PyODPS是MaxCompute的Python版本的SDK。提供簡單方便的Python編程接口,以便您使用Python編寫MaxCompute作業、查詢MaxCompute表和視圖,以及管理MaxCompute資源。PyODPS提供了與ODPS命令行工具類似的功能,例如上傳和下載文件、創建表、運行ODPS SQL查詢等,同時提供了一些高級功能,如提交MapReduce任務、使用ODPS UDF等。本文為您介紹PyODPS的應用場景、支持的工具,及使用過程中需要關注的注意事項
隨著MaxCompute MaxFrame的上線發布,將逐步替換PyODPS DataFrame及Mars接口,同時在算子兼容性以及分布式能力上有明顯提升,建議新用戶/新作業直接基于MaxFrame進行Python開發工作。
功能介紹
PyODPS應用場景請參見:
DataFrame操作:DataFrame快速入門。
讀取分區表數據:PyODPS讀取分區表數據。
參數傳遞:PyODPS參數傳遞。
使用第三方包:PyODPS使用第三方包。
查看一級分區:PyODPS查看一級分區。
條件查詢:PyODPS條件查詢。
DataFrame Sequence及執行:PyODPS的Sequence及執行操作。
支持的工具
PyODPS支持在本地環境、DataWorks、PAI Notebooks中使用。
無論您通過何種工具使用PyODPS,建議您盡量避免將全量數據下載到本地直接運行PyODPS任務,容易占用大量內存造成OOM,建議您將任務提交到MaxCompute進行分布式運行,對比介紹請參見下文的注意事項:請勿下載全量數據到本地并運行PyODPS。
本地環境:您可以在本地環境安裝并使用PyODPS,操作指導可參見通過本地環境使用PyODPS。
DataWorks:DataWorks的PyODPS節點已安裝好了PyODPS,您可以直接在DataWorks的PyODPS節點上開發PyODPS任務并周期性運行,操作指導請參見通過DataWorks使用PyODPS。
PAI Notebooks:PAI的Python環境也可安裝運行PyODPS,其中PAI的內置鏡像均已安裝好了PyODPS可直接使用,如PAI-Designer的自定義Python組件,在PAI Notebooks中使用PyODPS的方式與通用的使用方式基本一致,可參考基本操作概述、DataFrame概述。
注意事項:請勿下載全量數據到本地并運行PyODPS
PyODPS作為一個SDK,本身運行于各種客戶端,包括PC、DataWorks(數據開發的PyODPS節點)或PAI Notebooks的運行環境。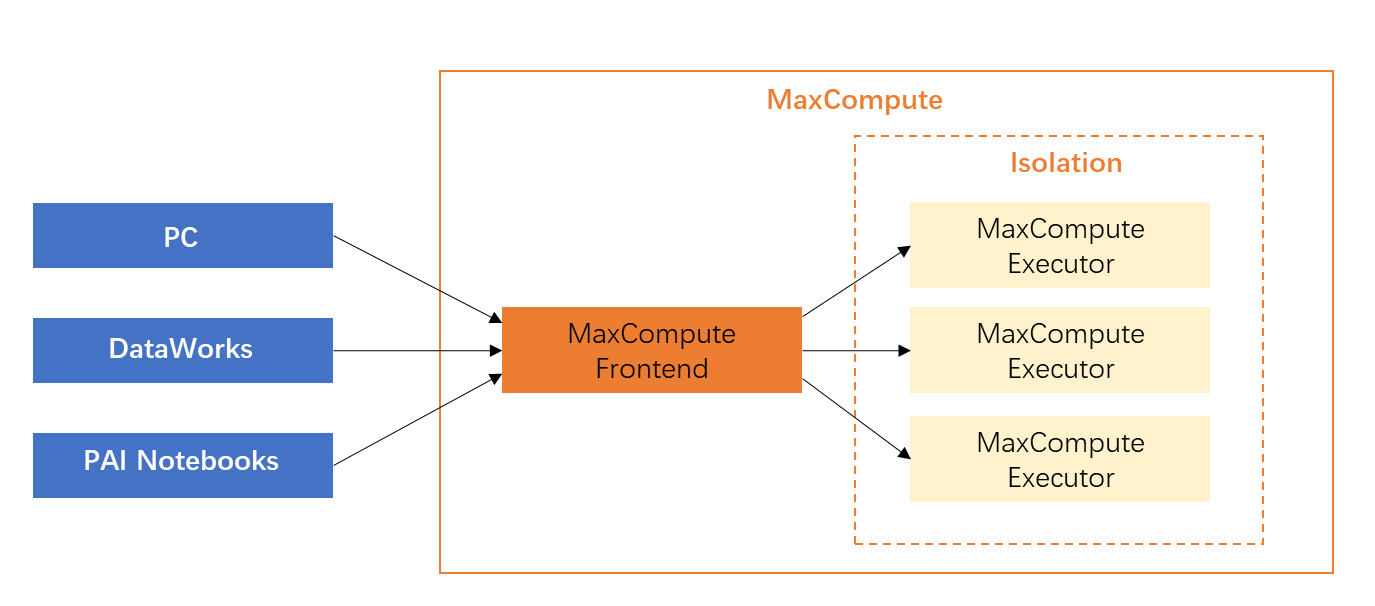 需要注意的是,PyODPS提供了多種方便拉取數據到本地的操作,如tunnel下載操作、execute操作、to_pandas操作等,因此,很多初始使用PyODPS的用戶會試圖把數據拉取到本地,處理完成后再上傳到 MaxCompute上,很多時候這種方式是十分低效的,拉取數據到本地徹底喪失了MaxCompute的大規模并行能力的優勢。
需要注意的是,PyODPS提供了多種方便拉取數據到本地的操作,如tunnel下載操作、execute操作、to_pandas操作等,因此,很多初始使用PyODPS的用戶會試圖把數據拉取到本地,處理完成后再上傳到 MaxCompute上,很多時候這種方式是十分低效的,拉取數據到本地徹底喪失了MaxCompute的大規模并行能力的優勢。
數據處理方式 | 描述 | 場景示例 |
拉取到本地處理(不推薦,易OOM) | 例如DataWorks中的PyODPS節點,內置了PyODPS包以及必要的Python環境,是一個資源非常受限的客戶端運行容器,并不使用MaxCompute計算資源,有較強的內存限制。 | PyODPS提供了 |
提交到MaxCompute分布式執行(推薦) | 推薦您合理利用PyODPS提供的分布式DataFrame功能,將主要的計算提交到MaxCompute分布式執行而不是在PyODPS客戶端節點下載處理,這是正確使用PyODPS的關鍵。 | 推薦使用PyODPS DataFrame接口來完成數據處理。常見的需求,比如需要對每一行數據處理然后寫回表,或者一行數據要拆成多行,都可以通過PyODPS DataFrame中的 使用這些接口最終都會翻譯成SQL到MaxCompute計算集群做分布式計算,并且本地幾乎沒有任何的內存消耗,相比于單機有很大的性能提升。 |
以下以一個分詞的示例為例,為您對比兩種方式的代碼區別。
示例場景
用戶需要通過分析每天產生的日志字符串來提取一些信息,有一個只有一列的表,類型是string,通過jieba分詞可以將中文語句分詞,然后再找到想要的關鍵詞存儲到信息表里。
低效處理代碼demo
import jieba t = o.get_table('word_split') out = [] with t.open_reader() as reader: for r in reader: words = list(jieba.cut(r[0])) # # 處理邏輯,產生出 processed_data # out.append(processed_data) out_t = o.get_table('words') with out_t.open_writer() as writer: writer.write(out)單機處理數據的思維,逐行讀取數據,然后逐行處理數據,再逐行寫入目標表。整個流程中,下載上傳數據消耗了大量的時間,并且在執行腳本的機器上需要很大的內存處理所有的數據,特別是對于使用DataWorks節點的用戶來說,很容易因為超過默認分配的內存值而導致OOM運行報錯。
高效處理代碼demo
from odps.df import output out_table = o.get_table('words') df = o.get_table('word_split').to_df() # 假定需要返回的字段及類型如下 out_names = ["word", "count"] out_types = ["string", "int"] @output(out_names, out_types) def handle(row): import jieba words = list(jieba.cut(row[0])) # # 處理邏輯,產生出 processed_data # yield processed_data df.apply(handle, axis=1).persist(out_table.name)利用apply實現分布式執行:
復雜邏輯都放在handle這個函數里,這個函數會被自動序列化到服務端作為UDF使用,在服務端調用執行,且因為handle服務端實際執行時也是對每一行進行處理的,所以邏輯上是沒有區別的。不同的是,這樣寫的程序在提交到MaxCompute端執行時,有多臺機器同時處理數據,可以節約很多時間。
調用persist接口會將產生的數據直接寫到另一張MaxCompute表中,所有的數據產生與消費都在 MaxCompute集群完成,也節約了本地的網絡與內存。
在這個例子中也使用到了三方包,MaxCompute是支持自定義函數中使用三方包的(示例中的
jieba),所以無需擔心代碼改動帶來的成本,您可以幾乎不需要改動主要邏輯就可以享受到MaxCompute的大規模計算能力。
使用限制
由于沙箱的限制,部分Pandas計算后端執行本地調試通過的程序,無法在MaxCompute上調試通過。