本文為您介紹如何在Data Science集群讀取MaxCompute的數據,進行EasyRec模型訓練。
前提條件
- 已創建DataScience集群,且選擇了EasyRec和TensorFlow服務,詳情請參見創建集群。
- 已創建MaxCompute項目,詳情請參見創建MaxCompute項目。
- 下載dsdemo代碼:請已創建DataScience集群的用戶,使用釘釘搜索釘釘群號32497587加入釘釘群以獲取dsdemo代碼。
操作步驟
- 連接容器服務。
- 登錄容器鏡像服務控制臺,創建企業版實例詳情,詳情請參見創建企業版實例。
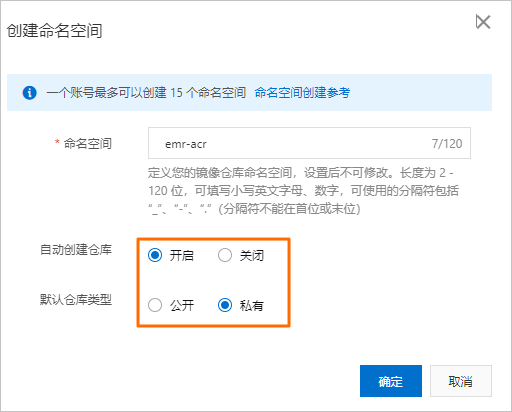
- 在頁面,創建命名空間。
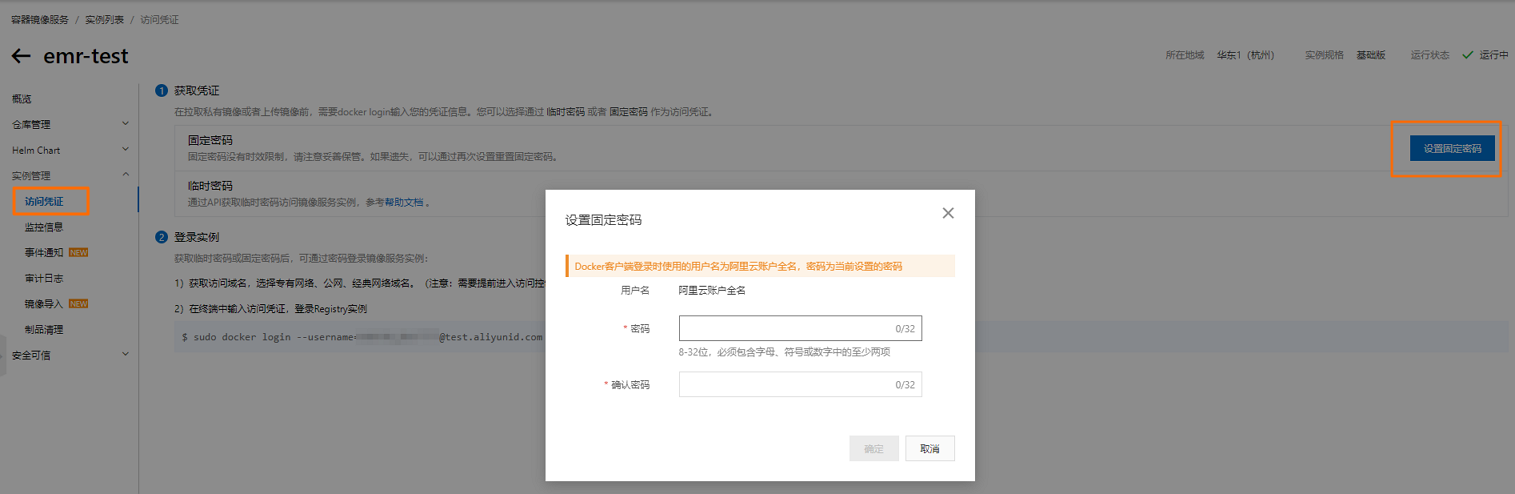
- 在頁面,設置固定密碼。
- 在DataScience集群的header節點,通過
docker login命令連接容器服務,詳情請參見docker login。
- 上傳dsdemo代碼至DataScience集群的header節點,并解壓縮。
- 通過SSH方式連接DataScience集群,詳情請參見登錄集群。
- 修改文件。
- 修改ml_on_ds/tools/下的odps_config.ini文件,添加訪問MaxCompute的AccessKey和Endpoint。
- 修改ml_on_ds目錄下的config文件,根據前面的容器服務路徑、命名空間和區域信息修改相應的配置。
- 修改模型的easyrec_model.config文件,將input_type的參數值修改為OdpsInputV3。
說明 OdpsInputV3是專門定制在DataScience集群讀取MaxCompute表的Class。
- 根據Python版本,選擇對應common_io。
- Python 2.7版本
pip install --user -U https://tfsmoke1.oss-cn-zhangjiakou.aliyuncs.com/tunnel_paiio/common_io/py2/common_io-0.1.0-cp27-cp27mu-linux_x86_64.whl
- Python 3.6版本
pip3 install --user -U http://tfsmoke1.cn-hangzhou.oss.aliyun-inc.com/tunnel_paiio/common_io/py3/common_io-0.3.0-cp36-cp36m-linux_x86_64.whl
- Python 3.7版本
pip3 install --user -U http://tfsmoke1.cn-hangzhou.oss.aliyun-inc.com/tunnel_paiio/common_io/py3/common_io-0.2.0-cp37-cp37m-linux_x86_64.whl
- 修改ml_on_ds目錄下的Dockerflie文件,添加以下信息。
請根據您Python版本,執行相應命令。
ADD ./common_io-0.3.0-cp36-cp36m-linux_x86_64.whl /tmp/
RUN pip3 install --user -U http://tfsmoke1.cn-hangzhou.oss.aliyun-inc.com/tunnel_paiio/common_io/py3/common_io-0.3.0-cp36-cp36m-linux_x86_64.whl -i http://mirrors.cloud.aliyuncs.com/pypi/simple --trusted-host mirrors.cloud.aliyuncs.com
COPY ./odps_config.ini /root/.odps_config.ini
- 執行以下命令,打包鏡像。
- 修改ml_on_ds目錄下的tfjob_easyrec_training.yaml的數據輸入。
- "--train_input_path"
- "odps://<pai_online_project>/tables/<easyrec_demo_taobao_train_data>"
- "--eval_input_path"
- "odps://<pai_online_project>/tables/<easyrec_demo_taobao_test_data>"
說明 <pai_online_project>需要替換為您創建的MaxCompute項目名。<easyrec_demo_taobao_train_data>和<easyrec_demo_taobao_test_data>需要替換為您創建的MaxCompute表名。
- 執行以下命令,進行模型訓練。
kubectl apply -f tfjob_easyrec_training.yaml