EMR Notebook提供了全托管的兼容開源Jupyter的Notebook服務,同時內置了SQL Editor的功能。支持SparkSQL、Hive、StarRocks、PySpark等應用程序的開發和運行。本文以Hive查詢為例,為您介紹如何使用EMR Notebook。
前提條件
已完成系統角色授權,詳情請參見EMR Notebook角色授權。
已創建EMR on ECS形態下的集群,詳情請參見創建集群。
支持的集群類型為DataLake、Hadoop和自定義集群。本文以Hive類型為例,所以集群需要選擇Hive服務。
注意事項
代碼的運行環境由所屬用戶負責管理和配置。
步驟一:新建工作空間
在左側導航欄,選擇EMR Workbench > Notebook。
在工作空間頁面,單擊創建工作空間。
在彈出的對話框中,選擇地域,設置名稱、描述及網絡相關參數(專有網絡、交換機、安全組),單擊創建工作空間。
網絡配置相關信息,請參見管理網絡配置。
例如,新建地域為華東1(杭州),名稱為emr_notebook的工作空間。
說明工作空間創建成功后,系統會自動分配一臺配備2 vCPU和8 GiB內存的機器,您可以在運行Notebook作業時啟動并使用這臺機器。
步驟二:配置訪問信息
單擊上一步中已新建工作空間(emr_notebook)操作列的控制臺。
首次訪問E-MapReduce Notebook頁面時,您可以根據使用習慣選擇筆記本的模式。后續可以通過左上角
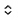 > 偏好設置進行調整。
> 偏好設置進行調整。Notebook傳統模式:可同時展開多個單元格,適用于原Jupyter用戶。
SQL專注模式:可放大SQL單元格,專注于SQL場景,適用于原Hue用戶。
在左側導航欄,單擊
 (數據庫)圖標。
(數據庫)圖標。單擊
 圖標。
圖標。在彈出的面板中,配置相關的參數。
更多類型介紹,請參見管理數據庫。
參數
說明
數據庫類型
選擇Hive。本文以Hive類型為例。
名稱
新建數據庫的名稱,長度限制為1~64個字符,只允許包含中文、字母、數字、空格、短劃線(-)和下劃線(_)。
本示例為demo_hive。
網絡類型
僅支持專有網絡類型。
專有網絡
默認展示工作空間配置的網絡參數,不支持修改。為了確保數據源能夠順利連接至工作空間,其專有網絡、安全組必須與當前展示的工作空間預設網絡配置完全一致。
安全組
地址
EMR集群部署了HiveServer2的節點的IP地址,通常為集群Master節點的IP地址。
端口
EMR集群中HiveServer2的端口信息,通常為hive.server2.thrift.port的參數值。
您可以在EMR控制臺Hive服務的配置頁面,查看hive.server2.thrift.port的參數值。
數據庫
待訪問的Hive數據庫名稱。
訪問方式
支持以下訪問方式:
LDAP:EMR集群中設置的用戶名和密碼,詳情請參見管理用戶。
免密登錄:僅需設置用戶名。
網絡檢測
單擊測試連通性,可以測試網絡連通性。
單擊添加數據庫。
步驟三:新建Notebook
在左側導航欄,單擊
 (文件瀏覽器)圖標。
(文件瀏覽器)圖標。單擊
 。
。在彈出的添加筆記本對話框中,輸入名稱,然后單擊確定。
步驟四:編輯并運行Notebook
在新建的筆記本中,單擊上方的SQL,新建一個單元格(Cell)。
本文以SQL語言為例。
在新建Cell的數據庫下拉列表中,選擇目標數據庫(本示例為demo_hive)。
輸入SQL語句。
本文示例如下。
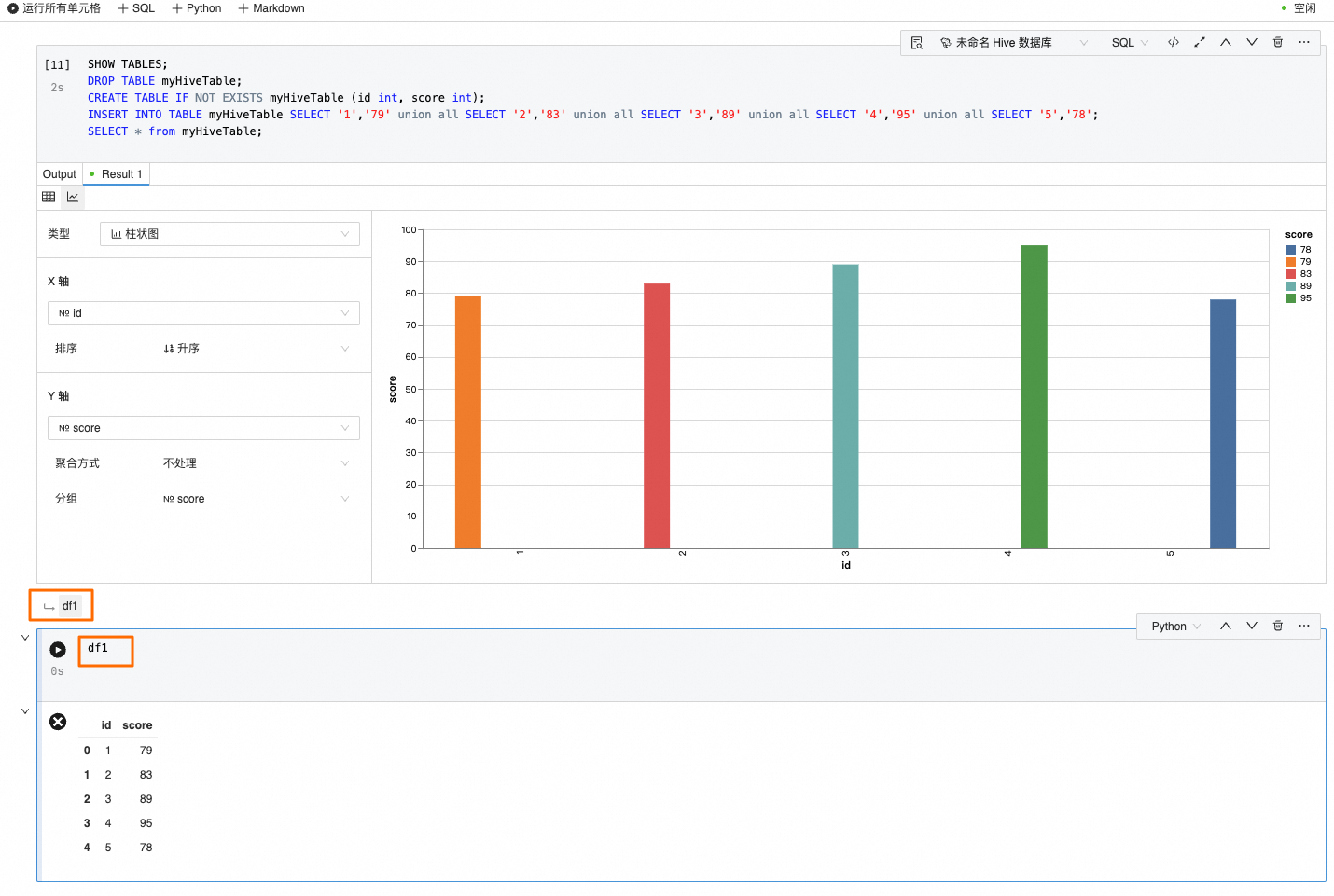
SHOW TABLES; DROP TABLE myHiveTable; CREATE TABLE IF NOT EXISTS myHiveTable (id int, score int); INSERT INTO TABLE myHiveTable SELECT '1','79' union all SELECT '2','83' union all SELECT '3','89' union all SELECT '4','95' union all SELECT '5','78'; SELECT * from myHiveTable;單擊
 按鈕,運行該Cell。
按鈕,運行該Cell。
步驟五:基于運行結果進行圖表分析
選擇步驟四中SELECT * from myHiveTable;的運行結果,單擊![]() 圖標切換至圖表分析模塊,根據需求選擇圖表類型及其他參數。
圖標切換至圖表分析模塊,根據需求選擇圖表類型及其他參數。
如圖所示,該圖為柱狀圖,其中:X軸為id,Y軸為score。
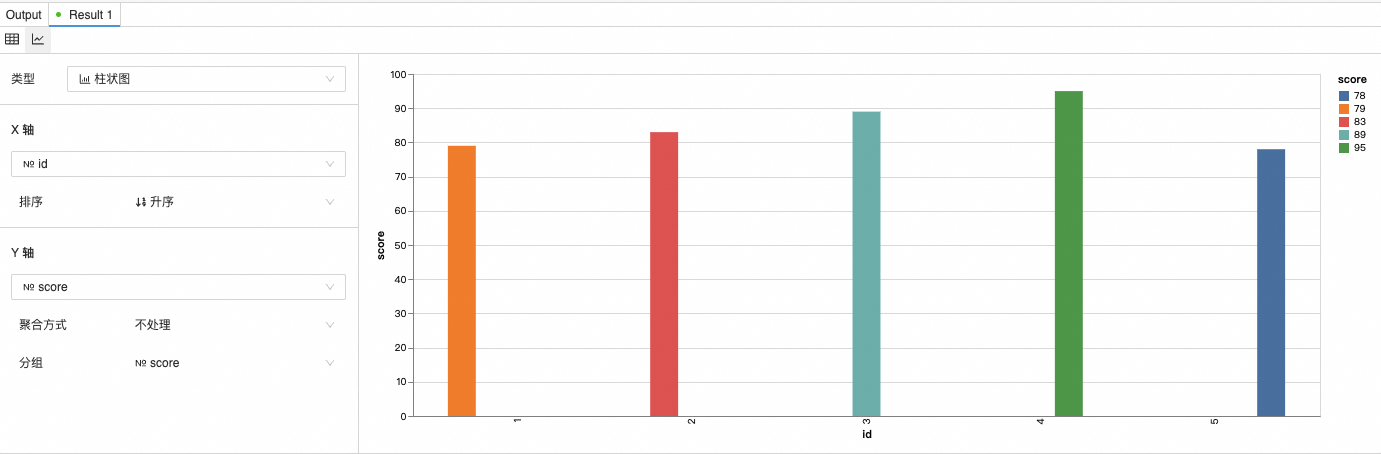
步驟六:在Notebook中引用單元格變量
在一個Notebook文件內,如果同時有SQL和Python語言的單元格,SQL單元格運行的結果,被標記為變量df4, 則該變量結果可以在同一個Notebook內被再次引用。