Hologres推出了聲明式數據處理架構Dynamic Table,該架構可以自動處理并存儲一個或者多個基表(Base Table)對象的數據聚合結果,內置不同的數據刷新策略,業務可以根據需求設置不同的數據刷新策略,實現數據從基表對象到Dynamic Table的自動流轉,滿足業務統一開發、數據自動流轉、處理時效性等訴求。
背景信息
在實時數倉場景中,通常會涉及到復雜的業務處理,例如多表關聯查詢、大表聚合查詢等,針對不同場景,業務在時效性方面也有不同的需求:
風控、推薦等純實時場景(實時場景):需要秒級/毫秒級出結果。
實時報表、BI看數等場景(近實時場景):時效性可以允許分鐘級延遲。
定期報表、查歷史數據等場景(離線場景):查詢頻率較低,時效性可以允許小時級延遲。
同時業務之間也會有關聯查詢的訴求,需要嚴格保證數據口徑一致性。
為了滿足業務資源成本、開發效率及業務時效性等需求,業界做了比較多的架構研究演進,例如早期的Lambda架構、流批一體架構等,雖然解決了部分業務/開發問題,但還存在以下問題:
架構上:目前市面上的產品通過相互組合的解決方案,來支持不同業務場景不同時效性的業務訴求。不能在一個產品里滿足所有業務訴求。
數據加工上(ETL):從明細層到應用層,實時數倉沒有明確的方法論,無法做到更低成本的數據自動流動,資源成本高、開發效率低。
基于上述背景,Hologres重磅推出Dynamic Table,支持全量、增量的數據處理模式,實現更高效、更低成本的數據自動流動與分層。通過Dynamic Table,結合Hologres本身特性,能夠統一存儲層、統一計算層、統一數據服務層,滿足開發效率、時效性等需求。
Dynamic Table的優勢
簡化數倉架構
Dynamic Table多種刷新模式可實現不同級別的時延,滿足業務不同時效性的查詢訴求,再基于Hologres的統一存儲(存儲實時數據、離線數據),直接賦能業務OLAP查詢、在線服務、AI與大模型等多個應用場景的查詢訴求,有效簡化數倉架構,節約開發、運維成本。
自動數倉分層
Dynamic Table可以自動刷新數據,實現數據從ODS>DWD>DWS>ADS的自動數據流轉,提升數倉分層體驗。
提升數據處理(ETL)效率
Dynamic Table支持全量刷新和增量刷新,滿足業務的不同時效性處理需求。對于增量刷新,只處理增量數據,減少ETL計算數據量,顯著提升數據處理效率。
簡化開發維護
Dynamic Table自動管理刷新任務,以及數據之間的層級和依賴關系,簡化繁瑣的開發運維流程,提升開發效率。

基本概念
基表(Base Table)
Dynamic Table中數據來源的基表,可以是一張表(內部表或外部表),也可以是多個表關聯。不同的刷新模式,支持的基表類型不同。詳情請參見Dynamic Table支持范圍和限制。
Query
創建Dynamic Table時指定的Query,是指對基表數據的處理Query,相當于ETL過程。不同的刷新模式支持的Query類型不同,詳情請參見Dynamic Table支持范圍和限制。
刷新(Refresh)
當基表中的數據發生變化時,需要通過刷新(Refresh)Dynamic Table以更新數據的變動。Dynamic Table會根據設置的刷新開始時間和刷新間隔,自動在后臺運行刷新任務,對刷新任務的觀測和運維詳情請參見運維Dynamic Table刷新任務。
技術原理
基表中的數據根據Dynamic Table中Query定義的數據處理流程,通過刷新的方式寫入Dynamic Table。以下將從刷新模式、計算資源、數據存儲及表索引四個方面介紹Dynamic Table的部分技術原理。
刷新模式
當前Dynamic Table支持兩種刷新模式,即全量刷新(Full)和增量刷新(Incremental),根據設置的刷新模式不同,Dynamic Table的技術原理也有所差異。
全量刷新(Full)
全量刷新是指每次執行刷新時,都以全量的方式進行數據處理,并將基表的聚合結果物化寫入Dynamic Table,其技術原理類似于INSERT OVERWRITE的相關原理。
增量刷新(Incremental)
增量刷新模式下,每次刷新時只會讀取基表中新增的數據,根據中間聚合狀態和增量數據計算最終結果并更新到Dynamic Table中。相比全量刷新,增量刷新每次處理的數據量更少,效率更高,從而可以非常有效地提升刷新任務的時效性,同時降低計算資源的使用。
技術原理
創建了增量刷新的Dynamic Table后,系統會在底層創建一個列存的狀態表(State表),用于存儲Query的中間聚合狀態,引擎在編碼、存儲等方面對中間聚合狀態進行了優化,可以加快對中間聚合狀態的讀取和更新。增量數據會以微批次方式做內存態的聚合,再與狀態表中的數據進行合并,然后以BulkLoad的方式將最新聚合結果高效地寫入Dynamic Table。微批次的增量處理方式減少了單次刷新的數據處理量,顯著提升了計算的時效性。
注意事項
增量刷新模式支持的基表存在一定的限制,詳情請參見Dynamic Table支持范圍和限制。
增量刷新需要基表開啟Binlog,以此感知基表的數據變化,詳情請參見訂閱Hologres Binlog。
增量刷新內置的狀態表會占用一定的存儲,系統會設置TTL定期清理數據,您可以使用函數查看狀態表的存儲大小,詳情請參見狀態表(State)管理。
計算資源
執行刷新任務的計算資源可以是本實例的資源或者Serverless資源:
本實例資源:刷新任務將會使用本實例的資源運行,與實例中的其他任務共享資源,高峰期可能會出現資源爭搶現象。
Serverless資源(默認):默認會將刷新任務通過Serverless方式執行,如果Query比較復雜,處理的數據量較多,通過Serverless方式可以有效地提升刷新任務的穩定性,避免本實例內多任務間的資源爭搶,同時也可以對單個刷新任務修改計算資源,以便更合理地使用Serverless資源。
數據存儲
Dynamic Table在數據存儲方面與普通表一致,默認使用熱存儲模式。為了減少存儲成本,也可以將查詢頻率較低的數據設置為冷存儲,有效降低成本。
表索引
業務在查詢時,可以直接查詢Dynamic Table,相當于直接查詢聚合結果,這樣可以顯著提升查詢性能。同時,Dynamic Table也如同普通表,支持設置表索引,如行存/列存、Distribution Key、Clustering Key等,通常情況下,引擎會根據Dynamic Table的Query推導出合適的索引,如業務有進一步的調優需求,可以重新為其設置合適的索引,以進一步提升查詢性能。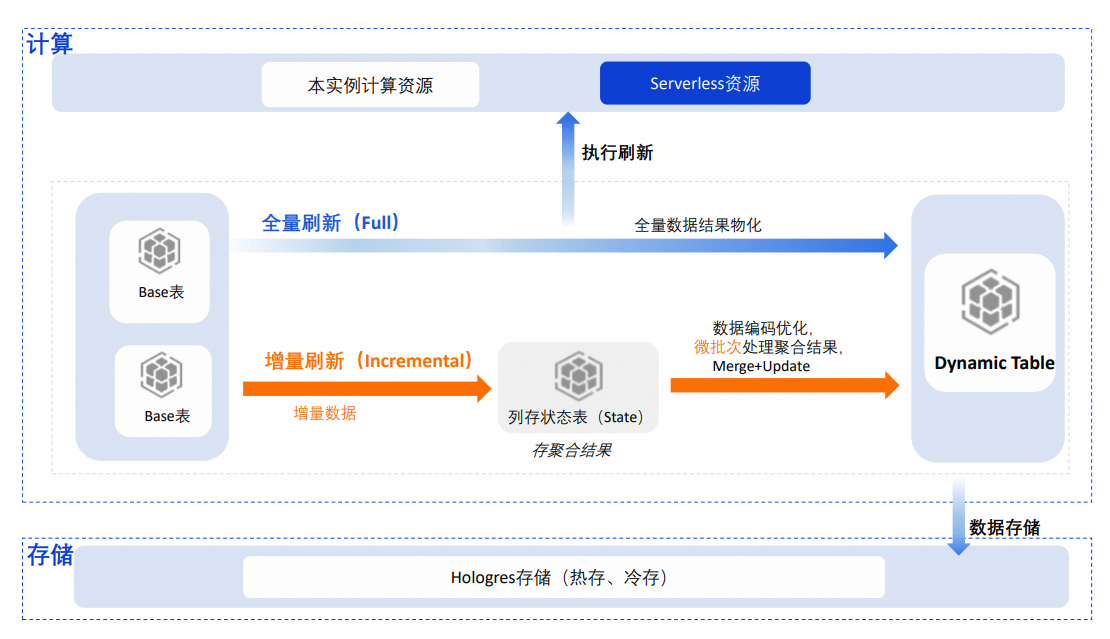
與物化視圖對比
Dynamic Table VS Hologres實時物化視圖
Hologres在V1.3版本推出了SQL管理物化視圖,但是支持的能力相對較弱,與Dynamic Table的差異如下:
功能分類 | Hologres Dynamic Table | Hologres實時物化視圖 |
基表類型 |
| 單內表 |
基表操作 |
| 僅支持append寫入 |
刷新原理 | 異步刷新(全量刷新、增量刷新) | 同步刷新 |
刷新時效性 |
| 實時 |
Query類型 |
說明 不同的刷新模式,支持的Query類型不同,詳情請參見Dynamic Table支持范圍和限制。 | 有限算子支持(AGG、RB函數等) |
查詢模式 | 直接查Dynamic Table |
|
Dynamic Table VS 異步物化視圖
當前市面上,與Dynamic Table功能類似的有OLAP產品的異步物化視圖、Snowflake的Dynamic Table等,其差別如下:
功能分類 | Hologres Dynamic Table | OALP產品異步物化視圖 | Snowflake Dynamic Table |
基表類型 |
說明 不同的刷新模式,支持的Query類型不同,詳情請參見Dynamic Table支持范圍和限制。 |
|
|
刷新模式 |
|
|
|
刷新時效性 |
| 小時級 |
|
Query類型 |
說明 不同的刷新模式,支持的Query類型不同,詳情請參見Dynamic Table支持范圍和限制。 |
|
|
查詢模式 | 直接查Dynamic Table |
| 直接查Dynamic Table |
觀測/運維 |
| 豐富的監控指標 | 可視化界面 |
使用場景
Dynamic Table可以自動完成數據加工和存儲,通過Dynamic Table,可以加速數據查詢,提升業務時效性,推薦您在湖倉加速和數倉分層場景中使用。
湖倉加速
Dynamic Table的基表數據可以來源于Hologres表,也可以來源于數據倉庫,例如MaxCompute、數據湖OSS、Paimon等,通過對基表數據的全量/增量刷新,滿足不同時效性的數據查詢探索需求。推薦的使用場景包括:
定期報表查詢
對于周期性觀測的相關場景,例如周期性報表等,如果數據量較少或者Query不復雜,可以使用全量刷新或者增量刷新的模式,周期性地將湖倉數據的聚合分析結果刷新至Dynamic Table,應用側直接查詢Dynamic Table獲取分析結果,加速報表查詢。
實時大屏/報表
對于實時大屏和實時報表等場景,數據的時效性要求更高,推薦使用增量刷新的模式,將湖Paimon或者實時數據的聚合分析結果刷新至Dynamic Table,以此來加速對實時數據的處理,應用側直接查詢Dynamic Table獲取數據分析結果,達到近實時分析的目的。

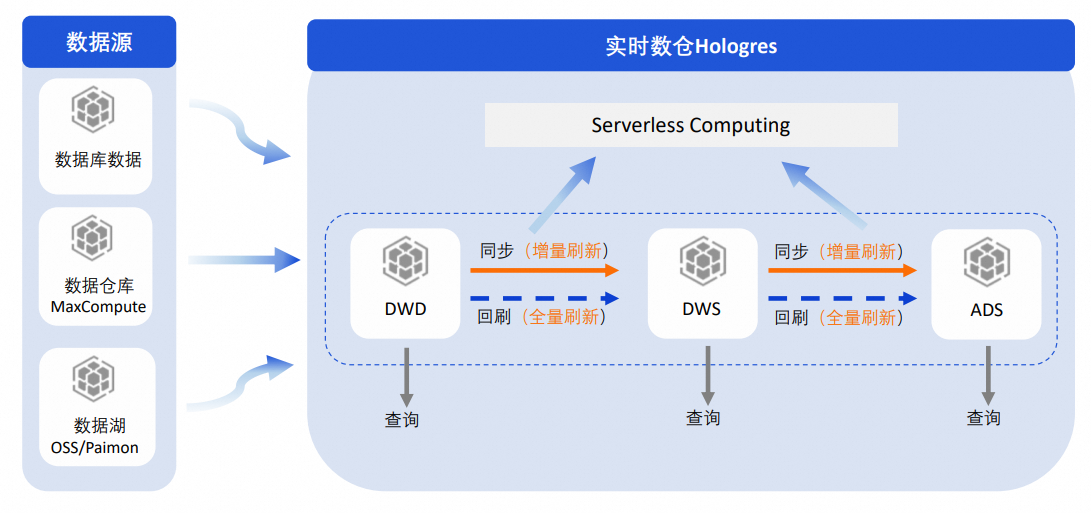
數倉分層
如果基表中有大量數據,需要進行復雜的ETL處理來滿足業務的時效性需求,常見的做法就是數倉分層。對于實時數倉,業界在數倉分層上的方案較多,例如使用物化視圖、周期性調度等,這些方案雖然能解決一部分問題,但也都存在數據時效性、開發不便捷等問題。而Hologres Dynamic Table本身就具備數據自動處理的能力,因此可以通過Dynamic Table方便地實現數倉分層。
推薦做法如下:
可以在Hologres中通過Dynamic Table構建數倉分層DWD>DWS>ADS:
每一層之間的數據同步使用增量刷新模式,這樣可以確保每一層處理的數據量更少,減少不必要的重復計算,提升同步速度。也可以根據業務情況,將刷新任務提交到Serverless Computing執行,進一步提升刷新的時效性和穩定性。
如果要對每一層的數據進行回刷,可以使用全量刷新模式執行一次刷新,以此來保證每一層數據口徑的一致性。同樣也可以根據業務情況,將刷新任務提交到Serverless Computing執行,進一步提升刷新的時效性和穩定性。
每一層都在Hologres中構建,數倉分層明確,每一層都可以根據業務情況提供查詢,保證數據的可見性、復用性。
通過Hologres Dynamic Table方案即可完成數據加工+應用的場景,顯著提升數倉開發、運維效率。