FineBI是帆軟軟件有限公司推出的一款商業智能(Business Intelligence)產品。FineBI自助分析以業務需求為方向,通過便捷的數據處理和管控,提供自由的探索分析。本文為您介紹FineBI如何連接Hologres進行可視化分析。
連接Hologres
安裝FineBI。
安裝FineBI,詳細步驟請參見FineBI官方文檔。
安裝JDBC驅動。
請前往PostgreSQL官網下載JDBC驅動。
說明請您下載并使用42.2.18以上版本的JDBC驅動。
您需要將下載的PostgreSQL的JDBC驅動包放置于<FineBI安裝目錄>\webapps\webroot\WEB-INF\lib目錄下,并重啟FineBI。
連接Hologres。
使用管理員賬號登錄FineBI,選擇。
單擊新建數據連接,在所有頁簽下選擇Hologres。
說明如您的FineBI版本低于5.1.14,也可以使用PostgreSQL數據源連接Hologres。

在Hologres頁面配置連接信息。
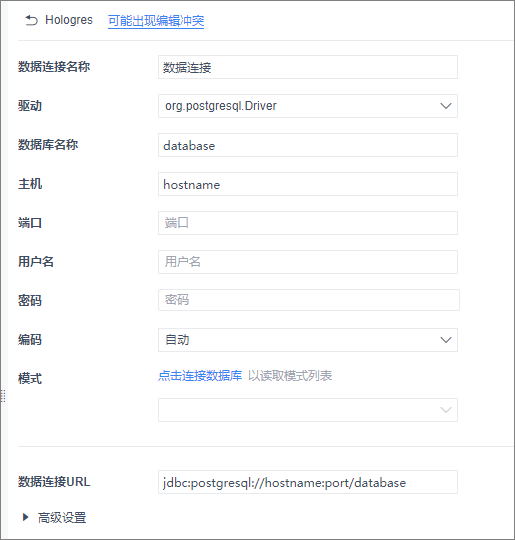
具體參數說明如下:
參數
說明
數據連接名稱
您可以輸入數據連接的名稱。如Hologres。
驅動
驅動選擇
org.postgresql.Driver。數據庫名稱
Hologres的數據庫名稱。
主機
Hologres實例的公共網絡地址。您可以進入Hologres管理控制臺的實例詳情頁,從網絡信息區域獲取網絡地址。
端口
Hologres的實例端口。您可以進入Hologres管理控制臺的實例詳情頁,從網絡信息區域獲取實例端口。
用戶名
當前阿里云賬號的AccessKey ID。獲取方式請參見創建訪問密鑰。
密碼
當前阿里云賬號的AccessKey Secret。獲取方式請參見創建訪問密鑰。
數據連接URL
數據連接URL,填寫格式為
jdbc:postgresql://<host>:<port>/<databasename>,其中各參數解釋如下所示:host:主機,Hologres實例的公共網絡地址。
port:端口,Hologres實例的端口。
databasename:數據庫名稱,Hologres創建的數據庫名稱。
高級設置
該示例不涉及高級設置。如業務涉及配置,更多內容請參見FineBI官方文檔。
配置完以上參數,在頁面中單擊點擊連接數據庫,讀取模式列表并從下拉列表中選擇您需要使用的Schema。
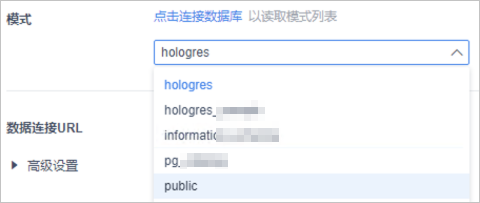
單擊頁面右上角的測試連接,如果提示連接成功表示FineBI能夠正常連接Hologres數據庫。
單擊頁面右上角的保存,完成數據連接的配置。
添加數據表。
在左側導航欄單擊數據準備,進入數據列表頁。
單擊進入目標業務包詳情頁,單擊添加表。
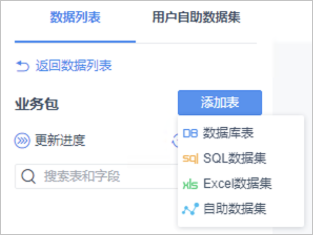
您可以使用數據庫表、SQL數據集等方式從Hologres中加載數據,此處以數據庫表為例獲取數據表信息。單擊數據庫表進入數據庫選表頁面,可以選擇已創建的數據連接,右側會列出數據連接的數據庫對應Schema中的所有數據表。

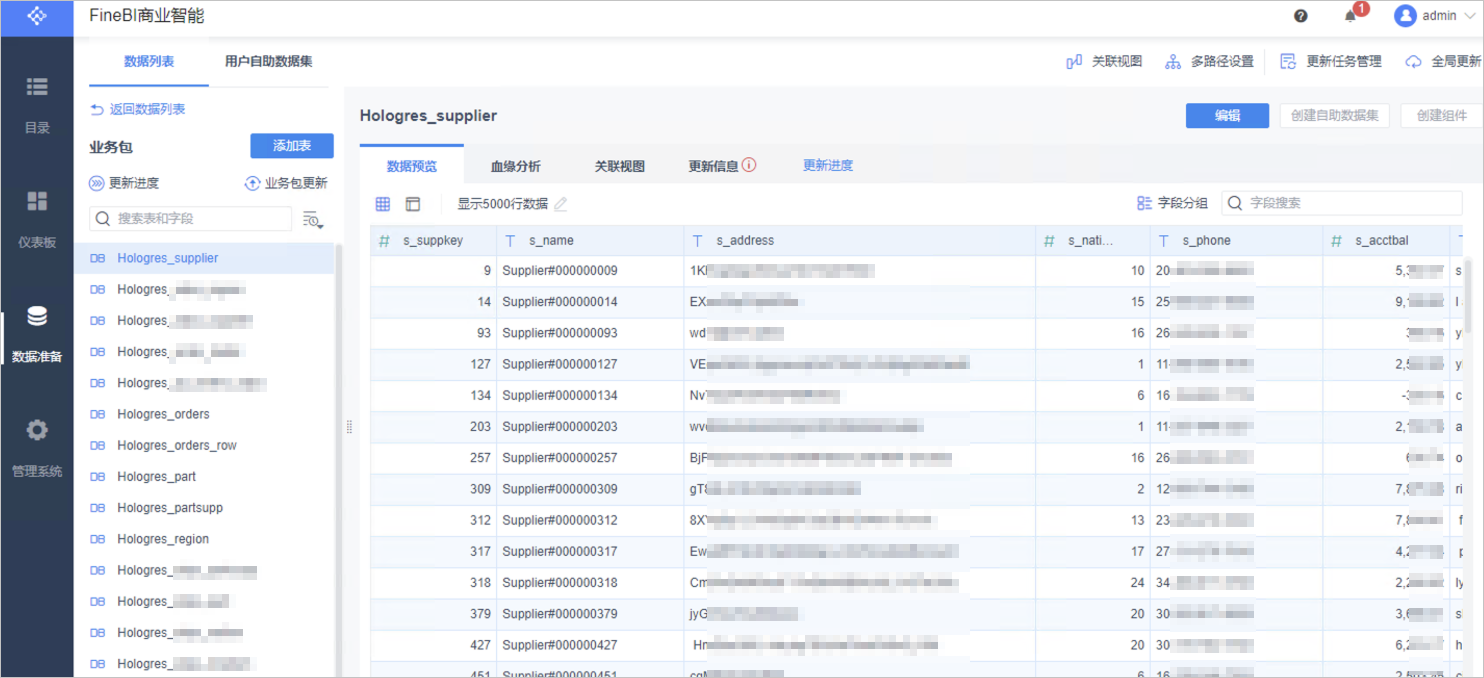
選擇需要加載的數據表,單擊頁面右上角的確定,FineBI即會加載選中的數據表,已添加的表灰化不可選擇。
加載完成后,您可以在目標業務包的數據列表中選擇具體的數據表,進行數據準備的相關操作。
數據分析。
當您完成數據表的加載操作后,您可以利用這些數據表進行數據可視化相關操作,更多操作指導請參見FineBI官方文檔。
時間篩選控件最佳實踐
在Hologres創建表時,我們可以設置Segment_key(別名event_time_column)屬性,對時間類型過濾條件進行索引優化,防止全表掃描,能夠加速查詢。Hologres默認把表中第一個時間戳類型作為Segment_key。
您可以通過創建帶參數的SQL數據集,當您的SQL的執行計劃中有Segment Filter關鍵字出現時,即表示Segment_key已經生效,您可以使用帶參數的SQL數據集創建的時間控件。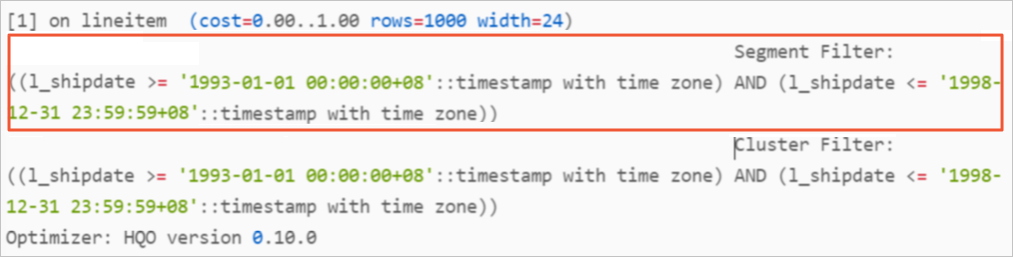
創建帶參數的SQL數據集具體步驟如下:
登錄FineBI,在左側導航欄單擊數據準備,進入數據列表頁。
單擊進入目標業務包詳情頁,單擊添加表,選擇SQL數據集。
說明FineBI支持帶參數的數據集,詳細的功能介紹,請參見FineBI官方文檔。
您可以根據文檔描述的帶參數的SQL數據集功能,使用參數來設置日期控件。
在表名處填寫表名,并在SQL語句模塊填寫如下SQL。單擊刷新,系統可自動識別參數,您可以手動選擇參數類型,單擊頁面右上角的確定保存數據集。
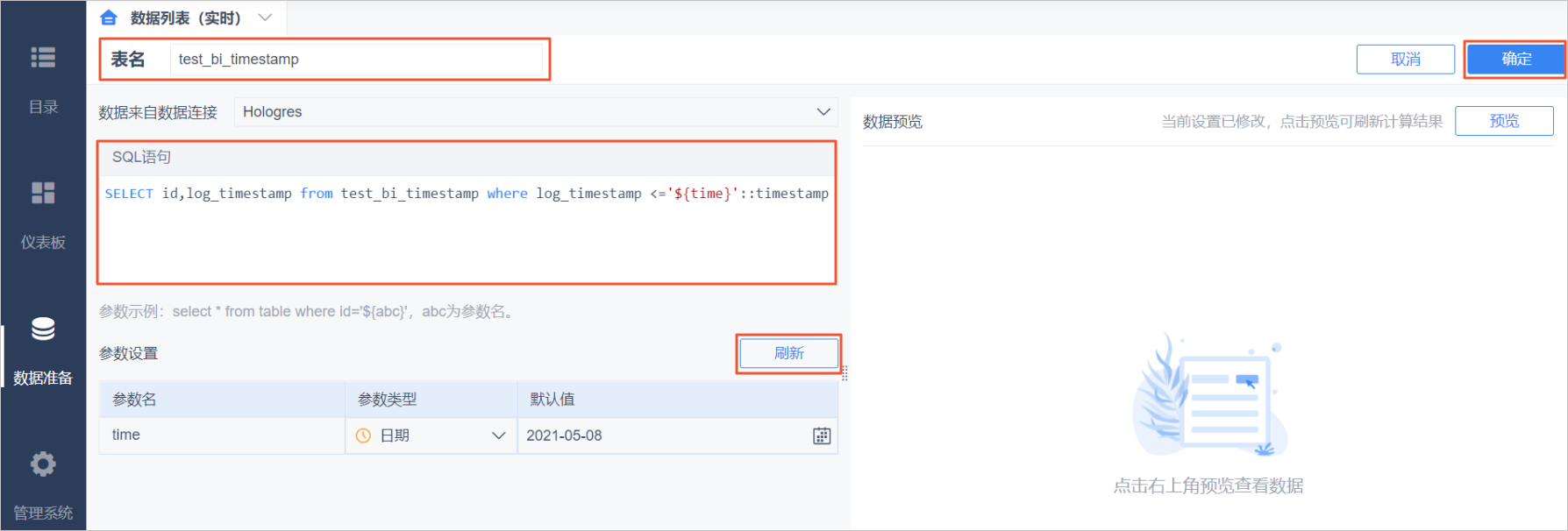
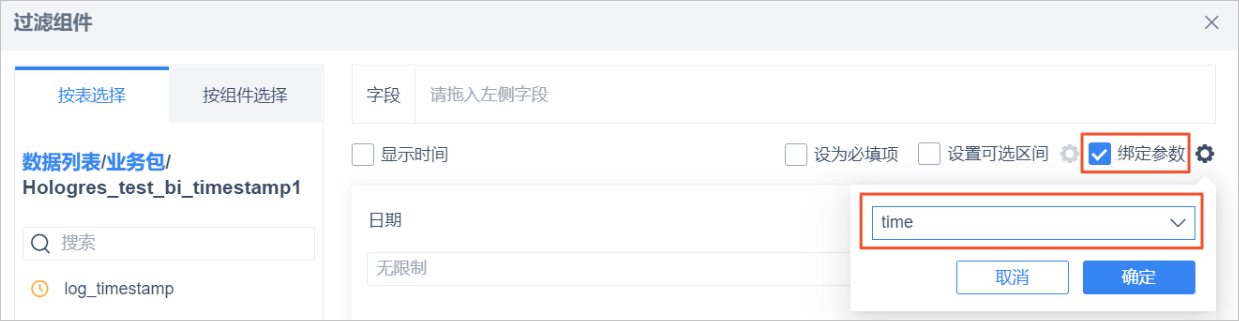
SELECT id, log_timestamp from test_bi_timestamp where log_timestamp <='${time}'::timestamp;在儀表盤中選擇日期控件,選中綁定參數,從列表中選擇time后單擊確定。
在頁面設置日期并進行過濾。
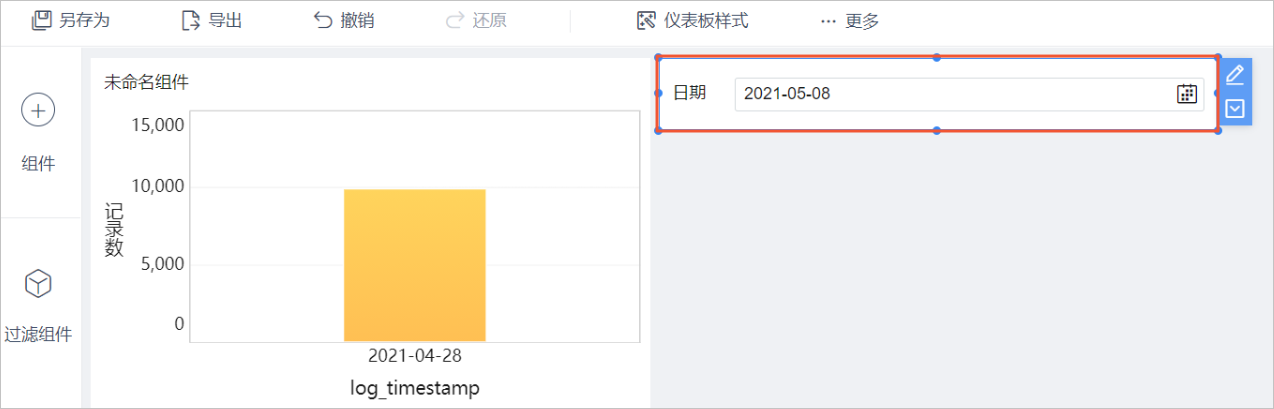
設置完成后,您可以通過日志查看執行的SQL。查看日志具體操作,請參見FineBI官方文檔。
生成的SQL如下所示:
select "T_13E5C8"."id" as "id", "T_13E5C8"."log_timestamp" as "log_timestamp" from ( select id, log_timestamp from test_bi_timestamp where log_timestamp <='2021-05-08'::timestamp ) as "T_13E5C8" limit 5000;生成的執行計劃具體如下:
Limit (cost=0.00..0.15 rows=1000 width=16) -> Gather Motion (cost=0.00..0.14 rows=1000 width=16) -> Limit (cost=0.00..0.10 rows=1000 width=16) -> Parallelism (Gather Exchange) (cost=0.00..0.10 rows=1000 width=16) -> DecodeNode (cost=0.00..0.10 rows=1000 width=16) -> Limit (cost=0.00..0.10 rows=1000 width=16) -> Index Scan using holo_index:[1] on test_bi_timestamp (cost=0.00..1.00 rows=1000 width=16) Segment Filter: (log_timestamp <= '2021-05-08 00:00:00+08'::timestamp with time zone) Optimizer: HQO version 0.8.0 (9 行記錄)當您SQL的執行計劃中有Segment Filter關鍵字出現時,即表示Segment_key已經生效,您可以使用帶參數的SQL數據集創建的時間控件。