本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
隨著時間的積累,日志數據會越來越多,當您需要查看并分析龐雜的日志數據時,可通過Filebeat+Kafka+Logstash+Elasticsearch采集日志數據到阿里云Elasticsearch中,并通過Kibana進行可視化展示與分析。本文介紹具體的實現方法。
背景信息
Kafka是一種分布式、高吞吐、可擴展的消息隊列服務,廣泛用于日志收集、監控數據聚合、流式數據處理、在線和離線分析等大數據領域,已成為大數據生態中不可或缺的部分。更多信息,請參見什么是云消息隊列 Kafka 版。
在實際應用場景中,為了滿足大數據實時檢索的需求,您可以使用Filebeat采集日志數據,并輸出到Kafka中。Kafka實時接收Filebeat采集的數據,并輸出到Logstash中。輸出到Logstash中的數據在格式或內容上可能不能滿足您的需求,此時可以通過Logstash的filter插件過濾數據。最后將滿足需求的數據輸出到Elasticsearch中進行分布式檢索,并通過Kibana進行數據分析與展示。簡單流程如下。
操作流程
完成環境準備,包括創建阿里云Elasticsearch、Logstash、ECS和
云消息隊列 Kafka 版實例、創建Topic和Consumer Group等。
重要建議您使用同一專有網絡VPC(Virtual Private Cloud)下的阿里云Elasticsearch、Logstash、ECS和
云消息隊列 Kafka 版實例。
安裝并配置Filebeat,設置input為系統日志,output為Kafka,將日志數據采集到Kafka的指定Topic中。
配置Logstash管道的input為Kafka,output為阿里云Elasticsearch,使用Logstash消費Topic中的數據并傳輸到阿里云Elasticsearch中。
在消息隊列Kafka中查看日志數據的消費的狀態,驗證日志數據是否采集成功。
在Kibana控制臺的Discover頁面,通過Filter過濾出Kafka相關的日志。
準備工作
創建阿里云Elasticsearch實例,并開啟實例的自動創建索引功能。
具體操作步驟請參見創建阿里云Elasticsearch實例和配置YML參數。本文以6.7版本為例。
創建阿里云Logstash實例。
具體操作步驟請參見創建阿里云Logstash實例。創建的實例需要滿足:
版本:與阿里云Elasticsearch實例的版本要滿足兼容性要求,詳細信息請參見產品兼容性。本文使用與Elasticsearch相同的版本,即6.7版本。
網絡:與阿里云Elasticsearch實例在同一VPC下,否則需要配置NAT網關實現與公網的連通,詳細信息請參見配置NAT公網數據傳輸。
購買并部署阿里云
云消息隊列 Kafka 版實例、創建Topic和Consumer Group。
創建阿里云ECS實例。
具體操作步驟請參見自定義購買實例。本文的ECS實例與阿里云Elasticsearch實例在同一VPC下,否則需要配置公網訪問白名單實現網絡互通,詳細信息請參見配置實例公網或私網訪問白名單。
重要該ECS實例用來安裝Filebeat,由于Filebeat目前僅支持Alibaba Cloud Linux (Alinux)、RedHat和CentOS這三種操作系統,因此在創建時請選擇其中一種操作系統。
步驟一:安裝并配置Filebeat
連接ECS服務器。
具體操作步驟請參見連接實例。
安裝Filebeat。
本文以6.8.5版本為例,安裝命令如下,詳細信息請參見Install Filebeat。
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.8.5-linux-x86_64.tar.gz tar xzvf filebeat-6.8.5-linux-x86_64.tar.gz執行以下命令,進入Filebeat安裝目錄,創建并配置filebeat.kafka.yml文件。
cd filebeat-6.8.5-linux-x86_64 vi filebeat.kafka.ymlfilebeat.kafka.yml配置如下。
filebeat.prospectors: - type: log enabled: true paths: - /var/log/*.log output.kafka: hosts: ["alikafka-post-cn-zvp2n4v7****-1-vpc.alikafka.aliyuncs.com:9092"] topic: estest version: 0.10.2重要當Filebeat為7.0及以上版本時,filebeat.prospectors需要替換為filebeat.inputs。
參數
說明
type
輸入類型。設置為log,表示輸入源為日志。
enabled
設置配置是否生效:
true:生效
false:不生效
paths
需要監控的日志文件的路徑。多個日志可在當前路徑下另起一行寫入日志文件路徑。
hosts
消息隊列Kafka實例的單個接入點,可在實例詳情頁面獲取,詳情請參見查看接入點。由于本文使用的是VPC實例,因此使用默認接入點中的任意一個接入點。
topic
日志輸出到消息隊列Kafka的Topic,請指定為您已創建的Topic。
version
Kafka的版本,可在消息隊列Kafka的實例詳情頁面獲取。
重要不配置此參數會報錯。
由于不同版本的Filebeat支持的Kafka版本不同,例如8.2及以上版本的Filebeat支持的Kafka版本為2.2.0,因此version需要設置為Filebeat支持的Kafka版本,否則會出現類似報錯:
Exiting: error initializing publisher: unknown/unsupported kafka version '2.2.0' accessing 'output.kafka.version' (source:'filebeat.kafka.yml'),詳細信息請參見version。
啟動Filebeat。
./filebeat -e -c filebeat.kafka.yml
步驟二:配置Logstash管道
- 進入阿里云Elasticsearch控制臺的Logstash頁面。
- 進入目標實例。
- 在頂部菜單欄處,選擇地域。
- 在Logstash實例中單擊目標實例ID。
在左側導航欄,單擊管道管理。
單擊創建管道。
在創建管道任務頁面,輸入管道ID并配置管道。
本文使用的管道配置如下。
input { kafka { bootstrap_servers => ["alikafka-post-cn-zvp2n4v7****-1-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-2-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-3-vpc.alikafka.aliyuncs.com:9092"] group_id => "es-test" topics => ["estest"] codec => json } } filter { } output { elasticsearch { hosts => "http://es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com:9200" user =>"elastic" password =>"<your_password>" index => "kafka‐%{+YYYY.MM.dd}" } }表 1. input參數說明
參數
說明
bootstrap_servers
消息隊列Kafka實例的接入點,可在實例詳情頁面獲取,詳情請參見查看接入點。由于本文使用的是VPC實例,因此使用默認接入點。
group_id
指定為您已創建的Consumer Group的名稱。
topics
指定為您已創建的Topic的名稱,需要與Filebeat中配置的Topic名稱保持一致。
codec
設置為json,表示解析JSON格式的字段,便于在Kibana中分析。
表 2. output參數說明
參數
說明
hosts
阿里云Elasticsearch的訪問地址,取值為
http://<阿里云Elasticsearch實例的私網地址>:9200。說明您可在阿里云Elasticsearch實例的基本信息頁面獲取其私網地址,詳情請參見查看實例的基本信息。
user
訪問阿里云Elasticsearch的用戶名,默認為elastic。您也可以使用自建用戶,詳情請參見通過Elasticsearch X-Pack角色管理實現用戶權限管控。
password
訪問阿里云Elasticsearch的密碼,在創建實例時設置。如果忘記密碼,可進行重置,重置密碼的注意事項及操作步驟請參見重置實例訪問密碼。
index
索引名稱。設置為
kafka‐%{+YYYY.MM.dd}表示索引名稱以kafka為前綴,以日期為后綴,例如kafka-2020.05.27。更多Config配置詳情請參見Logstash配置文件說明。
如果您有多topic的數據同步需求,需要在kafka中添加新的topic,然后在Logstash的管道配置中添加input。示例如下:
input { kafka { bootstrap_servers => ["alikafka-post-cn-zvp2n4v7****-1-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-2-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-3-vpc.alikafka.aliyuncs.com:9092"] group_id => "es-test" topics => ["estest"] codec => json } kafka { bootstrap_servers => ["alikafka-post-cn-zvp2n4v7****-1-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-2-vpc.alikafka.aliyuncs.com:9092,alikafka-post-cn-zvp2n4v7****-3-vpc.alikafka.aliyuncs.com:9092"] group_id => "es-test-2" topics => ["estest_2"] codec => json } }單擊下一步,配置管道參數。
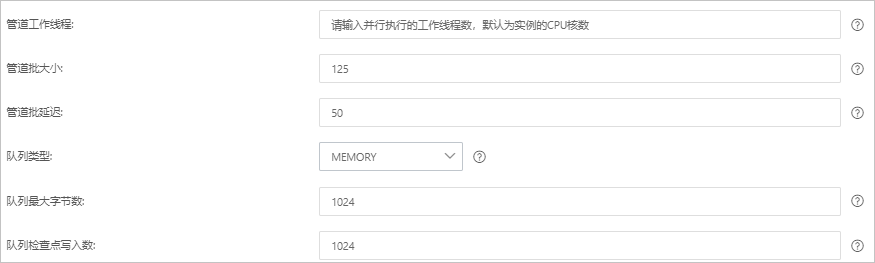
參數
說明
管道工作線程
并行執行管道的Filter和Output的工作線程數量。當事件出現積壓或CPU未飽和時,請考慮增大線程數,更好地使用CPU處理能力。默認值:實例的CPU核數。
管道批大小
單個工作線程在嘗試執行Filter和Output前,可以從Input收集的最大事件數目。較大的管道批大小可能會帶來較大的內存開銷。您可以設置LS_HEAP_SIZE變量,來增大JVM堆大小,從而有效使用該值。默認值:125。
管道批延遲
創建管道事件批時,將過小的批分派給管道工作線程之前,要等候每個事件的時長,單位為毫秒。默認值:50ms。
隊列類型
用于事件緩沖的內部排隊模型。可選值:
MEMORY:默認值。基于內存的傳統隊列。
PERSISTED:基于磁盤的ACKed隊列(持久隊列)。
隊列最大字節數
請確保該值小于您的磁盤總容量。默認值:1024 MB。
隊列檢查點寫入數
啟用持久性隊列時,在強制執行檢查點之前已寫入事件的最大數目。設置為0,表示無限制。默認值:1024。
警告配置完成后,需要保存并部署才能生效。保存并部署操作會觸發實例重啟,請在不影響業務的前提下,繼續執行以下步驟。
單擊保存或者保存并部署。
保存:將管道信息保存在Logstash里并觸發實例變更,配置不會生效。保存后,系統會返回管道管理頁面。可在管道列表區域,單擊操作列下的立即部署,觸發實例重啟,使配置生效。
保存并部署:保存并且部署后,會觸發實例重啟,使配置生效。
步驟三:查看日志消費狀態
進入消息隊列Kafka控制臺。
參見查看消費狀態,查看詳細消費狀態。
預期結果如下:

步驟四:通過Kibana過濾日志數據
- 登錄目標阿里云Elasticsearch實例的Kibana控制臺,根據頁面提示進入Kibana主頁。登錄Kibana控制臺的具體操作,請參見登錄Kibana控制臺。說明 本文以阿里云Elasticsearch 6.7.0版本為例,其他版本操作可能略有差別,請以實際界面為準。
創建一個索引模式。
在左側導航欄,單擊Management。
在Kibana區域,單擊Index Patterns。
單擊Create index pattern。
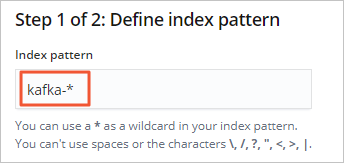
輸入Index pattern(本文使用kafka-*),單擊Next step。
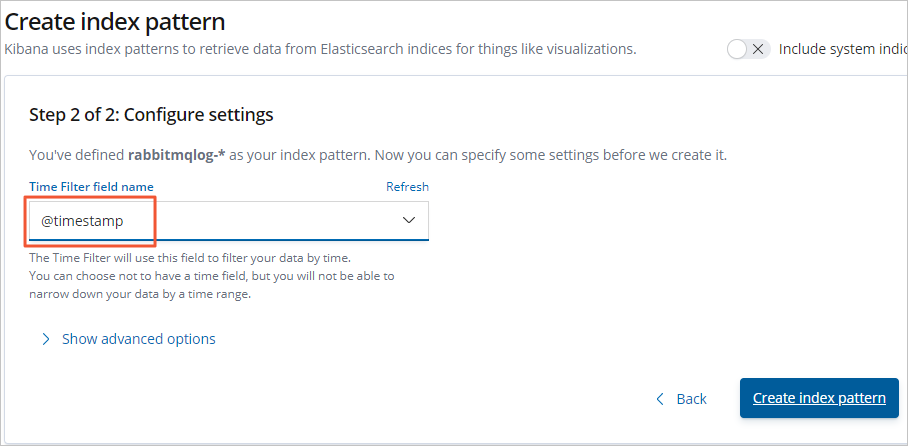
選擇Time Filter field name(本文選擇@timestamp),單擊Create index pattern。
在左側導航欄,單擊Discover。
從頁面左側的下拉列表中,選擇您已創建的索引模式(kafka-*)。
在頁面右上角,選擇一段時間,查看對應時間段內的Filebeat采集的日志數據。
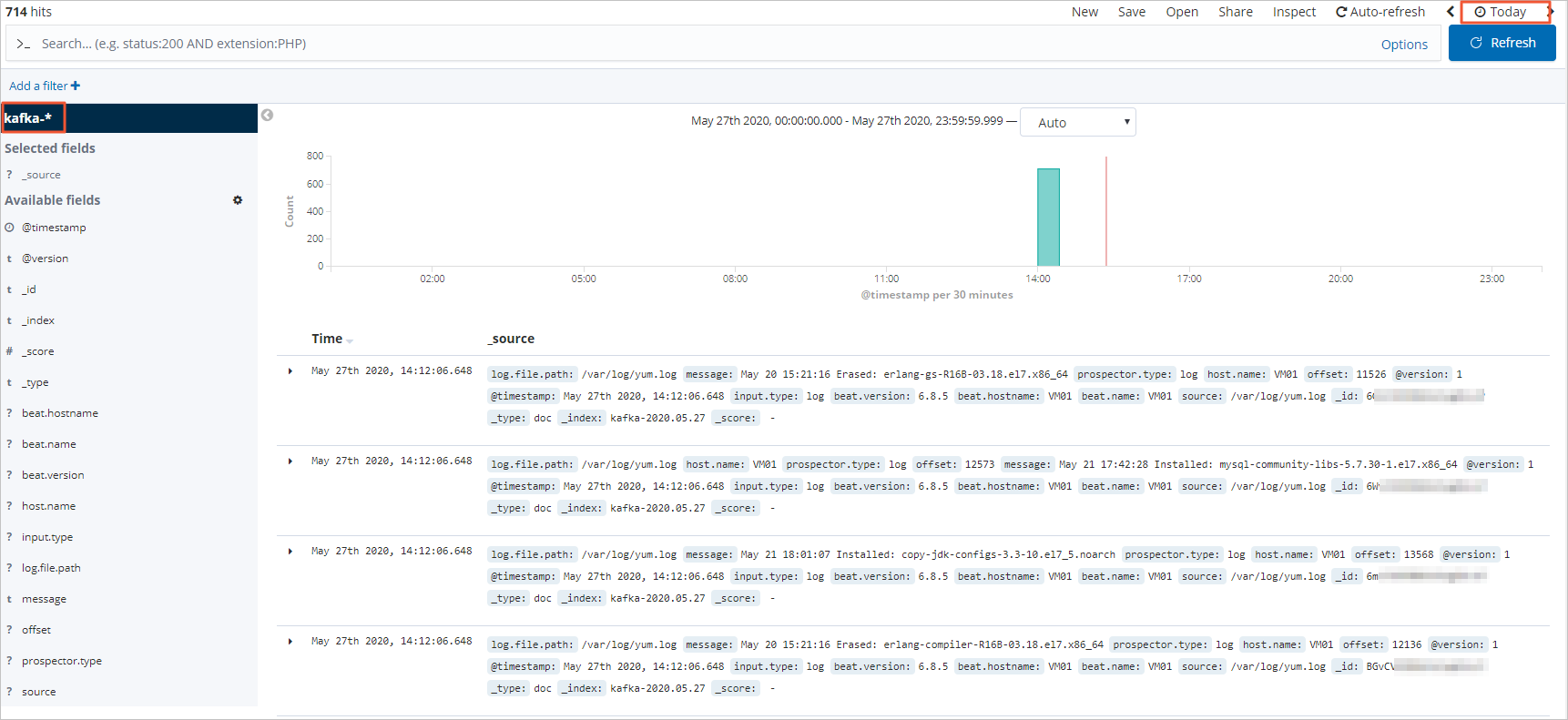
單擊Add a filter,在Add filter頁面中設置過濾條件,查看符合對應過濾條件的日志數據。
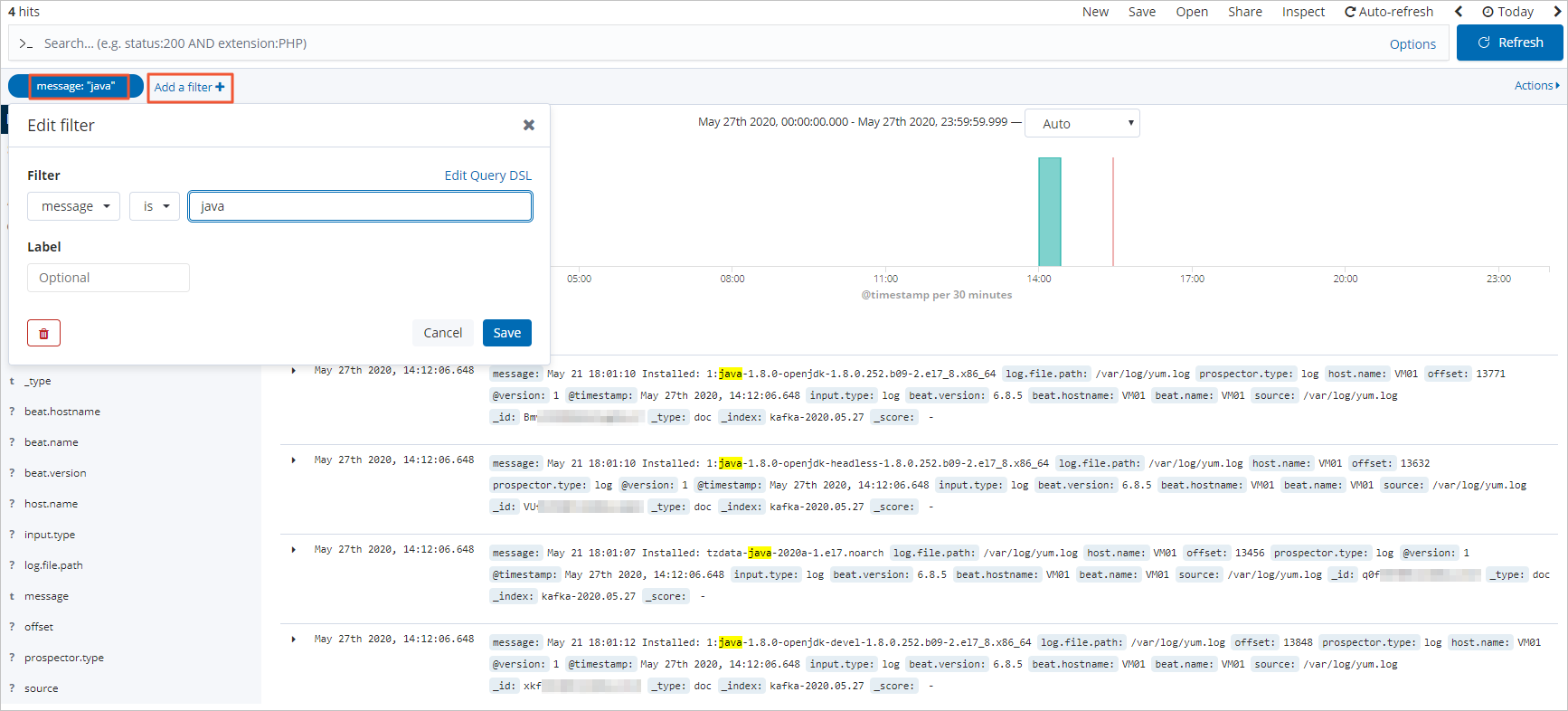
常見問題
Q:同步日志數據出現問題,管道一直在生效中,無法將數據導入Elasticsearch,如何解決?
A:查看Logstash實例的主日志是否有報錯,根據報錯判斷原因,具體操作請參見查詢日志。常見的原因及解決方法如下。
原因 | 解決方法 |
Kafka的接入點不正確。 | 參見查看接入點獲取正確的接入點。完成后,修改管道配置替換錯誤接入點。 |
Logstash與Kafka不在同一VPC下。 | 重新購買同一VPC下的實例。購買后,修改現有管道配置。 說明 VPC實例只能通過專有網絡VPC訪問 云消息隊列 Kafka 版。 |
Kafka或Logstash集群的配置太低,例如使用了測試版集群。 | 升級集群規格,完成后,刷新實例,觀察變更進度。升級Logstash實例規格的具體操作,請參見升配集群;升級Kafka實例規格的具體操作,請參見升級實例配置。 |
管道配置中包含了file_extend,但沒有安裝logstash-output-file_extend插件。 | 選擇以下任意一種方式處理:
|
更多問題原因及解決方法,請參見Logstash數據寫入問題排查方案。