產(chǎn)品架構(gòu)
本文為您介紹EMR Serverless StarRocks的架構(gòu)。
EMR Serverless StarRocks架構(gòu)

EMR Serverless StarRocks的產(chǎn)品架構(gòu)主要由以下三個層次構(gòu)成:
存儲層:
存算一體版:StarRocks內(nèi)表使用云盤或本地盤作為數(shù)據(jù)存儲的介質(zhì),使用StarRocks Table Format存儲格式。
存算分離版:StarRocks內(nèi)表使用對象存儲或HDFS等數(shù)據(jù)湖存儲,使用StarRocks Table Format存儲格式。
數(shù)據(jù)湖分析版:通過StarRocks外部表,直接讀取數(shù)據(jù)湖(例如對象存儲或HDFS)中的Hive格式或湖格式的數(shù)據(jù),采用DataLake Table Format。
StarRocks實例:
全部實例(包括前端FE,后端BE或CN)都在云端托管,實現(xiàn)免運維。
通過計算組(Warehouse)可以進行資源靈活配置及隔離。
通過彈性能力可以確保低成本的資源使用,降低資源成本。
通過緩存機制能顯著提升存算分離或數(shù)據(jù)湖分析的查詢速度,同時,產(chǎn)品自帶的StarRocks緩存管理功能進一步助力您高效地進行緩存調(diào)優(yōu)。
產(chǎn)品能力:
實例運維:提供無需運維的實例管理功能,包括資源與配置管理、告警、健康報告和自動升級等,提升運維效率與系統(tǒng)穩(wěn)定性。
數(shù)據(jù)運維:提供即開即用的數(shù)據(jù)管理能力,例如可視化SQL編輯器、導(dǎo)入任務(wù)、慢查詢、數(shù)據(jù)審計、元數(shù)據(jù)管理以及權(quán)限配置等能力。
基于以上產(chǎn)品能力,您可以更加高效地聚焦于自己的業(yè)務(wù)應(yīng)用,例如運營分析、用戶畫像、自助報表、訂單分析以及用戶報表生成等方面。
StarRocks系統(tǒng)架構(gòu)
StarRocks架構(gòu)的核心只有FE(Frontend)、BE(Backend)或CN(Compute Node)節(jié)點,方便部署與維護。節(jié)點可以在線水平擴展,元數(shù)據(jù)和業(yè)務(wù)數(shù)據(jù)都有副本機制,確保整個系統(tǒng)無單點。StarRocks提供MySQL協(xié)議接口,支持標準的SQL語法,您可以通過MySQL客戶端方便地查詢和分析StarRocks中的數(shù)據(jù)。
隨著StarRocks產(chǎn)品的發(fā)展,系統(tǒng)架構(gòu)從存算一體(shared-nothing)進化到存算分離(shared-data)。
在3.0版本更新前,StarRocks采用存算一體架構(gòu),其中BE節(jié)點負擔(dān)著數(shù)據(jù)的存儲和計算任務(wù),所有數(shù)據(jù)訪問和分析操作都直接在本地節(jié)點完成,以確保快速響應(yīng)的查詢性能。
自3.0版本起,StarRocks開始采納存算分離架構(gòu),轉(zhuǎn)變了數(shù)據(jù)存儲的方式。原有的BE節(jié)點得到升級改造成為無狀態(tài)的計算節(jié)點(CN),并將數(shù)據(jù)持久化存儲遷移至遠端對象存儲服務(wù)或HDFS。在這一新架構(gòu)下,CN節(jié)點的本地磁盤主要用于緩存經(jīng)常訪問的熱數(shù)據(jù),進而提高查詢處理的速度。存算分離架構(gòu)的優(yōu)勢在于支持計算節(jié)點的動態(tài)添加或刪除,實現(xiàn)了更靈活高效的擴縮容功能。
如下圖所示,是從存算一體向存算分離架構(gòu)演進的形象展示。
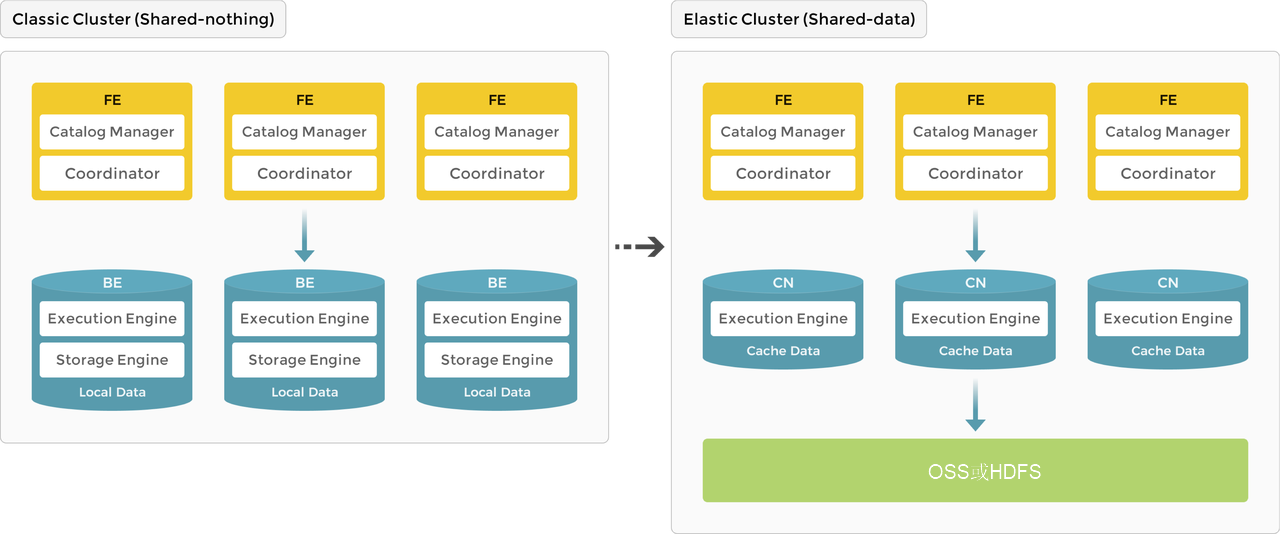
本文部分內(nèi)容和圖片來源于社區(qū)StarRocks的系統(tǒng)架構(gòu)。
存算一體
StarRocks 3.0版之前采用的是存算一體(shared-nothing)架構(gòu),這是其作為MPP數(shù)據(jù)庫的顯著特點。在這種架構(gòu)中,BE節(jié)點負責(zé)數(shù)據(jù)的存儲與計算。在查詢時可以直接讀取本地數(shù)據(jù)進行計算,極大地提升了查詢的速度,有效避免了數(shù)據(jù)傳輸和拷貝的延遲。此外,存算一體支持多副本數(shù)據(jù)存儲,提高了并發(fā)查詢能力和數(shù)據(jù)的可靠性,非常適合對查詢性能要求極高的場景。
在StarRocks的存算一體架構(gòu)中,系統(tǒng)主要由前端節(jié)點(FE)和后端節(jié)點(BE)兩種類型的節(jié)點構(gòu)成。
FE
FE負責(zé)管理元數(shù)據(jù)、管理客戶端連接、查詢規(guī)劃和調(diào)度等工作,并在每個節(jié)點的內(nèi)存中保存一份完整的元數(shù)據(jù)副本,以確保服務(wù)的一致性。
角色 | 元數(shù)據(jù)讀寫 | Leader選舉 | 說明 |
Leader | 讀寫 | 自動選舉 | Leader FE在對元數(shù)據(jù)進行讀寫操作后,通過BDB JE (Berkeley DB Java Edition) 同步變更至Follower和Observer。Leader由Follower節(jié)點中選舉產(chǎn)生,如果Leader失敗,其他Follower將進行新一輪選舉。 |
Follower | 只讀 | 參與 | Follower只有元數(shù)據(jù)的讀取權(quán)限,并通過Leader的元數(shù)據(jù)日志來異步同步數(shù)據(jù)。Follower節(jié)點也參與Leader的選舉,選舉過程基于BDB JE協(xié)議,并要求超過半數(shù)的Follower節(jié)點正常運行。 |
Observer | 只讀 | 不參與 | Observer節(jié)點與Follower具有相同的讀取權(quán)限,并進行異步數(shù)據(jù)同步,但不參與Leader選舉。Observer的主要目的是增強集群的查詢并發(fā)能力,并不給集群選舉帶來額外負擔(dān)。 |
BE
BE負責(zé)SQL計算和數(shù)據(jù)存儲的任務(wù),采用本地存儲和多副本機制以提高系統(tǒng)的可用性。
數(shù)據(jù)存儲: BE節(jié)點在存儲方面完全均等,沒有主次之分。數(shù)據(jù)由前端節(jié)點(FE)根據(jù)特定政策分配到各個BE節(jié)點,其中BE節(jié)點負責(zé)將接收的數(shù)據(jù)轉(zhuǎn)換成可存儲的格式并創(chuàng)建相應(yīng)的索引。
SQL計算: 對于SQL查詢的處理,BE節(jié)點首先將SQL語句按照語義規(guī)劃成邏輯執(zhí)行單元,然后再根據(jù)數(shù)據(jù)的分布情況拆分成具體的物理執(zhí)行單元。這些物理執(zhí)行單元直接在指定的BE節(jié)點上執(zhí)行,實現(xiàn)了數(shù)據(jù)計算的本地化,避免了不必要的數(shù)據(jù)傳輸和復(fù)制,從而極大的提升了查詢性能。
盡管存算一體架構(gòu)在查詢性能上具有顯著優(yōu)勢,但也存在一些局限性:
成本高:為了確保數(shù)據(jù)的可靠性,BE節(jié)點必須使用多副本,特別是三副本機制,這隨著數(shù)據(jù)量的增加會導(dǎo)致存儲資源的持續(xù)擴充,可能會造成計算資源的浪費。
架構(gòu)復(fù)雜:多副本的維護要求高一致性,這使得存算一體架構(gòu)變得更加復(fù)雜,提高了管理和維護的難度。
彈性不足:在存算一體模式下,擴縮容往往伴隨著數(shù)據(jù)重新平衡的過程,可能會影響彈性使用體驗。
存算分離
StarRocks存算分離架構(gòu)是在存算一體的基礎(chǔ)上將計算和存儲進行解耦。在這種模式中,數(shù)據(jù)持久化存儲轉(zhuǎn)移到了成本更優(yōu)化且可靠性更高的遠程對象存儲(例如OSS)或HDFS上。計算節(jié)點(CN)所在的本地磁盤主要用作緩存,以加速對高頻訪問數(shù)據(jù)的查詢。當本地緩存得到命中時,存算分離模式能夠提供與存算一體相當?shù)牟樵兯俣取?/p>
存算分離模式下,您可以動態(tài)地添加或移除計算節(jié)點,實現(xiàn)秒級別的擴縮容,有效降低了數(shù)據(jù)存儲與資源擴展的成本,并促進資源隔離及計算資源的彈性伸縮。此模式類似于存算一體,整個系統(tǒng)依舊由前端(FE)和計算節(jié)點(CN)兩種服務(wù)進程構(gòu)成,需要您額外配置的僅是后端的對象存儲。
在StarRocks存算分離架構(gòu)中,F(xiàn)E節(jié)點的角功能保持不變,而BE節(jié)點轉(zhuǎn)變?yōu)闊o狀態(tài)的CN節(jié)點,其僅緩存熱數(shù)據(jù),負責(zé)數(shù)據(jù)導(dǎo)入、查詢計算和緩存數(shù)據(jù)管理等任務(wù)。
存儲
StarRocks的存算分離技術(shù)目前支持以下后端存儲解決方案,您可以根據(jù)需求靈活選擇:
阿里云OSS對象存儲。
HDFS,包括自建Hadoop或阿里云EMR DataLake集群。
在數(shù)據(jù)格式方面,StarRocks存算分離的數(shù)據(jù)文件與存算一體保持一致,并支持各種索引技術(shù),其中元數(shù)據(jù)(例如TabletMeta)經(jīng)過重新設(shè)計以更好地適應(yīng)對象存儲環(huán)境。
緩存
為了優(yōu)化查詢性能,StarRocks構(gòu)建了層級分明的數(shù)據(jù)緩存體系。熱數(shù)據(jù)存放在內(nèi)存,確保快速可達;次熱數(shù)據(jù)則存放在本地磁盤;而冷數(shù)據(jù)則位于遠端的對象存儲中。數(shù)據(jù)會根據(jù)訪問頻率在這三個層次中流轉(zhuǎn)。
在查詢操作中,通常來說熱數(shù)據(jù)會直接從緩存中獲取,冷數(shù)據(jù)需要從后端對象存儲中讀取并緩存至本地,以便加快后序訪問速度。通過內(nèi)存、本地磁盤及遠程存儲的聯(lián)合,StarRocks構(gòu)建了多層數(shù)據(jù)訪問體系,您可以自定義數(shù)據(jù)冷熱規(guī)則以優(yōu)化業(yè)務(wù)需求,實現(xiàn)了高效計算與成本可控的存儲。
您在建立表時可以選擇是否開啟緩存。開啟緩存后,數(shù)據(jù)將在寫入過程中同時存放到本地磁盤以及后端對象存儲中。在查詢時,CN節(jié)點會優(yōu)先讀取本地磁盤中的數(shù)據(jù),若本地緩存未命中,則從后端對象存儲獲取原始數(shù)據(jù),并將其緩存至本地磁盤,以優(yōu)化后續(xù)的訪問速度。對于未緩存的冷數(shù)據(jù),StarRocks還針對性地進行了優(yōu)化,結(jié)合應(yīng)用的訪問模式,通過預(yù)讀技術(shù)和并行掃描等策略,降低了對遠端對象存儲訪問的頻率,進一步提升了查詢效率。