JindoFS是基于阿里云對象存儲OSS,為開源大數據生態構建的Hadoop兼容文件系統(Hadoop Compatible File System,HCFS)。JindoFS提供兼容對象存儲的純客戶端模式(SDK)和緩存模式(Cache),以支持與優化Hadoop和Spark生態大數據計算對OSS的訪問;提供塊存儲模式(Block),以充分利用OSS的海量存儲能力和優化文件系統元數據的操作。
JindoFS純客戶端模式(SDK)
JindoFS純客戶端模式為Hive和Spark等計算框架提供了訪問阿里云OSS及其各種操作的優化,類似Hadoop社區的OSS FileSystem或S3A FileSystem。此模式不改變文件或對象在OSS上的組織方式,文件還是保存在OSS上,JindoFS只是提供面向Hadoop生態的客戶端連接、擴展、適配和優化訪問。您可以使用此模式,上傳JindoFS
SDK的JAR包至組件的classpath目錄,簡單易用,無需部署分布式服務。
JindoFS緩存模式(Cache)
JindoFS緩存模式(Cache)兼容JindoFS純客戶端模式(SDK),同時利用Jindo分布式緩存能力在計算側為OSS提供緩存加速,以滿足大規模的分析和訓練吞吐需求。在純客戶端模式(SDK)基礎上,Cache模式支持可選的元數據緩存和數據分布式緩存,同時保持數據跟OSS兼容和同步。數據緩存可以基于內存、SSD和普通磁盤,以適用不同的計算場景。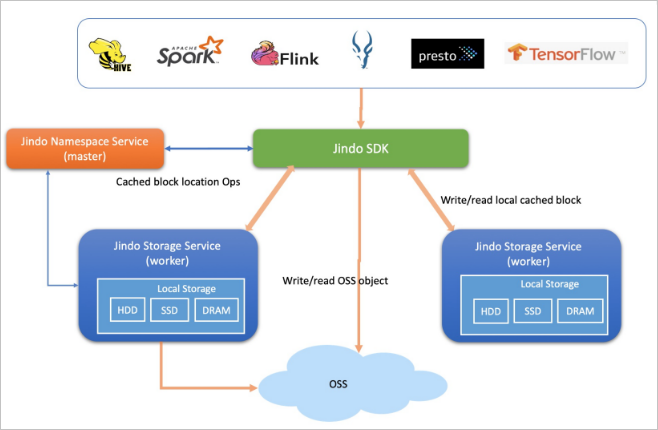
JindoFS塊存儲模式(Block)
JindoFS存儲模式(Block),不僅提供緩存加速能力,還可以組織、存儲數據和管理文件元數據,類似Apache Hadoop HDFS。在此模式下JindoFS是個獨立的存儲系統,只是文件塊數據存儲在OSS上。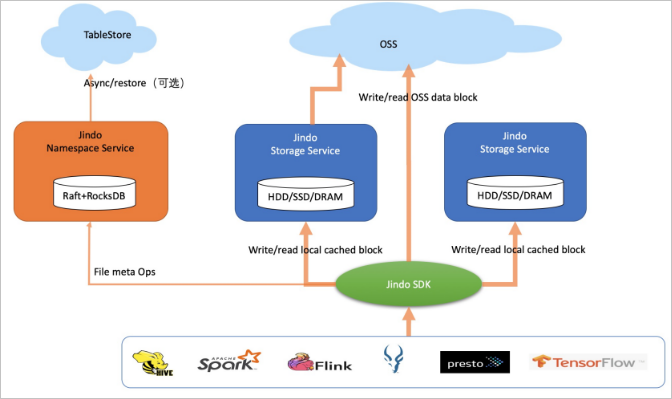
Cache模式和Block模式對比
兩種模式都把數據存儲在OSS上,同時根據本地緩存空間剩余情況確定是否在本地也放置一份以用于緩存加速。
兩種模式的本質區別在于,塊存儲模式可以管理目錄和文件元數據,文件是分成多個塊存儲在OSS上,所以寫到OSS上的是一個一個的文件塊,而緩存模式存儲的是整個文件對象。
三種模式對比
以下從多個維度上介紹JindoFS的純客戶端模式(SDK)、緩存模式(Cache)和塊存儲模式(Block)的差異。
| 維度 | JindoFS SDK | JindoFS Cache | JindoFS Block |
|---|---|---|---|
| 存儲成本 |
|
|
|
| 彈性 | 高 | 較高 | 支持 |
| 吞吐 | OSS帶寬。 | OSS帶寬和熱數據緩存帶寬。 | OSS帶寬、溫數據和熱數據緩存帶寬。 |
| 元數據 |
|
|
|
| 運維 | 低 | 一般
需要維護緩存系統能力。 |
較高
需要維護文件系統元數據服務和緩存系統。 |
| 安全 |
|
|
|
| 使用方式 | 僅支持oss://<oss_bucket>/<oss_dir>/方式,支持跨產品訪問該文件路徑。 |
說明 Cache模式使用詳情請參見各版本下JindoFS Cache模式的內容。
|
僅支持多Namespace使用方式jfs://<your_namespace>/<path_of_file>,不支持跨產品訪問該文件路徑,可以打開緩存開關。
說明 Block模式使用詳情請參見各版本下JindoFS Block模式的內容。
|
常見問題
- Q:針對典型的數據湖場景,建議采用什么模式?
A:因為JindoFS SDK和Cache模式完全兼容OSS對象存儲語義,具有完全的存儲分離架構和彈性靈活性,所以,針對典型的數據湖場景,推薦您使用SDK或者Cache模式以支持大數據分析和AI訓練加速。
- Q:為什么Block模式跟HDFS相比,是更好的HDFS?
A:
- HDFS的常規限制為4億,而Block模式元數據規模上支撐10億以上的文件數,大于HDFS的限制,而且在集群高峰期時性能更為穩定。
- HDFS有Java onheap限制,而Block模式沒有Java onheap和內存限制,可以支持更大的數據規模。
- Block模式輕運維,不用擔心壞盤或壞節點,數據1備份放置在OSS上,支持上下線節點。
- 支持對冷數據做透明壓縮和歸檔,使用多種手段進行成本優化,對接對象存儲,支持EB級數據規模。
- Block模式支持HDFS的一些重要特性。例如,HDFS AuditLog、Ranger集成和數據加密。
- Q:Block模式具有哪些特別的優勢?
A:
- Block模式可以管理文件元數據和組織文件數據,因此可以不局限于OSS對象存儲,完全可以滿足各種大數據引擎對存儲接口的需求。這些接口包括但不限于Rename的原子性和事務性能力、高性能本地寫入、透明壓縮、truncate、append、flush、sync和snapshot等。這些高階存儲接口對實現完整的POSIX和對接更多的大數據引擎到OSS是不可或缺的,例如,Flink、HBase、Kafka和Kudu。其他兩種方式使用OSS也可以對接部分接口,但是能力和優勢會有所不足。
- Block模式在費用上優于其他兩種方式使用OSS。Block模式中,因為全部數據中占比60%的溫數據和熱數據都在本地有緩存備份,大部分讀請求都不會通過OSS,所以可以節省一部分費用。