本文介紹如何將對象存儲OSS里面的數據作為PAI的訓練樣本。
本文由 龍臨@阿里云 提供,僅供參考。
背景信息
本文通過OSS與PAI的結合,為一家傳統的文具零售店提供決策支持。本文涉及的具體業務場景(場景與數據均為虛擬)如下:
一家傳統的線下文具零售店,希望通過數據挖掘尋找強相關的文具品類,幫助合理調整文具店的貨架布局。但由于收銀設備陳舊,是一臺使用XP系統的POS收銀機,可用的銷售數據僅有一份從POS收銀機導出的訂單記錄(csv格式)。本文介紹如何將此csv文件導入OSS,并連通OSS與PAI,實現商品的關聯推薦。
操作步驟
數據上傳至Bucket。
以上傳文件為Sample_superstore.csv,上傳至華東1(杭州)地域下的目標存儲空間examplebucket為例。
構造Sample_superstore.csv文件數據樣例。
order_id,order_date,customer_id,item,sales,quantity 1,20240101,1,aa,10,100將Sample_superstore.csv文件上傳至examplebucket。具體操作,請參見簡單上傳。
連通OSS和PAI。
在華東1(杭州)地域新建工作流。具體操作,請參見新建自定義工作流。
單擊新建的工作流,然后在左側導航欄選擇。
雙擊讀CSV文件組件,在右側的讀CSV文件組件面板的參數設置頁簽,文件路徑設置為
oss://examplebucket/Sample_superstore.csv,Schema設置為order_id string,order_date string,customer_id string,item string,sales string,quantity string,打開是否忽略第一行數據開關,其他參數保留默認配置。右鍵單擊讀CSV文件組件,然后單擊執行該節點。
等待執行完成后,右鍵單擊讀CSV文件組件,然后單擊。
在組件下方,查看表信息。數據預覽僅支持1000條記錄。如果需要查看全表,請按照頁面指引前往DataWorks。
數據探索流程
本文所用的主要算法組件為協同過濾。有關該組件的詳細用法,請參見協同過濾做商品推薦。
本案例中的數據探索流程如下:
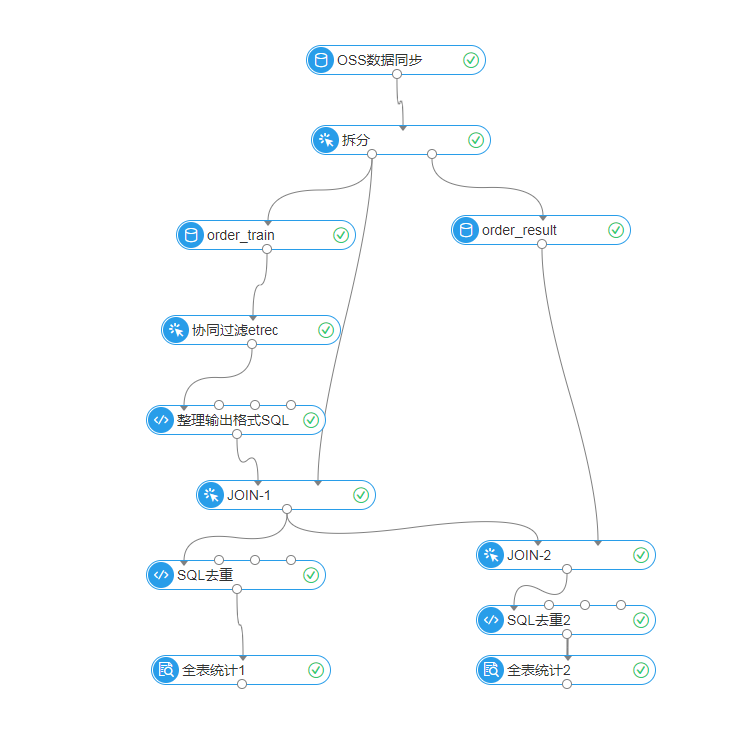
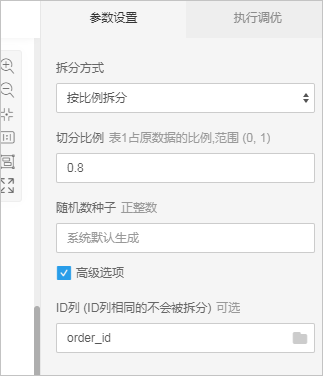
本案例按8:2的比例將源數據拆分為訓練集和測試集,其中一個訂單中可能有多個item,故ID列選擇order_id,保證含有多個item的訂單不會被拆分,如下圖所示:
本案例中共有17個產品item。通過協同過濾算法組件,取相似度最高的item,結果如下表:

結論
通過機器學習,我們發現“紙張”與“訂書器”二者的相似度較高,且與其它產品也有較高的相似度。
對于這家文具零售店來說,根據此數據發現可以有兩種布局貨架的方式:
紙張和訂書器貨架放在最中間,其它產品貨架呈環形圍繞二者擺放,這樣無論顧客從哪個貨架步入,都可以快速找到關聯程度較高的紙張和訂書器。
將紙張和訂書器兩個貨架分別擺放在文具店的兩端,顧客需要橫穿整個文具店才可以購買到另外一樣,中途路過其他產品的貨架可以提高交叉購買率。當然,此布局方式犧牲了用戶購物的便利性,實際操作中應保持慎重。