在EMR集群運(yùn)行TPC-DS Benchmark
TPC-DS是大數(shù)據(jù)領(lǐng)域最為知名的Benchmark標(biāo)準(zhǔn)。阿里云E-MapReduce多次刷新TPC-DS官方最好成績(jī),并且是第一個(gè)通過認(rèn)證的可運(yùn)行TPC-DS 100 TB的大數(shù)據(jù)系統(tǒng)。本文介紹如何在EMR集群完整運(yùn)行TPC-DS的99個(gè)SQL,并得到最佳的性能體驗(yàn)。
背景信息
TPC-DS是全球最知名的數(shù)據(jù)管理系統(tǒng)評(píng)測(cè)基準(zhǔn)標(biāo)準(zhǔn)化組織TPC(事務(wù)性管理委員會(huì))制定的標(biāo)準(zhǔn)規(guī)范,并由TPC管理測(cè)試結(jié)果的發(fā)布。TPC-DS官方工具只包含SQL生成器以及單機(jī)版數(shù)據(jù)生成工具,并不適合大數(shù)據(jù)場(chǎng)景,所以本文教程中使用的工具和集群信息如下:
- Hive TPC-DS Benchmark測(cè)試工具。
該工具是業(yè)界最常用的測(cè)試工具,是由Hortonworks公司開發(fā),支持使用Hive和Spark運(yùn)行TPC-DS以及TPC-H等Benchmark。
EMR集群版本為EMR-5.15.1。
Hive TPC-DS Benchmark測(cè)試工具是基于Hortonworks HDP 3版本開發(fā)的,對(duì)應(yīng)的Hive版本是3.1。本文教程使用的是EMR-5.15.1版本,EMR-4.8.0及之后的版本、EMR-5.1.0以及之后的版本均可運(yùn)行該教程。
使用限制
EMR-4.8.0及之后的版本、EMR-5.1.0以及之后的版本均可運(yùn)行該教程。
注意事項(xiàng)
本文示例使用的是DataLake集群,所以Master節(jié)點(diǎn)名稱為master-1-1。如果您使用的是Hadoop集群,請(qǐng)修改文檔中的節(jié)點(diǎn)名稱為emr-header-1。
步驟一:創(chuàng)建EMR集群和下載TPC-DS Benchmark工具
創(chuàng)建EMR-5.15.1集群,具體操作步驟,請(qǐng)參見創(chuàng)建集群。
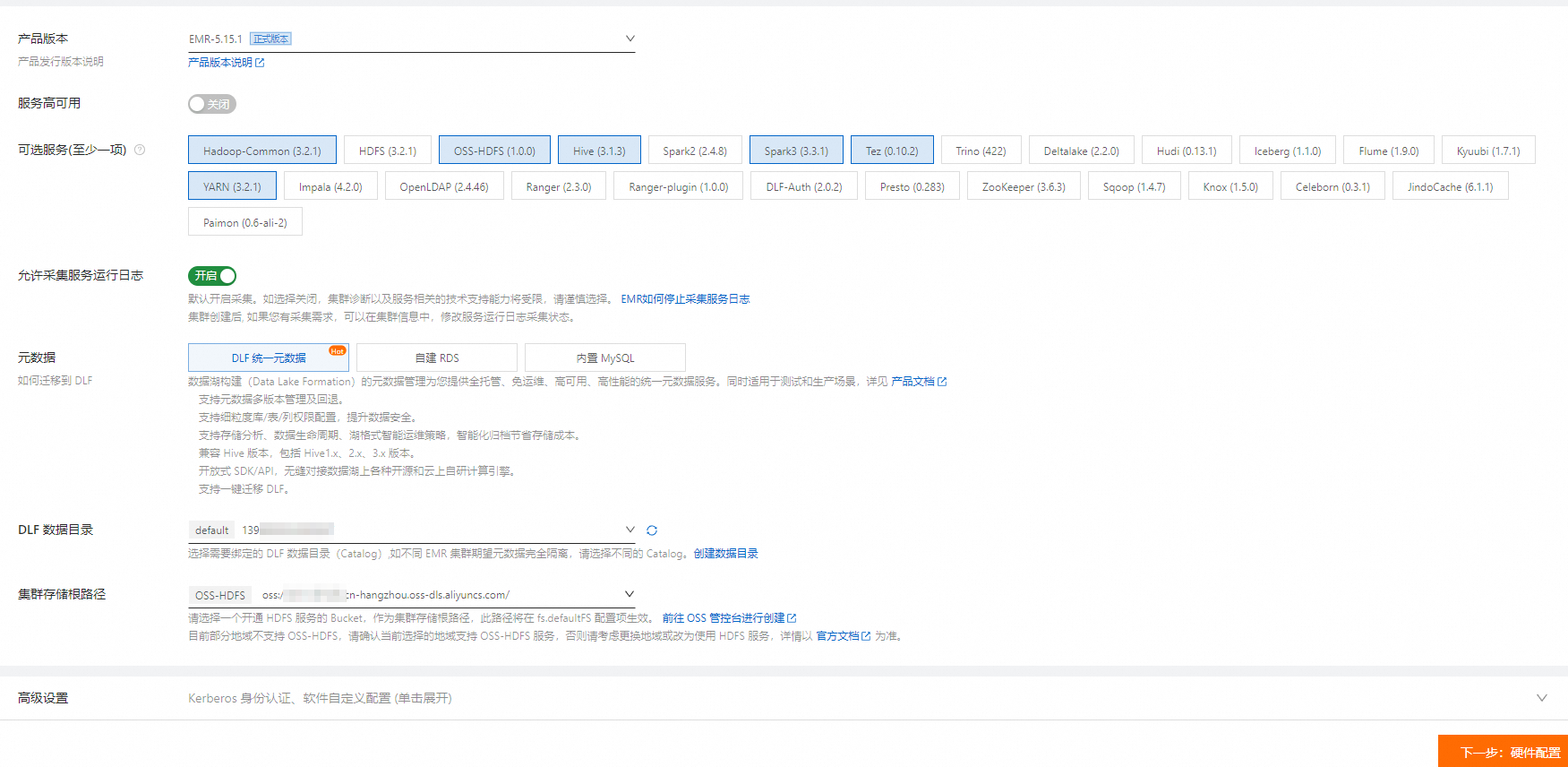
在創(chuàng)建集群時(shí),請(qǐng)關(guān)注如下配置信息:
集群類型:選擇DataLake。
產(chǎn)品版本:以EMR-5.15.1版本為例。
可選服務(wù):使用默認(rèn)配置。
實(shí)例規(guī)格:如果想獲得最佳性能,Core實(shí)例推薦使用大數(shù)據(jù)型或本地SSD。如果想用小規(guī)模數(shù)據(jù)快速完成所有流程,Core實(shí)例也可以選擇4 vCPU 16 GiB規(guī)格的通用型實(shí)例。
重要根據(jù)您選擇運(yùn)行的數(shù)據(jù)集確定集群規(guī)模,確保Core實(shí)例的數(shù)據(jù)盤總?cè)萘看笥跀?shù)據(jù)集規(guī)模的三倍。數(shù)據(jù)集相關(guān)信息,請(qǐng)參見步驟三:生成并加載數(shù)據(jù)。
元數(shù)據(jù):推薦使用DLF統(tǒng)一元數(shù)據(jù)。
集群存儲(chǔ)根路徑:選擇一個(gè)開通HDFS服務(wù)的Bucket。
如果您當(dāng)前的地域不支持OSS-HDFS,請(qǐng)考慮更換地域或改為使用HDFS服務(wù),即在可選服務(wù)中去掉OSS-HDFS服務(wù),選擇HDFS服務(wù)。

掛載公網(wǎng):在Master節(jié)點(diǎn)組中,打開掛載公網(wǎng)開關(guān)。
通過SSH方式連接集群的Master節(jié)點(diǎn),具體操作請(qǐng)參見登錄集群。
安裝Git和Maven。
執(zhí)行以下命令,安裝Git。
sudo yum install -y git在Apache Maven Project下載最新的Binary tar.gz archive。本文將以apache-maven-3.9.6-bin.tar.gz為例進(jìn)行說明。
上傳下載好的文件到EMR集群的Master節(jié)點(diǎn),并解壓縮。
tar zxf apache-maven-3.9.6-bin.tar.gz cd apache-maven-3.9.6 export MAVEN_HOME=`pwd` export PATH=`pwd`/bin:$PATH
下載TPC-DS Benchmark工具。
通過Git下載。
git clone https://github.com/hortonworks/hive-testbench.git重要在中國(guó)內(nèi)地訪問GitHub較慢,如果下載失敗,可直接本地下載,將ZIP文件上傳到EMR集群的Master節(jié)點(diǎn),并解壓縮。
本地下載,將ZIP文件上傳到EMR集群的Master節(jié)點(diǎn),并解壓縮。
具體操作步驟如下:
執(zhí)行以下命令,上傳ZIP文件到EMR集群的Master節(jié)點(diǎn)。
scp hive-testbench-hdp3.zip root@**.**.**.**:/root/說明**.**.**.**為Master節(jié)點(diǎn)的公網(wǎng)IP地址。您可以在集群的節(jié)點(diǎn)管理頁面,單擊Master節(jié)點(diǎn)組所在行的 圖標(biāo),獲取Master節(jié)點(diǎn)的公網(wǎng)IP地址。
圖標(biāo),獲取Master節(jié)點(diǎn)的公網(wǎng)IP地址。執(zhí)行以下命令,解壓縮ZIP文件。
unzip hive-testbench-hdp3.zip
步驟二:編譯并打包數(shù)據(jù)生成器
(可選)配置阿里云鏡像。
如果在中國(guó)內(nèi)地可以使用阿里云鏡像加速M(fèi)aven編譯。使用阿里云鏡像,編譯并打包數(shù)據(jù)生成器的耗時(shí)為2min~3min。
執(zhí)行如下命令,新建文件目錄。
mkdir -p ~/.m2/執(zhí)行如下命令,將Maven配置文件拷貝到新文件目錄下。
cp $MAVEN_HOME/conf/settings.xml ~/.m2/在~/.m2/settings.xml文件中添加鏡像信息,具體內(nèi)容如下:
<mirror> <id>aliyun</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror>
切換到hive-testbench-hdp3目錄。
cd hive-testbench-hdp3下載tpcds-extern.patch文件,上傳到當(dāng)前目錄下,然后復(fù)制到
tpcds-gen/patches/all/目錄中。重要EMR-5.10.0及后續(xù)版本使用Alibaba Cloud Linux (Alinux) 3,編譯過程需要額外的patch文件。而對(duì)于EMR-5.10.0之前的版本,編譯時(shí)不需要這個(gè)patch文件。
cp tpcds-extern.patch ./tpcds-gen/patches/all/使用TPC-DS工具集進(jìn)行編譯并打包數(shù)據(jù)生成器。
./tpcds-build.sh
步驟三:生成并加載數(shù)據(jù)
設(shè)置數(shù)據(jù)規(guī)模SF(Scale Factor)。
SF單位相當(dāng)于GB,所以SF=1相當(dāng)于1 GB,SF=100相當(dāng)于100 GB,SF=1000相當(dāng)于1 TB,以此類推。本步驟示例采用小規(guī)模數(shù)據(jù)集,推薦使用SF=3。具體命令如下:
SF=3重要請(qǐng)確保數(shù)據(jù)盤總大小是數(shù)據(jù)集規(guī)模的3倍以上,否則后續(xù)流程中會(huì)出現(xiàn)報(bào)錯(cuò)情況。
檢查并清理Hive數(shù)據(jù)庫(kù)。
檢查Hive數(shù)據(jù)庫(kù)是否存在。
hive -e "desc database tpcds_bin_partitioned_orc_$SF"(可選)清理已經(jīng)存在的Hive數(shù)據(jù)庫(kù)。
重要如果Hive數(shù)據(jù)庫(kù)tpcds_bin_partitioned_orc_$SF已經(jīng)存在,需要執(zhí)行下面的命令清理數(shù)據(jù)庫(kù),否則后續(xù)流程會(huì)報(bào)錯(cuò)。如果不存在,則跳過該步驟。
hive -e "drop database tpcds_bin_partitioned_orc_$SF cascade"
配置Hive服務(wù)地址。
tpcds-setup.sh腳本默認(rèn)配置的Hive服務(wù)地址與EMR集群環(huán)境不一致,所以需要將腳本中HiveSever的地址替換為EMR集群中的Hive服務(wù)地址。具體命令如下:
sed -i 's/localhost:2181\/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2?tez.queue.name=default/master-1-1:10000\//' tpcds-setup.sh腳本默認(rèn)配置的Hive服務(wù)地址為:
jdbc:hive2://localhost:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2?tez.queue.name=default。通過上述命令替換后的Hive服務(wù)地址為:jdbc:hive2://master-1-1:10000/。修復(fù)開源工具配置問題。
部分參數(shù)在Hive 2和Hive 3等開源版本中不支持,繼續(xù)使用TPC-DS會(huì)導(dǎo)致作業(yè)報(bào)錯(cuò),所以需要參考以下命令替換參數(shù)。
sed -i 's/hive.optimize.sort.dynamic.partition.threshold=0/hive.optimize.sort.dynamic.partition=true/' settings/*.sql生成并加載數(shù)據(jù)。
在SF=3時(shí),該步驟耗時(shí)為40min~50min。如果運(yùn)行正常,TPC-DS數(shù)據(jù)表將會(huì)加載到tpcds_bin_partitioned_orc_$SF數(shù)據(jù)庫(kù)中。通過EMR存儲(chǔ)和計(jì)算分離的架構(gòu)能力,可以很方便地做到將數(shù)據(jù)保存在OSS-HDFS。
執(zhí)行以下命令,生成并加載數(shù)據(jù)。
./tpcds-setup.sh $SF
獲取Hive表統(tǒng)計(jì)信息。
推薦使用Hive SQL ANALYZE命令獲取Hive表統(tǒng)計(jì)信息,可以加快后續(xù)SQL的查詢速度。此步驟在SF=3時(shí),耗時(shí)為20min~30min。
hive -f ./hive-testbench-hdp3/ddl-tpcds/bin_partitioned/analyze.sql \ --hiveconf hive.execution.engine=tez \ --database tpcds_bin_partitioned_orc_$SF
因?yàn)橥瑫r(shí)使用了數(shù)據(jù)湖構(gòu)建(DLF)來保存Hive表的元數(shù)據(jù),所以數(shù)據(jù)生成后,您可以隨時(shí)釋放當(dāng)前的EMR集群,并在同一地域的其他EMR集群上再次查詢當(dāng)前生成的TPC-DS數(shù)據(jù)集。
步驟四:運(yùn)行TPC-DS SQL
本步驟分別介紹如何使用Hive和Spark運(yùn)行TPC-DS SQL。
使用Hive運(yùn)行TPC-DS SQL
通過以下命令執(zhí)行單SQL。
TPC-DS SQL共有99個(gè)文件都放在sample-queries-tpcds工作目錄下(包括query10.sql和query11.sql等文件)。在SF=3時(shí),所有的SQL都可以在5min內(nèi)返回結(jié)果。
重要因?yàn)門PC-DS Query和數(shù)據(jù)都是隨機(jī)生成,所以部分SQL查詢返回結(jié)果數(shù)為0屬于正常現(xiàn)象。
cd sample-queries-tpcds hive --database tpcds_bin_partitioned_orc_$SF set hive.execution.engine=tez; source query10.sql;利用工具包中的腳本順序執(zhí)行99個(gè)完整SQL。具體命令如下:
cd ~/hive-testbench-hdp3 # 生成一個(gè)Hive配置文件,并指定Hive執(zhí)行引擎為Tez。 echo 'set hive.execution.engine=tez;' > sample-queries-tpcds/testbench.settings ./runSuite.pl tpcds $SF
使用Spark運(yùn)行TPC-DS SQL
TPC-DS工具集中包含Spark SQL用例,用例位于spark-queries-tpcds目錄下,可以使用spark-sql或者spark-beeline等命令行工具執(zhí)行這些SQL。本步驟以Spark Beeline工具連接Spark ThriftServer為例,介紹如何使用Spark運(yùn)行TPC-DS SQL來查詢步驟三:生成并加載數(shù)據(jù)生成的TPC-DS數(shù)據(jù)集。
EMR Spark支持HDFS和OSS等多種存儲(chǔ)介質(zhì)保存的數(shù)據(jù)表,也支持?jǐn)?shù)據(jù)湖構(gòu)建(DLF)元數(shù)據(jù)。
使用Spark Beeline ANALYZE命令獲得Hive表統(tǒng)計(jì)信息,加快后續(xù)SQL查詢速度。
cd ~/hive-testbench-hdp3 spark-beeline -u jdbc:hive2://master-1-1:10001/tpcds_bin_partitioned_orc_$SF \ -f ./ddl-tpcds/bin_partitioned/analyze.sql切換到Spark SQL用例所在的文件目錄。
cd spark-queries-tpcds/通過以下命令執(zhí)行單個(gè)SQL。
spark-beeline -u jdbc:hive2://master-1-1:10001/tpcds_bin_partitioned_orc_$SF -f q1.sql通過腳本順序執(zhí)行99個(gè)SQL。
TPC-DS工具集中沒有包含批量執(zhí)行Spark SQL的腳本,所以本步驟提供一個(gè)簡(jiǎn)單腳本供參考。
for q in `ls *.sql`; do spark-beeline -u jdbc:hive2://master-1-1:10001/tpcds_bin_partitioned_orc_$SF -f $q > $q.out done重要SQL列表中q30.sql文件存在列名c_last_review_date_sk錯(cuò)寫為c_last_review_date的情況,所以該SQL運(yùn)行失敗屬于正常現(xiàn)象。
通過腳本順序執(zhí)行99個(gè)Spark SQL的時(shí)候,如果出現(xiàn)報(bào)錯(cuò)情況,解決方案請(qǐng)參見常見問題。
常見問題
Q:通過腳本順序執(zhí)行99個(gè)Spark SQL的時(shí)候報(bào)錯(cuò),怎么解決?
A:Spark ThriftServer服務(wù)的默認(rèn)內(nèi)存不適合較大規(guī)模數(shù)據(jù)集測(cè)試,如果在測(cè)試過程中出現(xiàn)Spark SQL作業(yè)提交失敗,原因可能是Spark ThriftServer出現(xiàn)OutOfMemory異常。針對(duì)這種情況的解決方法為調(diào)整Spark服務(wù)配置spark_thrift_daemon_memory的值后重啟ThriftServer服務(wù)。具體操作步驟如下:
進(jìn)入Spark服務(wù)頁面。
在頂部菜單欄處,根據(jù)實(shí)際情況選擇地域和資源組。
單擊目標(biāo)集群操作列的集群服務(wù)。
在集群服務(wù)頁面,單擊Spark服務(wù)區(qū)域的配置。
調(diào)整服務(wù)配置spark_thrift_daemon_memory的值。
搜索參數(shù)spark_thrift_daemon_memory。
根據(jù)使用的數(shù)據(jù)集規(guī)模調(diào)整對(duì)應(yīng)的參數(shù)值。
您可以將默認(rèn)的值調(diào)大。
單擊保存。
在彈出的對(duì)話框中,輸入執(zhí)行原因,單擊保存。
重啟Spark。
在Spark服務(wù)頁面,選擇右上角的。
在彈出的對(duì)話框中,輸入執(zhí)行原因,單擊確定。
在確認(rèn)對(duì)話框中,單擊確定。