集群吞吐性能測試
本文介紹集群在順序?qū)憽㈨樞蜃x、隨機讀等方面的性能測試方法。
注意事項
性能測試前,請注意以下事項。
吞吐最大不會超過ECS帶寬。如果您的ECS帶寬只有1.5 Gbps,則吞吐最高可達(dá)到187.5 MB/s。
文件存儲 HDFS 版的吞吐能力和購買的存儲空間相關(guān)。
測試集群吞吐性能所使用的TestDFSIO是一個分布式任務(wù),存在任務(wù)調(diào)度及結(jié)果匯總階段,計算集群吞吐均值時會略低于文件存儲 HDFS 版吞吐限速。
在進(jìn)行順序讀與隨機讀的測試之前需要確保文件存儲 HDFS 版之上已有指定的待測數(shù)據(jù),如果沒有待測數(shù)據(jù)請使用順序?qū)懴壬纱郎y數(shù)據(jù)再進(jìn)行順序讀與隨機讀的測試。
測試環(huán)境
配置名稱 | 配置說明 |
計算VM配置 | CPU核數(shù):4核 |
內(nèi)存:16 GB | |
機器數(shù)量:6臺 | |
網(wǎng)絡(luò)帶寬:1.5 Gbps | |
文件存儲 HDFS 版配置 | 實例大小:10 TB |
吞吐限速:1000 MB/s | |
軟件配置 | Apache Hadoop:Hadoop 2.7.6 |
測試工具
TestDFSIO是Hadoop系統(tǒng)自帶的基準(zhǔn)測試組件,用于測試DFS的IO吞吐性能。
TestDFSIO的jar包位于開源Hadoop版本的${HADOOP_HOME}/share/hadoop/mapreduce目錄下,其中${HADOOP_HOME}為測試機器中的Hadoop安裝目錄,jar包名為hadoop-mapreduce-client-jobclient-x.x.x-tests.jar。
本文所有命令均在 ${HADOOP_HOME}/bin 目錄下執(zhí)行。
您可通過執(zhí)行以下命令,查看TestDFSIO的使用方法
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.6-tests.jar TestDFSIO順序?qū)懶阅軠y試
預(yù)估值:1000 MB/s
將文件寫入到文件存儲 HDFS 版。
將500個大小為4 GB的文件按順序?qū)懭氲?span id="50bb5d1027rmk" outputclass="productName" data-tag="ph" data-ref-searchable="yes" data-reuse-tag="productName" data-type="productName" data-product-code="dfs" docid="3761036" data-source="reuse_library" class="ph productName">文件存儲 HDFS 版,讀寫數(shù)據(jù)的緩存大小為8 MB,并將統(tǒng)計數(shù)據(jù)寫入 /tmp/TestDFSIOwrite.log中。
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.6-tests.jar TestDFSIO -write -nrFiles 500 -size 4GB -bufferSize 8388608 -resFile /tmp/TestDFSIOwrite.log執(zhí)行以下命令查看文件存儲 HDFS 版已寫入的文件數(shù)量及大小。
./hadoop fs -count -q -h /benchmarks/TestDFSIO/io_data執(zhí)行以下命令查看生成的統(tǒng)計信息文件。
cat /tmp/TestDFSIOwrite.log測試結(jié)果如下所示。
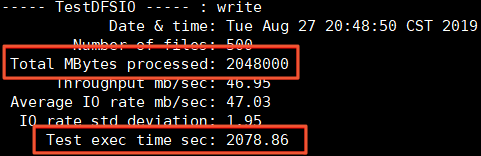
Total MBytes processed:寫入的文件的總大小。
Test exec time sec:消耗的時長。
計算集群吞吐。
您可以通過以下兩種方式計算集群吞吐。
通過統(tǒng)計信息文件計算吞吐。
集群的吞吐約為Total MBytes processed / Test exec time sec = 985.16 MB/s
通過ECS監(jiān)控的帶寬流出速率,計算集群吞吐。
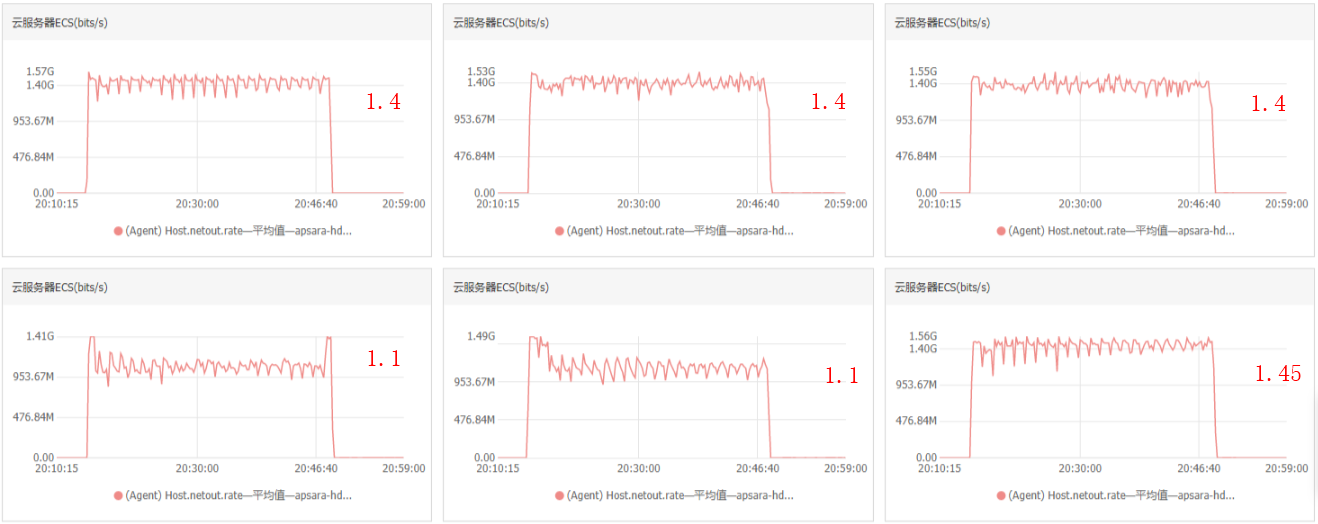
進(jìn)行順序?qū)憰r集群中每個節(jié)點的帶寬流出速率大約為1.4 Gb/s、1.4 Gb/s、1.4 Gb/s、1.1 Gb/s、1.1 Gb/s、1.45 Gb/s。
集群吞吐=(1.4+1.4+1.4+1.1+1.1+1.45)*1000÷8=981.25 MB/s
順序讀性能測試
預(yù)估值:1000 MB/s
按順序讀取文件存儲 HDFS 版上的文件。
順序讀取文件存儲 HDFS 版上面500個大小為4 GB的文件,讀寫數(shù)據(jù)的緩存大小為8 MB,并將統(tǒng)計數(shù)據(jù)寫入/tmp/TestDFSIOread.log中。
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.6-tests.jar TestDFSIO -read -nrFiles 500 -size 4GB -bufferSize 8388608 -resFile /tmp/TestDFSIOread.log執(zhí)行以下命令查看生成的統(tǒng)計信息文件。
cat /tmp/TestDFSIOread.log測試結(jié)果如下所示。
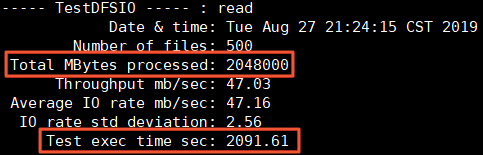
Total MBytes processed:寫入的文件的總大小。
Test exec time sec:消耗的時長。
計算集群吞吐。
您可以通過以下兩種方式計算集群吞吐。
通過統(tǒng)計信息文件計算吞吐。
集群的吞吐約為Total MBytes processed / Test exec time sec = 989.15 MB/s
通過ECS監(jiān)控的帶寬流入速率,計算集群吞吐。
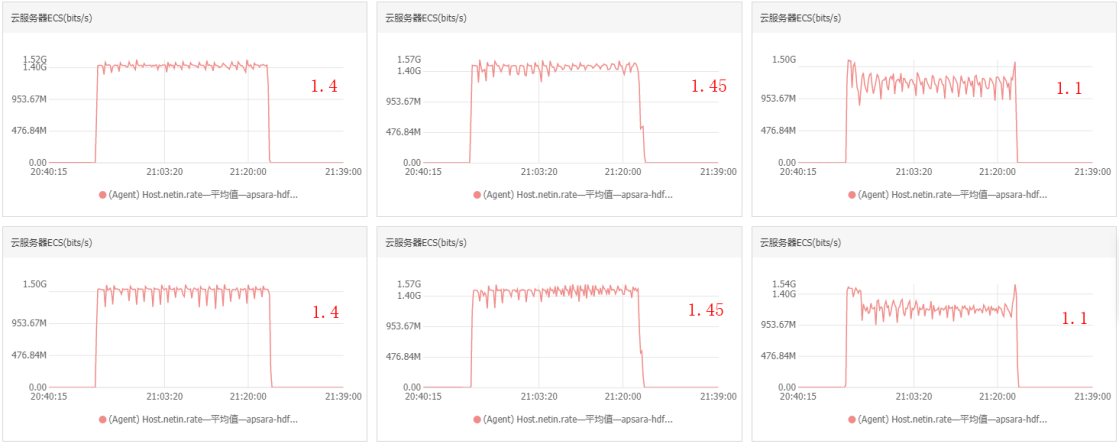
進(jìn)行順序讀時集群中每個節(jié)點的帶寬流入速率大約為1.4 Gb/s,1.45 Gb/s,1.1 Gb/s,1.4 Gb/s,1.45 Gb/s,1.1 Gb/s
集群吞吐=(1.4+1.45+1.1+1.4+1.45+1.1)*1000÷8=987.5 MB/s
隨機讀性能測試
預(yù)估值:1000 MB/s
隨機讀取文件存儲 HDFS 版上的文件。
隨機讀取文件存儲 HDFS 版上面的大小為1 GB的500個文件,讀寫數(shù)據(jù)的緩存大小為8 MB,并將統(tǒng)計數(shù)據(jù)寫入/tmp/TestDFSIOrandomread.log中。
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.6-tests.jar TestDFSIO -read -random -nrFiles 500 -size 1GB -bufferSize 8388608 -resFile /tmp/TestDFSIOrandomread.log執(zhí)行以下命令查看生成的統(tǒng)計信息文件。
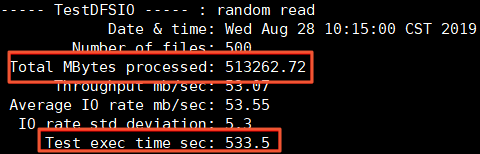
cat /tmp/TestDFSIOrandomread.log測試結(jié)果如下所示。
Total MBytes processed:寫入的文件的總大小。
Test exec time sec:消耗的時長。
計算集群吞吐。
您可以通過以下兩種方式計算集群吞吐。
通過統(tǒng)計信息文件計算吞吐。
集群的吞吐約為Total MBytes processed / Test exec time sec = 962.07 MB/s
通過ECS監(jiān)控的帶寬流入速率,計算集群吞吐。
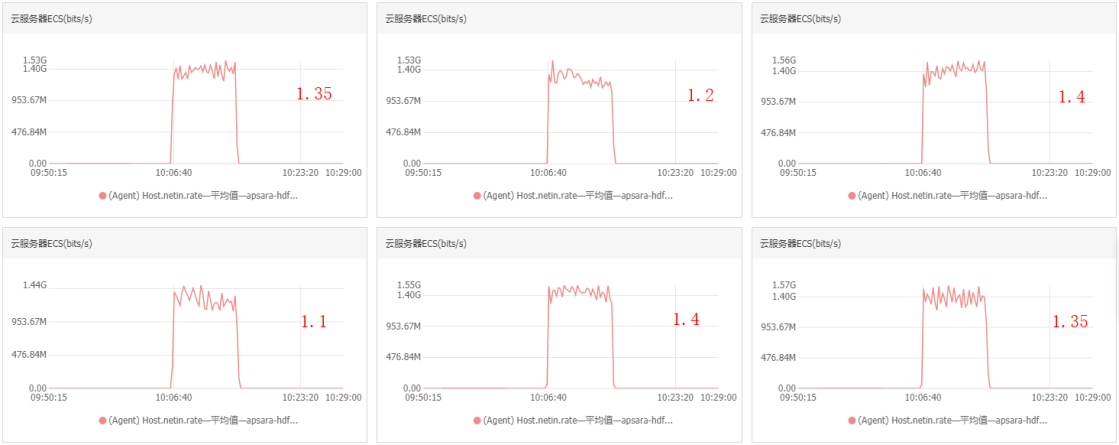
進(jìn)行隨機讀時集群中每個節(jié)點的帶寬流入速率大約為1.35 Gb/s,1.2 Gb/s,1.4 Gb/s,1.1 Gb/s,1.4 Gb/s,1.35 Gb/s
集群吞吐=(1.35+1.2+1.4+1.1+1.4+1.35)*1000÷8=975 MB/s