配置作業(yè)資源
您可以在作業(yè)啟動前配置作業(yè)資源或者作業(yè)上線后修改作業(yè)資源,支持基礎(chǔ)模式(粗粒度)和專家模式(細(xì)粒度)兩種資源模式。本文為您介紹如何配置作業(yè)資源,以及兩種資源模式下的參數(shù)信息。
注意事項
資源配置后,需重啟作業(yè)才能生效。
操作步驟
進入資源配置入口。
登錄實時計算控制臺。
單擊目標(biāo)工作空間操作列下的控制臺。
在頁面,單擊目標(biāo)作業(yè)名稱。
在部署詳情頁簽,單擊資源配置區(qū)域右側(cè)的編輯。
修改作業(yè)資源信息。
支持基礎(chǔ)模式(粗粒度)和專家模式(細(xì)粒度)兩種資源配置模式。
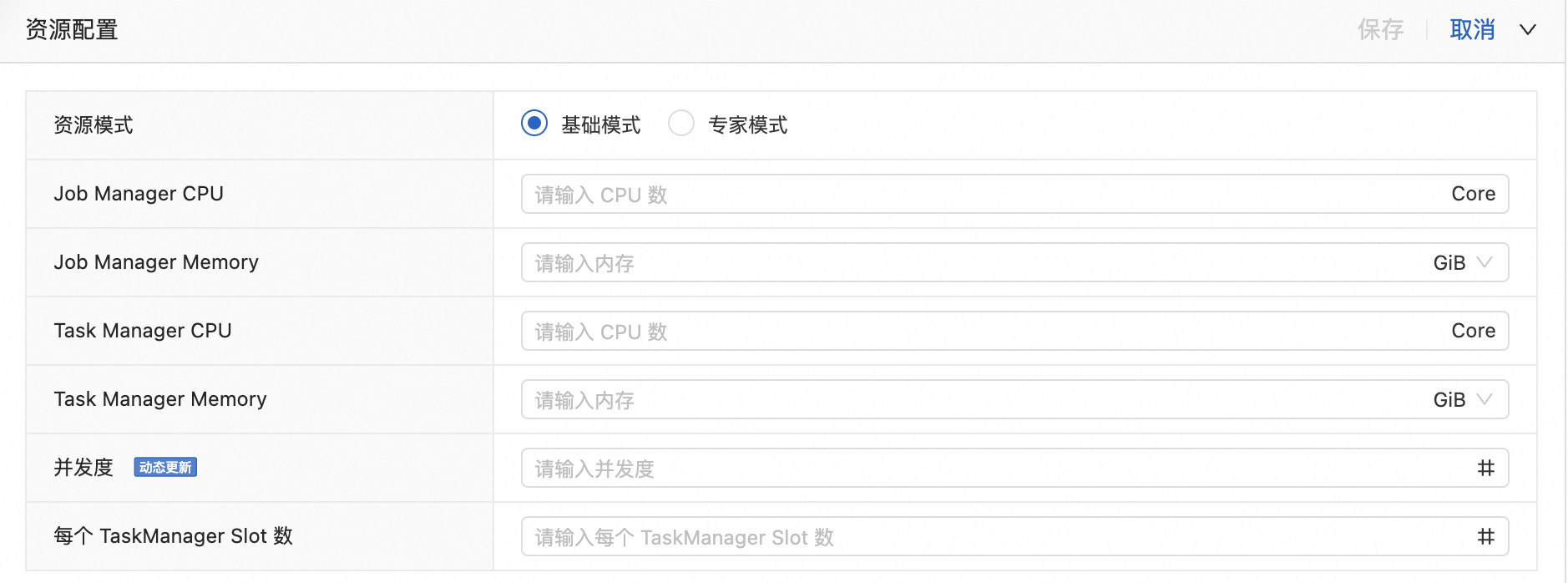
資源模式
說明
配置參數(shù)說明
基礎(chǔ)模式
粗粒度是一種靜態(tài)資源分配方式,您只需要給定每個TM啟動所需要的總資源(CPU和JVM總內(nèi)存),系統(tǒng)會根據(jù)每個TaskManager Slot數(shù)(即flink conf taskmanager.numberOfTaskSlots)均勻分配所有資源。對于大多數(shù)簡單作業(yè),粗粒度即可滿足要求。
專家模式
細(xì)粒度是一種動態(tài)資源分配方式,您可以配置每個Slot共享組(Slot Sharing Group,SSG)所需要的資源,F(xiàn)link會計算出每個Slot需要的資源規(guī)格大小,動態(tài)的從可用資源池去申請完全匹配的TM和Slot。對于復(fù)雜作業(yè),粗粒度可能導(dǎo)致資源利用率低,因此需要細(xì)粒度資源對每個算子進行精細(xì)資源控制,從而提高資源使用率,滿足作業(yè)吞吐的要求。
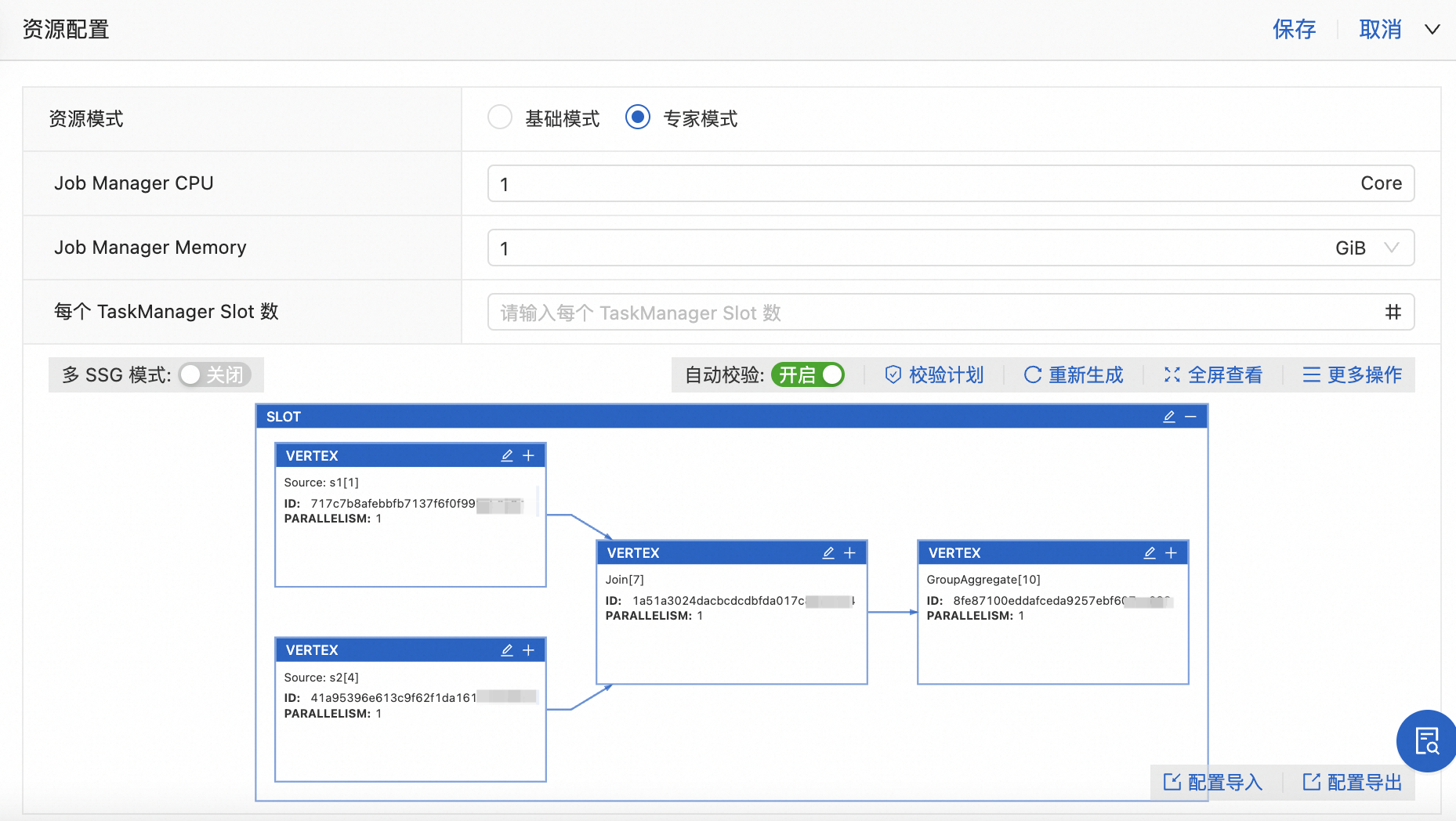 說明
說明僅SQL作業(yè)支持配置專家模式。
關(guān)于TM、JM、Task或Slot等概念,詳情請參見Apache Flink Architecture。
單擊保存。
重啟作業(yè)。
作業(yè)資源配置后,需重啟作業(yè)才能生效。
基礎(chǔ)模式(粗粒度)
配置項 | 說明 |
并發(fā)度 | 作業(yè)全局并發(fā)數(shù)。 |
JobManager CPU | 根據(jù)Flink最佳實踐,單個JM內(nèi)存資源需要至少配置為0.5 Core和2 GiB,才能保證作業(yè)穩(wěn)定運行。建議您配置為1 Core和4 GiB。最大值為16 Core。 |
JobManager Memory | 單位為GiB,最小值為2 GiB,最大值為64 GiB。 |
TaskManager CPU | 根據(jù)Flink最佳實踐,單個TM內(nèi)存資源需要至少配置為0.5 Core和2 GiB,才能保證作業(yè)穩(wěn)定運行。建議您配置為1 Core和4 GiB。最大值為16 Core。 |
TaskManager Memory | 單位為GiB,最小值為2 GiB,最大值為64 GiB。 |
每個TaskManager Slot數(shù) | 請?zhí)顚慣M的Slot數(shù)。 |
您可以根據(jù)以下公式進行推算:
作業(yè)所配置的CU數(shù) = MAX(JM和TM的CPU總和, JM和TM的內(nèi)存總和/4)。
每個作業(yè)所需IP數(shù) = JM數(shù)(每個作業(yè)只有一個)+實際TM數(shù)。
實際TM數(shù)= MAX(?總CPU數(shù)/TM的CPU默認(rèn)最大值?,?總內(nèi)存數(shù)/TM的內(nèi)存默認(rèn)最大值?)。
總CPU數(shù)=設(shè)置的并發(fā)度/設(shè)置的每個TaskManager Slot數(shù)*設(shè)置的單個TM CPU。
總內(nèi)存數(shù)=設(shè)置的并發(fā)度/設(shè)置的每個TaskManager Slot數(shù)*設(shè)置的單個TM的內(nèi)存。
TM的CPU默認(rèn)最大值為16 Core。
TM的內(nèi)存默認(rèn)最大值為64 GiB。
實際每個TM上可分配的slot數(shù) = ?設(shè)置的并發(fā)數(shù)/實際TM數(shù)?。
例如,當(dāng)并發(fā)度設(shè)置為80,每個TM Slot數(shù)設(shè)置為20,每個TM CPU設(shè)置為22 Core,每個TM 內(nèi)存設(shè)置為30 GiB時,配置如下圖所示。
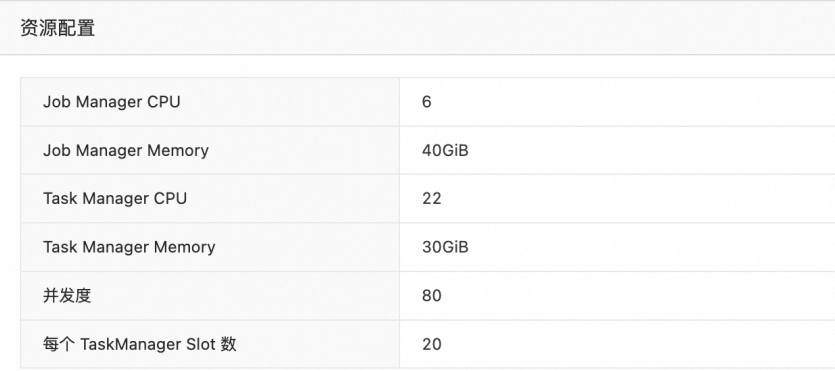
在Flink開發(fā)控制臺,您會看到實際的TaskManager數(shù)為6,每個TaskManager Slot數(shù)為14。
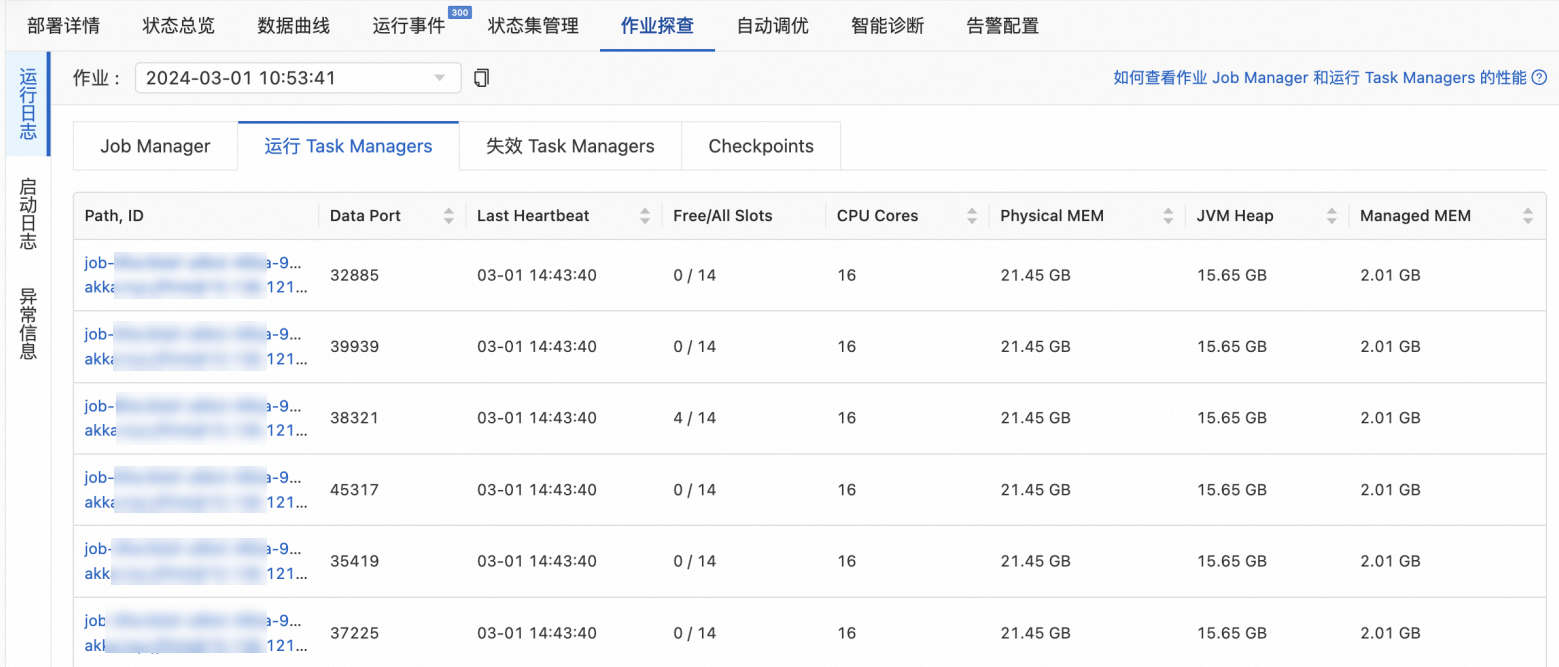
實際的TM數(shù)和每個TM的Slot數(shù)的推算過程如下:
實際TM數(shù) =MAX(?總CPU數(shù)/TM的CPU默認(rèn)最大值?,?總內(nèi)存數(shù)/TM的內(nèi)存默認(rèn)最大值?)= MAX(?設(shè)置的并發(fā)數(shù)/單個TM的Slot數(shù)量*設(shè)置的單個TM CPU/16?,?設(shè)置的并發(fā)數(shù)/單個TM的Slot數(shù)量*設(shè)置的單個TM的內(nèi)存/64?)= MAX(?80/20*22/16?,?80/20*30/64?)= MAX(?88/16?,?120/64?)= MAX(6,2) = 6。
實際TM的Slot數(shù)=?并發(fā)數(shù)/實際TM數(shù)? = ?80/6?=14。
實際TM的推算邏輯需要您設(shè)置的TM的CPU和內(nèi)存大于其最大默認(rèn)值,才可有效。
計算比值需分別向上取整。
如果您需要提高默認(rèn)TM內(nèi)存和CPU的最大值,請您提交工單。
您也可以在作業(yè)部署詳情頁簽運行參數(shù)配置區(qū)域的其他配置中設(shè)置numberOfTaskSlots參數(shù),和界面配置每個TaskManager Slot數(shù)作用相同,但優(yōu)先級更高。
專家模式(細(xì)粒度)
僅SQL作業(yè)支持配置專家模式。
在部署作業(yè)后,若對SQL或者資源配置進行了修改,需要重新生成資源計劃圖,以確保作業(yè)能夠正常啟動。
配置基礎(chǔ)資源
配置項 | 說明 |
JobManager CPU | 根據(jù)Flink最佳實踐,單個JM內(nèi)存資源需要至少配置為0.25 Core和1 GiB,才能保證作業(yè)穩(wěn)定運行,最大值16 Core。 |
JobManager Memory | 單位為GiB,例如,4 GiB。最小值為1 GiB,最大值64 GiB。 |
每個TaskManager Slot數(shù) | 無。 |
配置Slot資源
在專家模式下,單擊立刻獲取,獲取資源計劃圖。
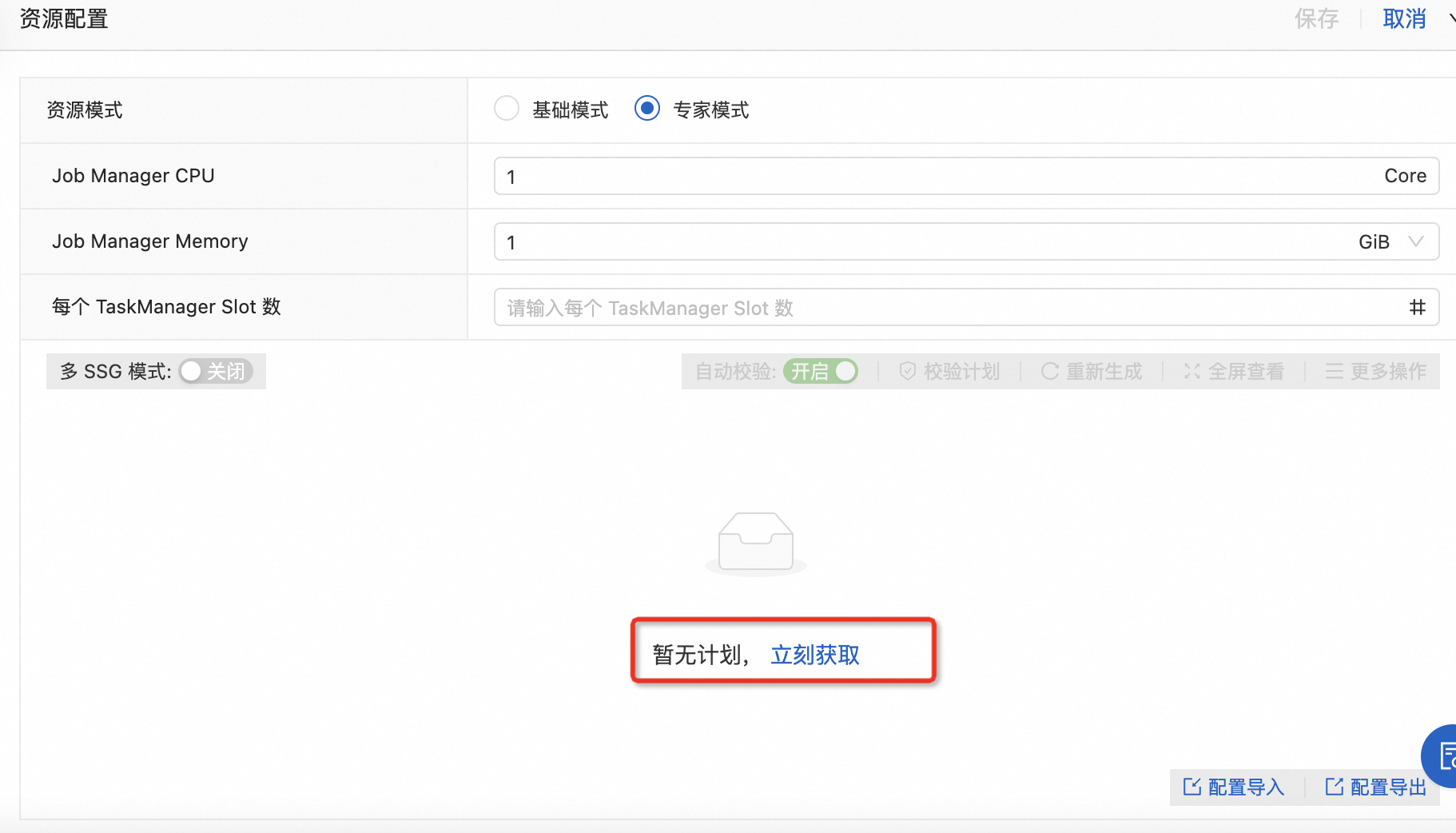
單擊Slot框上的
 圖標(biāo)。
圖標(biāo)。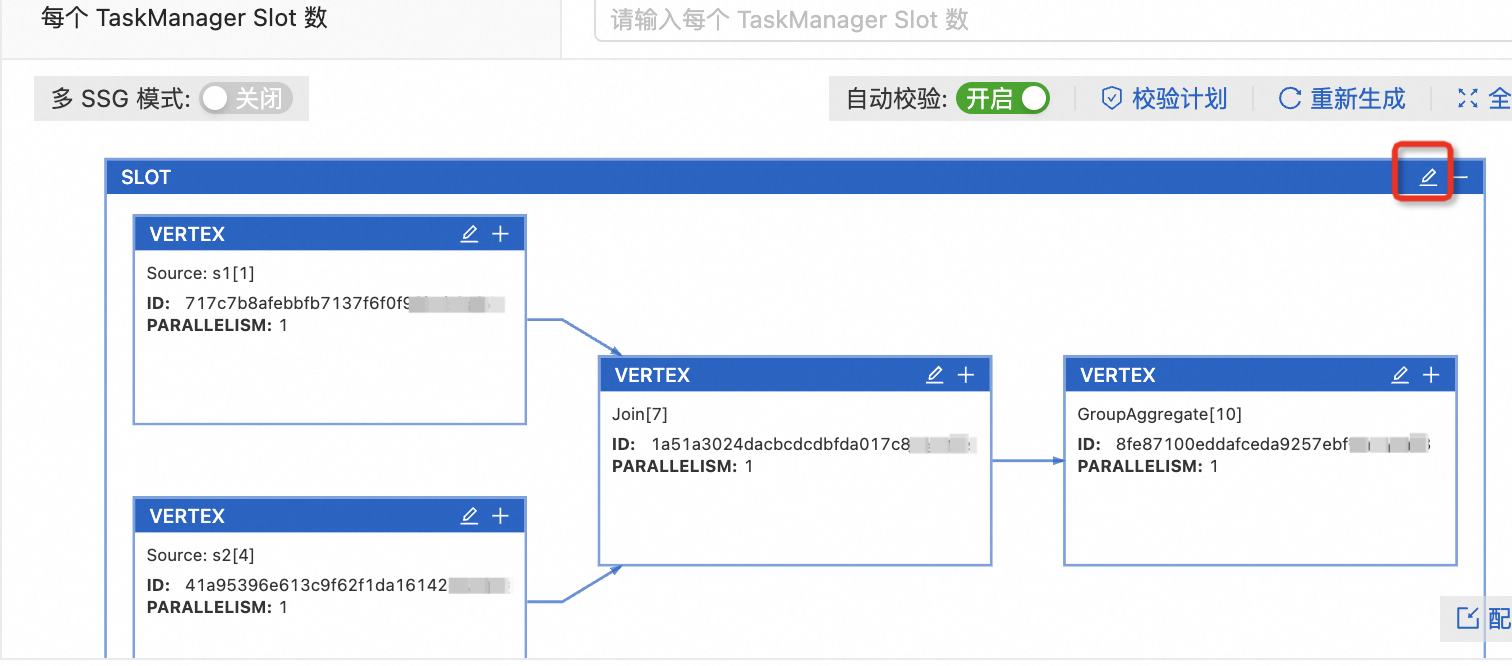
修改Slot配置信息。
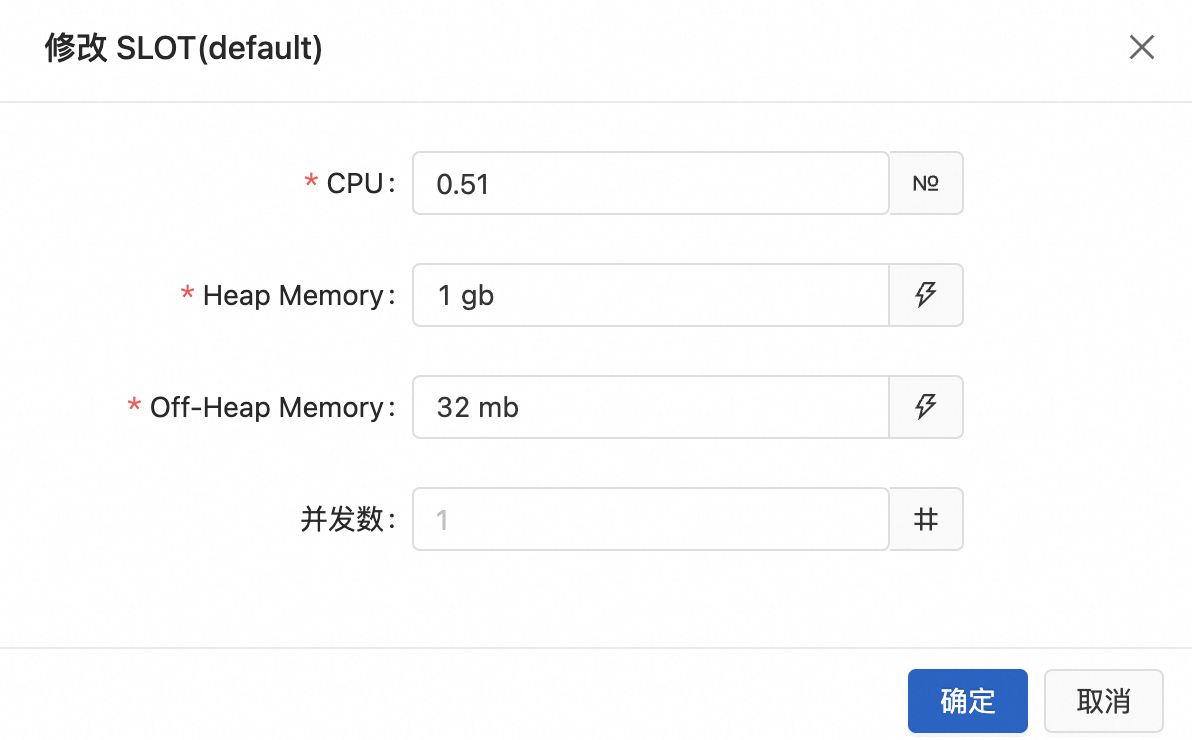
此處設(shè)置的并發(fā)數(shù)為該Slot共享組內(nèi)所有算子的統(tǒng)一并發(fā)數(shù)。設(shè)置完成后,系統(tǒng)將自動進行以下操作:
系統(tǒng)將自動為該Slot共享組內(nèi)的所有算子設(shè)置相同的并發(fā)數(shù)。
系統(tǒng)會根據(jù)作業(yè)的計算邏輯按需自動生成Statebackend、Python和Operator所需的內(nèi)存,無需您手動進行配置。
建議Source節(jié)點并發(fā)度和分區(qū)數(shù)成比例,即并發(fā)度數(shù)能整除分區(qū)數(shù)。例如Kafka有16個分區(qū),則并發(fā)度建議設(shè)置為16、8或4,這樣可以避免數(shù)據(jù)傾斜。同時Source節(jié)點的并發(fā)度不宜設(shè)置太小,避免一個Source需要讀取太多數(shù)據(jù),導(dǎo)致出現(xiàn)入口瓶頸,影響作業(yè)吞吐。
建議按需配置除Source外的其他節(jié)點的并發(fā)度。流量大的節(jié)點,并發(fā)設(shè)置大一些;流量小的節(jié)點,并發(fā)設(shè)置小一些。
建議在有明確異常或者需求時,再調(diào)整Heap Memory和Off-heap Memory的大小,例如作業(yè)出現(xiàn)OOM或嚴(yán)重GC等。因為在作業(yè)正常運行時,調(diào)整Heap Memory和Off-heap Memory的大小,不會明顯改變作業(yè)的吞吐量。
說明單擊確定。
配置算子資源
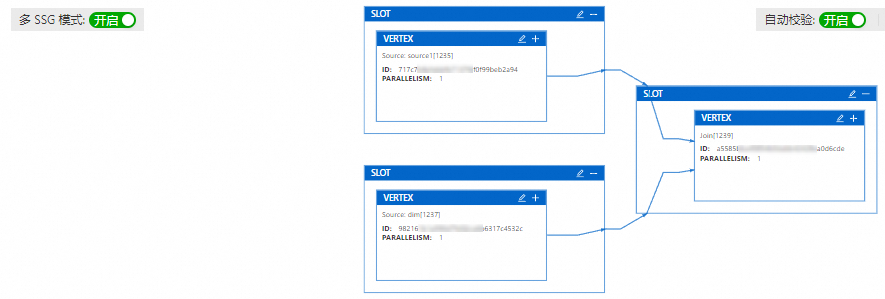
默認(rèn)情況下,所有算子都放在一個Slot共享組內(nèi),因此您無法為每個算子單獨修改資源配置。如果您需要對單獨的算子設(shè)置資源,需要開啟多SSG模式后讓每個算子有自己獨立的Slot,這樣就可以直接在對應(yīng)的Slot上設(shè)置算子的資源。具體的算子資源設(shè)置步驟如下:
在作業(yè)部署詳情頁簽資源配置區(qū)域,單擊編輯后,資源模式選擇為專家模式。
(可選)如果暫無資源計劃,單擊立刻獲取。
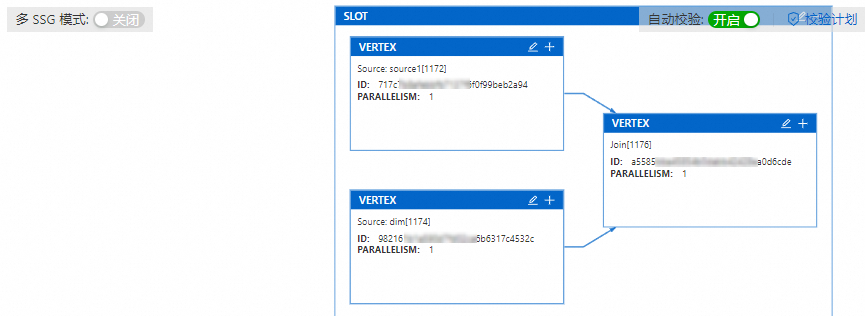
打開多SSG模式開關(guān)后,單擊重新生成。
此時一個共享組內(nèi)的算子被拆分為單個Slot。
單擊目標(biāo)算子對應(yīng)Slot框上的
圖標(biāo)后,修改算子資源。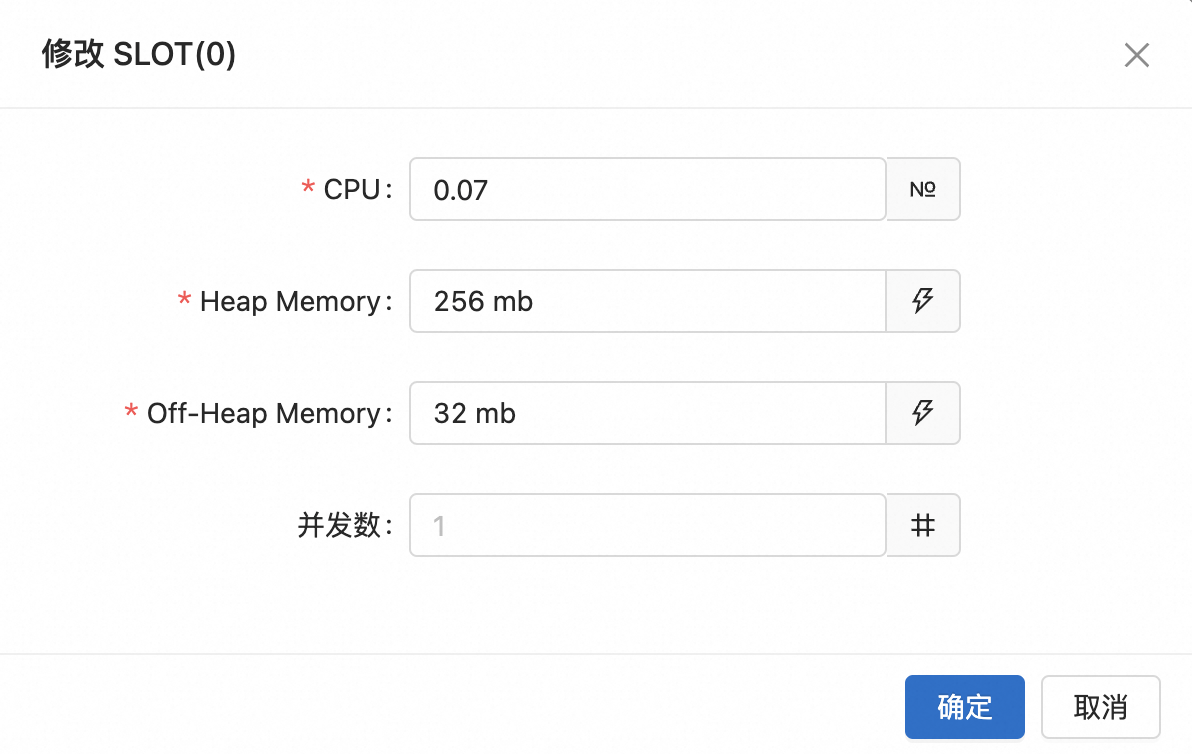
單擊確定。
配置算子并發(fā)、Chain策略和TTL
僅實時計算引擎VVR 8.0.7及以上版本支持配置算子TTL。
支持配置單個算子的并發(fā)數(shù)、Chaining策略和算子State過期時間(TTL)。
單擊目標(biāo)VERTEX框上的
 展開VERTEX。
展開VERTEX。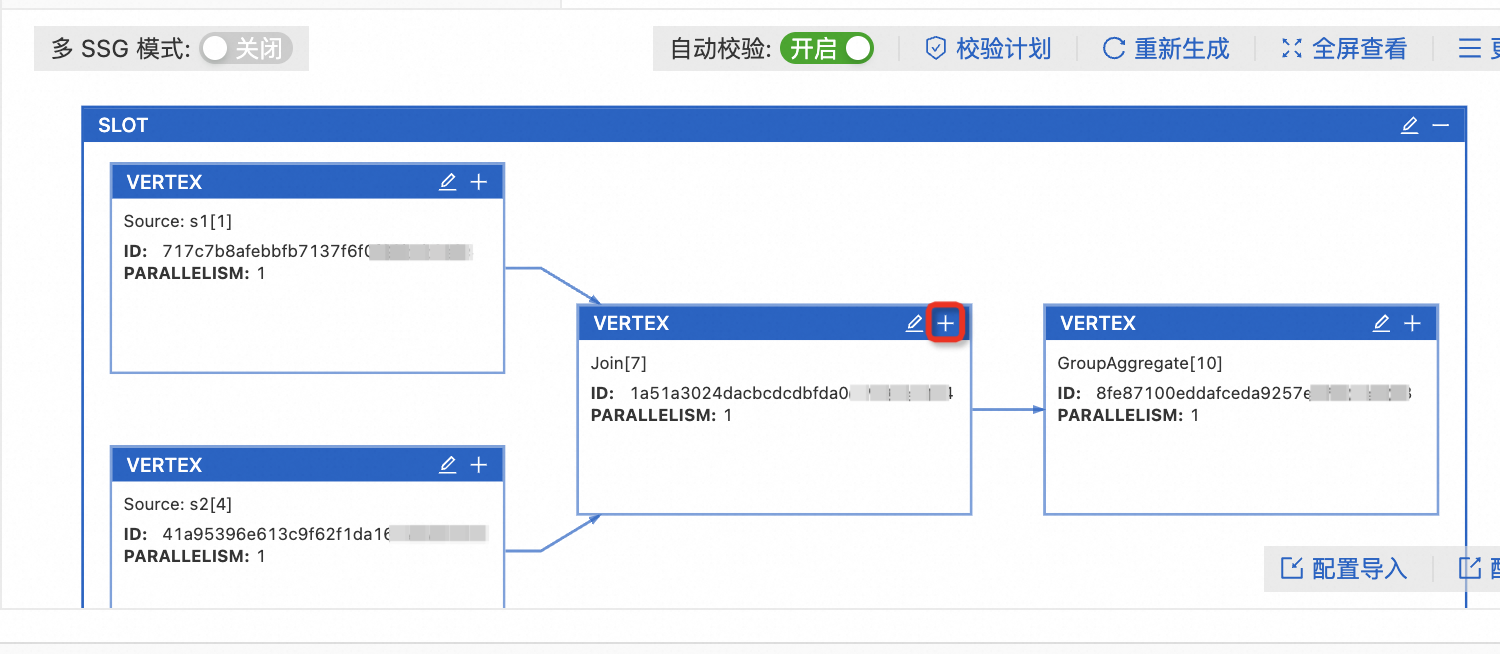 說明
說明您可以單擊目標(biāo)VERTEX上的
圖標(biāo),批量設(shè)置對應(yīng)VERTEX下的算子并發(fā)數(shù)。單擊算子的
 圖標(biāo)。
圖標(biāo)。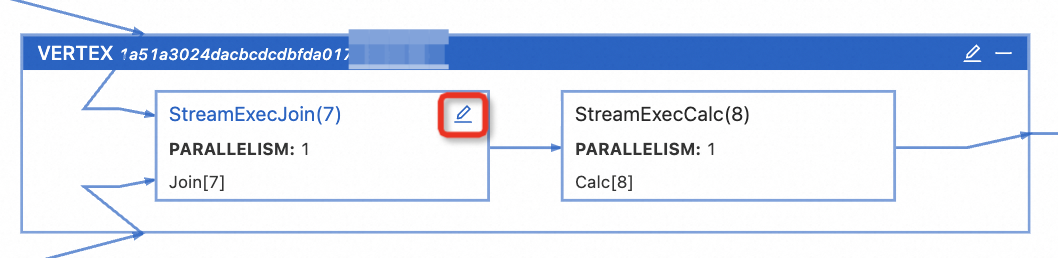
配置算子資源。
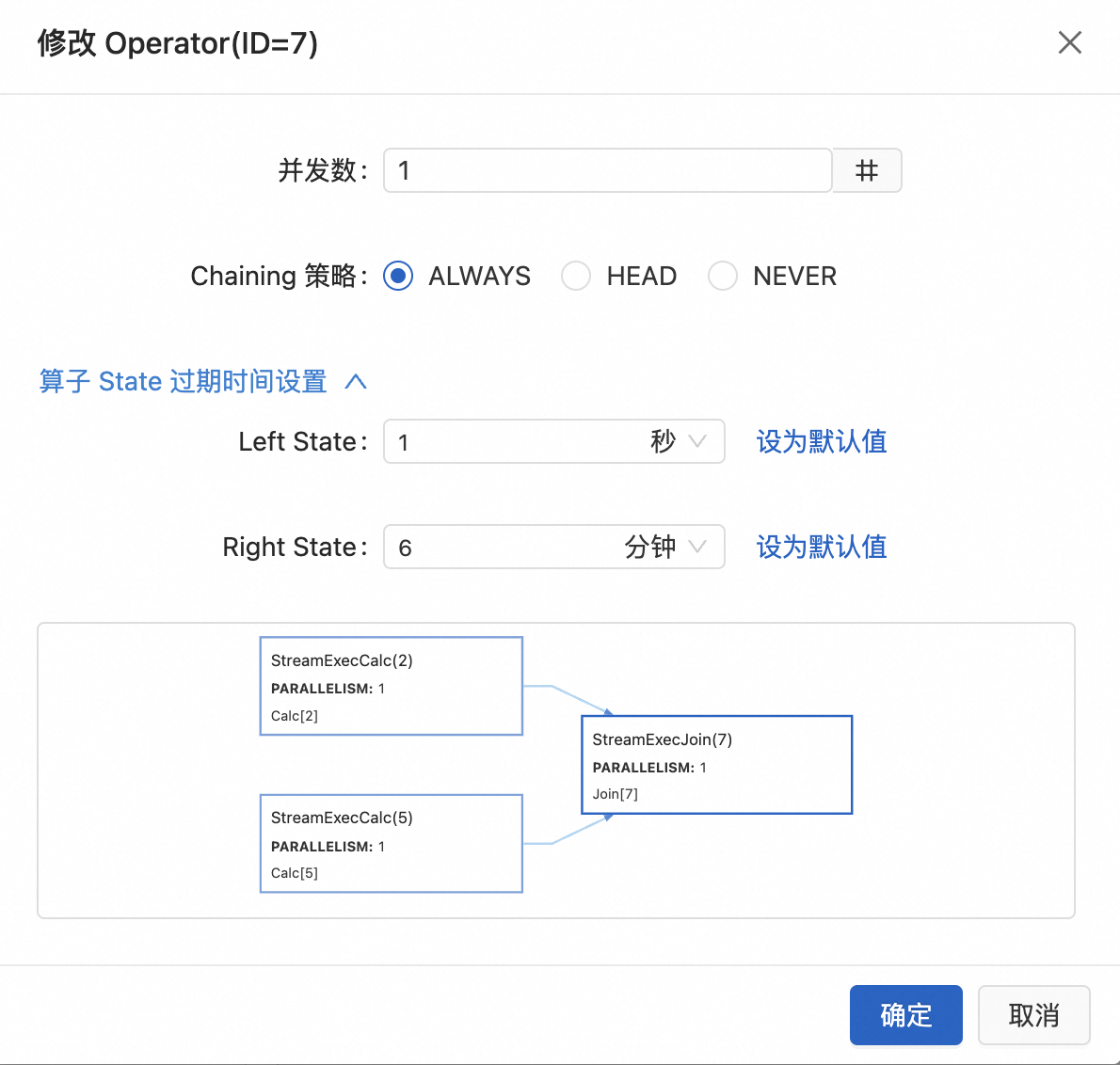
參數(shù)說明如下:
參數(shù)
說明
并發(fā)數(shù)
對應(yīng)算子的并發(fā)數(shù)。
Chaining策略
Chain是指多個算子被連接在一起形成的邏輯計算鏈。它能夠提高作業(yè)的執(zhí)行效率和性能,減少數(shù)據(jù)在算子之間的傳輸和序列化開銷。不過有時可能需要將Chain斷開,以便更好地控制作業(yè)的執(zhí)行流程和性能。支持配置策略如下:
ALWAYS(默認(rèn)值):算子始終可以和上下游算子Chain一起。
HEAD:當(dāng)前算子作為Chain的頭節(jié)點,只和上游算子斷開Chain,下游節(jié)點仍和當(dāng)前算子Chain在一起。
NEVER:當(dāng)前算子不會與上下游算子進行Chain。
算子State過期時間設(shè)置(TTL)
支持設(shè)置秒、分鐘、小時和天為單位的過期時間。默認(rèn)為作業(yè)的過期時間(未設(shè)置過期時間的作業(yè)默認(rèn)為1.5天,作業(yè)過期時間配置請參見運行參數(shù)配置)。
說明僅實時計算引擎VVR 8.0.7及以上版本支持。
僅有狀態(tài)算子支持配置過期時間。
單擊確定。
相關(guān)文檔
資源優(yōu)化技巧,詳情請參見高性能Flink SQL優(yōu)化技巧。
如果不想手動調(diào)節(jié)資源,可以使用自動調(diào)優(yōu),系統(tǒng)會自動完成資源調(diào)節(jié),詳情請參見配置自動調(diào)優(yōu)。
作業(yè)的基礎(chǔ)配置、運行參數(shù)配置和日志配置,詳情請參見配置作業(yè)部署信息。
您可以通過Flink Advisor作業(yè)智能診斷服務(wù)幫您監(jiān)控作業(yè)健康狀況,詳情請參見作業(yè)智能診斷。