MapReduce
本文為您介紹MaxCompute支持的MapReduce編程接口及使用限制。
MaxCompute提供個兩版本的MapReduce編程接口:
MaxCompute MapReduce:MaxCompute的原生接口,執(zhí)行速度快、開發(fā)快捷、不暴露文件系統(tǒng)。
MaxCompute擴展MapReduce(MR2):對MaxCompute MapReduce的擴展,支持更復(fù)雜的作業(yè)調(diào)度邏輯。MapReduce的實現(xiàn)方式與MaxCompute原生接口一致。
以上版本在基本概念、作業(yè)提交、輸入與輸出、資源使用等方面基本一致,僅各版本的Java SDK有所不同。本文僅對MapReduce的基本原理做簡單介紹,更多詳情請參見Hadoop Map/Reduce教程。
您無法通過MapReduce讀寫外部表中的數(shù)據(jù)。
應(yīng)用場景
MapReduce支持下列場景:
搜索:網(wǎng)頁爬取、倒排索引、PageRank。
Web訪問日志分析:
分析和挖掘用戶在Web上的訪問、購物行為特征,實現(xiàn)個性化推薦。
分析用戶訪問行為。
文本統(tǒng)計分析:
熱門小說的字數(shù)統(tǒng)計(WordCount)、詞頻TFIDF分析。
學(xué)術(shù)論文、專利文獻的引用分析和統(tǒng)計。
維基百科數(shù)據(jù)分析。
海量數(shù)據(jù)挖掘:非結(jié)構(gòu)化數(shù)據(jù)、時空數(shù)據(jù)和圖像數(shù)據(jù)挖掘。
機器學(xué)習(xí):監(jiān)督學(xué)習(xí)、無監(jiān)督學(xué)習(xí)和分類算法(例如決策樹、SVM)。
自然語言處理:
基于大數(shù)據(jù)的訓(xùn)練和預(yù)測。
基于語料庫構(gòu)建單詞同現(xiàn)矩陣,頻繁項集數(shù)據(jù)挖掘、重復(fù)文檔檢測等。
廣告推薦:用戶單擊(CTR)和購買行為(CVR)預(yù)測。
MapReduce流程說明
MapReduce處理數(shù)據(jù)過程主要分成Map和Reduce兩個階段。首先執(zhí)行Map階段,再執(zhí)行Reduce階段。Map和Reduce的處理邏輯由用戶自定義實現(xiàn),但要符合MapReduce框架的約定。MapReduce處理數(shù)據(jù)的完整流程如下:
輸入數(shù)據(jù):對文本進行分片,將每片內(nèi)的數(shù)據(jù)作為單個Map Worker的輸入。分片完畢后,多個Map Worker便可以同時工作。
在正式執(zhí)行Map前,需要將輸入數(shù)據(jù)進行分片。所謂分片,就是將輸入數(shù)據(jù)切分為大小相等的數(shù)據(jù)塊,每一塊作為單個Map Worker的輸入被處理,以便于多個Map Worker同時工作。
Map階段:每個Map Worker在讀入各自的數(shù)據(jù)后,進行計算處理,最終輸出給Reduce。Map Worker在輸出數(shù)據(jù)時,需要為每一條輸出數(shù)據(jù)指定一個Key,這個Key值決定了這條數(shù)據(jù)將會被發(fā)送給哪一個Reduce Worker。Key值和Reduce Worker是多對一的關(guān)系,具有相同Key的數(shù)據(jù)會被發(fā)送給同一個Reduce Worker,單個Reduce Worker有可能會接收到多個Key值的數(shù)據(jù)。
在進入Reduce階段之前,MapReduce框架會對數(shù)據(jù)按照Key值排序,使得具有相同Key的數(shù)據(jù)彼此相鄰。如果您指定了合并操作(Combiner),框架會調(diào)用Combiner,將具有相同Key的數(shù)據(jù)進行聚合。Combiner的邏輯可以由您自定義實現(xiàn)。與經(jīng)典的MapReduce框架協(xié)議不同,在MaxCompute中,Combiner的輸入、輸出的參數(shù)必須與Reduce保持一致,這部分的處理通常也叫做洗牌(Shuffle)。
Reduce階段:進入Reduce階段,相同Key的數(shù)據(jù)會傳送至同一個Reduce Worker。同一個Reduce Worker會接收來自多個Map Worker的數(shù)據(jù)。每個Reduce Worker會對Key相同的多個數(shù)據(jù)進行Reduce操作。最后,一個Key的多條數(shù)據(jù)經(jīng)過Reduce的作用后,將變成一個值。
輸出結(jié)果數(shù)據(jù)。
上文僅是對MapReduce框架的簡單介紹,更多詳情請查閱功能介紹。
下文將以WordCount為例,為您介紹MaxCompute MapReduce各個階段的概念。
假設(shè)存在一個文本a.txt,文本內(nèi)每行是一個數(shù)字,您要統(tǒng)計每個數(shù)字出現(xiàn)的次數(shù)。文本內(nèi)的數(shù)字稱為Word,數(shù)字出現(xiàn)的次數(shù)稱為Count。如果MaxCompute MapReduce完成這一功能,需要經(jīng)歷以下流程,圖示如下。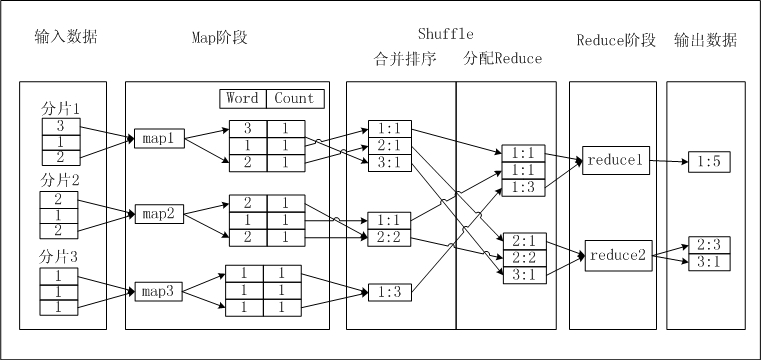
操作步驟
輸入數(shù)據(jù):對文本進行分片,將每片內(nèi)的數(shù)據(jù)作為單個Map Worker的輸入。
Map階段:Map處理輸入,每獲取一個數(shù)字,將數(shù)字的Count設(shè)置為1,并將此<Word, Count>對輸出,此時以Word作為輸出數(shù)據(jù)的Key。
Shuffle>合并排序:在Shuffle階段前期,首先對每個Map Worker的輸出,按照Key值(即Word值)進行排序。排序后進行Combiner操作,即將Key值(Word值)相同的Count累加,構(gòu)成一個新的<Word, Count>對。此過程被稱為合并排序。
Shuffle>分配Reduce:在Shuffle階段后期,數(shù)據(jù)被發(fā)送到Reduce端。Reduce Worker收到數(shù)據(jù)后依賴Key值再次對數(shù)據(jù)排序。
Reduce階段:每個Reduce Worker對數(shù)據(jù)進行處理時,采用與Combiner相同的邏輯,將Key值(Word值)相同的Count累加,得到輸出結(jié)果。
輸出結(jié)果數(shù)據(jù)。
由于MaxCompute的所有數(shù)據(jù)都被存放在表中,因此MaxCompute MapReduce的輸入、輸出只能是表,不允許您自定義輸出格式,不提供類似文件系統(tǒng)的接口。
使用限制
MapReduce使用限制請參見使用限制匯總。
有關(guān)本地運行的MapReduce使用限制,請參見本地運行和分布式環(huán)境運行差異。
按量計費開發(fā)者版資源僅支持MaxCompute SQL(支持使用UDF)、PyODPS作業(yè)任務(wù),暫不支持MapReduce、Spark等其他任務(wù)。