本文將為您介紹在Hologres中Shard級別的Replication使用。
功能概述
從Hologres V1.1版本開始,支持通過設置Table Group副本數的方式來提高某個Table Group查詢并發能力和可用性。您可以在創建Table Group的時候通過顯式指定的replica count或者修改已有的replica count來打開Replication的功能。新增的副本屬于內存級別的運行時副本,不會增加額外存儲成本。
關于replica count的說明具體如下:
數據是按Shard分布的,不同Shard管理不同的數據,不同Shard之間的數據沒有重復,所有的Shard在一起是一份完整的數據。
默認情況下每一個Shard只有一個副本,即
replica count = 1,其對應的屬性為leader。您可以通過調整replica count的值,使相同的數據有多個副本,其他副本的屬性為follower。寫請求由Leader Shard負責,讀請求會均衡由多個Follower Shard(也包含leader Shard)共同服務。當使用Follower Shard查詢時,數據可能會出現10~20ms級別延遲。
replica count默認值是1,表示不啟用Replication。大于1表示開啟Replication,replica count數字越大,對資源的消耗也越大。由于Replica布局具有反親和特性,即多個replica不可以布局在同一個計算節點上,因此replica count參數應小于等于計算節點數。從Hologres V1.3.53版本開始,replica count上限為worker個數,如若超過則會報錯。有關不同規格擁有的計算節點數,參考實例規格概述。
考慮到計算節點計算力的均衡性,在增加Replication時,應該同步縮小shard_count,保持
shard_count * replica count = 默認實例推薦shard數時,具備最好的性能。Hologres從V1.3.45版本開始,支持查詢高可用。
若您發現您的實例監控信息頁面出現了類似如下圖的情況:
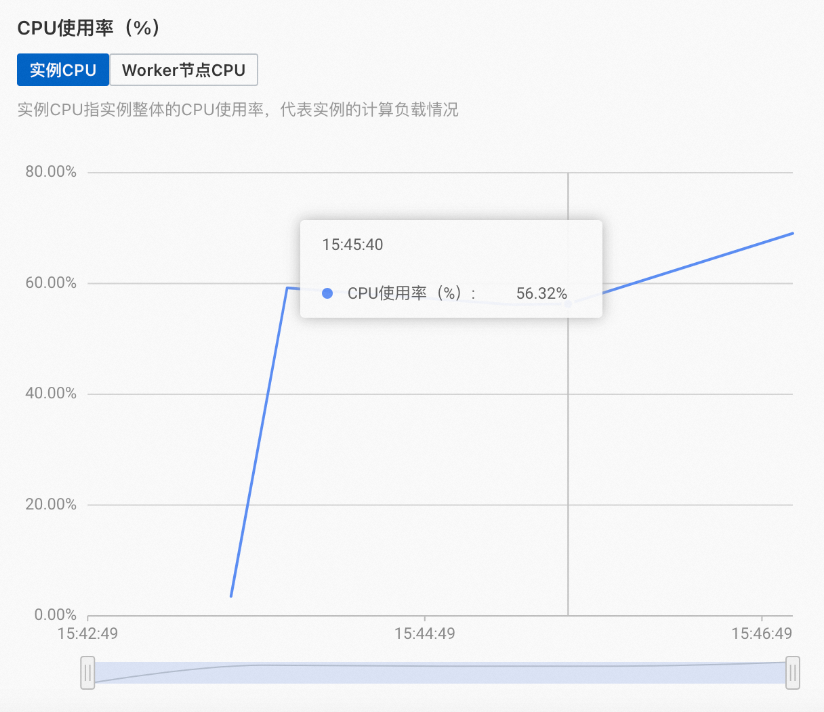
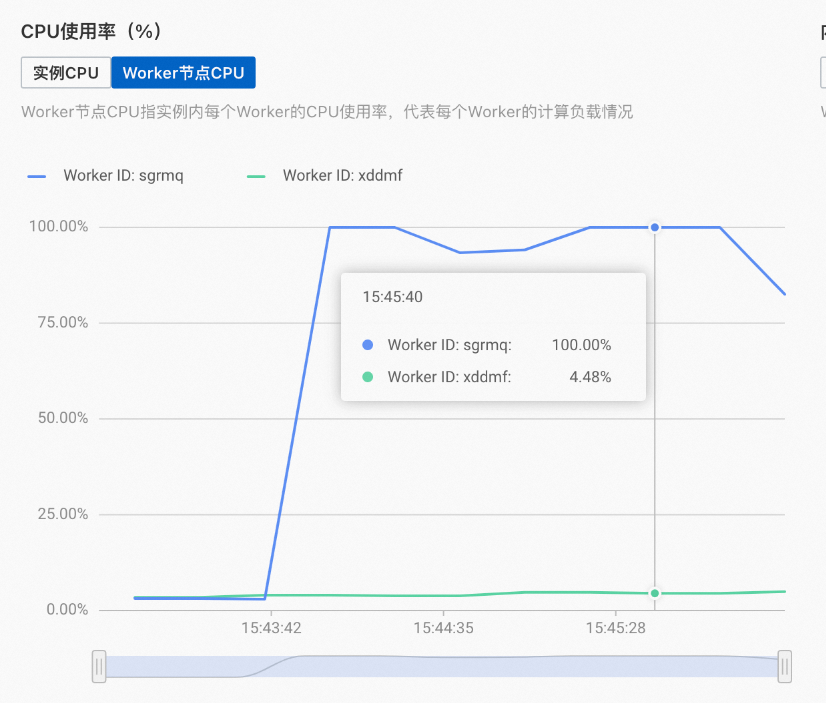
實例整體資源利用率不高,但是僅有小部分Worker計算資源使用率很高,其他Worker計算資源利用率很低,那么有可能是查詢不均導致的,即大部分的查詢僅用了其中幾個Shard回答查詢,此時您可以增加Shard的副本數量,讓更多的Worker上有Shard的副本,該操作可以有效提高資源利用率和QPS。
說明Leader Shard和Follower Shard之間同步元數據需要消耗一定的資源,且副本數越多,消耗的資源越多。所以若非定位到是因為查詢不均導致資源使用不均衡,否則不建議使用該方式提升QPS。
同時Leader Shard和Follower Shard會存在毫秒級的數據延遲。
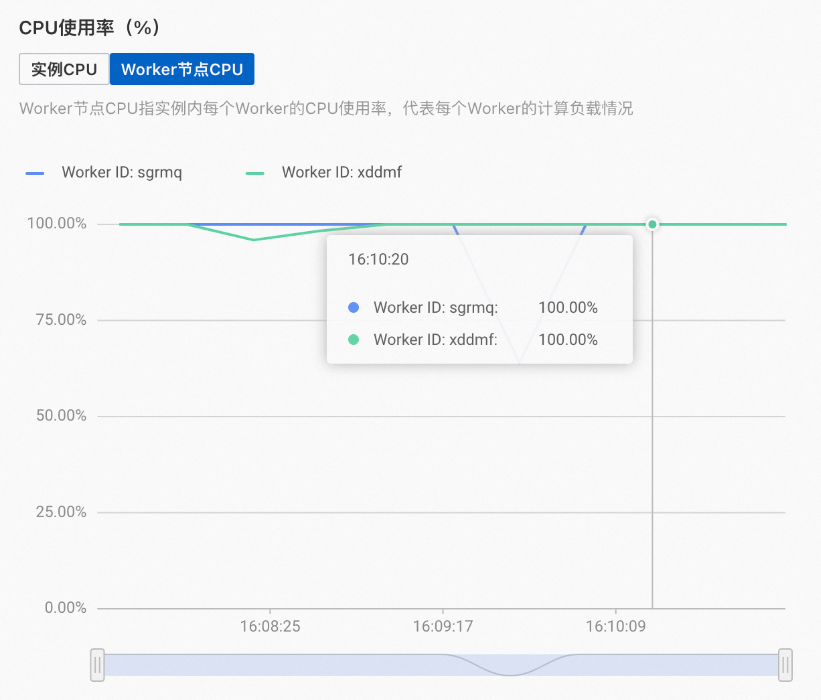
當增加replica后,同樣的查詢條件下,各個Worker的資源已經得到了充分的利用,如下所示。
使用限制
在Hologres中使用Shard級別的Replication時,僅Hologres V1.1及以上版本支持。
說明您可以在Hologres管控臺的實例詳情頁查看當前實例版本,如果您的實例是V0.10以下版本,請您使用自助升級或加入Hologres釘釘交流群反饋,詳情請參見如何獲取更多的在線支持?。
replica_count必須小于等于計算節點數量。您可以在Hologres的管理控制臺的實例詳情頁面中查看實例節點數量。
語法說明
查詢當前DB的Table Group
您可以使用如下語法查看當前DB有哪些Table Group。
select * from hologres.hg_table_group_properties ;查詢已有Table Group的replica count
語法示例
select property_value from hologres.hg_table_group_properties where tablegroup_name = 'table_group_name' and property_key = 'replica_count';參數說明
參數
說明
table_group_name
請輸入您需要查詢的Table Group名稱。
replica_count
此處為固定參數名稱,無需修改。
開啟Replication
通過以下命令調整Table Group的副本數量。
-- 調整Table Group的副本數量 call hg_set_table_group_property ('<table_group_name>', 'replica_count', '<replica_count>');replica_count:設置目標Table Group的副本數量,replica_count應小于計算節點數。
關閉Replication
語法示例
-- 修改replica_count,關閉replication call hg_set_table_group_property ('table_group_name', 'replica_count', '1');參數說明
參數
說明
hg_set_table_group_property
修改Table Group的replica_count。
table_group_name:請輸入您需要修改的Table Group名稱。
replica_count:設置目標Table Group的副本數量。
設置是否開啟Replication:1為默認值,表示不啟用read replica功能。大于1的數值表示啟用read replica功能。
查看加載情況
當您設置多replica之后,可以通過如下SQL查看每個Worker加載Shard的情況。
SELECT * FROM hologres.hg_worker_info;說明當Worker未完成Shard元數據加載之前,worker_id列可能為空。
示例返回結果如下:
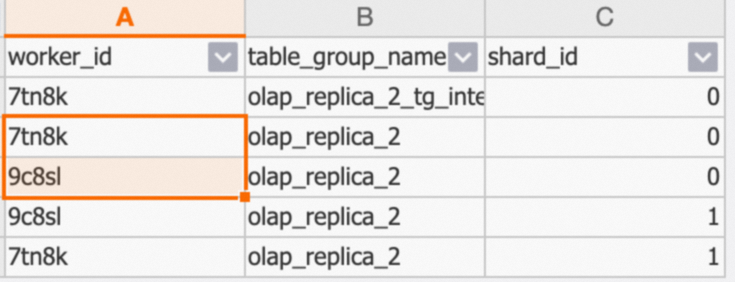
olap_replica_2有2個Shard,shard_id分別是0和1,分別在7tn8k和9c8slWorker上都有一份數據。
設置查詢高可用和高吞吐策略
行為說明
當設置了Shard多副本時,如下圖所示,Shard的副本會被加載到多個Worker上,此時查詢會隨機使用某個Worker上的Shard副本回答查詢。
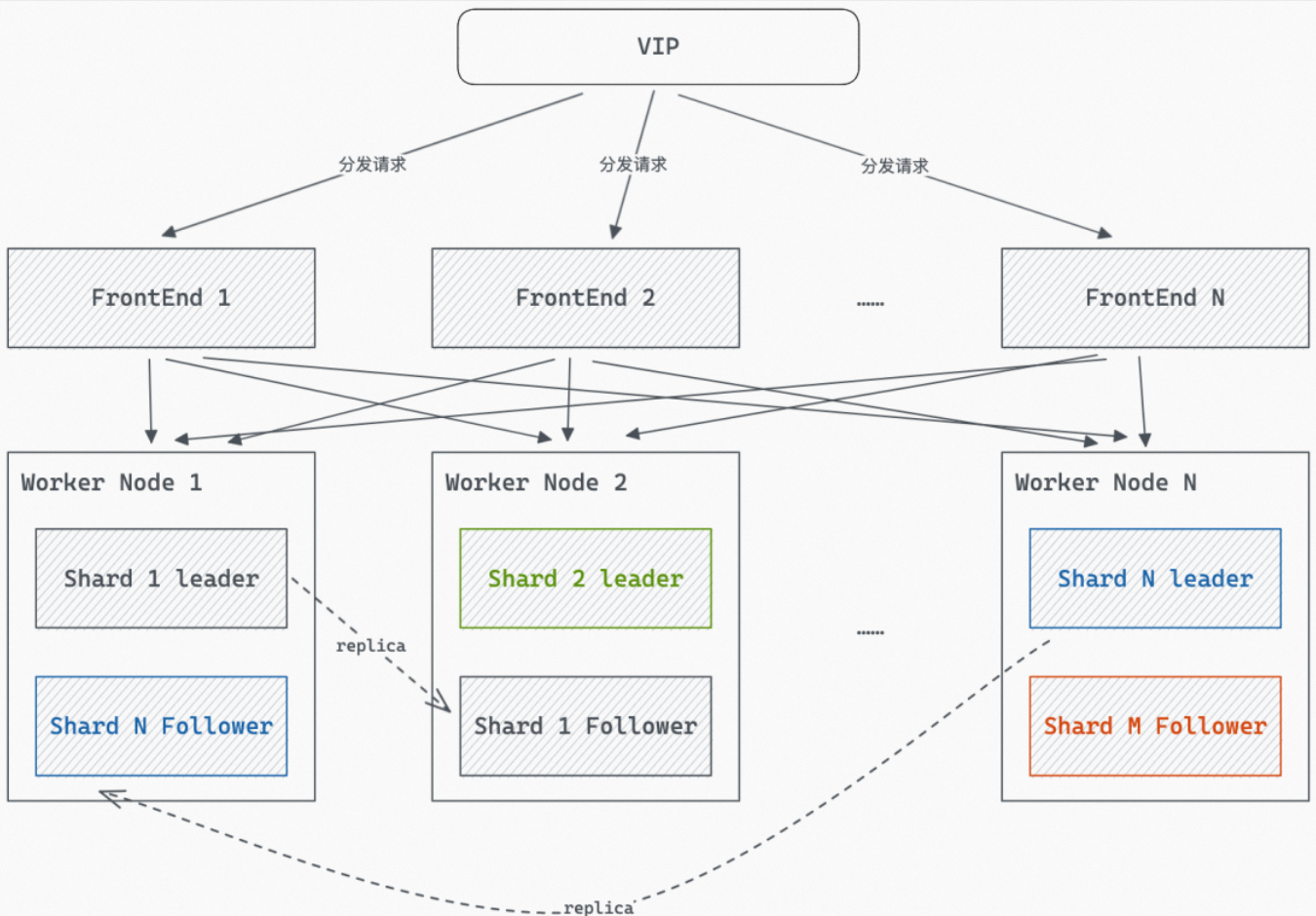
對于點查(Fixed Plan查詢)場景,為了保證點查場景盡量能夠返回結果,在點查場景下會進行查詢重試,當查詢超過一定時間未返回,會使用另一個Worker上的Shard再重試查詢。
相關參數說明
hg_experimental_query_replica_mode:指定回答查詢的Shard策略。使用場景
默認值
取值類型
可選值
使用示例
所有查詢
leader_follower
TEXT
leader_follower(默認):表示會按照比例使用Leader Shard和Follower Shard回答查詢。leader_only:表示僅使用Leader Shard回答查詢,在該設置下即使replica數 > 1,也無法實現擴充吞吐和高可用的能力。follower_only:表示僅使用Follower Shard回答查詢,在該設置下需要replica數 > 3,此時一個Follower Shard>=2,才能實現擴充吞吐和高可用的能力。
-- session 級別設置 SET hg_experimental_query_replica_mode = leader_follower; -- 數據庫級別設置 ALTER DATABASE <database_name> SET hg_experimental_query_replica_mode = leader_follower;hg_experimental_query_replica_leader_weight:指定回答查詢Leader Shard的權重。使用場景
默認值
取值類型
可選值
使用示例
所有查詢
100
INT
最大值:10000
最小值:1
默認值:100
-- session 級別設置 SET hg_experimental_query_replica_leader_weight = 100; -- 數據庫級別設置 ALTER DATABASE <database_name> SET hg_experimental_query_replica_leader_weight = 100;當表對應的Table Group的
replica_count >1,且查詢是OLAP點查場景,查詢根據hg_experimental_query_replica_mode和hg_experimental_query_replica_leader_weight設置的使用Leader Shard和Follower Shard按照一定比例回答查詢。存在如下場景:場景1:當表對應的Table Group的
replica_count>1,hg_experimental_query_replica_mode=leader_follower,系統會根據Leader Shard回答查詢的權重(hg_experimental_query_replica_leader_weight參數值默認為100),將查詢路由到Leader Shard 和 Follower Shard進行查詢,默認情況下每個Follower Shard回答查詢的權重為100。例如replica_count=4,此時每個Shard有1個Leader Shard和3個Follower Shard,命中每個Leader Shard和Follower Shard的概率都是25%。場景2:當表對應的Table Group的
replica_count>1且hg_experimental_query_replica_mode=leader_only,無論replica_count是多少,系統僅使用Leader Shard回答查詢。場景3:當表對應的Table Group的
replica_count>1且hg_experimental_query_replica_mode='follower_only',系統僅使用Follower Shard回答查詢,默認情況下每個Follower Shard回答查詢的權重為100。例如replica_count=4,此時每個Shard有1個Leader Shard和3個Follower Shard,此時只會使用3個Follower Shard回答查詢,命中每個Follower Shard的概率是三分之一。
hg_experimental_query_replica_fixed_plan_ha_mode:指定點查(Fixed Plan查詢)場景下高可用的模式策略。使用場景
默認值
取值類型
可選值
使用示例
點查(Fixed Plan查詢)
any
TEXT
any(默認值):按照hg_experimental_query_replica_mode設定的Shard范圍和hg_experimental_query_replica_leader_weight設置的權重將查詢隨機分發到Shard副本回答查詢。leader_first:默認值,僅在hg_experimental_query_replica_mode值設為leader_follower時生效,表示優先發送查詢到Leader Shard,僅在Leader Shard不可用(如超時)時才發送查詢到Follower Shard。off:表示不執行重試,僅做一次查詢。
-- session 級別設置 SET hg_experimental_query_replica_fixed_plan_ha_mode = any; -- 數據庫級別設置 ALTER DATABASE <database_name> SET hg_experimental_query_replica_fixed_plan_ha_mode = any;hg_experimental_query_replica_fixed_plan_first_query_timeout_ms:指定點查(Fixed Plan查詢)場景下高可用的模式時,表示首次查詢的超時時間,超時后查詢將被發送至另一個可用的Shard來重試。例如hg_experimental_query_replica_fixed_plan_first_query_timeout_ms=60表示如果查詢60ms并未返回結果,系統會換一個Worker進行重試。使用場景
默認值
取值類型
可選值
使用示例
所有查詢
60
INT
最大值:10000
最小值:0
默認值:60
-- session 級別設置 SET hg_experimental_query_replica_fixed_plan_first_query_timeout_ms = 60; -- 數據庫級別設置 ALTER DATABASE <database_name> SET hg_experimental_query_replica_fixed_plan_first_query_timeout_ms = 60;
場景設置建議
場景1:多副本高吞吐場景
場景描述:發現監控出現了類似如下的情況,實例整體資源利用率不高,但是僅有小部分Worker計算資源使用率很高,其他Worker計算資源利用率很低,判斷有可能是查詢不均導致的,即大部分的查詢僅用了其中幾個Shard回答查詢,此時您可以增加Shard的副本數量,使更多的Worker上有Shard的副本,該操作可以有效提高資源利用率和QPS。
具體操作:
增加副本數量:
例如出現數據庫中有一個名為tg_replica的Table Group,您可以使用如下SQL將其副本數量設置為2。
-- 針對將名為tg_replica的table group的副本數量設置為2 call hg_set_table_group_property ('tg_replica', 'replica_count', '2');由于系統默認配置如下:
hg_experimental_query_replica_mode=leader_follower
hg_experimental_query_replica_leader_weight=100
所以增加副本數量后,系統會將查詢隨機分發到Leader Shard和Follower Shard對應的Worker節點上,以解決因為查詢熱點導致的QPS無法增加的問題。
檢查Worker是否加載了Shard:
使用如下命令檢查Worker是否加載了Shard。
SELECT * FROM hologres.hg_worker_info WHERE table_group_name = 'tg_replica';示例返回結果如下:
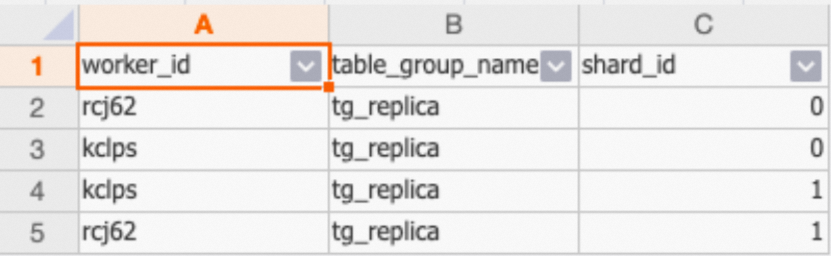
如上圖所示,同一個Shard被多個Worker加載,表示設置成功。
場景2:多副本高可用場景
場景描述:您希望解決因為單Shard Failover時導致查詢不可用情況。
具體操作:
增加副本數量:
例如出現數據庫中有一個名為tg_replica的Table Group,您可以使用如下SQL將其副本數量設置為2。
-- 針對將名為tg_replica的table group的副本數量設置為2 call hg_set_table_group_property ('tg_replica', 'replica_count', '2');由于系統默認配置如下:
hg_experimental_query_replica_mode=leader_follower
hg_experimental_query_replica_fixed_plan_ha_mode=any
hg_experimental_query_replica_fixed_plan_first_query_timeout_ms=60
所以增加副本數量后:
此時對于OLAP場景,系統會將查詢隨機分發到Leader Shard和Follower Shard對應的Worker節點上。查詢的同時,Master會定期檢測每個Shard的是否可用,系統會主動將不可用的Shard剔除查詢備選Shard,當Shard重新可用后,再加入查詢備選Shard。由于發現Shard不可用需要5秒,且摘除Worker對應的FE需要10秒,所以在系統發現問題到摘除節點恢復查詢需要15秒,即有15秒的查詢失敗持續時間,15秒后即可正常查詢。
對于Fixed Plan場景,由于系統有重試機制,若一個Worker發生Failover,當時的查詢響應時間變長,但是不會失敗。
對于一些Fixed Plan查詢場景,對于數據寫入即可查的行為敏感,無法容忍Leader Shard和Follower Shard之間延遲的場景,可以將
hg_experimental_query_replica_fixed_plan_ha_mode設置為leader_first。表示在Fixed Plan下,查詢始終先用Leader Shard回答查詢,當Leader Shard查詢超時時,再使用Follower Shard回答查詢。說明此時Fixed Plan場景就不具有解決因為查詢熱點導致的QPS無法增加問題的能力。
檢查Worker是否加載了Shard:
使用如下命令檢查Worker是否加載了Shard。
SELECT * FROM hologres.hg_worker_info WHERE table_group_name = 'tg_replica';示例返回結果如下:
如上圖所示,同一個Shard被多個Worker加載,表示設置成功。
常見問題
問題描述:按照場景1的場景設置參數后,查詢并未分發到Follower Shard。Hologres管理控制臺監控信息上仍然是設置多副本之前的Worker負載很高。
原因分析:Hologres V1.3版本之前存在
hg_experimental_enable_read_replicaGUC,用于控制Follower Shard是否能參數查詢,且默認關閉。您可以使用如下SQL檢查該參數是否開啟。如果返回值是on表示開啟,返回值是off表示關閉。SHOW hg_experimental_enable_read_replica;解決方法:如果
hg_experimental_enable_read_replica是關閉的,您可以使用如下SQL在數據庫級別開啟。ALTER DATABASE <database_name> SET hg_experimental_enable_read_replica = on;其中database_name為數據庫名稱。