DataX Writer
DataX Writer插件實現(xiàn)了寫入數(shù)據(jù)到StarRocks目的表的功能。在底層實現(xiàn)上,DataX Writer通過Stream Load以CSV或JSON格式導(dǎo)入數(shù)據(jù)至StarRocks。內(nèi)部將Reader讀取的數(shù)據(jù)進(jìn)行緩存后批量導(dǎo)入至StarRocks,以提高寫入性能。阿里云DataWorks已經(jīng)集成了DataX導(dǎo)入的能力,可以同步MaxCompute數(shù)據(jù)到EMR StarRocks。本文為您介紹DataX Writer原理,以及如何使用DataWorks進(jìn)行離線同步任務(wù)。
背景信息
DataX Writer總體的數(shù)據(jù)流為Source -> Reader -> DataX channel -> Writer -> StarRocks。
功能說明
環(huán)境準(zhǔn)備
您可以下載DataX插件和DataX源碼進(jìn)行測試:
測試時可以使用命令python datax.py --jvm="-Xms6G -Xmx6G" --loglevel=debug job.json。
配置樣例
從MySQL讀取數(shù)據(jù)后導(dǎo)入至StarRocks。
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "xxxx",
"password": "xxxx",
"column": [ "k1", "k2", "v1", "v2" ],
"connection": [
{
"table": [ "table1", "table2" ],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/datax_test1"
]
},
{
"table": [ "table3", "table4" ],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/datax_test2"
]
}
]
}
},
"writer": {
"name": "starrockswriter",
"parameter": {
"username": "xxxx",
"password": "xxxx",
"database": "xxxx",
"table": "xxxx",
"column": ["k1", "k2", "v1", "v2"],
"preSql": [],
"postSql": [],
"jdbcUrl": "jdbc:mysql://172.28.**.**:9030/",
"loadUrl": ["172.28.**.**:8030", "172.28.**.**:8030"],
"loadProps": {}
}
}
}
]
}
}相關(guān)參數(shù)描述如下表所示。
參數(shù) | 描述 | 是否必選 | 默認(rèn)值 |
username | StarRocks數(shù)據(jù)庫的用戶名。 | 是 | 無 |
password | StarRocks數(shù)據(jù)庫的密碼。 | 是 | 無 |
database | StarRocks數(shù)據(jù)庫的名稱。 | 是 | 無 |
table | StarRocks表的名稱。 | 是 | 無 |
loadUrl | StarRocks FE的地址,用于Stream Load,可以為多個FE地址,格式為 | 是 | 無 |
column | 目的表需要寫入數(shù)據(jù)的字段,字段之間用英文逗號(,)分隔。例如, 重要 該參數(shù)必須指定。如果希望導(dǎo)入所有字段,可以使用 | 是 | 無 |
preSql | 寫入數(shù)據(jù)到目的表前,會先執(zhí)行設(shè)置的標(biāo)準(zhǔn)語句。 | 否 | 無 |
postSql | 寫入數(shù)據(jù)到目的表后,會先執(zhí)行設(shè)置的標(biāo)準(zhǔn)語句。 | 否 | 無 |
jdbcUrl | 目的數(shù)據(jù)庫的JDBC連接信息,用于執(zhí)行preSql和postSql。 | 否 | 無 |
maxBatchRows | 單次Stream Load導(dǎo)入的最大行數(shù)。 | 否 | 500000(50W) |
maxBatchSize | 單次Stream Load導(dǎo)入的最大字節(jié)數(shù)。 | 否 | 104857600 (100M) |
flushInterval | 上一次Stream Load結(jié)束至下一次開始的時間間隔。單位為ms。 | 否 | 300000(ms) |
loadProps | Stream Load的請求參數(shù),詳情請參見Stream Load。 | 否 | 無 |
類型轉(zhuǎn)換
默認(rèn)傳入的數(shù)據(jù)均會被轉(zhuǎn)為字符串,并以\t作為列分隔符,\n作為行分隔符,組成CSV文件進(jìn)行Stream Load導(dǎo)入操作。類型轉(zhuǎn)換示例如下:
更改列分隔符,則loadProps配置如下。
"loadProps": { "column_separator": "\\x01", "row_delimiter": "\\x02" }更改導(dǎo)入格式為JSON,則loadProps配置如下。
"loadProps": { "format": "json", "strip_outer_array": true }
DataWorks離線同步使用方式
在DataWorks上創(chuàng)建工作空間,詳情請參見創(chuàng)建工作空間。
在DataWorks上創(chuàng)建測試表并上傳數(shù)據(jù)到MaxCompute數(shù)據(jù)源,詳情請參見建表并上傳數(shù)據(jù)。
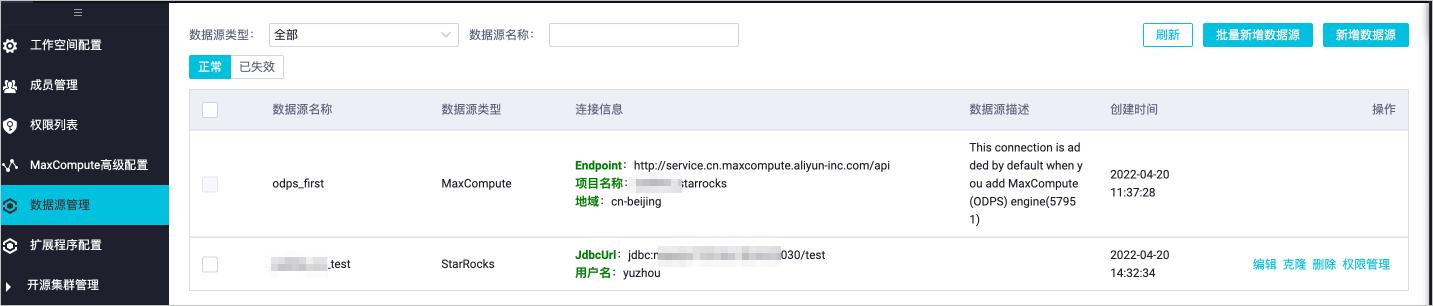
創(chuàng)建StarRocks數(shù)據(jù)源。
在DataWorks的工作空間列表頁面,單擊目標(biāo)工作空間操作列的數(shù)據(jù)集成。
在左側(cè)導(dǎo)航欄,單擊數(shù)據(jù)源。
單擊右上角的新增數(shù)據(jù)源。
在新增數(shù)據(jù)源對話框中,新增StarRocks類型的數(shù)據(jù)源。
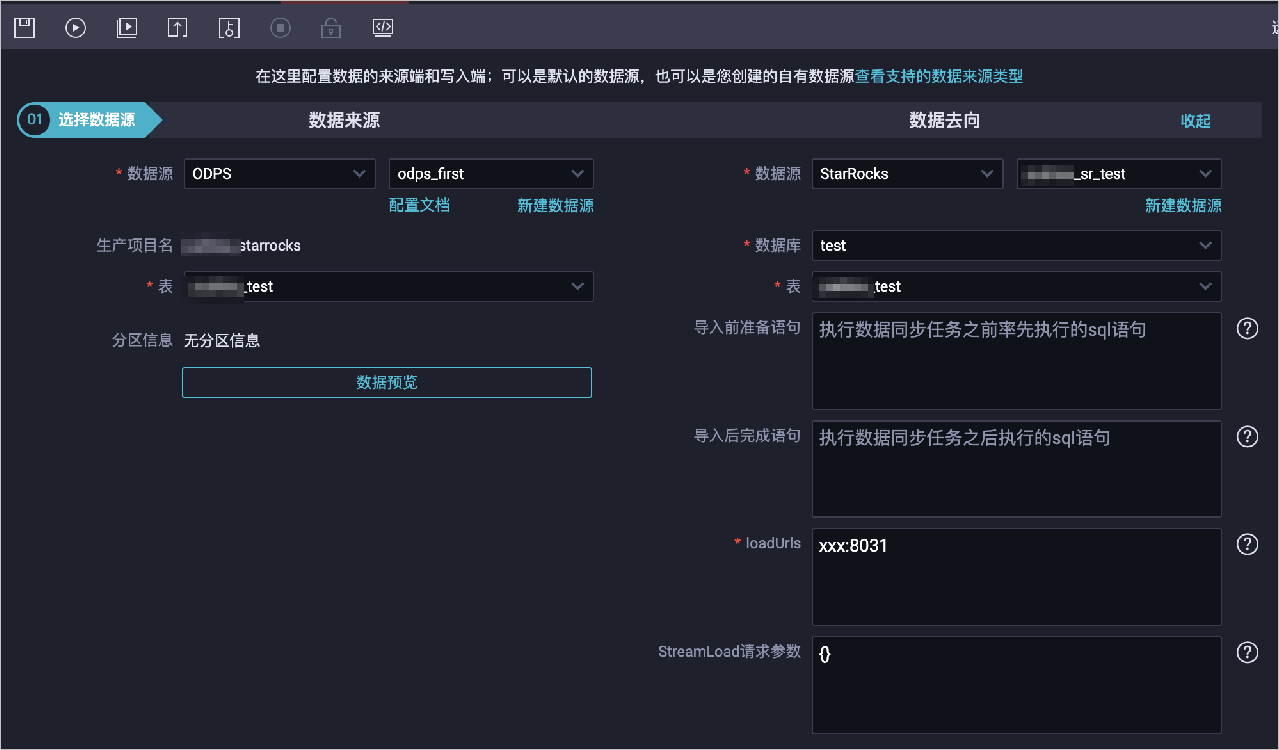
創(chuàng)建離線同步任務(wù)流程。
新建業(yè)務(wù)流程,詳情請參見創(chuàng)建業(yè)務(wù)流程。
在目錄業(yè)務(wù)流程,新建離線同步任務(wù),詳情請參見通過向?qū)J脚渲秒x線同步任務(wù)。
在StarRocks集群中查看數(shù)據(jù),詳情請參見快速入門。