sales/ # 刪除臨時(shí)目錄。
在原MySQL表做一些操作,插入更新部分?jǐn)?shù)據(jù)。
-- 注意DELETE的數(shù)據(jù)無法被Sqoop導(dǎo)出,因而沒辦法合并到目標(biāo)表中 -- DELETE FROM sales WHERE id = 1; UPDATE sales SET name='Robert',modified=now() WHERE id = 2; INSERT INTO sales VALUES (5, '2019-11-14', 'Lee', 500.00, now()); SELECT * FROM sales;+------+------------+--------+-------+---------------------+ | id | date | name | sales | modified | +------+------------+--------+-------+---------------------+ | 1 | 2019-11-11 | Robert | 323 | 2019-11-11 12:00:05 | | 2 | 2019-11-11 | Robert | 500 | 2019-11-26 11:08:34 | | 3 | 2019-11-12 | Robert | 136 | 2019-11-12 10:23:54 | | 4 | 2019-11-13 | Lee | 211 | 2019-11-13 11:33:27 | | 5 | 2019-11-14 | Lee | 500 | 2019-11-26 11:08:38 | +------+------------+--------+-------+---------------------+sqoop導(dǎo)出更新數(shù)據(jù)。
sqoop import --connect jdbc:mysql://emr-header-1:3306/test --username root --password EMRroot1234 -table sales -m1 --target-dir /tmp/cdc/staging_sales --incremental lastmodified --check-column modified --last-value "2019-11-20 00:00:00" hdfs dfs -ls /tmp/cdc/staging_sales/ Found 2 items -rw-r----- 2 hadoop hadoop 0 2019-11-26 11:11 /tmp/cdc/staging_sales/_SUCCESS -rw-r----- 2 hadoop hadoop 93 2019-11-26 11:11 /tmp/cdc/staging_sales/part-m-00000為更新數(shù)據(jù)建立臨時(shí)表,然后MERGE到目標(biāo)表。
CREATE TABLE staging_sales (id LONG, date STRING, name STRING, sales DOUBLE, modified STRING) USING csv LOCATION '/tmp/cdc/staging_sales/'; MERGE INTO sales AS target USING staging_sales AS source ON target.id = source.id WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT *; SELECT * FROM sales; 1 2019-11-11 Robert 323.0 2019-11-11 12:00:05.0 3 2019-11-12 Robert 136.0 2019-11-12 10:23:54.0 2 2019-11-11 Robert 500.0 2019-11-26 11:08:34.0 5 2019-11-14 Lee 500.0 2019-11-26 11:08:38.0 4 2019-11-13 Lee 211.0 2019-11-13 11:33:27.0
實(shí)時(shí)同步
實(shí)時(shí)同步的方式對場景的限制沒有第一種方式多,例如,DELETE數(shù)據(jù)也能處理,不需要修改業(yè)務(wù)模型增加一個額外字段。但是這種方式實(shí)現(xiàn)較為復(fù)雜,如果binlog的輸出不標(biāo)準(zhǔn)的話,您還需要寫專門的UDF來處理binlog數(shù)據(jù)。例如RDS MySQL輸出的binlog,以及Log Service輸出的binlog格式上就不相同。
在這個例子中,我們使用阿里云RDS MySQL版作為源庫,使用阿里云DTS服務(wù)將源庫的binlog數(shù)據(jù)實(shí)時(shí)導(dǎo)出到Kafka集群,您也可以選擇開源的Maxwell或Canal等。 之后我們定期從Kafka讀取binlog并存放到OSS或HDFS,然后用Spark讀取該binlog并解析出Insert、Update、Delete的數(shù)據(jù),最后用Delta的Merge API將源表的變動更新到Delta表,其鏈路如下圖所示。
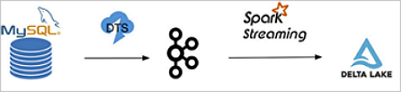
首先開通RDS MySQL服務(wù),設(shè)置好相應(yīng)的用戶、Database和權(quán)限(RDS的具體使用請參見什么是RDS MySQL)。建立一張表并插入一些數(shù)據(jù)。
-- 該建表動作可以在RDS控制臺頁面方便地完成,這里展示最后的建表語句。 CREATE TABLE `sales` ( `id` bigint(20) NOT NULL, `date` date DEFAULT NULL, `name` varchar(32) DEFAULT NULL, `sales` double DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 -- 插入部分?jǐn)?shù)據(jù),并確認(rèn)。 INSERT INTO sales VALUES (1, '2019-11-11', 'Robert', 323.00), (2, '2019-11-11', 'Lee', 500.00), (3, '2019-11-12', 'Robert', 136.00), (4, '2019-11-13', 'Lee', 211.00); SELECT * FROM `sales` ; ``` <img src="./img/rds_tbl.png" width = "400" alt="RDS Table" align=center />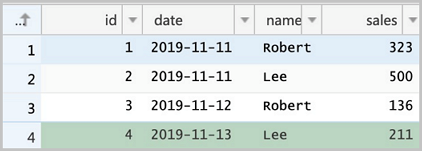
建立一個EMR Kafka集群(如果已有EMR Kafka集群的話請?zhí)^),并在Kafka集群上創(chuàng)建一個名為sales的topic:
bash
kafka-topics.sh --create --bootstrap-server core-1-1:9092 --partitions 1 --replication-factor 1 --topic sales開通DTS服務(wù)(如果未開通的話),并創(chuàng)建一個同步任務(wù),源庫選擇RDS MySQL,目標(biāo)庫選擇Kafka。
配置DTS的同步鏈路,將RDS的sales table同步至Kafka,目標(biāo)topic選擇sales。正常的話,可以在Kafka的機(jī)器上看到數(shù)據(jù)。
編寫Spark Streaming作業(yè),從Kafka中解析binlog,利用Delta的MERGE API將binlog數(shù)據(jù)實(shí)時(shí)回放到目標(biāo)Delta表。DTS導(dǎo)入到Kafka的binlog數(shù)據(jù)的樣子如下,其每一條記錄都表示了一條數(shù)據(jù)庫數(shù)據(jù)的變更。 詳情請參見附錄:Kafka內(nèi)binlog格式窺探。
|字段名稱|值| |:--|:--| |recordid|1| |source|{"sourceType": "MySQL", "version": "0.0.0.0"}| |dbtable|delta_cdc.sales| |recordtype|INIT| |recordtimestamp|1970-01-01 08:00:00| |extratags|{}| |fields|["id","date","name","sales"]| |beforeimages|{}| |afterimages|{"sales":"323.0","date":"2019-11-11","name":"Robert","id":"1"}|說明這里最重要的字段是
recordtype、beforeimages、afterimages。其中recordtype是該行記錄對應(yīng)的動作,包含INIT、UPDATE、DELETE、INSERT幾種。beforeimages為該動作執(zhí)行前的內(nèi)容,afterimages為動作執(zhí)行后的內(nèi)容。Scala
編寫Spark代碼。
以Scala版代碼為例,代碼示例如下。
import io.delta.tables._ import org.apache.spark.internal.Logging import org.apache.spark.sql.{AnalysisException, SparkSession} import org.apache.spark.sql.expressions.Window import org.apache.spark.sql.functions._ import org.apache.spark.sql.types.{DataTypes, StructField} val schema = DataTypes.createStructType(Array[StructField]( DataTypes.createStructField("id", DataTypes.StringType, false), DataTypes.createStructField("date", DataTypes.StringType, true), DataTypes.createStructField("name", DataTypes.StringType, true), DataTypes.createStructField("sales", DataTypes.StringType, true) )) //初始化delta表中INIT類型的數(shù)據(jù)。 def initDeltaTable(): Unit = { spark.read .format("kafka") .option("kafka.bootstrap.servers", "192.168.XX.XX:9092") .option("subscribe", "sales") .option("failOnDataLoss", value = false) .load() .createTempView("initData") // 對于DTS同步到Kafka的數(shù)據(jù),需要avro解碼,EMR提供了dts_binlog_parser的UDF來處理此問題。 val dataBatch = spark.sql( """ |SELECT dts_binlog_parser(value) |AS (recordID, source, dbTable, recordType, recordTimestamp, extraTags, fields, beforeImages, afterImages) |FROM initData """.stripMargin) // 選擇INIT類型的數(shù)據(jù)作為初始數(shù)據(jù)。 dataBatch.select(from_json(col("afterImages").cast("string"), schema).as("jsonData")) .where("recordType = 'INIT'") .select( col("jsonData.id").cast("long").as("id"), col("jsonData.date").as("date"), col("jsonData.name").as("name"), col("jsonData.sales").cast("decimal(7,2)")).as("sales") .write.format("delta").mode("append").save("/delta/sales") } try { DeltaTable.forPath("/delta/sales") } catch { case e: AnalysisException if e.getMessage().contains("is not a Delta table") => initDeltaTable() } spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "192.168.XX.XX:9092") .option("subscribe", "sales") .option("startingOffsets", "earliest") .option("maxOffsetsPerTrigger", 1000) .option("failOnDataLoss", value = false) .load() .createTempView("incremental") // 對于DTS同步到Kafka的數(shù)據(jù),需要avro解碼,EMR提供了dts_binlog_parser的UDF來處理此問題。 val dataStream = spark.sql( """ |SELECT dts_binlog_parser(value) |AS (recordID, source, dbTable, recordType, recordTimestamp, extraTags, fields, beforeImages, afterImages) |FROM incremental """.stripMargin) val task = dataStream.writeStream .option("checkpointLocation", "/delta/sales_checkpoint") .foreachBatch( (ops, id) => { // 該window function用于提取針對某一記錄的最新一條修改。 val windowSpec = Window .partitionBy(coalesce(col("before_id"), col("id"))) .orderBy(col("recordId").desc) // 從binlog中解析出recordType, beforeImages.id, afterImages.id, afterImages.date, afterImages.name, afterImages.sales。 val mergeDf = ops .select( col("recordId"), col("recordType"), from_json(col("beforeImages").cast("string"), schema).as("before"), from_json(col("afterImages").cast("string"), schema).as("after")) .where("recordType != 'INIT'") .select( col("recordId"), col("recordType"), when(col("recordType") === "INSERT", col("after.id")).otherwise(col("before.id")).cast("long").as("before_id"), when(col("recordType") === "DELETE", col("before.id")).otherwise(col("after.id")).cast("long").as("id"), when(col("recordType") === "DELETE", col("before.date")).otherwise(col("after.date")).as("date"), when(col("recordType") === "DELETE", col("before.name")).otherwise(col("after.name")).as("name"), when(col("recordType") === "DELETE", col("before.sales")).otherwise(col("after.sales")).cast("decimal(7,2)").as("sales") ) .select( dense_rank().over(windowSpec).as("rk"), col("recordType"), col("before_id"), col("id"), col("date"), col("name"), col("sales") ) .where("rk = 1") //merge條件,用于將incremental數(shù)據(jù)和delta表數(shù)據(jù)做合并。 val mergeCond = "target.id = source.before_id" DeltaTable.forPath(spark, "/delta/sales").as("target") .merge(mergeDf.as("source"), mergeCond) .whenMatched("source.recordType='UPDATE'") .updateExpr(Map( "id" -> "source.id", "date" -> "source.date", "name" -> "source.name", "sales" -> "source.sales")) .whenMatched("source.recordType='DELETE'") .delete() .whenNotMatched("source.recordType='INSERT' OR source.recordType='UPDATE'") .insertExpr(Map( "id" -> "source.id", "date" -> "source.date", "name" -> "source.name", "sales" -> "source.sales")) .execute() } ).start() task.awaitTermination()打包程序并部署到DataLake集群。
本地調(diào)試完成后,通過以下命令打包。
mvn clean install使用SSH方式登錄DataLake集群,詳情信息請參見登錄集群。
上傳JAR包至DataLake集群。
本示例是上傳到DataLake集群的根目錄下。
提交運(yùn)行Spark作業(yè)。
執(zhí)行以下命令,通過spark-submit提交Spark作業(yè)。
spark-submit \ --master yarn \ --deploy-mode cluster \ --driver-memory 1g \ --executor-cores 2 \ --executor-memory 3g \ --num-executors 1 \ --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.2 \ --class com.aliyun.delta.StreamToDelta \ delta-demo-1.0.jar說明delta-demo-1.0.jar為您打包好的JAR包。--class和JAR包請根據(jù)您實(shí)際信息修改。
SQL
執(zhí)行以下命令,進(jìn)入streaming-sql客戶端。
streaming-sql --master local執(zhí)行以下SQL語句。
CREATE TABLE kafka_sales USING kafka OPTIONS( kafka.bootstrap.servers='192.168.XX.XX:9092', subscribe='sales' ); CREATE TABLE delta_sales(id long, date string, name string, sales decimal(7, 2)) USING delta LOCATION '/delta/sales'; INSERT INTO delta_sales SELECT CAST(jsonData.id AS LONG), jsonData.date, jsonData.name, jsonData.sales FROM ( SELECT from_json(CAST(afterImages as STRING), 'id STRING, date DATE, name STRING, sales STRING') as jsonData FROM ( SELECT dts_binlog_parser(value) AS (recordID, source, dbTable, recordType, recordTimestamp, extraTags, fields, beforeImages, afterImages) FROM kafka_sales ) binlog WHERE recordType='INIT' ) binlog_wo_init; CREATE SCAN incremental on kafka_sales USING STREAM OPTIONS( startingOffsets='earliest', maxOffsetsPerTrigger='1000', failOnDataLoss=false ); CREATE STREAM job OPTIONS( checkpointLocation='/delta/sales_checkpoint' ) MERGE INTO delta_sales as target USING ( SELECT recordId, recordType, before_id, id, date, name, sales FROM( SELECT recordId, recordType, CASE WHEN recordType = "INSERT" then after.id else before.id end as before_id, CASE WHEN recordType = "DELETE" then CAST(before.id as LONG) else CAST(after.id as LONG) end as id, CASE WHEN recordType = "DELETE" then before.date else after.date end as date, CASE WHEN recordType = "DELETE" then before.name else after.name end as name, CASE WHEN recordType = "DELETE" then CAST(before.sales as DECIMAL(7, 2)) else CAST(after.sales as DECIMAL(7, 2)) end as sales, dense_rank() OVER (PARTITION BY coalesce(before.id,after.id) ORDER BY recordId DESC) as rank FROM ( SELECT recordId, recordType, from_json(CAST(beforeImages as STRING), 'id STRING, date STRING, name STRING, sales STRING') as before, from_json(CAST(afterImages as STRING), 'id STRING, date STRING, name STRING, sales STRING') as after FROM ( select dts_binlog_parser(value) as (recordID, source, dbTable, recordType, recordTimestamp, extraTags, fields, beforeImages, afterImages) from incremental ) binlog WHERE recordType != 'INIT' ) binlog_wo_init ) binlog_extract WHERE rank=1 ) as source ON target.id = source.before_id WHEN MATCHED AND source.recordType='UPDATE' THEN UPDATE SET id=source.id, date=source.date, name=source.name, sales=source.sales WHEN MATCHED AND source.recordType='DELETE' THEN DELETE WHEN NOT MATCHED AND (source.recordType='INSERT' OR source.recordType='UPDATE') THEN INSERT (id, date, name, sales) values (source.id, source.date, source.name, source.sales);
待上一步驟中的Spark Streaming作業(yè)啟動后,我們嘗試讀一下這個Delta Table。
執(zhí)行以下命令,進(jìn)入spark-shell客戶端,并查詢數(shù)據(jù)。
spark-shell --master localspark.read.format("delta").load("/delta/sales").show +---+----------+------+------+ | id| date| name| sales| +---+----------+------+------+ | 1|2019-11-11|Robert|323.00| | 2|2019-11-11| Lee|500.00| | 3|2019-11-12|Robert|136.00| | 4|2019-11-13| Lee|211.00| +---+----------+------+------+在RDS控制臺執(zhí)行下列四條命令并確認(rèn)結(jié)果,注意我們對于
id = 2的記錄update了兩次,理論上最終結(jié)果應(yīng)當(dāng)為最新一次修改。DELETE FROM sales WHERE id = 1; UPDATE sales SET sales = 150 WHERE id = 2; UPDATE sales SET sales = 175 WHERE id = 2; INSERT INTO sales VALUES (5, '2019-11-14', 'Robert', 233); SELECT * FROM sales;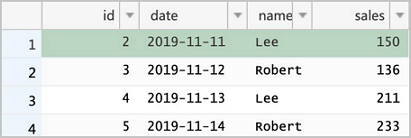
重新讀一下Delta表,發(fā)現(xiàn)數(shù)據(jù)已經(jīng)更新了,
且id=2的結(jié)果為最后一次的修改:spark.read.format("delta").load("/delta/sales").show +---+----------+------+------+ | id| date| name| sales| +---+----------+------+------+ | 5|2019-11-14|Robert|233.00| | 3|2019-11-12|Robert|136.00| | 4|2019-11-13| Lee|211.00| | 2|2019-11-11| Lee|175.00| +---+----------+------+------+
最佳實(shí)踐
隨著數(shù)據(jù)實(shí)時(shí)流入,Delta內(nèi)的小文件會迅速增多。針對這種情況,有兩種解決方案:
對表進(jìn)行分區(qū)。一方面,寫入多數(shù)情況下是針對最近的分區(qū),歷史分區(qū)修改往往頻次不是很高,這個時(shí)候?qū)v史分區(qū)進(jìn)行compaction操作,compaction因事務(wù)沖突失敗的可能性較低。另一方面,帶有分區(qū)謂詞的查詢效率較不分區(qū)的情況會高很多。
在流式寫入的過程中,定期進(jìn)行compaction操作。例如,每過10個mini batch進(jìn)行一次compaction。這種方式不存在compaction由于事務(wù)沖突失敗的問題,但是由于compaction可能會影響到后續(xù)mini batch的時(shí)效性,因此采用這種方式要注意控制compaction的頻次。
對于時(shí)效性要求不高的場景,又擔(dān)心compation因事務(wù)沖突失敗,可以采用如下所示處理。在這種方式中,binlog的數(shù)據(jù)被定期收集到OSS上(可以通過DTS到Kafka然后借助kafka-connect-oss將binlog定期收集到OSS,也可以采用其他工具),然后啟動Spark批作業(yè)讀取OSS上的binlog,一次性地將binlog合并到Delta Lake。其流程圖如下所示。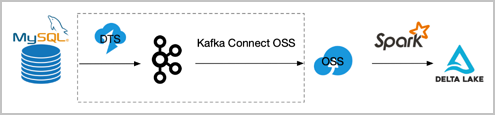
虛線部分可替換為其他可能方案。
附錄:Kafka內(nèi)binlog格式窺探
DTS同步到Kafka的binlog是avro編碼的。如果要探查其文本形式,我們需要借助EMR提供的一個avro解析的UDF:dts_binlog_parser。
Scala
執(zhí)行以下命令,進(jìn)入spark-shell客戶端。
spark-shell --master local執(zhí)行以下Scala語句,查詢數(shù)據(jù)。
spark.read .format("kafka") .option("kafka.bootstrap.servers", "192.168.XX.XX:9092") .option("subscribe", "sales") .option("maxOffsetsPerTrigger", 1000) .load() .createTempView("kafkaData") val kafkaDF = spark.sql("SELECT dts_binlog_parser(value) FROM kafkaData") kafkaDF.show(false)
SQL
執(zhí)行以下命令,進(jìn)入streaming-sql客戶端。
streaming-sql --master local執(zhí)行以下SQL語句,建表并查詢數(shù)據(jù)。
CREATE TABLE kafkaData USING kafka OPTIONS( kafka.bootstrap.servers='192.168.XX.XX:9092', subscribe='sales' ); SELECT dts_binlog_parser(value) FROM kafkaData;最終顯示結(jié)果如下所示。
+--------+---------------------------------------------+---------------+----------+-------------------+---------+----------------------------+------------+--------------------------------------------------------------+ |recordid|source |dbtable |recordtype|recordtimestamp |extratags|fields |beforeimages|afterimages | +--------+---------------------------------------------+---------------+----------+-------------------+---------+----------------------------+------------+--------------------------------------------------------------+ |1 |{"sourceType": "MySQL", "version": "0.0.0.0"}|delta_cdc.sales|INIT |1970-01-01 08:00:00|{} |["id","date","name","sales"]|{} |{"sales":"323.0","date":"2019-11-11","name":"Robert","id":"1"}| |2 |{"sourceType": "MySQL", "version": "0.0.0.0"}|delta_cdc.sales|INIT |1970-01-01 08:00:00|{} |["id","date","name","sales"]|{} |{"sales":"500.0","date":"2019-11-11","name":"Lee","id":"2"} | |3 |{"sourceType": "MySQL", "version": "0.0.0.0"}|delta_cdc.sales|INIT |1970-01-01 08:00:00|{} |["id","date","name","sales"]|{} |{"sales":"136.0","date":"2019-11-12","name":"Robert","id":"3"}| |4 |{"sourceType": "MySQL", "version": "0.0.0.0"}|delta_cdc.sales|INIT |1970-01-01 08:00:00|{} |["id","date","name","sales"]|{} |{"sales":"211.0","date":"2019-11-13","name":"Lee","id":"4"} | +--------+---------------------------------------------+---------------+----------+-------------------+---------+----------------------------+------------+--------------------------------------------------------------+