本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
在交易、注冊拉新場景,我們會經常面臨黃牛賬號的困擾,影響拉新效果和新用戶的權益保證。針對這種業務場景,我們基于豐富表的圖數據關系,通過OneID快速識別和定位黃牛賬號、判定新人拉新規范,從而進一步賦予業務更準確和可解釋的防控手段。
為了方便用戶能夠熟悉圖計算服務GraphCompute,我們提供一份完整的OneID-黃牛賬號識別Demo數據、查詢Query和文檔指南,幫助用戶快速搭建一個圖計算應用,并提供百萬級別數據量的黃牛賬號識別和挖掘能力。
什么是GraphCompute?
GraphCompute 是一個分布式的、萬億級數據規模下、高性能、高穩定性的圖查詢和計算解決方案。同時,搭載智能運維和離線系統,實現湖倉一體化的數據打通,支持多版本數據快速迭代和管理能力。結合阿里巴巴在電商、安全和社交等多個行業領域的積累,為全球企業及開發者提供圖技術服務
背景介紹
數字經濟時代下,數據成為推動創新發展的關鍵要素。數據的開放,推動了多行業、跨行業、跨組織的協同與創新,催生出新型的產業形態和商業模式。但隨著數據價值的凸顯,針對數據的攻擊、竊取、濫用、劫持等活動持續泛濫,并呈現出產業化、高科技化等特性。在互聯網企業,對于識別、追蹤用戶身份都有強烈的需求,通過用戶的賬號、設備之間信息關聯,能夠快速識別賬戶情況,做出更好的業務聯動或者防護。在該類場景下,我們統一定義為OneID賬戶同人識別。
什么是OneID?
簡單來說OneID是一套跨屏、跨域的自然人身份識別、追蹤系統,類似于實際生活中的身份證號,對于每個互聯網世界的每個自然人都通過算法賦予一個穩定的虛擬身份ID
- OneID,并且識別自然人所擁有的各類身份ID。 身份ID包括三大類:
- 賬號類:業務賬號,手機號,Email等等
- 設備類:設備IMEI,設備IMSI,設備IDFA,
- cookie類:Acookie等等。
OneID體系能夠將稀疏的信息通過實體之間的關系匯聚起來,聚焦到自然人,譬如從重要設備ID能夠關聯出大量的賬號ID,說明這些賬號可以屬于一個人或者團伙共有,并挖掘出業務平臺的黃牛或者非法團伙信息。
為什么用“圖”做風險挖掘?
圖能夠高效表達關系和行為,業界通過圖計算相關技術能夠沉淀歸類部分圖模型和關系。而我們可以通過其中的關系現象進行對應的數據建模,就能將痕跡歸納總結,應用于欺詐防控。此外,傳統的欺詐檢測通常關注特征空間中的離群點,而忽略了現實世界中的關系數據。在現實生活中,實體之間有著豐富的關系,圖結構可以為欺詐檢測提供信息增益。
【黃牛賬號識別】業務落地
業務背景
某款科技公司網站,主要售賣各種AI數字化產品和解決方案,針對活動都會發放優惠券權益,但是主要希望能對網站的注冊賬戶做OneID風控識別,幫助公司挖掘黃牛賬號、薅羊毛團伙,減少無效資金損失。
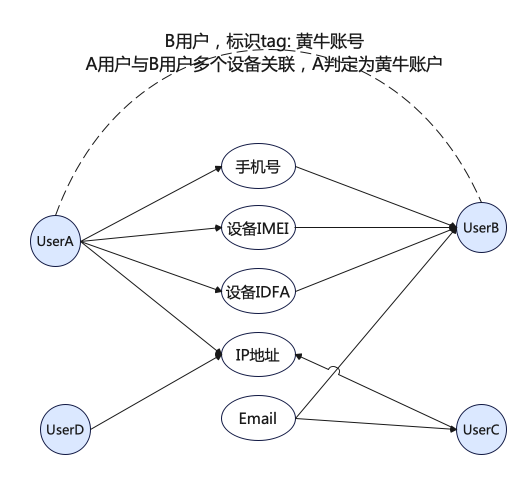
通過對黃牛黨或者團伙行為分析,普遍的現象是最大程度的利用手上設備資源,實現賬號體系的最大化;針對有部分用戶通過重復注冊賬號領取優惠券薅羊毛的行為進行檢測,需要進行用戶到用戶的多度查詢;
根據業務的特點進行抽象定義,最終的業務邏輯可以理解為:
1)查詢的業務場景:賬戶A - 設備G - 賬號B 二跳關系
2)需要獲取多種設備關聯的二跳用戶后,對設備路徑權重加分,最終得到
業務梳理
基于圖數據在交易欺詐、垃圾注冊場景下,我們就能夠OneID快速識別和定位黃牛賬號、新人拉新判定,從而進一步賦予業務更準確和可解釋的防控手段。
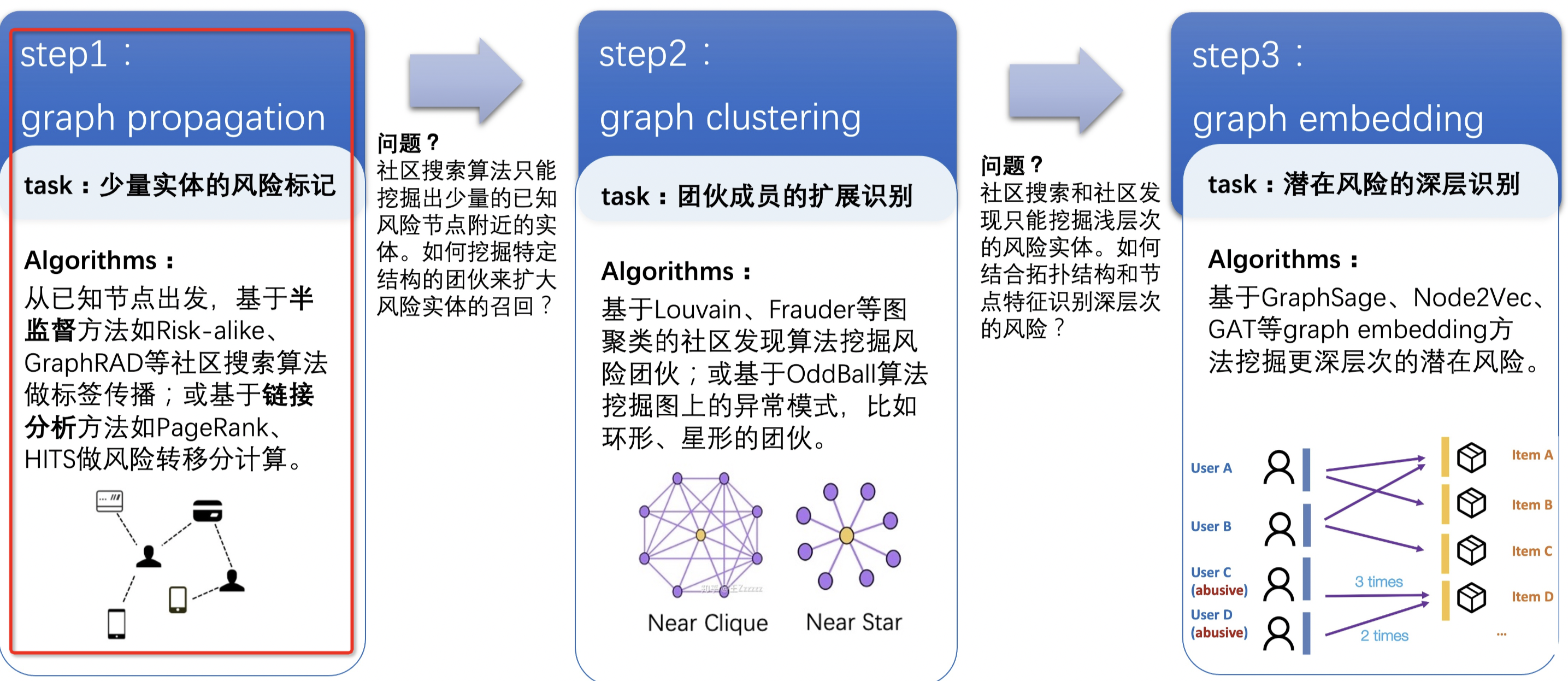
首先從離線算法出發:探索的路線從圖傳播算法——>圖聚類算法——>圖表征算法,挖掘更大范圍,更深層次的風險。最開始使用圖傳播算法,可以快速地挖掘出少量風險實例且較高的準確率效果,但是半監督的圖傳播算法只能從局部出發,挖掘出已知風險實體附近的少量風險實體。如何能夠從全局出發,擴大風險實例的召回,這時候開始使用圖聚類算法去挖掘風險團伙。除了圖結構可以幫助挖掘風險外,實體的屬性也可以幫助挖掘風險。充分結合賬號的違規、處罰、行為特征以帶來更多的信息增益,幫助挖掘更深層次的風險。
當前我們重點講解的「黃牛賬號識別」,該類風控場景就可以通過下圖第一步【圖傳播算法】,從當前已經風險的節點往外傳播影響決策能力,挖掘出高風險節點,以及對應的風險分數。
Step1:日志數據梳理
用戶登錄、注冊信息進行日志收集,將用戶的登錄記錄進行
定義數據:確認數據源,定義每個數據源返回的數據格式、字段
SLS日志收集,原始的數據信息包括:
用戶登錄信息
用戶注冊信息
cookie信息
數據標準化及映射:有一個專門的平臺可以定義數據源數據到表中數據的映射,并允許對數據進行腳本化處理
【用戶信息表】
注冊賬號、時間等有效信息
【設備信息表】
設備類型:手機、IP地址、email 等信息
事件觸發增量寫入:當事件發生,觸發一個向對應表內寫的增量信息
新用戶注冊登錄后,進行數據輸出,最終將進行【用戶信息表】和【設備信息表】對應信息更新
持久化:引入MaxCompute,存儲離線全量
Step2:離線算法選擇
Community Search根據網絡中給出的已知種子節點的局部信息出發,去發現給定種子節點所在的局部社區,具有更強的社區針對性,是一種圖傳播的方法。可以使用半監督方法,基于已有的有標記的節點,為附近的無標記的節點打上偽標簽,并不斷迭代預測更多的無標記節點。
在反作弊時,通常只獲取到少量有標簽數據。同時,需要大量的無標簽數據,這些無標簽數據中存在著大量的風險實例,如何從大量的無標簽數據中,挖掘風險實例,是該場景需要解決的問題。這里構建半監督學習的流程,基于業務提供的風險數據作為原始輸入,挖掘風險數據周邊的高風險實例,并將挖掘的實例反饋給業務校驗,接下來將業務校驗認為有風險的實例添加到原始輸入中,繼續迭代,從而召回更多的風險數據。半監督方法只能挖掘有限有標簽附近的樣例,無法發現特定結構的團伙.
工業界比較知名的基于半監督關系網絡圖上的風險實體挖掘方法有亞馬遜在2018年提出的GraphRAD方法和螞蟻集團在2021年提出的Risk-alike方法,這兩種方法都是基于黑種子節點的輸入在圖上挖掘風險。也可以使用鏈接分析的方法,如PageRank,從已有的有標記的節點出發,計算網絡中其他節點的重要程度。
例如:
Risk_alike
輸入:黑種子節點,所有的邊關系
step1:構圖:基于與黑種子點有2跳以內關聯關系的節點構圖;
step2:用louvain做社區發現得到風險團伙,并對跟團伙有兩跳以內關聯的節點做召回;然后用規則篩選黑節點占比>=40%且節點數量<=200的團伙;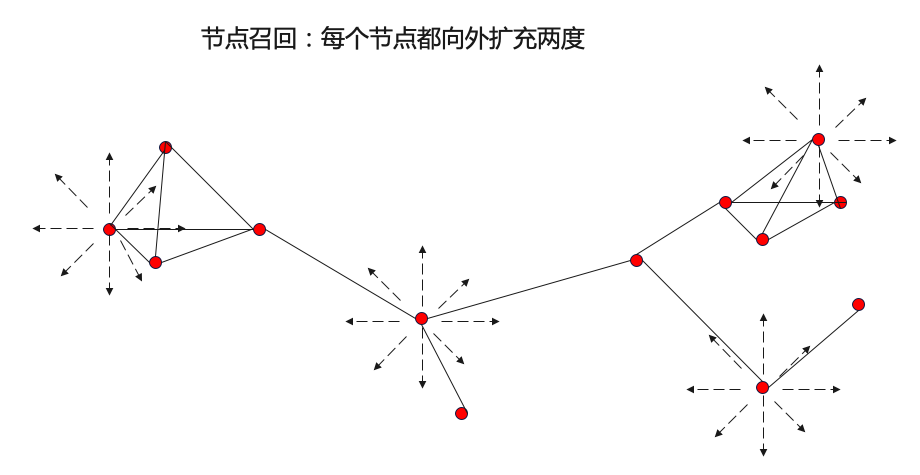
step3:基于pageRank計算每個節點的風險分并排序。從黑種子節點出發,計算每個節點對黑種子節點的重要程度,作為風險分;
step4:提純Purify:基于louvain社區發現的結果和pageRank的結果篩選并輸出挖掘的高風險節點。
輸出:挖掘出的高風險節點,以及對應的風險分數。
阿里云訓練平臺PAI中已內置了Risk-alike、Louvain、LPA、PageRank等反作弊算法,可直接調用即可。最終結果產出:【用戶信息表】注冊賬號、時間等有效信息、【新增】用戶團伙標簽 isbad = true | false
Step3:業務模型的梳理和沉淀
根據對前面業務邏輯的了解,我們設計了多種圖配置的業務模型來做相應的圖構建;
【方案一】 | 【方案二】 | 【方案三】 |
|
|
|
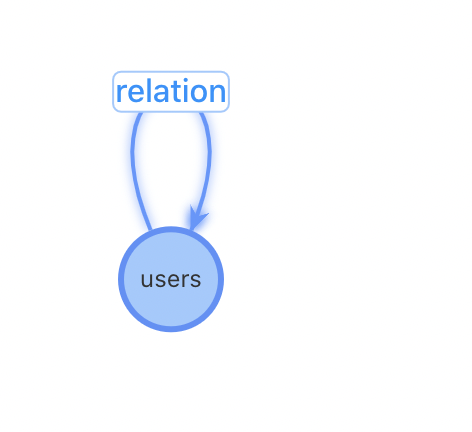
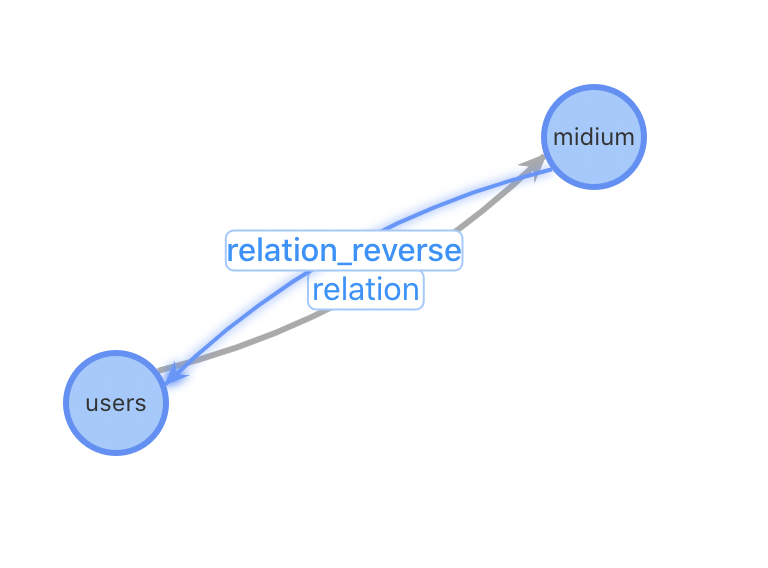
特點:relation異構表 與原始的數據結構最貼近、表配置量過多 | 特點:relation同構表 圖配置簡單,只需要2張表:User用戶表和設備關聯表 | 特點:增加設備作為獨立節點 對于熱門設備的關系變更更加友好 |
問題:設備類型不能靈活增加,設備關系表需要人工添加,不利于擴展性 | 問題:對于插入一個新用戶,需要先進行一(多)次查詢找到相關的用戶關系才能進行插入 | 問題:犧牲一些查詢性能,增加了設備到用戶查詢 |
Step4:業務模型優化方案
基于業務考量,最終業務配置模型選擇了【方案三】來支持,主要的考慮如下:
總結一:進行起點為指定medium類型的快速檢索,通過type類型進行過濾和統計計算更方便
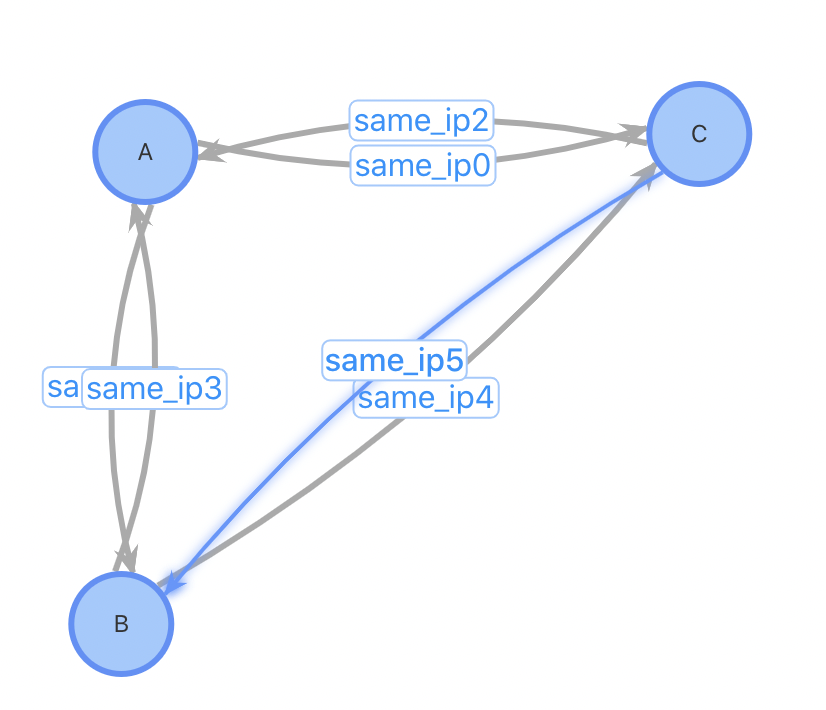
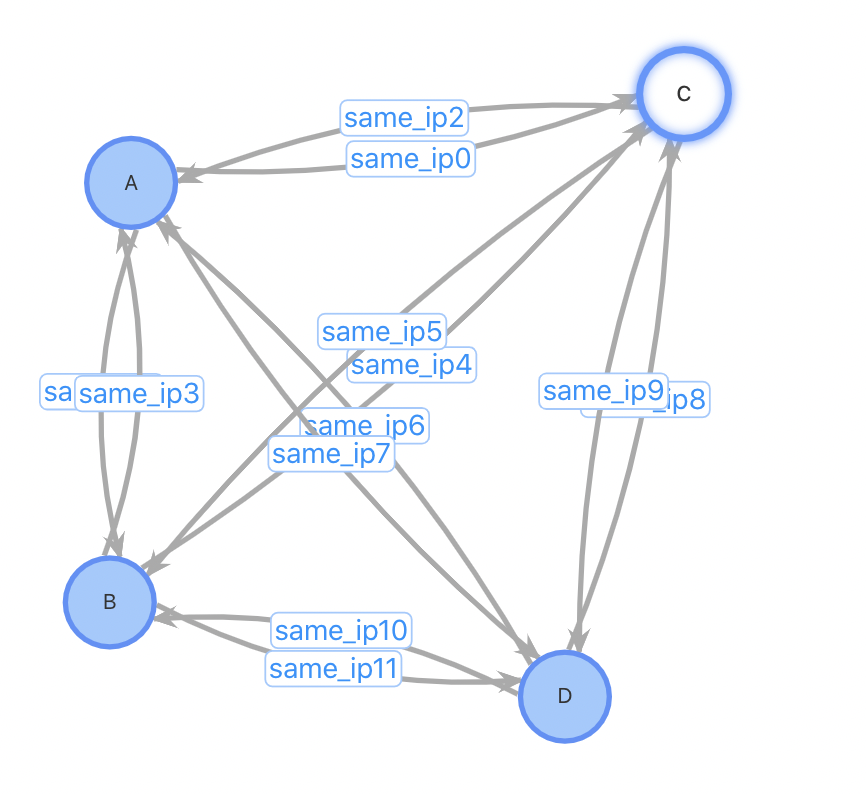
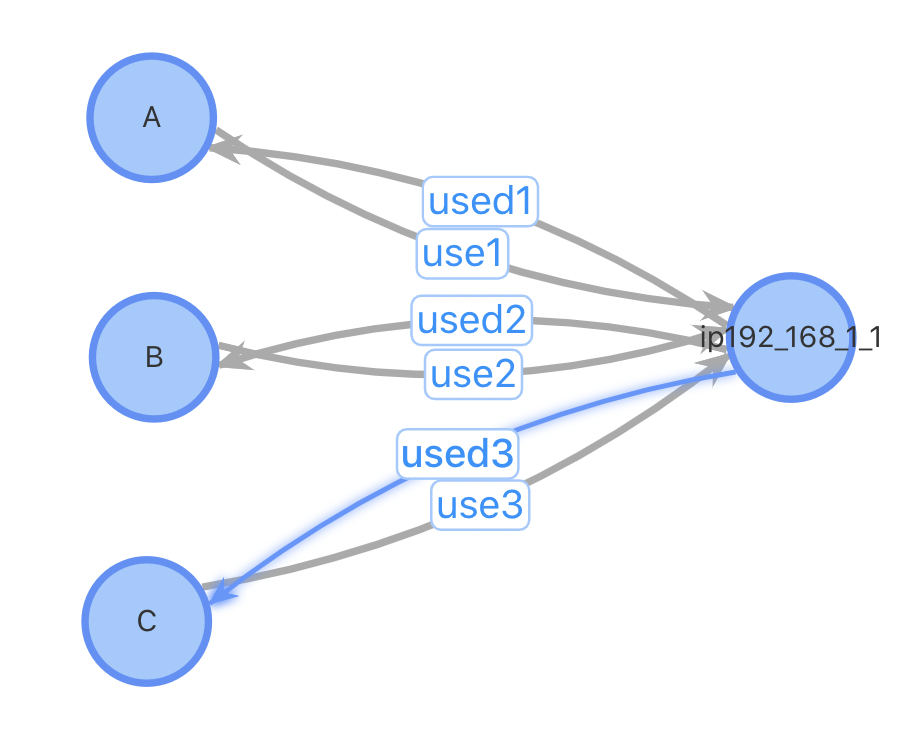
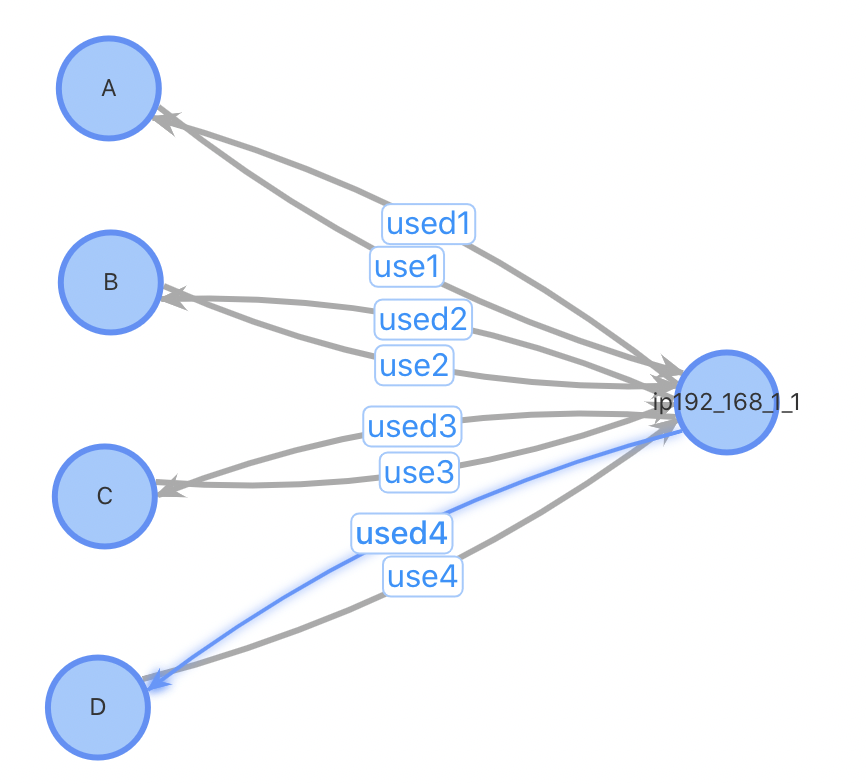
總結二:插入性能優;對于插入一個新用戶,設計1、2需要先進行一(多)次查詢找到相關的用戶關系才能進行插入,設計3不需要這個步驟;設計1、2需要進行一次點插入和多次邊插入,設計3只需1次點插入和2次邊插入。對于某些熱門的IP,一個使用熱門IP的新用戶插入需要插入數萬條邊,對系統的開銷會很大。考慮以下case:插入用戶D,已有3位用戶ABC使用與D相同的IP
方案1、2:插入用戶點D,查詢與D使用同IP的所有用戶,插入邊。插入前,3條點數據,6條邊數據;插入后4個點,12條邊數據
方案3:插入用戶點D,如果該IP不存在表中,插入IP點192.168.1.1,插入用戶D到IP點之間的正反向邊。插入前,4條點數據,6條邊數據;插入后4(5)個點,8條邊數據。
|
|
|
|
主要問題在于犧牲查詢性能:用戶到用戶的跳數從1跳增加到2跳,綜合考慮總結如下:通過【方案三】可以更好的簡化離線更新鏈路的邏輯,同時對于性能影響不會太大。
GraphCompute搭建
Step1:圖模型確定
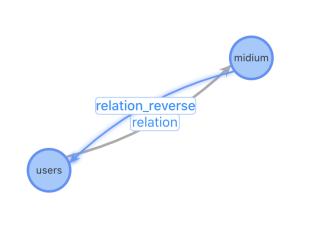
根據前面的業務梳理和沉淀,我們最終按照【方案三】進行圖配置,包括節點表User、medium設備表、relation 用戶設備關系表。
Step2:選擇適合自己的數據源方式
請根據自己的業務特點進行選擇:
已是或者未來需要MaxCompute,源數據托管到MaxCompute,同時業務數據需要做24小時實時計算更新圖數據 - 請參考【方案一:MaxCompute數據源 + API數據】 --- 最佳推薦方式
數據直接托管到圖計算GraphCompute,支持業務數據通過API方式,支持24小時實時數據更新 - 請參考【方案二:API數據源】
已是MaxCompute資深用戶,源數據托管到MaxCompute,每天定時產出MaxCompute分區,無需對圖數據做24小時增量更新 - 可選擇【MaxCompute數據源】
Step3:【黃牛賬號識別】- 創建數據源
當前我們的快速接入采用【方案一:MaxCompute源數據表 + API數據】、【方案二:API數據源】
【方案一:MaxCompute源數據表 + API數據】
該方案依靠MaxCompute已有項目和源表數據。
如果沒有現成的數據,可以選擇直接使用我們提供的Demo數據源(已經定義好了節點和關系數據)。
如果業務數據已經存在CSV或者MaxCompute中,可以選擇自己的MaxCompute源數據。
用戶源表:
使用【igraph_mock.anti_cheating_demo_user_vertex】,節點表中包括100000個用戶,其中有1%的風險賬戶(isbad=TRUE)
可參考的MaxCompute建表語句:
isbad字段可以根據需要添加,用于標示一些已知的黃牛用戶。
根據需要可以加入更多的用戶信息字段,例如名字、性別、注冊時間等以滿足其他業務邏輯的需要。
CREATE TABLE IF NOT EXISTS anti_cheating_demo_user_vertex ( user_id BIGINT COMMENT '用戶賬號id' ,isbad BOOLEAN COMMENT '是否為風險賬號' ) COMMENT '用戶頂點表' PARTITIONED BY (ds STRING COMMENT '日期分區');
媒介表
使用【igraph_mock.anti_cheating_demo_medium_vertex】,關系表中包括100000個媒介,其中0.3%的媒介被超過1個用戶使用。
可參考的MaxCompute建表語句:
常見的medium_type包括電話號碼、郵箱、IP、設備等,本例中只包括電話號碼和郵箱。
weight用于表示媒介的重要性,一般來說同一種設備的weight可以使用同樣的值。例如:多個用戶使用同一IP不需要特定區分。
CREATE TABLE IF NOT EXISTS anti_cheating_demo_medium_vertex ( medium_id BIGINT COMMENT '媒介id' ,medium_type STRING COMMENT '媒介類型' ,weight double COMMENT '權重' ) COMMENT '媒介頂點表' PARTITIONED BY (ds STRING COMMENT '日期分區');
用戶媒介關系表
使用【igraph_mock.anti_cheating_demo_medium_edge】,關系表中包括100000個媒介,其中0.3%的媒介被超過1個用戶使用
可參考的MaxCompute建表語句:
score主要用于表示用戶使用媒介的頻繁程度/重要性,可以根據業務邏輯進行賦值,如沒有特殊業務邏輯可以默認設置為1。
CREATE TABLE IF NOT EXISTS anti_cheating_demo_user_medium_edge
(
user_id BIGINT COMMENT '用戶賬號id'
,medium_id BIGINT COMMENT '媒介id'
,score double COMMENT '權重'
)
COMMENT '用戶媒介關系邊表'
PARTITIONED BY (ds STRING COMMENT '日期分區');【方案二:API數據源】
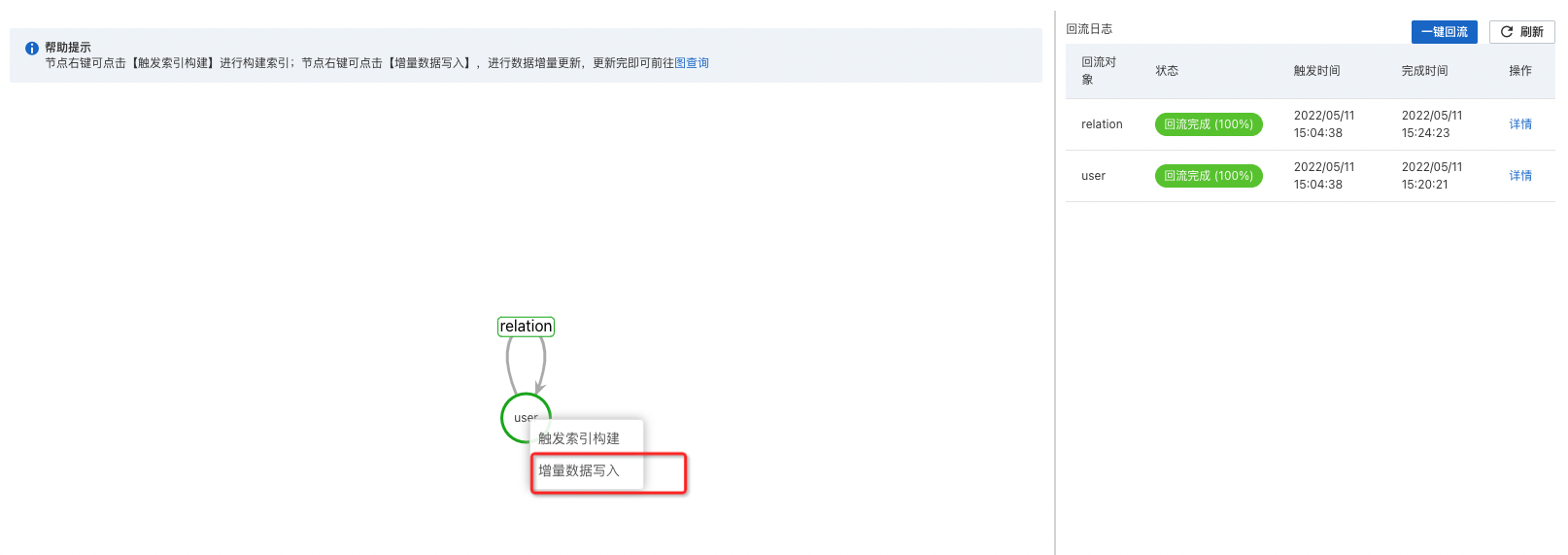
該方案依靠用戶服務端SDK或者控制臺寫入窗口進行數據寫入和更新。
控制臺寫入窗口可參考:【圖運維 - 選擇User、Relation后右鍵 - 增量數據寫入】。
|
|
【MaxCompute源表操作指南】
業務可參看如下步驟自行創建MaxCompute數據表:
在DataWorks創建數據表,每一種點表和邊表需要有一張自己單獨的數據表。
進入DataWorks,左上角選擇數據開發。
進入業務流程->MaxCompute->表,右鍵新建表,并輸入表的名字。
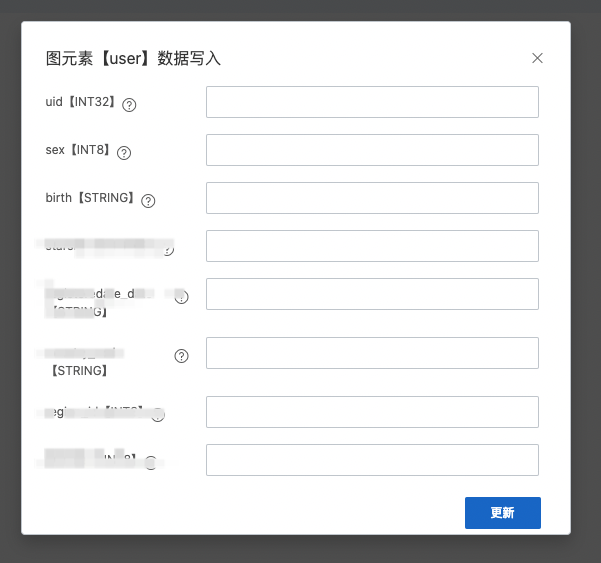
設置表的屬性。
項目名及表名(重要):
不可更改,記下項目名(MaxCompute引擎實例)及表名,需要給圖計算賬號授權。
基本屬性中文名:可以設置表的中文名字和描述。
物理模型設計:
分區類型:請選擇分區表。
生命周期:設置生命周期意味著表的每個分區會保留xx天后被自動刪除,請按照需要勾選 。

表結構設計:請逐列添加表的列屬性,主要包括列名、類型和是否為主鍵。字段類型的選擇請盡量貼合字段本身的屬性(例如:在精度要求不高的情況下使用float代替double類型、對于數字類型的ID使用int類型代替string類型),這樣有助于減少數據表構建索引的大小,節約數據回流生效的時間。
警告注意:圖計算目前字段類型有所限制,僅支持MaxCompute 1.0、2.0的基礎數據類型,不支持復雜類型(ARRAY、MAP、STRUCT),具體字段類型定義及取值范圍請參考2.0數據類型版本。
Step4:【黃牛賬號識別】- 創建圖計算服務
Step4-1:購買實例鏈接
地域:為了減少網絡延遲,請盡可能選擇靠近您的位置。
用戶名/密碼:用于請求時的訪問驗證。
規格:請根據您的數據量及請求的復雜程度選擇規格。
推薦選擇獨享通用型
如果您的業務計算需求較為復雜或對返回性能的要求較高,建議增加分片數
規格參考:
一般百萬級數據量級,可參考如下配置即可。
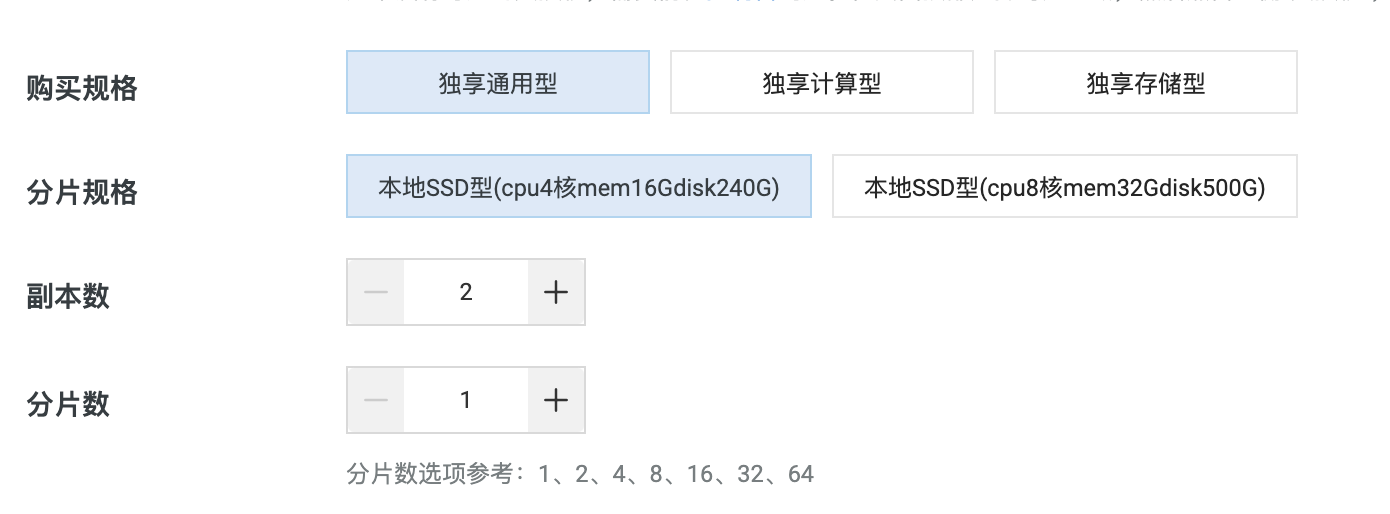
如果數據量過大,可增加【分片數】。
如果線上查詢流量加大,可以增加【副本數】。
購買完畢之后需要等待【15分鐘】實例初始化完畢。
購買活動:企業認證用戶新客首購可以參加免費一個月活動。
Step4-2: 創建業務的圖模型
根據前面【Step1】中已總結完該場景的業務圖模型,我們這里就可以直接創建;在右側列表選擇“圖列表”,并點擊新增,輸入圖的名字及描述。

Step4-3: 創建節點表
創建節點表【User】
左上角選擇“新增點”并輸入點的名稱。
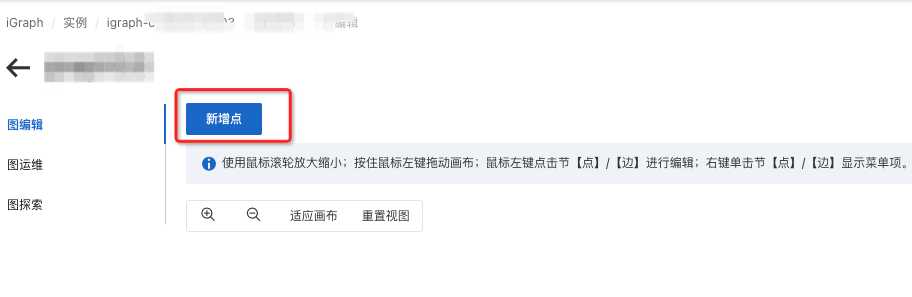
選擇數據來源為【MaxCompute數據源+API更新】
輸入MaxCompute項目名和表名
用戶源表:使用【項目名:igraph_mock,表名:anti_cheating_demo_user_vertex】
點擊【導入字段】會自動為您導入MaxCompute中的對應表字段名及類型映射。
選擇您的pkey并根據字段內的數據調整字段類型,請注意GraphCompute的表類型與MaxCompute有些不同。請盡可能選擇合適的類型int取值范圍(例如:INT8 INT32 INT64),這將大大加速您的請求響應速度。
索引類型:一般直接選擇【KV】
如果您有倒排需求請選擇【inverted INDEX】,并使用"添加索引"增加索引字段,可以提供全局統計和查詢能力,比如需要按照一些屬性做全局查詢:例如「查詢所有風險用戶」等場景。
如果您需要添加額外字段,可以使用“添加字段”。
如果您需要啟用done分區自動回流,請打開掃描DONE分區開關,具體用法詳見done分區指南。
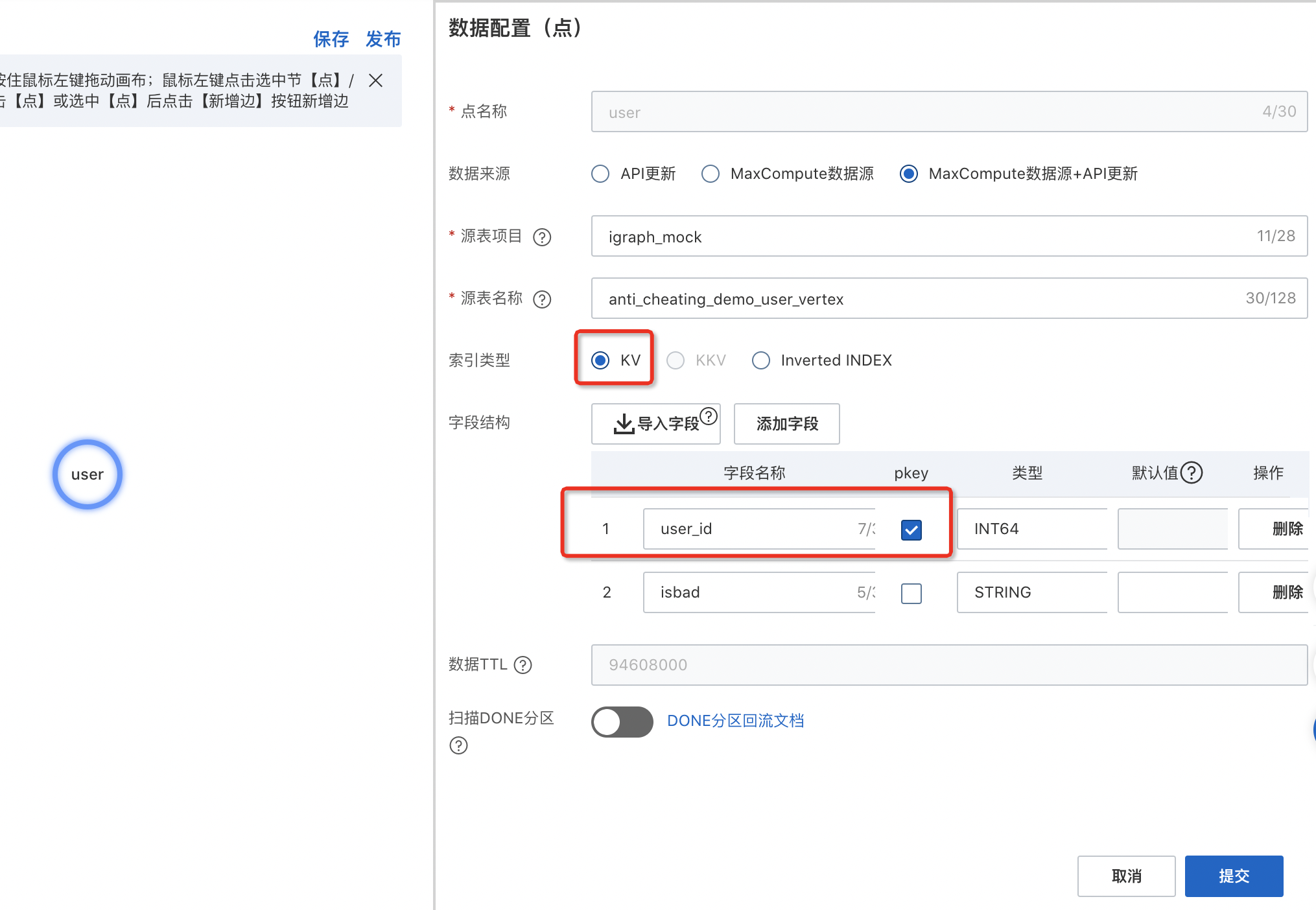
創建節點表【medium】
媒介源表:使用【項目名:igraph_mock,表名:anti_cheating_demo_medium_vertex】
Step4-4:創建關系表
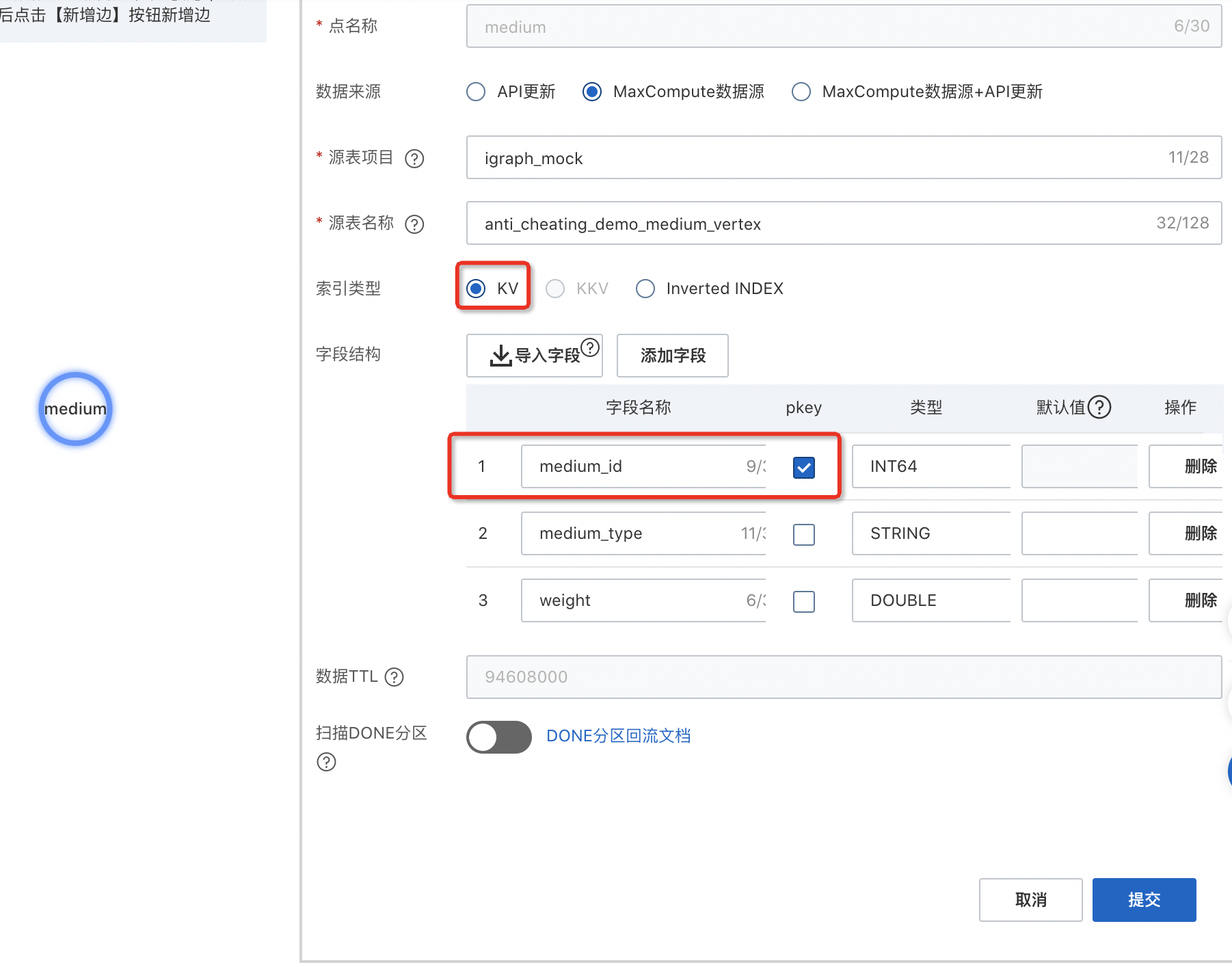
創建用戶到媒介的正向邊
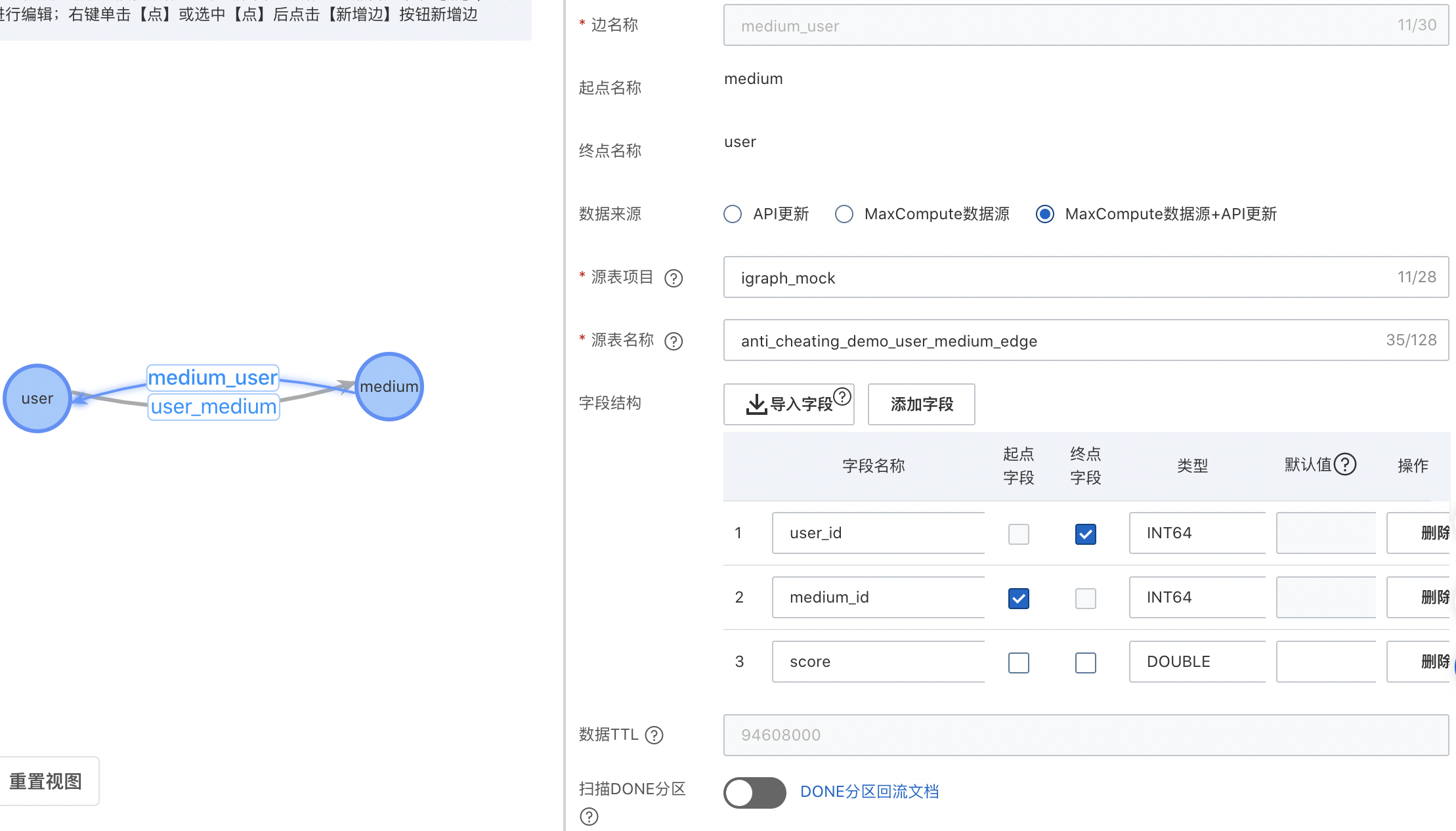
選中user點,鼠標右鍵-彈出【新增邊】,選擇邊的入點并輸入邊的名稱。
選擇數據來源“MaxCompute數據源+API更新”.
輸入項目名+表名并導入字段。
關系源表:使用【項目名:igraph_mock,表名:anti_cheating_demo_user_medium_edge】。
選擇起點字段及終點字段并根據字段內的數據調整字段類型。
pkey起點字段:user_id
skey終點字段:medium_id
如果您需要添加額外字段,可以使用“添加字段”。
如果您需要啟用done分區自動回流,請打開掃描DONE分區開關,具體用法詳見done分區指南。
單擊提交。
創建媒介到用戶的反向邊
選擇數據來源“MaxCompute數據源+API更新”。
輸入項目名+表名并導入字段。
關系源表:使用【項目名:igraph_mock,表名:anti_cheating_demo_user_medium_edge】。
選擇起點字段及終點字段并根據字段內的數據調整字段類型。
pkey起點字段:medium_id
skey終點字段:user_id
Step4-5:圖模型發布
節點User表 、設備medium 和關系Relation表創建號,即可依次點擊【保存】、【發布】。

Step4-6: 數據索引構建
圖模型發布完成后就可以進行圖計算的索引構建工作,點擊【一鍵回流】功能即可觸發海量數據的索引構建。
分區選擇:根據業務數據需要,自行選擇一個可用分區。
增量時間戳:數據切換上線時,回追增量數據的起始時間。
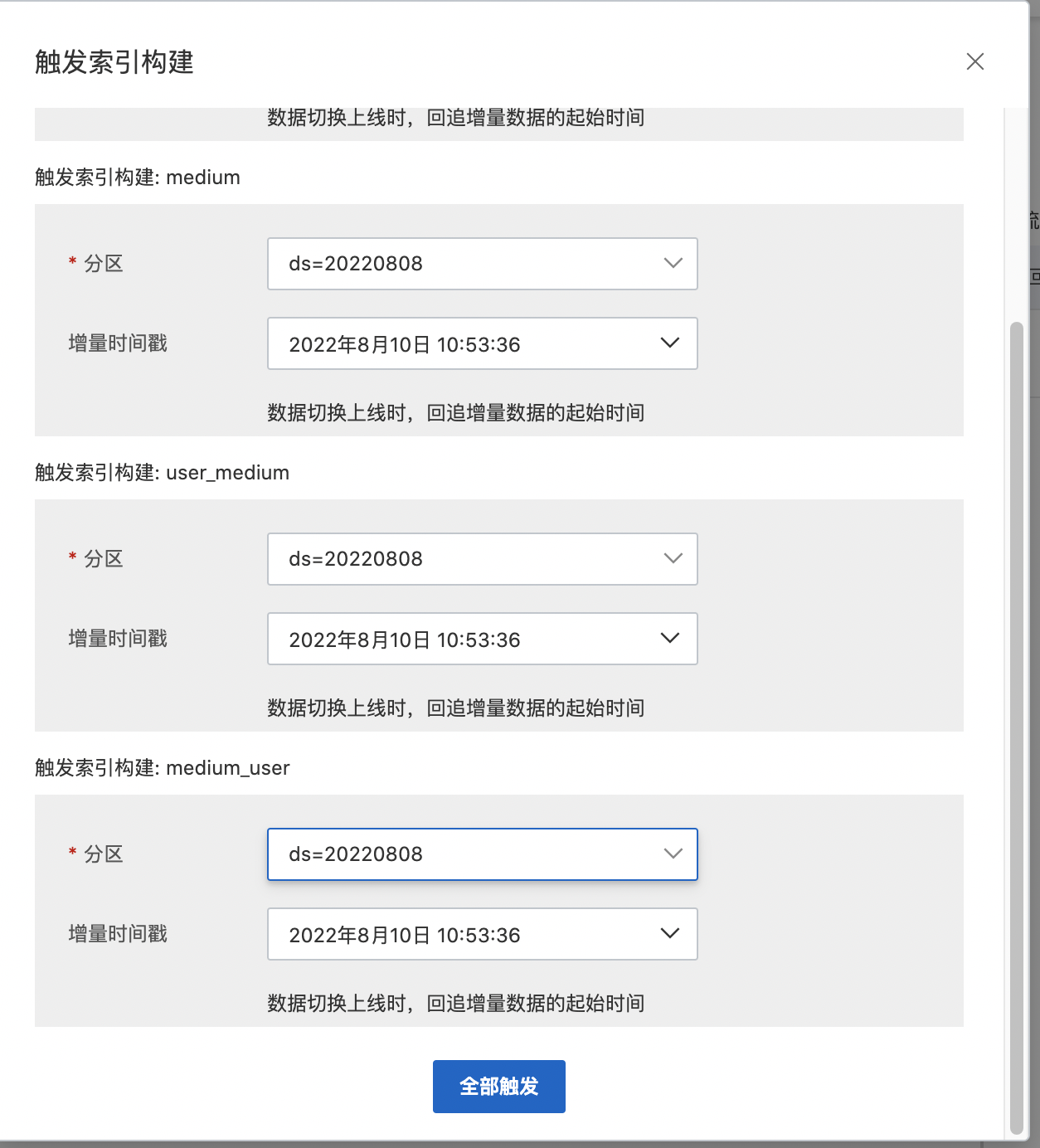
數據索引構建的耗時主要決定于數據量級的大小,一般百萬級數據量,需要等待15-20分鐘即可完成。通過【圖運維】中圖模型的節點和關系都綠色即可進行判斷。

Step4-7: 判定賬戶風險
通過團伙大小等相關業務邏輯進行判定。
GraphCompute查詢
通過前面的步驟,圖計算應用及數據已經準備完成,下面就可以進行圖數據的查詢和分析;可以通過【圖探索】-進行探索式交互或者控制臺Gremlin語句查詢。
|
|
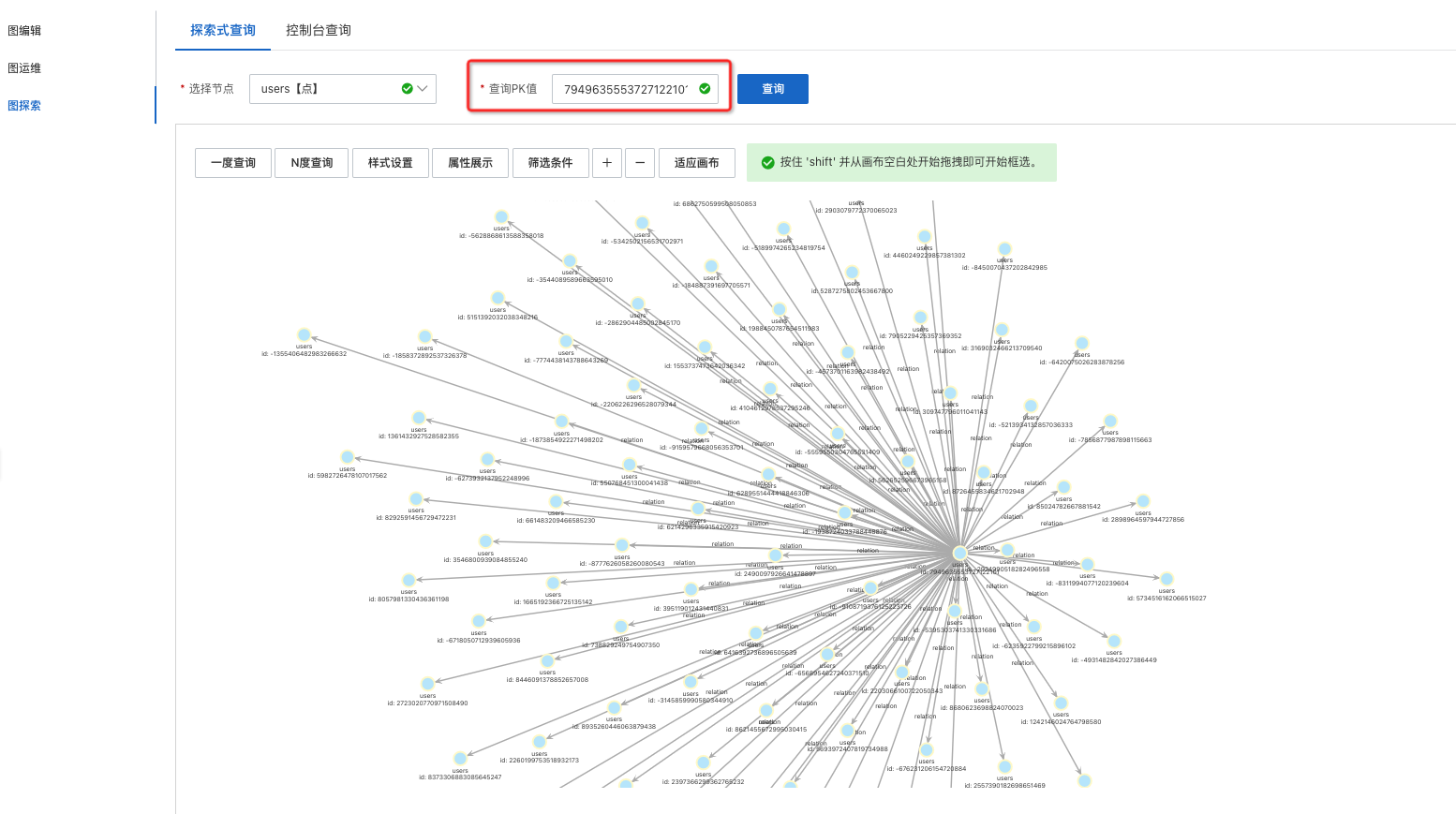
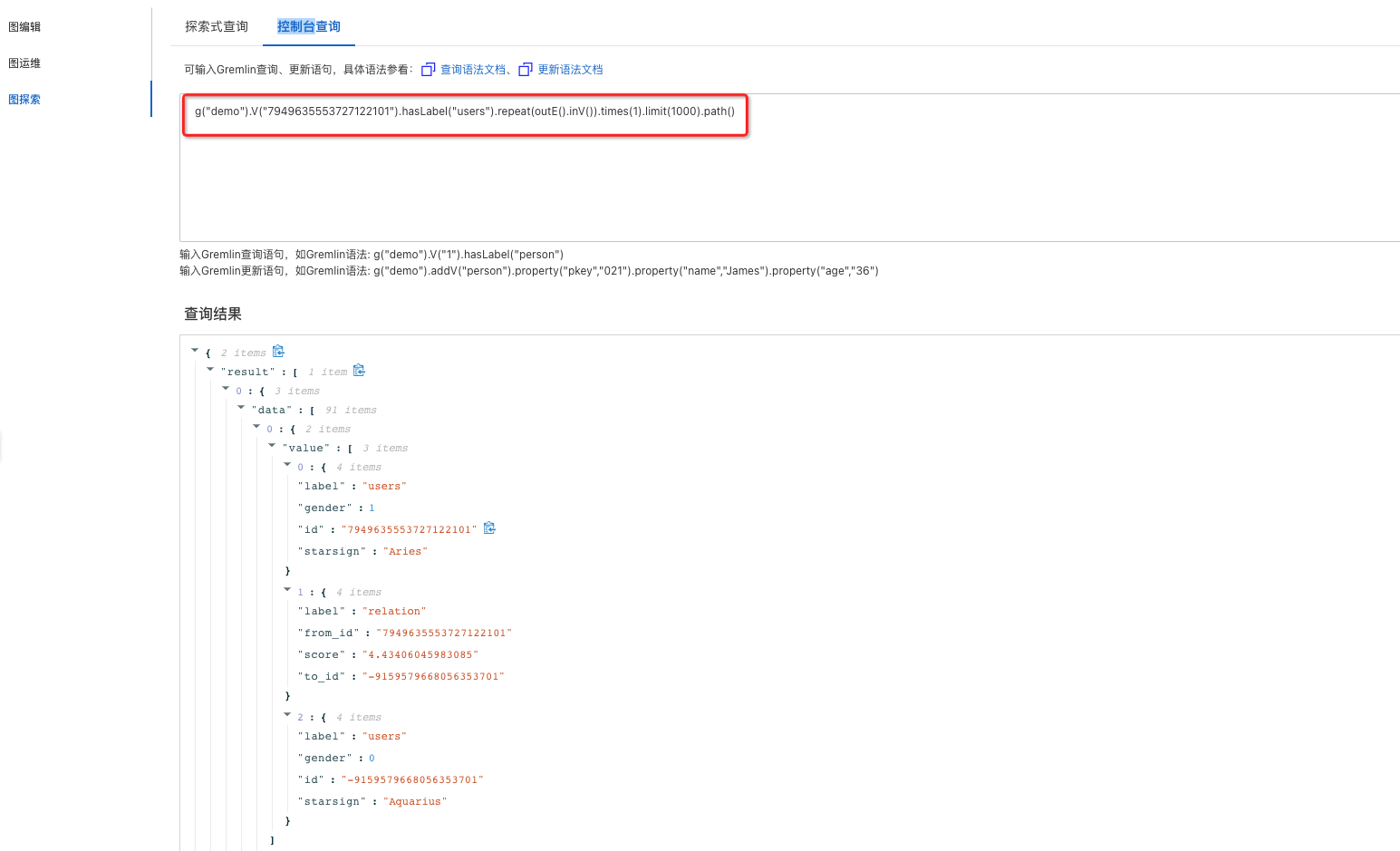
查詢用例
直接查詢
//查詢某個用戶的信息判斷是否為風險用戶
g("anti_cheating").V("-889411487137524591").hasLabel("user")
間接查詢
//查詢某個媒介關聯到風險用戶的個數
g("anti_cheating").V("-3161643561846490971").hasLabel("medium")
.outE().inV()
.filter("isbad=\"true\"").count()
//查詢與某用戶使用相同媒介的風險用戶個數
g("anti_cheating").V("-189711352665847917").hasLabel("user").
.outE().outE().inV()
.filter("isbad=\"true\"").count()
使用權重進行枝剪
//對于部分超級媒介可能同時有數十萬用戶使用,例如某高校的ip,
//此時建議使用sample(n).by("score"),隨機選擇n條關聯用戶進行檢查,按照score字段分越高,越有可能被選取到
g("anti_cheating").V("-189711352665847917").hasLabel("user").
.outE().sample(10).by("score").outE().inV()
.filter("isbad=\"true\"").count()
使用權重計算風險得分
g("anti_cheating").withSack(supplier(normal,"0.0"),Splitter.identity,Operator.sum).
V("2532895489060363835").hasLabel("user").outE().sack(Operator.assign).by("to_double(score)").
inV().sack(Operator.mult).by("to_double(weight)").outE().inV()
.filter("isbad=\"true\"").barrier().sack()【GraphCompute】技術價值
當前市面上有很多不同類型的圖產品可以選擇,而且每種產品都有獨特的優勢;根據各個行業的企業和場景不一樣,業務需要了解產品的差異能力,這樣對于選擇性更有目的性;GraphCompute超強的實時寫性能,專攻海量圖數據存儲和快速查詢;通過引擎索引和算子優化邏輯,極好的保障圖查詢的穩定性;數據限制邏輯、自研算子、數據導入有極強的容錯機制,重復輸入做最新數據的覆蓋;一站式智能運維能力,既提供復雜分布式圖引擎能力,也簡化了用戶的運維成本。
圖計算服務的方案優勢:
1、低成本
圖計算Proxy-Search多行架構讓集群負載更高,提高資源利用率,節省機器資源50%;同時集群負載QPS更高1倍。
2、高性能
節點拆分、多種kkv類型,在數據構建時已經將數據進行分類、同時提供可定制的截斷邏輯保證查詢性能;iGraph在熱點key的處理經驗豐富,多級cache 能夠比較好的防御這類問題,同時可以支持動態擴容等;相比開源方案,查詢耗時性能RT降低100%~500%
3、秒級百萬更新能力
在風控領域中,OneID- 同人防控能力是通常金融、互聯網企業都需要和建設的風控規則,需要實時判定用戶是否違規。該類場景需要:整體數據更新量龐大,同時對圖數據的查詢性能要求較高,聚焦OLTP能力;GraphCompute通過最終一致性方案能夠保證單節點百萬QPS更新量,生效時間在1-2s,保證風控數據的實效性到秒級,從而提升識別準確率;
4、數倉一體化對接能力
離線處理平臺對接,風控安全業務都會由算法、數據團隊建設完整的大數據分析,基于阿里云MaxCompute數倉,我們能夠無縫對接數據源,同時支持數倉快速迭代,將數倉全量數據的迭代周期最快從T天級到小時級別。