Spark是一種通用的大數據計算框架,擁有Hadoop MapReduce所具有的計算優點,能夠通過內存緩存數據為大型數據集提供快速的迭代功能。與MapReduce相比,減少了中間數據讀取磁盤的過程,進而提高了處理能力。本文介紹如何通過ES-Hadoop實現Hadoop的Spark服務讀寫阿里云Elasticsearch數據。
準備工作
創建阿里云Elasticsearch實例,并開啟自動創建索引功能。
具體操作步驟請參見創建阿里云Elasticsearch實例和配置YML參數。本文以6.7.0版本的實例為例。
重要在生產環境中,建議關閉自動創建索引功能,提前創建好索引和Mapping。由于本文僅用于測試,因此開啟了自動創建索引功能。
創建與Elasticsearch實例在同一專有網絡下的E-MapReduce(以下簡稱EMR)實例。
實例配置如下:
產品版本:EMR-3.29.0
必選服務:Spark(2.4.5),其他服務保持默認
具體操作步驟,請參見創建集群。
重要Elasticsearch實例的私網訪問白名單默認為0.0.0.0/0,您可在安全配置頁面查看,如果未使用默認配置,您還需要在白名單中加入EMR集群的內網IP地址:
請參見查看集群列表與詳情,獲取EMR集群的內網IP地址。
請參見配置實例公網或私網訪問白名單,配置Elasticsearch實例的VPC私網訪問白名單。
準備Java環境,要求JDK版本為8.0及以上。
編寫并運行Spark任務
準備測試數據。
登錄E-MapReduce控制臺,獲取Master節點的IP地址,并通過SSH登錄對應的ECS機器。
具體操作步驟,請參見登錄集群。
將測試數據寫入文件中。
本文使用的JSON數據示例如下,將該數據保存在http_log.txt文件中。
{"id": 1, "name": "zhangsan", "birth": "1990-01-01", "addr": "No.969, wenyixi Rd, yuhang, hangzhou"} {"id": 2, "name": "lisi", "birth": "1991-01-01", "addr": "No.556, xixi Rd, xihu, hangzhou"} {"id": 3, "name": "wangwu", "birth": "1992-01-01", "addr": "No.699 wangshang Rd, binjiang, hangzhou"}執行以下命令,將測試數據上傳至EMR Master節點的tmp/hadoop-es文件中。
hadoop fs -put http_log.txt /tmp/hadoop-es
配置pom依賴。
創建Java Maven工程,并將如下的pom依賴添加到Java工程的pom.xml文件中。
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>2.4.5</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.4.5</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch-spark-20_2.11</artifactId> <version>6.7.0</version> </dependency> </dependencies>重要請確保pom依賴中版本與云服務對應版本保持一致,例如elasticsearch-spark-20_2.11版本與阿里云Elasticsearch版本一致;spark-core_2.12與HDFS版本一致。
編寫示例代碼。
寫數據
以下示例代碼用來將測試數據寫入Elasticsearch的company索引中。
import java.util.Map; import java.util.concurrent.atomic.AtomicInteger; import org.apache.spark.SparkConf; import org.apache.spark.SparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.elasticsearch.spark.rdd.api.java.JavaEsSpark; import org.spark_project.guava.collect.ImmutableMap; public class SparkWriteEs { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setAppName("Es-write"); conf.set("es.nodes", "es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com"); conf.set("es.net.http.auth.user", "elastic"); conf.set("es.net.http.auth.pass", "xxxxxx"); conf.set("es.nodes.wan.only", "true"); conf.set("es.nodes.discovery","false"); conf.set("es.input.use.sliced.partitions","false"); SparkSession ss = new SparkSession(new SparkContext(conf)); final AtomicInteger employeesNo = new AtomicInteger(0); //以下的/tmp/hadoop-es/http_log.txt需要替換為您測試數據的路徑。 JavaRDD<Map<Object, ?>> javaRDD = ss.read().text("/tmp/hadoop-es/http_log.txt") .javaRDD().map((Function<Row, Map<Object, ?>>) row -> ImmutableMap.of("employees" employeesNo.getAndAdd(1), row.mkString())); JavaEsSpark.saveToEs(javaRDD, "company/_doc"); } }讀數據
以下示例代碼用來讀取上一步寫入Elasticsearch的數據,并進行打印。
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaSparkContext; import org.elasticsearch.spark.rdd.api.java.JavaEsSpark; import java.util.Map; public class ReadES { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("readEs").setMaster("local[*]") .set("es.nodes", "es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com") .set("es.port", "9200") .set("es.net.http.auth.user", "elastic") .set("es.net.http.auth.pass", "xxxxxx") .set("es.nodes.wan.only", "true") .set("es.nodes.discovery","false") .set("es.input.use.sliced.partitions","false") .set("es.resource", "company/_doc") .set("es.scroll.size","500"); JavaSparkContext sc = new JavaSparkContext(conf); JavaPairRDD<String, Map<String, Object>> rdd = JavaEsSpark.esRDD(sc); for ( Map<String, Object> item : rdd.values().collect()) { System.out.println(item); } sc.stop(); } }
表 1. 參數說明 參數
默認值
說明
es.nodes
localhost
指定阿里云Elasticsearch實例的訪問地址,建議使用私網地址,可在實例的基本信息頁面查看。更多信息,請參見查看實例的基本信息。
es.port
9200
Elasticsearch實例的訪問端口號。
es.net.http.auth.user
elastic
Elasticsearch實例的訪問用戶名。
說明如果程序中指定elastic賬號訪問Elasticsearch服務,后續在修改elastic賬號對應密碼后需要一些時間來生效,在密碼生效期間會影響服務訪問,因此不建議通過elastic來訪問。建議在Kibana控制臺中創建一個符合預期的Role角色用戶進行訪問,詳情請參見通過Elasticsearch X-Pack角色管理實現用戶權限管控。
es.net.http.auth.pass
/
對應用戶的密碼,在創建實例時指定。如果忘記可進行重置,具體操作步驟,請參見重置實例訪問密碼。
es.nodes.wan.only
false
開啟Elasticsearch集群在云上使用虛擬IP進行連接,是否進行節點嗅探:
true:設置
false:不設置
es.nodes.discovery
true
是否禁用節點發現:
true:禁用
false:不禁用
重要使用阿里云Elasticsearch,必須將此參數設置為false。
es.input.use.sliced.partitions
true
是否使用slice分區:
true:使用。設置為true,可能會導致索引在預讀階段的時間明顯變長,有時會遠遠超出查詢數據所耗費的時間。建議設置為false,以提高查詢效率。
false:不使用。
es.index.auto.create
true
通過Hadoop組件向Elasticsearch集群寫入數據,是否自動創建不存在的index:
true:自動創建
false:不會自動創建
es.resource
/
指定要讀寫的index和type。
es.mapping.names
/
表字段與Elasticsearch的索引字段名映射。
更多的ES-Hadoop配置項說明,請參見官方配置說明。
將代碼打成Jar包,上傳至EMR客戶端機器(例如Gateway或EMR集群主節點)。
在EMR客戶端機器上,運行如下命令執行Spark程序:
寫數據
cd /usr/lib/spark-current ./bin/spark-submit --master yarn --executor-cores 1 --class "SparkWriteEs" /usr/local/spark_es.jar重要/usr/local/spark_es.jar需要替換為您Jar包上傳的路徑。
讀數據
cd /usr/lib/spark-current ./bin/spark-submit --master yarn --executor-cores 1 --class "ReadES" /usr/local/spark_es.jar讀數據成功后,打印結果如下。
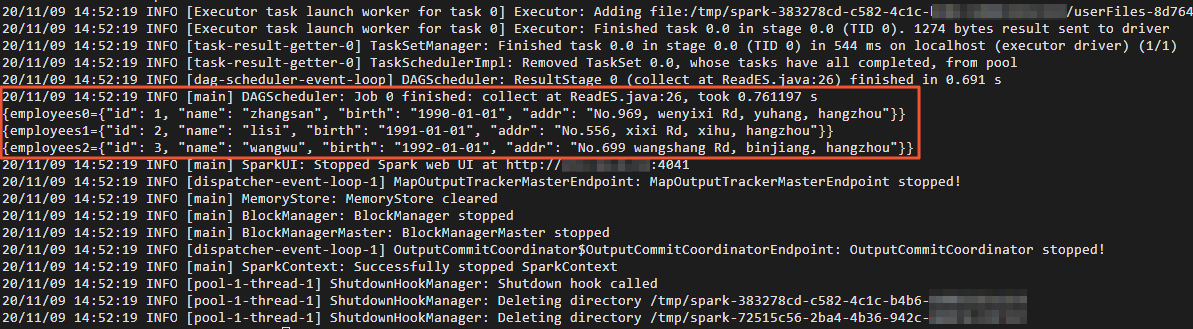
驗證結果
登錄對應阿里云Elasticsearch實例的Kibana控制臺。
具體操作步驟請參見登錄Kibana控制臺。
在左側導航欄,單擊Dev Tools。
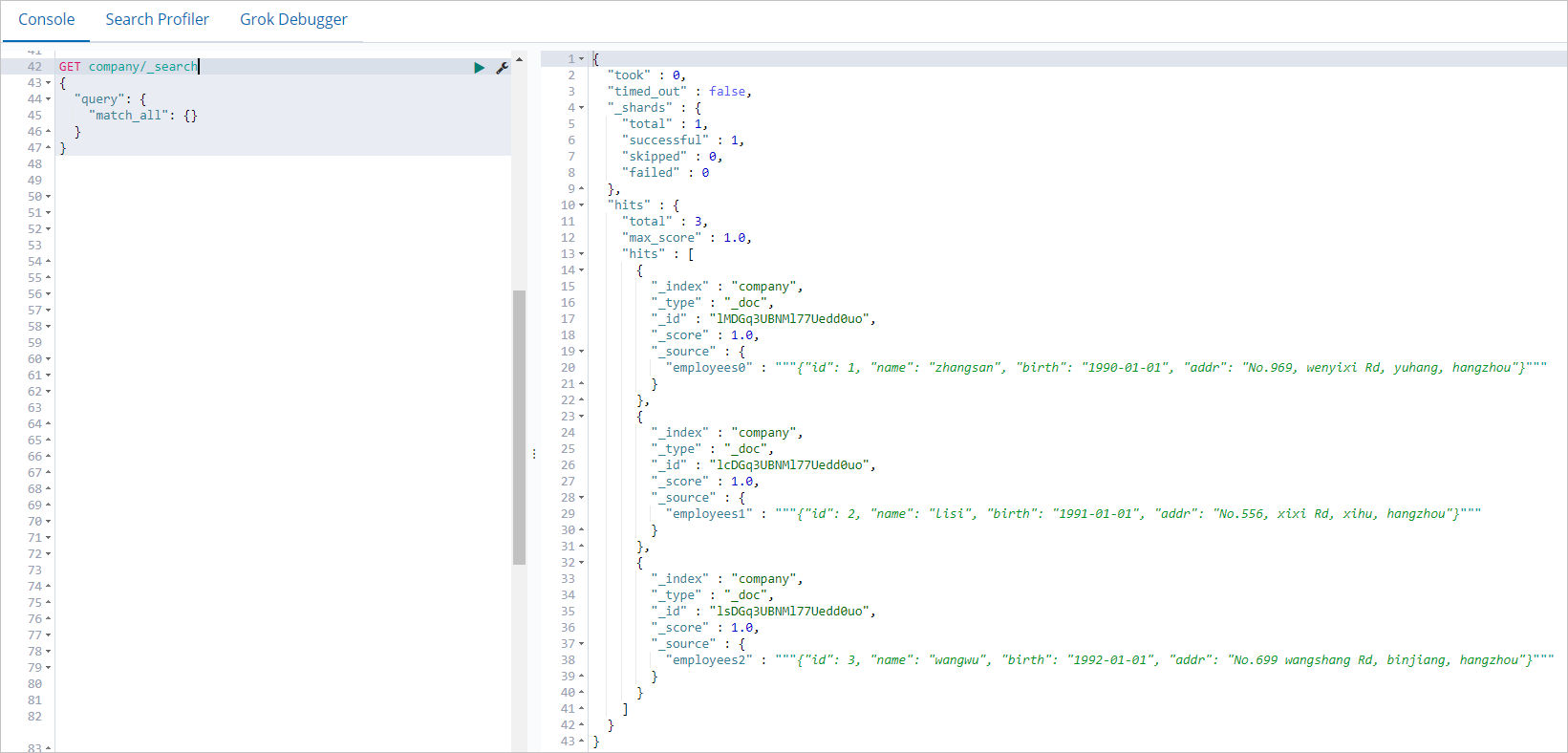
在Console中,執行以下命令,查看通過Spark任務寫入的數據。
GET company/_search { "query": { "match_all": {} } }查詢成功后,返回結果如下。
總結
本文以阿里云Elasticsearch和EMR為例,介紹了如何通過ES-Hadoop,實現Spark讀寫阿里云Elasticsearch數據。與其他EMR組件相比,ES-Hadoop與Spark的集成,不僅包括RDD,還包括Spark Streaming、scale、DataSet與Spark SQL等,您可以根據需求進行配置。詳細信息,請參見Apache Spark support。