Spark是一個通用的大數據分析引擎,具有高性能、易用性和普遍性等特點。
架構
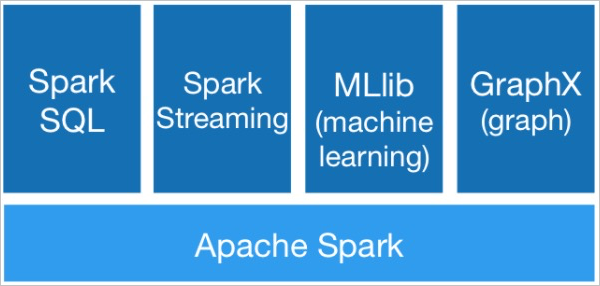
使用場景
離線ETL
離線ETL主要應用于數據倉庫,對大規模的數據進行抽取(Extract)、轉換(Transform)和加載(Load),其特點是數據量大,耗時較長,通常設置為定時任務執行。
在線數據分析(OLAP)
在線數據分析主要應用于BI(Business Intelligence)。分析人員交互式地提交查詢作業,Spark可以快速地返回結果。除了Spark,常見的OLAP引擎包括Presto和Impala等。Spark 3.0的主要特性在EMR中的Spark 2.4版本已支持,更多特性詳情請參見Spark SQL Guide。
流計算
流計算主要應用于實時大屏、實時風控、實時推薦和實時報警監控等。流計算主要包括Spark Streaming和Flink引擎,Spark Streaming提供DStream和Structured Streaming兩種接口,Structured Streaming和Dataframe用法類似,門檻較低。Flink適合低延遲場景,而Spark Streaming更適合高吞吐的場景,詳情請參見Structured Streaming Programming Guide。
機器學習
Spark的MLlib提供了較豐富的機器學習庫,包括分類、回歸、協同過濾、聚合,同時提供了模型選擇、自動調參和交叉驗證等工具來提高生產力。MLlib主要支持非深度學習的算法模塊,詳情請參見Machine Learning Library (MLlib) Guide。
圖計算
Spark的GraphX支持圖計算的庫,支持豐富的圖計算的算子,包括屬性算子、結構算子、Join算子和鄰居聚合等。詳情請參見GraphX Programming Guide。