智能文創(chuàng)解決方案
阿里云PAI提供智能文創(chuàng)解決方案,幫助您快速搭建囊括模型離線訓(xùn)練、離線預(yù)測和在線部署的端到端全鏈路構(gòu)建流程。旨在從冗長、重復(fù)的文本序列中抽取、精煉或總結(jié)出要點信息,實現(xiàn)各類文本生成任務(wù),包括文本摘要生成、新聞標(biāo)題生成、文案生成、問題生成、作文生成和古詩生成等。
前提條件
在開始執(zhí)行操作前,請確認(rèn)您已完成以下準(zhǔn)備工作。
已開通PAI(Designer、DSW、EAS)后付費,并創(chuàng)建默認(rèn)工作空間,具體操作,請參見開通PAI并創(chuàng)建默認(rèn)工作空間。
已創(chuàng)建OSS存儲空間(Bucket),用于存儲數(shù)據(jù)集、訓(xùn)練獲得的模型文件和配置文件。關(guān)于如何創(chuàng)建存儲空間,詳情請參見控制臺創(chuàng)建存儲空間。
背景信息
阿里云PAI在智能文本創(chuàng)作領(lǐng)域已實現(xiàn)各類文本生成任務(wù),包括:文本摘要生成、新聞標(biāo)題生成、文案生成、問題生成、作文生成和古詩生成等。各任務(wù)詳情介紹及具體解決方案如下。
任務(wù)介紹
任務(wù)類型
功能描述
輸入示例
輸出示例
文本摘要
根據(jù)輸入文本生成概要性總結(jié)。
新冠肺炎疫情發(fā)生以來,濫食野生動物的突出問題,以及由此給公共衛(wèi)生安全帶來的巨大隱患,引發(fā)社會廣泛關(guān)注。全國多地公安、林業(yè)以及市場監(jiān)管部門開展相關(guān)專項行動,對非法獵捕、販賣、食用野生動物進行全鏈條打擊,效果顯著。執(zhí)法部門在打擊涉野生動物違法犯罪活動的過程中發(fā)現(xiàn),野味消費群體龐大、盜獵利潤驚人、鑒定難度大成本高等問題,成為盜獵野生動物黑色利益鏈條得以在地下運轉(zhuǎn)的重要原因。
全國許多地方的公安、林業(yè)和市場監(jiān)管部門已采取相關(guān)專項行動,打擊非法狩獵、販運和食用野生動物的行為,產(chǎn)生了重大影響。
新聞標(biāo)題生成
根據(jù)新聞文本生成新聞標(biāo)題。
在廣州某某醫(yī)院,一個上午6名患者做支氣管鏡檢查。5人查出肺癌,且4人是老煙民!專家稱,吸煙和被動吸煙是肺癌的主要元兇,而二手煙、三手煙(即吸煙后滯留在室內(nèi)或衣服、頭發(fā)等的微粒和氣體)與吸煙危害性一樣大!
遠(yuǎn)離煙草!不止二手煙,還有三手煙!
文案生成
根據(jù)產(chǎn)品介紹生成產(chǎn)品文案。
家用陶瓷杯。
這款陶瓷杯采用優(yōu)質(zhì)陶土高溫?zé)贫桑少|(zhì)細(xì)膩通透,杯口圓潤光滑,唇感舒適。杯身上的花紋設(shè)計,時尚美觀,盡顯其現(xiàn)代簡約風(fēng)格時尚、典雅的氣息。圓潤的杯身,手感舒適,握感極佳,是您居家生活的好幫手。
問題生成
根據(jù)段落敘述生成可回答的問題。
小貓的很多本領(lǐng),比如上廁所、對環(huán)境的探索等,都是跟貓媽媽學(xué)來的。最好是讓小貓在貓媽媽身邊待2個月到3個月,相應(yīng)的本領(lǐng)才比較成熟。如果是小母貓,過早離開媽媽,那么她長大后在育兒方面也會有所欠缺。
小貓多久可以離開母貓?
作文生成
根據(jù)標(biāo)題生成作文內(nèi)容。
家鄉(xiāng)的四季。
家鄉(xiāng)的四季是多姿多彩的。春天,萬物復(fù)蘇,小草從土里探出頭來,好奇地打量著這個世界。小河里的冰融化了,河水清澈見底,魚兒在水里自由自在地游來游去。柳樹抽出了新的枝條,長出嫩綠的葉子,像一個個小姑娘在梳理自己美麗的長發(fā)。
古詩生成
根據(jù)關(guān)鍵詞生成古詩。
諸葛亮。
臥龍起南陽,飛鳥起北向。初若不自慎,又何保社稷。伊吾一寸心,耿耿抱高亮。
解決方案
基于PAI提供的文本摘要模型和算法,根據(jù)您自己的文本摘要場景,在Designer可視化建模平臺進行模型微調(diào),從而構(gòu)建具體場景的NLP(Natural Language Processing)文本摘要模型。
在Designer可視化建模平臺,基于PAI提供的默認(rèn)模型或您自行微調(diào)的文本摘要模型進行批量離線預(yù)測。
將模型部署為EAS在線服務(wù),對本文進行自動摘要。
使用流程
基于阿里云PAI,智能文創(chuàng)解決方案的使用流程如下。

將訓(xùn)練數(shù)據(jù)集和驗證數(shù)據(jù)集上傳到OSS Bucket中,用于后續(xù)的文本摘要模型訓(xùn)練和預(yù)測。
在Designer可視化建模平臺,使用文本摘要訓(xùn)練組件,基于海量大數(shù)據(jù)語料預(yù)訓(xùn)練獲得的NLP預(yù)訓(xùn)練模型,構(gòu)建文本摘要模型。
在Designer可視化建模平臺,使用文本摘要預(yù)測組件,基于海量文本數(shù)據(jù)、文本摘要模型或PAI默認(rèn)的模型,進行批量離線預(yù)測生成文本摘要。
通過模型在線服務(wù)EAS,您可以將訓(xùn)練好的文本摘要模型部署為在線服務(wù),并在實際的生產(chǎn)環(huán)境調(diào)用,從而實現(xiàn)在線生成文本摘要。
步驟一:準(zhǔn)備數(shù)據(jù)
準(zhǔn)備訓(xùn)練數(shù)據(jù)集和驗證數(shù)據(jù)集。
本文使用某個新聞數(shù)據(jù)集的一個子集進行模型訓(xùn)練和預(yù)測。訓(xùn)練數(shù)據(jù)集和預(yù)測數(shù)據(jù)集具體格式要求如下。
需要準(zhǔn)備的數(shù)據(jù)
格式
包含列
數(shù)據(jù)集示例文件
訓(xùn)練數(shù)據(jù)集
TSV或TXT
新聞?wù)?/p>
新聞原文列
驗證數(shù)據(jù)集
TSV或TXT
新聞標(biāo)題摘要列
新聞原文列
新聞標(biāo)題摘要分詞結(jié)果列(非必須)
新聞原文分詞結(jié)果列(非必須)
新聞類別標(biāo)簽列(非必須)
將數(shù)據(jù)集上傳至OSS Bucket,具體操作,請參見控制臺上傳文件。
說明如果您需要利用自己的數(shù)據(jù)集對模型進行微調(diào),則需要提前將數(shù)據(jù)集上傳至OSS Bucket中。
步驟二:構(gòu)建文本摘要模型
進入PAI-Designer頁面,并創(chuàng)建空白工作流,具體操作請參見操作步驟。
在工作流列表,選擇已創(chuàng)建的空白工作流,單擊進入工作流。
在工作流頁面,分別拖入以下組件,并根據(jù)下文的組件參數(shù)配置組件。
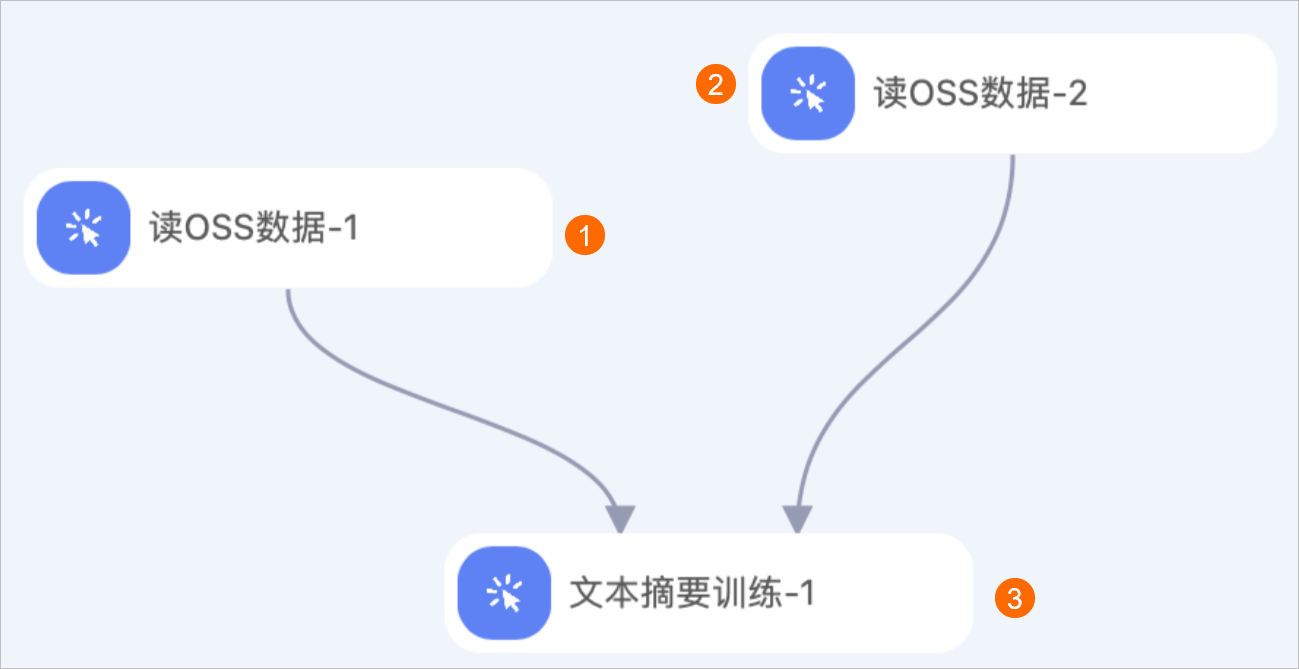
區(qū)域
描述
①
配置實驗的訓(xùn)練數(shù)據(jù)集,即配置讀OSS數(shù)據(jù)組件的OSS數(shù)據(jù)路徑參數(shù)為訓(xùn)練數(shù)據(jù)集在OSS Bucket中的存儲路徑。
②
配置實驗的驗證數(shù)據(jù)集,即配置讀OSS數(shù)據(jù)組件的OSS數(shù)據(jù)路徑參數(shù)為驗證數(shù)據(jù)集在OSS Bucket中的存儲路徑。
③
配置文本摘要模型訓(xùn)練的參數(shù)。文本摘要訓(xùn)練組件的配置詳情,請參見下文的文本摘要訓(xùn)練組件的配置。
表 1. 文本摘要訓(xùn)練組件的配置 頁簽
參數(shù)
描述
本案例使用的示例值
字段設(shè)置
輸入數(shù)據(jù)格式
輸入文件中每列的數(shù)據(jù)格式,多列之間使用半角逗號(,)分隔。
title_tokens:str:1,content_tokens:str:1
原文列選擇
新聞原文在輸入文件中對應(yīng)的列名。
content_tokens
摘要列選擇
新聞?wù)跀?shù)據(jù)文件中對應(yīng)的列名。
title_tokens
模型存儲路徑
配置OSS Bucket中的目錄,用來存儲文本摘要訓(xùn)練生成的模型文件。
oss://exampleBucket.oss-cn-shanghai-internal.aliyuncs.com/exampledir
參數(shù)設(shè)置
預(yù)訓(xùn)練模型
預(yù)訓(xùn)練模型名稱。
alibaba-pai/mt5-title-generation-zh
批次大小
訓(xùn)練過程中的批處理大小。如果使用多機多卡,則表示每個GPU上的批處理大小。
8
文本最大長度
表示系統(tǒng)可處理的序列整體最大長度。
512
迭代輪數(shù)
訓(xùn)練總Epoch的數(shù)量。
3
學(xué)習(xí)率
模型構(gòu)建過程中的學(xué)習(xí)率。
3e-5
保存模型文件步數(shù)
表示每訓(xùn)練多少步,對模型進行評價,并保存當(dāng)前最優(yōu)模型。
150
語言
表示當(dāng)前文本處理的語言:
zh:中文
en:英文
zh
是否從原文中拷貝文本
表示是否采用復(fù)制機制,取值如下:
false:(默認(rèn)值),表示不拷貝。
true:表示拷貝。
false
解碼器最小長度
表示解碼器最小長度,模型輸出長度大于該值。
12
解碼器最大長度
表示解碼器最大長度,模型輸出長度小于該值。
32
最小不重復(fù)字段
表示不重復(fù)的片段大小。例如:當(dāng)取值為1時,不會生成類似“天天”等結(jié)果。
2
集束搜索數(shù)量
模型生成候選答案時的搜索空間,該值越大,預(yù)測越慢。
5
返回候選答案數(shù)量
模型返回的排名靠前的候選結(jié)果數(shù)量。
5
執(zhí)行調(diào)優(yōu)
GPU機器類型
計算資源的GPU機型。默認(rèn)值為gn5-c8g1.2xlarge,表示8核CPU、80G內(nèi)存、P100單卡。
gn5-c8g1.2xlarge
步驟三:離線批量預(yù)測
配置離線預(yù)測工作流。
文本摘要預(yù)測組件有以下兩種工作方式。
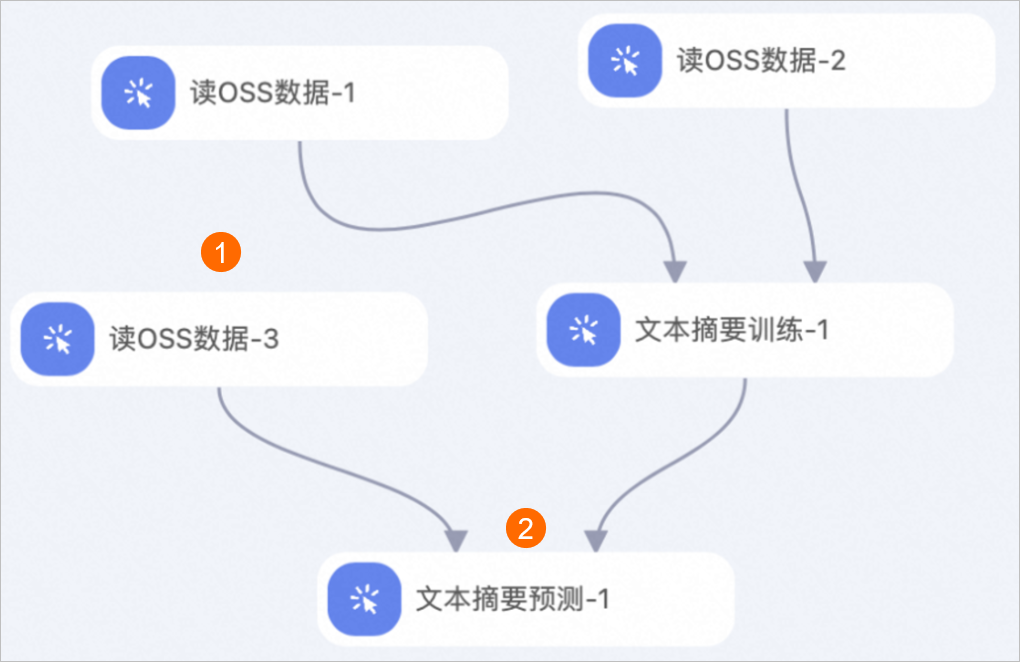
方式一:利用文本摘要訓(xùn)練組件生成的模型進行預(yù)測并生成摘要。
您需要在步驟二的工作流頁面,參照下圖補充拖入組件,并根據(jù)下文的組件參數(shù)配置組件。
方式二:將PAI默認(rèn)模型上傳至OSS Bucket,并接入文本摘要預(yù)測組件進行預(yù)測并生成摘要。
您需要參照步驟二創(chuàng)建新的空白工作流,參照下圖拖入組件,并根據(jù)下文的組件參數(shù)配置組件。

區(qū)域
描述
①
配置實驗的預(yù)測數(shù)據(jù)集(使用步驟一中的驗證數(shù)據(jù)集作為預(yù)測數(shù)據(jù)集),即配置讀OSS數(shù)據(jù)組件的OSS數(shù)據(jù)路徑參數(shù)為驗證數(shù)據(jù)集在OSS Bucket中的存儲路徑。
②
配置文本摘要模型預(yù)測的參數(shù)。文本摘要預(yù)測組件的配置詳情,請參見文本摘要預(yù)測組件的配置。
表 2. 文本摘要預(yù)測組件的配置 頁簽
參數(shù)
描述
本案例使用的示例值
字段設(shè)置
輸入數(shù)據(jù)格式
輸入文件的每列的數(shù)據(jù)格式,多列之間使用半角逗號(,)分隔。
title:str:1,content:str:1,title_tokens:str:1,content_tokens:str:1,tag:str:1
原文列選擇
新聞原文在輸入文件中對應(yīng)的列名。
content
輸出追加列選擇
將輸入文件的若干文本列追加到輸出文本列之后,多列之間使用半角逗號(,)分隔。
title_tokens,content,tag
輸出列選擇
選擇輸出列,多列之間使用半角逗號(,)分隔。
predictions,beams
預(yù)測數(shù)據(jù)輸出
配置預(yù)測結(jié)果文件在OSS Bucket中的路徑。
oss://exampleBucket.oss-cn-shanghai-internal.aliyuncs.com/exampledir/pred_data.tsv
使用自有模型
是否使用PAI默認(rèn)模型,進行直接預(yù)測。取值如下:
是:當(dāng)文本摘要預(yù)測組件使用方式二時,配置為是。
您需要在模型存儲路徑參數(shù)中配置PAI默認(rèn)模型在OSS Bucket中的存儲路徑。
否:當(dāng)文本摘要預(yù)測組件使用方式一時,配置為否。
否
是否為Megatron模型
僅支持文本摘要訓(xùn)練組件中列出的帶mg前綴的預(yù)訓(xùn)練模型。取值如下:
否(默認(rèn)值)
是
否
參數(shù)設(shè)置
批次大小
預(yù)測過程中的批處理大小。如果使用多機多卡,則表示每個GPU上的批處理大小。
8
文本最大長度
表示系統(tǒng)可處理的序列整體最大長度。
512
語言
表示當(dāng)前文本處理的語言:
zh:中文。
en:英文。
zh
是否從原文中拷貝文本
輸出結(jié)果是否從文本中拷貝文本片段:
false:(默認(rèn)值),表示不拷貝。
true:表示拷貝。
false
解碼器最小長度
表示解碼器最小長度,模型輸出長度大于該值。
12
解碼器最大長度
表示解碼器最大長度,模型輸出長度小于該值。
32
最小不重復(fù)字段
表示不重復(fù)的片段大小。
2
集束搜索數(shù)量
表示集束搜索大小。該值越大,預(yù)測越慢。
5
返回候選答案數(shù)量
表示返回結(jié)果的數(shù)量。
5
執(zhí)行調(diào)優(yōu)
GPU機器類型
計算資源的GPU機型。默認(rèn)值為gn5-c8g1.2xlarge,表示8核CPU、80G內(nèi)存、P100單卡。
gn5-c8g1.2xlarge
單擊畫布上方的運行。
實驗運行成功后,您可以在文本摘要訓(xùn)練組件模型存儲路徑配置的OSS Bucket目錄中,下載生成的模型文件和配置文件。
步驟四:部署及調(diào)用模型服務(wù)
通過模型在線服務(wù)EAS,您可以將訓(xùn)練好的文本摘要模型部署為在線服務(wù),并在實際的生產(chǎn)環(huán)境中調(diào)用,從而進行推理實踐。
首先將訓(xùn)練好的模型及其他相關(guān)配置文件打包。
如果您希望使用PAI默認(rèn)的模型進行部署,請?zhí)^此步。以下介紹文本摘要模型的打包方式。
首先將訓(xùn)練得到的模型,及其他配置文件打包為tgz格式,并上傳至OSS Bucket。模型和配置文件的目錄結(jié)構(gòu)如下所示。
finetuned_zh_model |--config.json |--label_mapping.json |--pytorch_model.bin |--train_config.json |--vocab.txt您可以使用以下命令,將目錄打包為tgz格式。
tar -zcvf finetuned_zh_model.tgz finetuned_zh_model/*進入模型在線服務(wù)(EAS)頁面。
登錄PAI控制臺。
在左側(cè)導(dǎo)航欄單擊工作空間列表,在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應(yīng)的工作空間。
在工作空間頁面的左側(cè)導(dǎo)航欄選擇,進入模型在線服務(wù)(EAS)頁面。
部署模型服務(wù)。
在模型在線服務(wù)(EAS)頁面,單擊部署服務(wù)。
在部署服務(wù)頁面,配置參數(shù)。
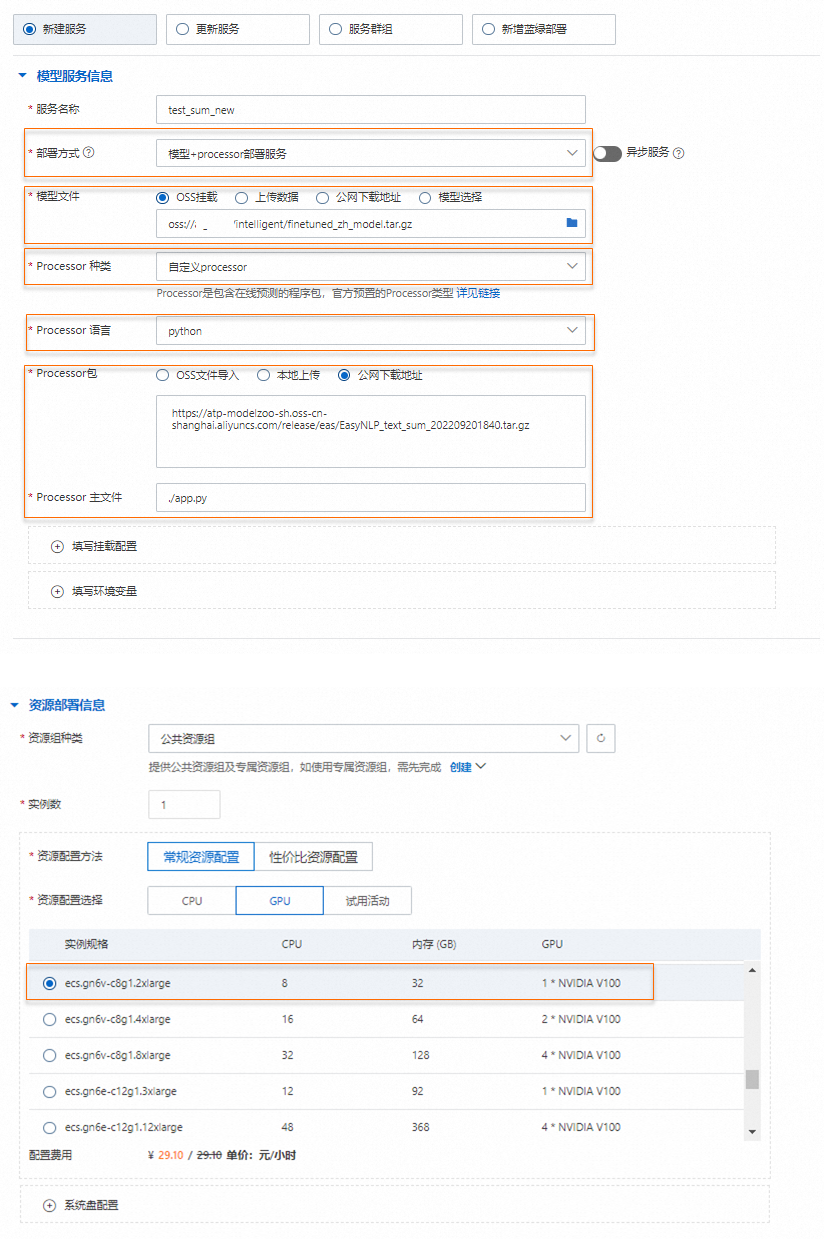 如果您希望部署自行訓(xùn)練的模型,模型文件參數(shù)需要配置第1步打包的文件在OSS Bucket的路徑。
如果您希望部署自行訓(xùn)練的模型,模型文件參數(shù)需要配置第1步打包的文件在OSS Bucket的路徑。參考以下內(nèi)容,確認(rèn)服務(wù)配置信息是否正確。
{ "metadata": { "instance": 1 }, "cloud": { "computing": { "instance_type": "ecs.gn6v-c8g1.2xlarge" } }, "name": "test_sum_new", "model_path": "oss://examplebucket/linshi/linshi_text/finetuned_zh_model.tgz", "processor_type": "python", "processor_path": "https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/eas/EasyNLP_text_sum_202209201840.tar.gz", "processor_entry": "./app.py" }單擊部署,等待一段時間即可完成模型部署。
調(diào)試模型服務(wù)。
在模型在線服務(wù)(EAS)頁面,單擊目標(biāo)服務(wù)操作列下的在線調(diào)試。
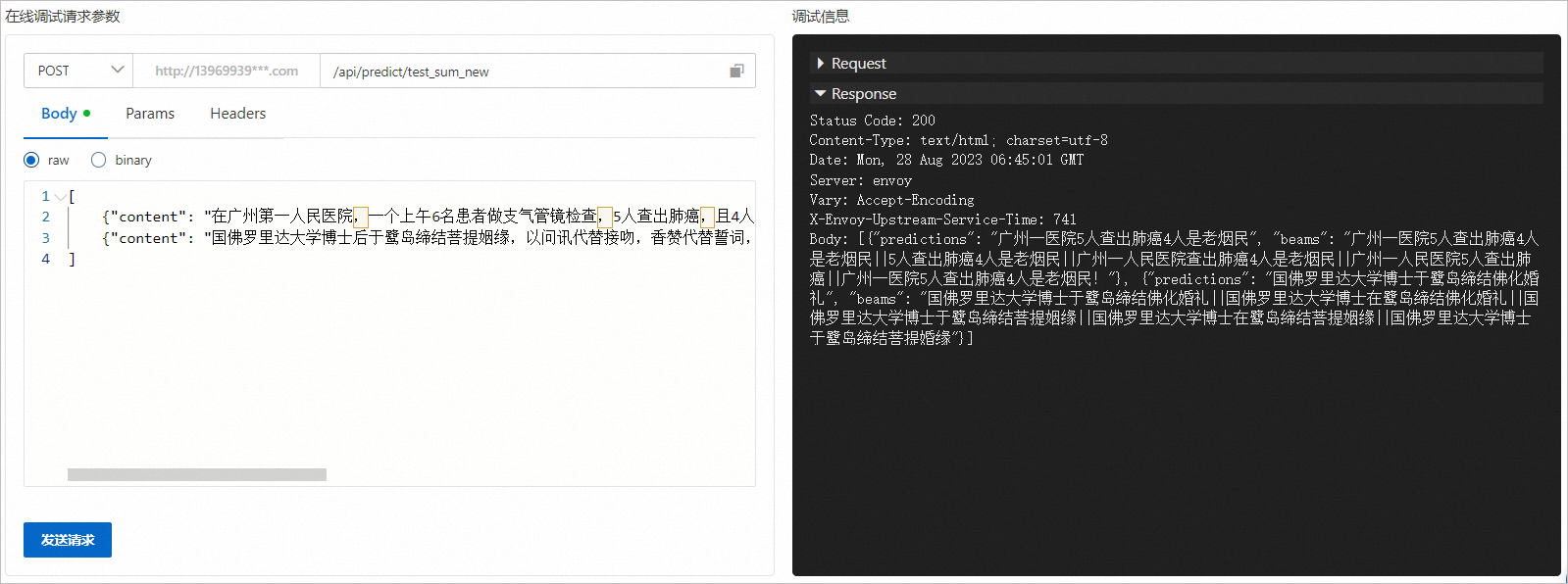
在調(diào)試頁面的在線調(diào)試請求參數(shù)區(qū)域的Body處填寫如下內(nèi)容。
[ {"content": "在廣州第一人民醫(yī)院,一個上午6名患者做支氣管鏡檢查,5人查出肺癌,且4人是老煙民!專家稱,吸煙和被動吸煙是肺癌的主要元兇,而二手煙、三手煙(即吸煙后滯留在室內(nèi)或衣服、頭發(fā)等的微粒和氣體)與吸煙危害性一樣大!"}, {"content": "國佛羅里達(dá)大學(xué)博士后于鷺島締結(jié)菩提姻緣,以問訊代替接吻,香贊代替誓詞,在白鹿洞寺法王寶殿舉行的佛化婚禮,兩位新人將永生難忘。佛化婚禮不同于一般結(jié)婚儀式,是將婚禮融入佛教禮節(jié),場面莊嚴(yán)隆重。"} ]單擊發(fā)送請求,即可在調(diào)試信息區(qū)域查看預(yù)測結(jié)果,如下圖所示。
查看模型服務(wù)的公網(wǎng)地址和訪問Token。
在模型在線服務(wù)(EAS)頁面,單擊目標(biāo)服務(wù)服務(wù)方式列下的調(diào)用信息。
在調(diào)用信息對話框的公網(wǎng)地址調(diào)用頁簽,查看公網(wǎng)調(diào)用的訪問地址和Token。
使用腳本進行批量調(diào)用。
創(chuàng)建調(diào)用模型服務(wù)的Python腳本eas_text_sum.py。
#!/usr/bin/env python #encoding=utf-8 from eas_prediction import PredictClient from eas_prediction import StringRequest if __name__ == '__main__': #下面的client = PredictClient()入?yún)⑿枰鎿Q為實際的訪問地址。 client = PredictClient('http://1664xxxxxxxxxxx.cn-hangzhou.pai-eas.aliyuncs.com', 'text_sum_new') #下面的Token需要替換為實際值。 client.set_token('<token>') client.init() #輸入請求需要根據(jù)模型進行構(gòu)造,此處僅以字符串作為輸入輸出的程序為例。 request = StringRequest('[\ {"content": "在廣州第一人民醫(yī)院,一個上午6名患者做支氣管鏡檢查,5人查出肺癌,且4人是老煙民!專家稱,吸煙和被動吸煙是肺癌的主要元兇,而二手煙、三手煙(即吸煙后滯留在室內(nèi)或衣服、頭發(fā)等的微粒和氣體)與吸煙危害性一樣大!"},\ {"content": "國佛羅里達(dá)大學(xué)博士后于鷺島締結(jié)菩提姻緣,以問訊代替接吻,香贊代替誓詞,在白鹿洞寺法王寶殿舉行的佛化婚禮,兩位新人將永生難忘。佛化婚禮不同于一般結(jié)婚儀式,是將婚禮融入佛教禮節(jié),場面莊嚴(yán)隆重。"}\ ]') for x in range(0, 1): resp = client.predict(request) print(str(resp.response_data, 'utf8')) print("test ending")其中:
client:需要配置為服務(wù)訪問地址和服務(wù)名稱。請參照示例代碼進行配置。
<token>:替換為服務(wù)Token。
將eas_text_sum.py的Python腳本上傳至您的任意環(huán)境,并在腳本上傳后的當(dāng)前目錄執(zhí)行如下調(diào)用命令。
python <eas_text_sum.py>其中<eas_text_sum.py>需要替換為實際的Python腳本名稱。
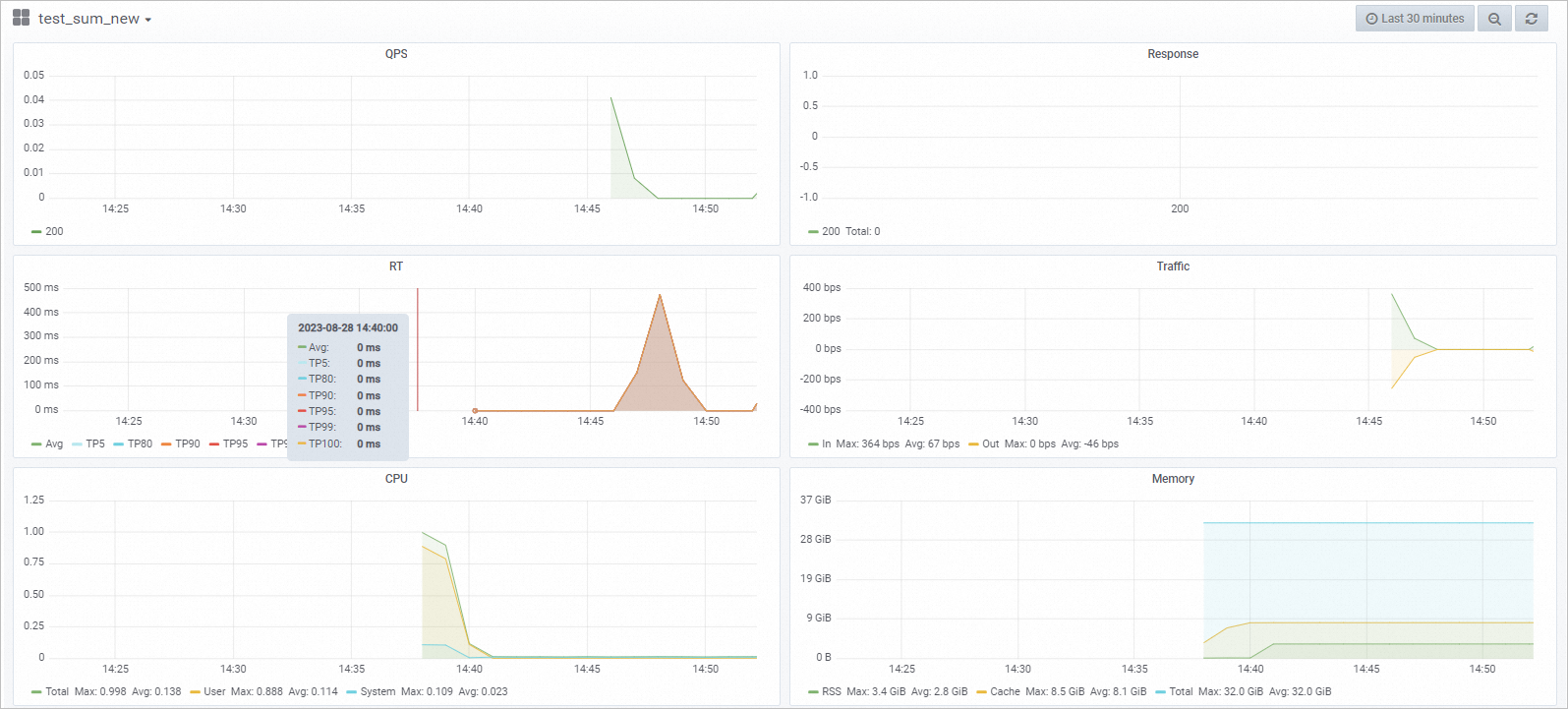
監(jiān)控服務(wù)指標(biāo)。調(diào)用模型服務(wù)后,您可以查看模型調(diào)用的相關(guān)指標(biāo)水位,包括QPS、RT、CPU、GPU及Memory。
在模型在線服務(wù)(EAS)頁面,單擊已調(diào)用服務(wù)服務(wù)監(jiān)控列下的
 圖標(biāo)。
圖標(biāo)。在服務(wù)監(jiān)控頁簽,即可查看模型調(diào)用的指標(biāo)水位。從下面的服務(wù)監(jiān)控水位圖中可以看到,本案例部署的模型預(yù)測一條數(shù)據(jù)的時延在200 ms左右。您自己的模型時延以實際為準(zhǔn)。
相關(guān)文檔
更多關(guān)于文本生成相關(guān)組件的使用詳情,請參見: