本文介紹如何創建Debezium PostgreSQL Source Connector,將PostgreSQL的數據同步至云消息隊列 Kafka 版。
使用限制
Debezium PostgreSQL Source Connector只能配置一個Task用于消費源端的CDC數據,不支持并發消費配置。
前提條件
步驟一:創建數據表
登錄RDS管理控制臺,創建RDS PostgreSQL實例。更多信息,請參見創建RDS PostgreSQL實例。
創建實例時,請選擇與前提條件中已購買部署的Kafka實例相同的VPC,并將此VPC網段加入白名單。
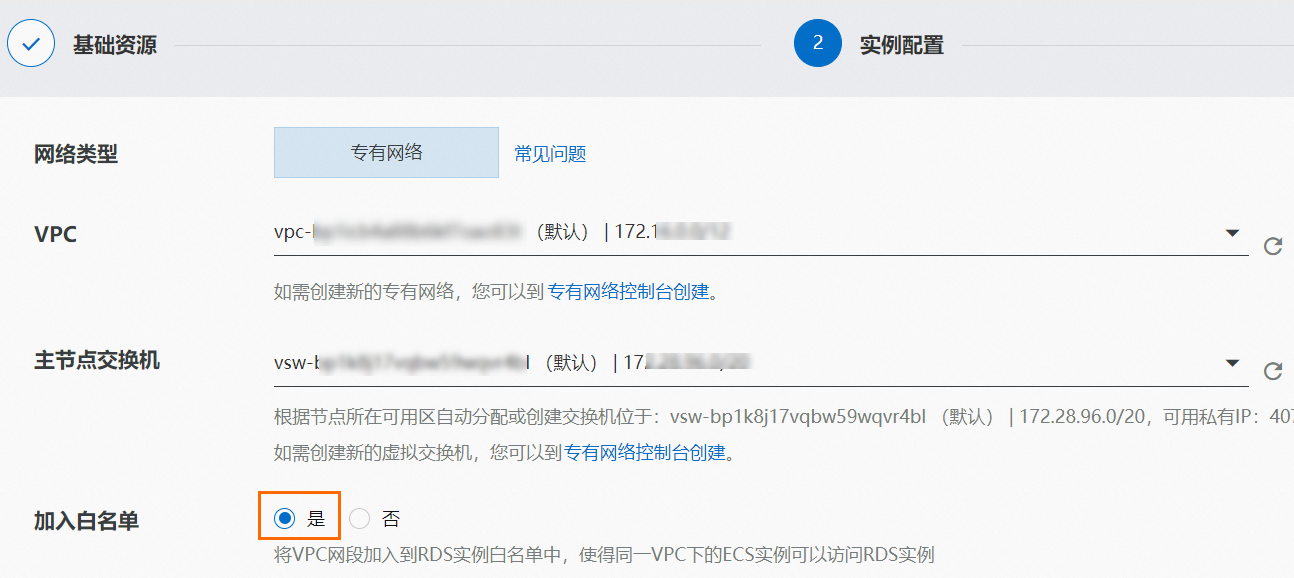
實例創建完成后,在實例列表頁面單擊目標實例,然后在實例詳情頁面的左側導航欄,完成以下操作。
在實例詳情頁面,單擊登錄數據庫進入DMS數據管理服務平臺,完成以下操作。
右鍵單擊目標數據庫,選擇模式管理,然后單擊創建模式創建新的模式(Schema)。
說明Connector配置中需使用新創建的Schema,不能用系統Schema(information、pg_catalog、public)代替。
在新建的Schema中,使用SQL語句創建表格。例如,創建一個列參數分別為id和number的表格,命令如下。更多信息,請參見SQL Commands。
CREATE TABLE sql_table(id INT ,number INT);執行以下命令,創建初始化wal2json插件,開啟數據訂閱能力。
SELECT 'init' FROM pg_create_logical_replication_slot('test_slot', 'wal2json');

步驟二:創建Connector任務
下載Debezium PostgreSQL Source Connector文件,上傳至提前創建好的OSS Bucket。更多信息,請參見控制臺上傳文件。
重要下載Debezium PostgreSQL Connector文件時請選擇適配Java 8的版本。
登錄云消息隊列 Kafka 版控制臺,在概覽頁面的資源分布區域,選擇地域。
在左側導航欄,選擇。
在任務列表頁面,單擊創建任務。
在創建任務面板,設置任務名稱,配置以下配置項。
任務創建
在Source(源)配置向導,選擇數據提供方為Apache Kafka Connect,單擊下一步。
在連接器配置配置向導,設置以下配置項,然后單擊下一步。
配置項
參數
說明
Kafka Connect插件
Bucket存儲桶
選擇OSS Bucket。
文件
選擇上傳的.ZIP文件。
Kafka資源信息
Kafka參數配置
選擇Source Connect。
Kafka實例
選擇前提條件中創建的實例。
專有網絡VPC
選擇VPC ID。
交換機
選擇vSwitch ID。
安全組
選擇安全組。
Kafka Connect配置信息
解析當前ZIP包下的properties文件
選擇新建properties文件。在輸入框中更新相關字段的取值。
字段名
描述
connector.class
運行的Connector包名稱,無需修改。
database.dbname
數據庫名稱。
database.hostname
填寫步驟一:創建數據表中獲取的內網地址。
database.port
填寫步驟一:創建數據表中獲取的端口號。
database.user
數據庫登錄用戶名。
database.password
數據庫登錄密碼。
slot.name
數據庫邏輯復制流的名稱。
table.whitelist
數據庫表格列表。不同表格之間用英文逗號(,)分隔,表格的指定規則為
{schemaName}.{tableName}。database.server.name
目標Topic前綴。目標Topic的命名規范為
{database.server.name}.{schemaName}.{tableName}。重要在投遞數據前,請按照命名規范提前創建好目標Topic。
connector.class=io.debezium.connector.postgresql.PostgresConnector database.dbname=test_database database.hostname=pgm-xxx.pg.rds.aliyuncs.com database.password=xxx database.port=5432 database.user=xxx name=debezium-psql-source # 插件名稱,本文場景下使用的是wal2json。有效取值包含decoderbufs、wal2json、wal2json_rds、wal2json_streaming以及wal2json_rds_streaming。 plugin.name=wal2json slot.drop_on_stop=true slot.name=test_slot # 源數據庫表格列表,不同表格之間用英文逗號(,)分隔,表格的指定規則為<schemaName>.<tableName>。 table.whitelist=test_schema.test_table # 注意,這里只能有1個task進行消費。 tasks.max=1 # 目標Topic前綴,目標Topic的命名規格為<database.server.name>.<schemaName>.<tableName>。 # 例如在本文的場景下,schemaName是kafka_connect_schema,tableName是table2_with_pk # 那么,這個表格的CDC數據會流入目標topic test-prefix.kafka_connect_schema.table2_with_pk database.server.name=test-prefix # 消息Value格式轉換組件。 value.converter=org.apache.kafka.connect.json.JsonConverter # 消息 Value 內容中是否包含結構體schema信息。 value.converter.schemas.enable=falseConnector全量參數,請參見Debezium Connector Properties。
在實例配置配置向導,設置以下參數,然后單擊下一步。
配置項
參數
說明
Worker規格
Worker規格
選擇合適的Worker規格。
最小Worker數
設置為1。
最大Worker數
設置為1。
Kafka Connect Worker配置
自動創建Kafka Connect Worker依賴資源
建議勾選此項,會在選擇的Kafka實例中自動創建Kafka Connect運行所需的一些Internal Topic以及ConsumerGroup,并將這些必填配置自動填入配置框中。包括以下配置項:
Offset Topic:用于存儲源數據偏移量,命名規則為
connect-eb-offset-<任務名稱>。Config Topic:用于存儲Connectors以及Tasks的配置信息,命名規則為
connect-eb-config-<任務名稱>。Status Topic:用于存儲Connectors以及Tasks狀態信息,命名規則為
connect-eb-status-<任務名稱>。Kafka Connect Consumer Group:Kafka Connect Worker用于消費Internal Topics的消費組,命名規則為
connect-eb-cluster-<任務名稱>。Kafka Source Connector Consumer Group:只針對Sink Connector有效,用于消費源Kafka Topic中的數據,命名規則為
connector-eb-cluster-<任務名稱>-<connector名稱>。
在運行配置配置向導,將日志投遞方式設置為投遞至SLS或者投遞至Kafka,在角色授權卡片設置Connect依賴的角色配置,然后單擊保存。
重要建議配置的角色包含AliyunSAEFullAccess權限,否則可能會導致任務運行失敗。
任務屬性
設置此任務的重試策略及死信隊列。更多信息,請參見重試和死信。
等待任務狀態變為運行中,此時Connector已經在正常工作中。
步驟三:測試Connector任務
在DMS數據管理服務平臺,向步驟一:創建數據表中創建的數據表插入一條數據。例如,插入一條id為123,number為20000的數據,命令如下。
INSERT INTO sql_table(id, number) VALUES(123,20000);登錄云消息隊列 Kafka 版控制臺,在實例列表頁面,單擊目標實例。
在目標實例頁面,單擊目標Topic(投遞數據前提前創建好的命名規則為
{database.server.name}.{schemaName}.{tableName}的Topic),然后單擊消息查詢,查看插入的消息數據,消息Value示例如下。{"before":null,"after":{"id":123,"number":20000},"source":{"version":"0.9.2.Final","connector":"postgresql","name":"test-prefix","db":"wb","ts_usec":168386295815075****,"txId":10339,"lsn":412719****,"schema":"test_schema","table":"sql_table","snapshot":false,"last_snapshot_record":null},"op":"c","ts_ms":168386295****}
常見報錯
場景一:所有Tasks運行失敗
錯誤信息:
All tasks under connector mongo-source failed, please check the error trace of the task.解決方法:在消息流入任務詳情頁面,單擊基礎信息區域的診斷鏈接,即可跳轉到Connector監控頁面,可以看到Tasks運行失敗的詳細錯誤信息。
場景二:Kafka Connect退出
錯誤信息:
Kafka connect exited! Please check the error log /opt/kafka/logs/connect.log on sae application to find out the reason why kafka connect exited and update the event streaming with valid arguments to solve it.解決方法:由于狀態獲取可能會有延遲,建議您先嘗試刷新頁面。若刷新后仍然是失敗狀態,您可以按照以下步驟查看錯誤信息。
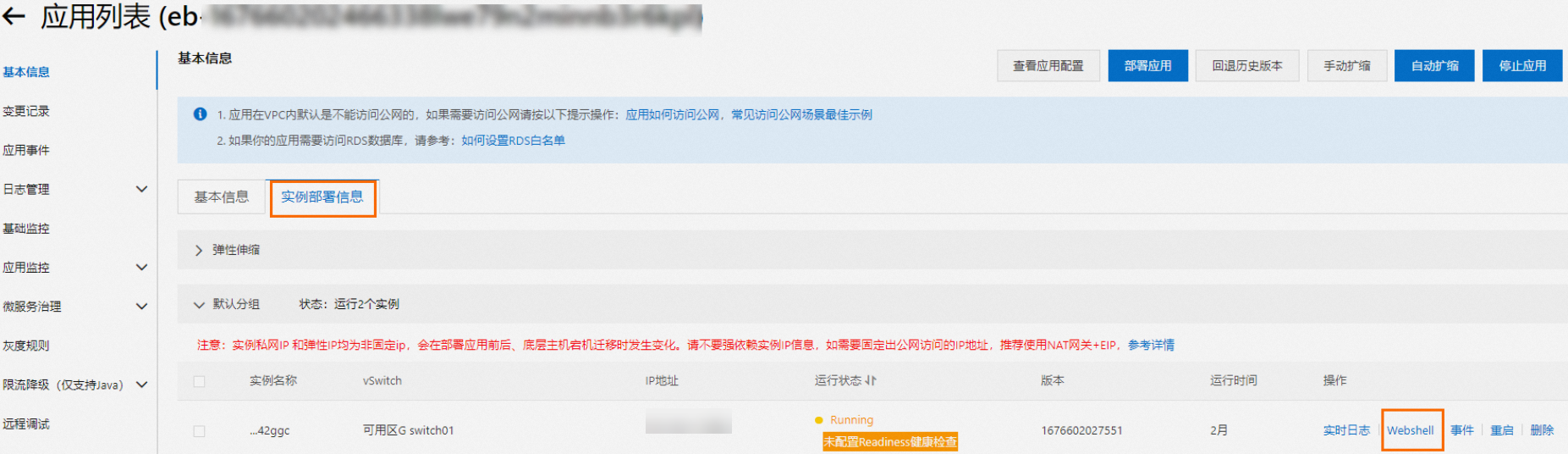
在消息流入任務詳情頁面的Worker信息區域,單擊SAE應用后的實例名稱,跳轉到SAE應用詳情頁面。
在基本信息頁面,單擊實例部署信息頁簽。
在實例右側操作列,單擊Webshell登錄Kafka Connect運行環境。
執行
vi /home/admin/connector-bootstrap.log命令,查看Connector啟動日志,查找其中是否包含錯誤信息。執行
vi /opt/kafka/logs/connect.log命令,查看Connector運行日志,在其中查找ERROR或者WARN字段來查看是否有錯誤信息。
基于錯誤信息提示進行修復操作后,可以重新啟動對應任務。
場景三:Connector參數校驗失敗
錯誤信息:
Start or update connector xxx failed. Error code=400. Error message=Connector configuration is invalid and contains the following 1 error(s):
Value must be one of never, initial_only, when_needed, initial, schema_only, schema_only_recovery
You can also find the above list of errors at the endpoint `/connector-plugins/{connectorType}/config/validate`解決方法:此時需要根據錯誤信息,找出具體哪個參數出錯,更新對應參數即可。若基于上述錯誤信息無法定位具體的出錯參數,可以參考上文場景二中的步驟登錄Kafka Connect運行環境,執行以下命令,查詢參數是否校驗通過。
curl -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" -d @$CONNECTOR_PROPERTIES_MAPPING http://localhost:8083/connector-plugins/io.confluent.connect.jdbc.JdbcSinkConnector/config/validate該指令會返回Connector參數中每個參數是否校驗通過,若不通過,則errors屬性非空,如下所示。
"value":{
"name":"snapshot.mode",
"value":null,
"recommended_values":[
"never",
"initial_only",
"when_needed",
"initial",
"schema_only",
"schema_only_recovery"
],
"errors":[
"Value must be one of never, initial_only, when_needed, initial, schema_only, schema_only_recovery"
],
"visible":true
}