本文為您介紹Delta Table在數據組織優化服務上的架構設計。
Clustering
當前痛點
Delta Table支持分鐘級近實時增量數據導入,高流量場景下可能會導致增量小文件數量膨脹,從而引發存儲訪問壓力大、成本高,并且大量的小文件還會引發Meta更新以及分析執行慢,數據讀寫I/O效率低下等問題,因此需要設計合理的小文件合并服務,即Clustering服務來自動優化此類場景。
解決方案
Clustering服務主要由MaxCompute內部的Storage Service來負責執行,專門解決小文件合并的問題,但它并不會改變任何數據的歷史中間狀態,即不會消除任何一條記錄數據的中間歷史狀態。
Clustering服務流程
Clustering服務的整體操作流程如圖所示。
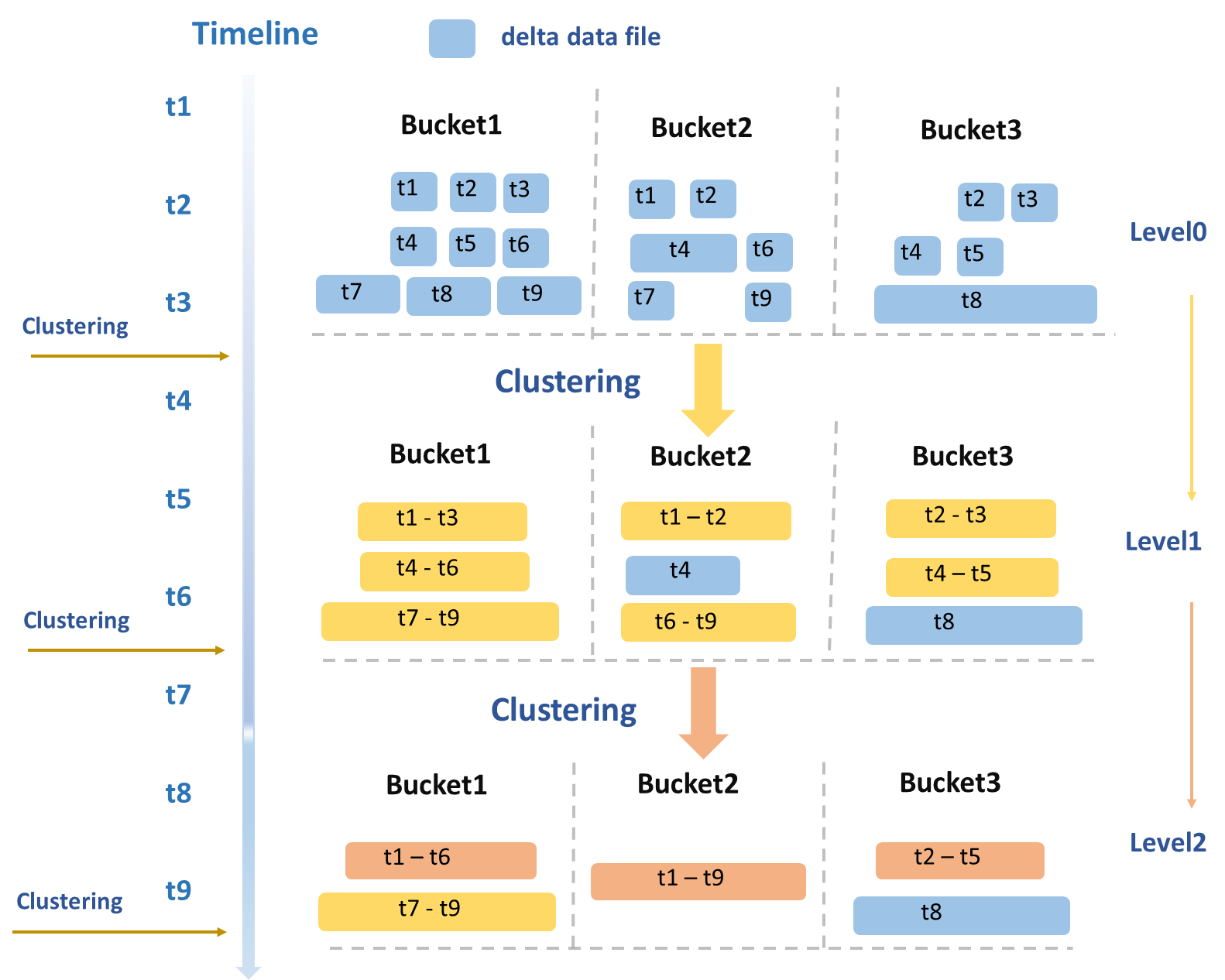
Clustering策略的制定主要基于典型的讀寫業務場景,會周期性地根據數據文件的大小、數量等多個維度進行綜合評估,并進行分層次的合并。Level0~Level1階段主要針對原始寫入的DeltaFile(圖中藍色數據文件)進行合并,形成中等大小的DeltaFile(圖中黃色數據文件)。當中等大小的DeltaFile達到一定規模后,會進一步觸發Level1~Level2的合并,生成更大的DeltaFile(圖中橙色數據文件)。
針對超過一定大小的數據文件,將進行專門的隔離處理,以避免觸發進一步的合并,從而避免不必要的讀寫放大問題。例如:Bucket3的T8數據文件所示。另外,對于超過一定時間跨度的文件也不會進行合并,因為將時間跨度太大的數據合并在一起可能導致在進行Time Travel或者增量查詢時讀取大量不屬于此次查詢時間范圍的歷史數據,進而造成不必要的讀放大問題。
由于數據是按照BucketIndex來切分存儲的,因此Clustering服務會以Bucket粒度來并發執行,大幅縮短整體運行時間。
Clustering服務會與Meta Service進行交互,以獲取待處理的表或分區列表。完成操作后,會將新舊數據文件的信息傳入Meta Service。Meta Service在此過程中起到關鍵作用,它負責進行事務沖突檢測,協調新舊文件Meta信息的無縫更新以及安全地回收舊數據文件。
Clustering服務能有效解決大量文件引發的讀寫效率低下的問題。由于每次執行至少需要讀寫一遍數據,將會消耗計算和I/O資源,存在一定的讀寫放大問題,當前MaxCompute引擎能夠根據系統狀態自動觸發執行,以確保Clustering服務的高效執行。
Compaction
當前痛點
Delta Table支持Update和Delete格式的數據寫入。如果存在大量此格式的數據寫入,會導致中間狀態的冗余記錄過多,增加存儲和計算成本,降低查詢效率等問題。因此,需要設計合理的Compaction服務,以消除中間狀態并優化這種場景。
解決方案
Compaction服務主要由MaxCompute內部的Storage Service來負責執行,既支持手動執行SQL語句觸發,也可通過配置表屬性按照時間頻率、Commit次數等維度自動觸發。此服務會把選中的數據文件,包含BaseFile和DeltaFile,一起進行Merge,消除數據的Update和Delete中間狀態,PK值相同的多行記錄只保留最新狀態的一行記錄,最后生成新的只包含Insert格式的BaseFile。
Compaction服務流程
Compaction服務的整體操作流程如下所示。
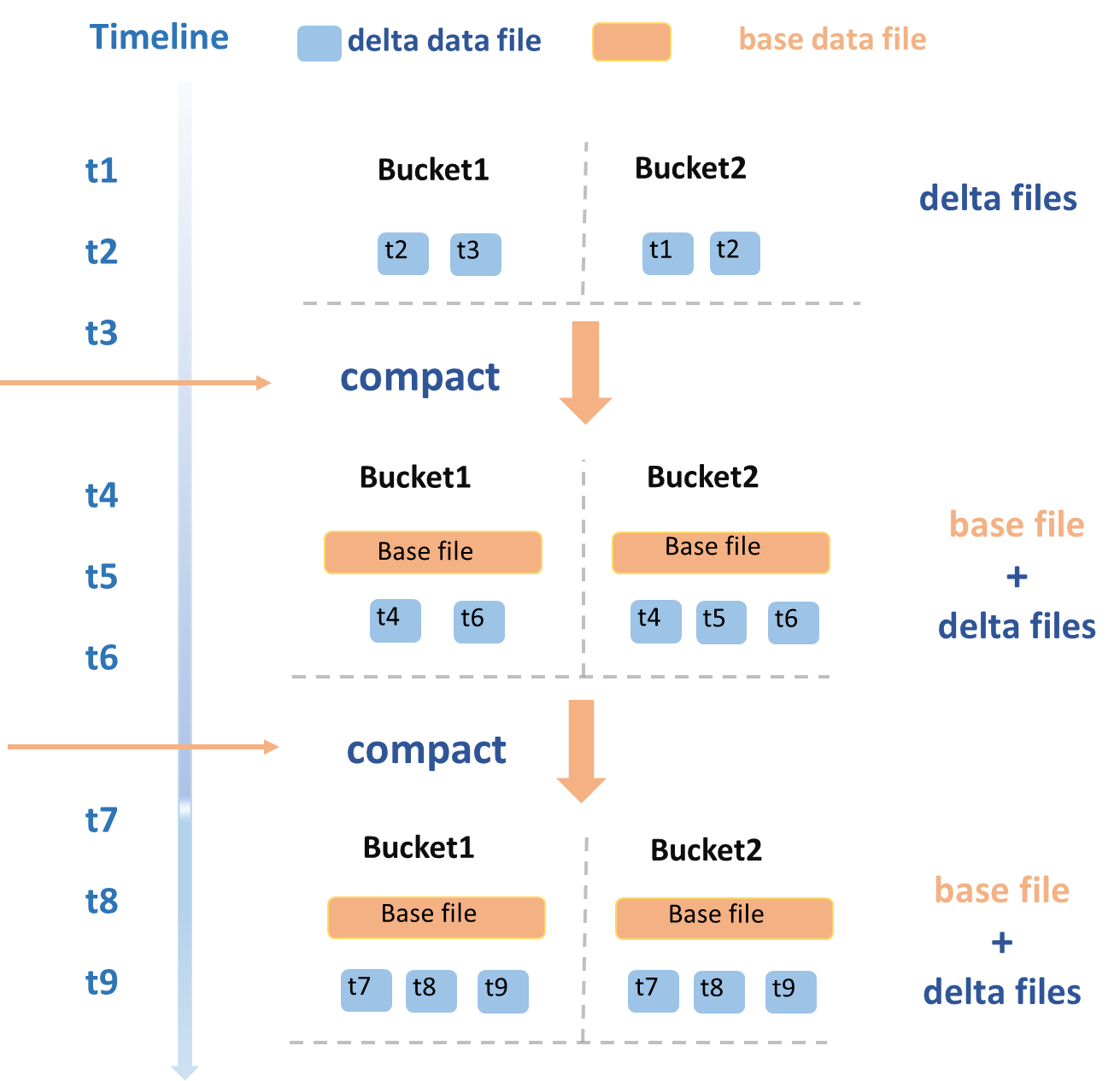
在t1~t3時間段內,一批DeltaFile被寫入,觸發Compaction操作,以Bucket粒度并發執行,將所有的DeltaFile進行Merge,然后每個Bucket會生成新的BaseFile。隨后在t4和t6時間段,又寫入了一批新的DeltaFile,再次觸發Compaction操作,將當前存在的BaseFile和新增的DeltaFile一起進行Merge操作,重新生成一個新的BaseFile。
Compaction服務還需要與Meta Service進行交互。其流程與Clustering類似,需要獲取需要執行此操作的表或分區的列表。執行結束后,將新舊數據文件的信息傳入Meta Service。其中,Meta Service負責Compaction操作的事務沖突檢測、新舊文件Meta信息的原子更新以及舊數據文件的回收等工作。
Compaction服務通過消除記錄的歷史狀態以節省計算和存儲資源,提升全量快照查詢的效率。然而,頻繁執行Compaction需要大量計算和I/O資源,并可能導致新BaseFile占用額外存儲,歷史DeltaFile文件可能會被用于Time Travel查詢,不能立即刪除,將繼續產生存儲成本。因此,應根據具體業務需求和數據特性來決定Compaction操作的執行頻率。在Update和Delete操作頻繁以及全量查詢需求高的情況下,可以考慮增加Compaction的頻率以優化查詢速度。
數據回收
由于Time Travel和增量查詢都會查詢數據的歷史狀態,因此需要保存一定的時間,可通過表屬性acid.data.retain.hours來配置保留的時間范圍。如果歷史狀態數據存在的時間早于配置值,系統會開始自動回收清理,一旦清理完成,Time Travel就查詢不到對應的歷史狀態了。回收的數據主要包含操作日志和數據文件兩部分。
同時,也會提供purge命令,用于特殊場景下手動觸發強制清除歷史數據。
需要特別說明的是,對于Delta Table,如果用戶一直寫入新的DeltaFile,那永遠也刪除不了任何一個DeltaFile,因為其他的DeltaFile可能對它有狀態依賴。只有執行COMPACTION或者InsertOverwrite操作后,之后產生的數據文件對之前的那些DeltaFile就沒有依賴了,如果超過Time Traval可查詢的時間周期后,就可以被刪除了。
對于用戶就是一直不執行Compaction操作的極端場景,引擎側會做一些優化避免產生無限的歷史記錄,后臺系統會周期性地對超過Time Travel時間的BaseFile或者DeltaFile進行自動Compaction,后續就可以正常回收這些被Compaction的歷史數據文件。