預訓練大語言模型面對來自于模型規模和數據規模的多重挑戰,為了解決這些問題,PAI提供了在DLC上使用Megatron-LM進行大語言模型預訓練的最佳實踐。該實踐通過準備鏡像環境與訓練數據、調整訓練策略、提交與管理任務等流程,幫助您在DLC上輕松高效地預訓練大語言模型。本文為您介紹該實踐的使用流程。
背景信息
基本概念
語言模型(LM)
是一種利用自然文本來預測詞(Token)順序的機器學習方法。
大語言模型(LLM)
是指參數數量達到億級別的神經網絡語言模型,例如:GPT-3、GPT-4、PaLM、PaLM2等。
Megatron-LM
是由NVIDIA的應用深度學習研究團隊開發的Transformer模型訓練框架,它可以高效利用算力、顯存和通信帶寬,大幅提升了大語言模型大規模預訓練的效率。Megatron-LM已經成為許多大語言模型預訓練任務的首選框架。
使用流程
首先準備訓練任務所需的鏡像環境和訓練數據,并將訓練數據創建為PAI數據集。
配置一系列優化策略來優化大語言模型的訓練過程,以提高模型的性能和準確度。
提交大語言模型預訓練任務,并對任務進行管理。
前提條件
已創建工作空間,具體操作,請參見創建工作空間。
已準備專有資源組,本案例使用靈駿智算資源gu7xf機型(例如:資源規格選擇ml.gu7xf.c96m1600.8-gu108),關于如何創建靈駿智算資源,請參見新建與管理靈駿智算資源。
已了解GPT的基本概念,詳情請參見Language Models are Few-Shot Learners。
使用限制
僅支持在華北6(烏蘭察布)使用靈駿智算資源。如果您在其他地域提交訓練任務,請選擇使用通用訓練資源專有資源組,關于如何創建通用訓練資源,請參見新建及管理通用訓練資源。
準備鏡像環境與訓練數據
準備鏡像環境
目前支持使用以下幾種類型的鏡像環境:
PyTorch鏡像和自定義Megatron
在DLC提供的公共鏡像中選擇一PyTorch類型的鏡像;下載Megatron并創建為代碼集,具體操作,請參見代碼配置。
集成了Megatron的鏡像
PAI提供了集成社區PyTorch和Megatron最新版本的鏡像:
registry.${region}.aliyuncs.com/pai-dlc/llmacc:23.05-gpu-py310-cu121-ubuntu22.04其中:${region}需要替換為當前地域ID,目前支持的地域為cn-beijing、cn-shanghai、cn-hangzhou、cn-shenzhen和cn-wulanchabu,您可以根據需要選擇其中一個。
本案例使用位于華北6(烏蘭察布)的靈駿智算資源,因此使用 registry-vpc.cn-wulanchabu.aliyuncs.com/pai-dlc/llmacc:23.05-gpu-py310-cu121-ubuntu22.04作為演示鏡像。
準備訓練數據
首先將詞表文件和合并規則表文件下載到本地。
本案例使用BPE 方式進行分詞,使用GPT-2的詞表和合并規則表:
對維基百科語料或自定義語料文件進行處理生成Megatron-LM支持的索引數據集文件。
任意選擇一種語料即可,本案例使用維基百科語料生成索引數據集文件。
維基百科語料
維基百科數據集是自然語言處理的常見語料,在詞表文件所在目錄使用WikiExtractor產生Megatron-LM支持的索引數據集文件:
# 1. Install wikiextractor pip install wikiextractor # 2. Download & extract to loose json wget https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2 python -m wikiextractor.WikiExtractor --json ./enwiki-latest-pages-articles.xml.bz2 # 3. Use nltk/spacy/ftfy to clean the corpus # 4. Convert the corpus into indexed datasets find text/ -type d | sed 's|text|mkdir -p datasets/text|' | sh find text/ -type f -name "wiki_*" | xargs -P $(nproc) -I{} \ bash -c "python env/megatron_lm/src/tools/preprocess_data.py --input {} \ --output-prefix datasets/{} \ --vocab-file gpt2-vocab.json \ --dataset-impl mmap \ --tokenizer-type GPT2BPETokenizer \ --merge-file gpt2-merges.txt \ --append-eod \ --workers 1 --chunk-size 1024" # 5. Merge indexed datasets mkdir -p flatten_datasets find datasets/text/ -type f | sed 's|\(.*\)/wiki\(.*\)|cp \1/wiki\2 ../../flatten_datasets/\1_wiki\2|' | sh python env/megatron_lm/src/tools/merge_datasets.py --output-prefix ./enwiki-latest-pages-articles --input flatten_datasets/自定義語料
使用loose JSON格式的語料,例如:
{"text": "A platform that provides enterprise-level data modeling services based on machine learning algorithms to quickly meet your needs for data-driven operations.", "type": "Eng", "id": "0", "title": "Machine Learning Platform for AI", "src": "www.alibabacloud.com"} {"text": "This topic describes how to use the Deep Learning Containers (DLC) of Machine Learning Platform for AI (PAI) to train transfer learning models based on the PyTorch framework.", "type": "Eng", "id": "42", "title": "Submit a standalone training job that uses PyTorch", "src": "www.alibabacloud.com"}使用Megatron-LM中提供的數據預處理工具對語料文件進行處理,可以產生Megatron-LM支持的mmap格式的索引數據集文件(my-gpt2_text_document.bin和my-gpt2_text_document.idx):
python /path/to/megatron-lm/tools/preprocess_data.py \ --input my-corpus.json \ --output-prefix my-gpt2 \ --vocab-file gpt2-vocab.json \ --dataset-impl mmap \ --tokenizer-type GPT2BPETokenizer \ --merge-file gpt2-merges.txt \ --append-eod \ --workers 2 \ --chunk-size 1執行后會打印出類似如下的日志:
Opening my-corpus.json > building GPT2BPETokenizer tokenizer ... > padded vocab (size: 50257) with 47 dummy tokens (new size: 50304) > building GPT2BPETokenizer tokenizer ... > building GPT2BPETokenizer tokenizer ... Vocab size: 50257 Output prefix: my-gpt2 Time to startup: 0.07754158973693848 > padded vocab (size: 50257) with 47 dummy tokens (new size: 50304) Done! Now finalizing. > padded vocab (size: 50257) with 47 dummy tokens (new size: 50304)創建數據集。
生成索引數據集文件后,您可以將詞表文件、合并規則文件和索引數據集文件上傳到OSS Bucket,具體操作,請參見控制臺上傳文件。
將上傳到OSS Bucket的數據創建為PAI數據集,具體操作,請參見創建及管理數據集。
說明如果OSS Bucket目錄中已產生了npy文件,您可以開啟數據集加速,提升數據訪問效率,具體操作,請參見在PAI平臺使用數據集加速器。
調整大規模訓練策略
參考附錄:PTD-P并行技術原理介紹,來配置訓練任務的優化策略,后續提交DLC容器訓練任務時,配置到執行命令中。目前支持使用以下兩種方式調整訓練策略。
手動調整訓練策略
在訓練大語言模型時,DLC支持在執行命令中配置以下參數手動調整訓練策略,來優化整體訓練性能。
參數 | 描述 |
--fp16 | 在Megatron-LM中支持使用fp16方式訓練模型。 |
--micro-batch-size |
|
--tensor-model-parallel-size | 用來配置tensor parallel size參數值。
|
--pipeline-model-parallel-size | 用來配置pipeline parallel size參數值。 您可以嘗試從1開始逐漸增加pipeline parallel size值,直到模型可以正常開始訓練,不出現OOM錯誤。 說明 pipeline parallel size參數值需要小于模型層數,且可以被模型層數整除。 |
--data-parallel-size | 您可以根據嘗試獲得的tensor parallel size和pipeline parallel size的值,以及準備訓練的總卡數,算出可行的data parallel size值: |
--use-distributed-optimizer | 將參數配置為true,分別用來打開優化器狀態并行技術、序列并行技術、激活重算技術,來進一步優化顯存占用。 |
--sequence-parallel | |
--recompute-activations | |
--use-flash-attn | 將參數配置為true,用來打開flash attention,進一步提升計算效率。 |
--global batch size | 在模型效果允許的前提下增加global batch size,從而降低流水并行時的層間等待開銷。 |
自動調整訓練策略
如果訓練GPT-like模型,您可以使用準備鏡像環境與訓練數據章節中的集成了Megatron的鏡像,并只需提供 global batch size或者最大允許的global batch size,就可以使用如下命令自動拉起Megatron預訓練作業:
torchrun \
--nnodes $WORLD_SIZE \
--node_rank $RANK \
--nproc_per_node ${LOCAL_WORLD_SIZE:-4} \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT \
-m llmacc.pretrain \
--task-type llmacc.megatron.GPT \
--max-global-batch-size 16 \
# megatron arguments此外,也可以直接將llmacc作為工具算出可能的并行配置:
python \
-m llmacc.pretrain \
--task-type llmacc.megatron.GPT \
--world-size 64 # 64 GPUs in total \
--local-world-size 8 # 8 GPUs for each node \
--max-global-batch-size 16 \
# megatron arguments對于非GU50或GU100機型,您可以通過配置DEVICE_MEMORY_GB環境變量來配置顯存大小。
提交與管理任務
進入創建任務頁面,具體操作,請參見創建訓練任務。
在創建任務頁面,配置以下參數,其他參數配置詳情,請參見創建訓練任務。
本案例以訓練GPT-22B模型為例:
參數
描述
資源組
選擇已創建的靈駿智算資源。
優先級
配置為1。
節點鏡像
選擇鏡像地址,并配置:
registry-vpc.cn-wulanchabu.aliyuncs.com/pai-dlc/llmacc:23.05-gpu-py310-cu121-ubuntu22.04。任務類型
選擇PyTorch。
數據集配置
選擇已創建的數據集。
執行命令
配置為以下命令,執行命令配置詳情,請參見調整大規模訓練策略。
torchrun \ --nnodes $WORLD_SIZE \ --node_rank $RANK \ --nproc_per_node gpu \ --master_addr $MASTER_ADDR \ --master_port $MASTER_PORT \ -m llmacc.pretrain \ --task-type llmacc.megatron.GPT \ --num-layers 48 \ --num-attention-heads 64 \ --hidden-size 6144 \ --seq-length 2048 \ --max-position-embeddings 2048 \ --train-iters 100 \ --lr 2.0e-4 \ --min-lr 2.0e-4 \ --vocab-file /mnt/data/gpt2-vocab.json \ --merge-file /mnt/data/gpt2-merges.txt \ --data-path /mnt/data/enwiki-20230526-pages-articles \ --log-interval 10 \ --max-global-batch-size 32任務資源配置
節點數量:配置為2。
CPU(核數):80。
內存(GB):800。
共享內存(GB):800。
GPU(卡數):8。
單擊提交。
頁面自動跳轉到容器訓練任務頁面。在該頁面,您可以單擊任務名稱進入任務詳情頁面,來觀察任務執行狀態。
在任務詳情頁面下方單擊資源視圖,查看任務中使用的資源。
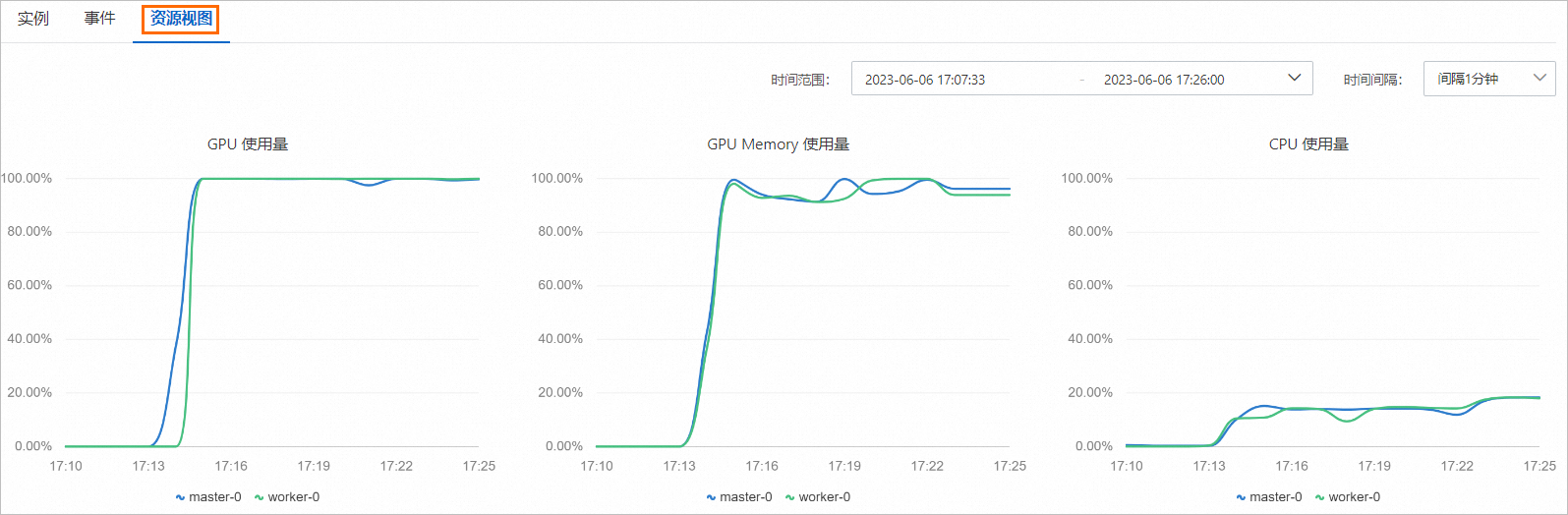
更多管理訓練任務的操作,請參見創建及管理容器訓練任務。
附錄:PTD-P并行技術原理介紹
大規模并行訓練的一個關鍵因素是并行訓練策略的選擇。在Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM和Reducing Activation Recomputation in Large Transformer Models這兩篇論文中介紹了Megatron-LM常見的大規模訓練策略。
常見的大模型訓練技術包括:數據并行技術、模型并行技術(包括張量并行技術和流水并行技術)、優化器狀態并行技術、序列并行技術、激活重算技術等:
數據并行技術(Data Parallel):在多個GPU組上有相同的模型參數副本,但讀取不同的樣本。在參數更新前使用allreduce來全局平均梯度,從而加速模型訓練。
優化器狀態并行技術(Distributed Optimizer / ZERO-DP):在使用數據并行技術的同時,將模型參數對應的優化器狀態切分到不同的GPU上,從而支持訓練更大的模型。
激活重算技術(Activation Recomputation):在反向傳播時重新計算部分激活,避免占用顯存存儲這部分激活,從而支持訓練更大的模型。
序列并行技術(Sequence Parallel):一個Transformer層內的dropout和layer-norm等部分參數切分到不同GPU上,從而支持訓練更大的模型。
模型并行技術(Model Parallel):在多個GPU上存放一套模型參數的不同分片,從而支持訓練更大的模型。
流水并行技術(Pipeline Parallel):模型內不同Transformer層切分到不同的GPU上;
張量并行技術(Tensor Parallel):一個Transformer層內的Attention和Linear部分參數切分到不同的GPU上;
模型并行的示意圖如下,來源:Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM和Reducing Activation Recomputation in Large Transformer Models。
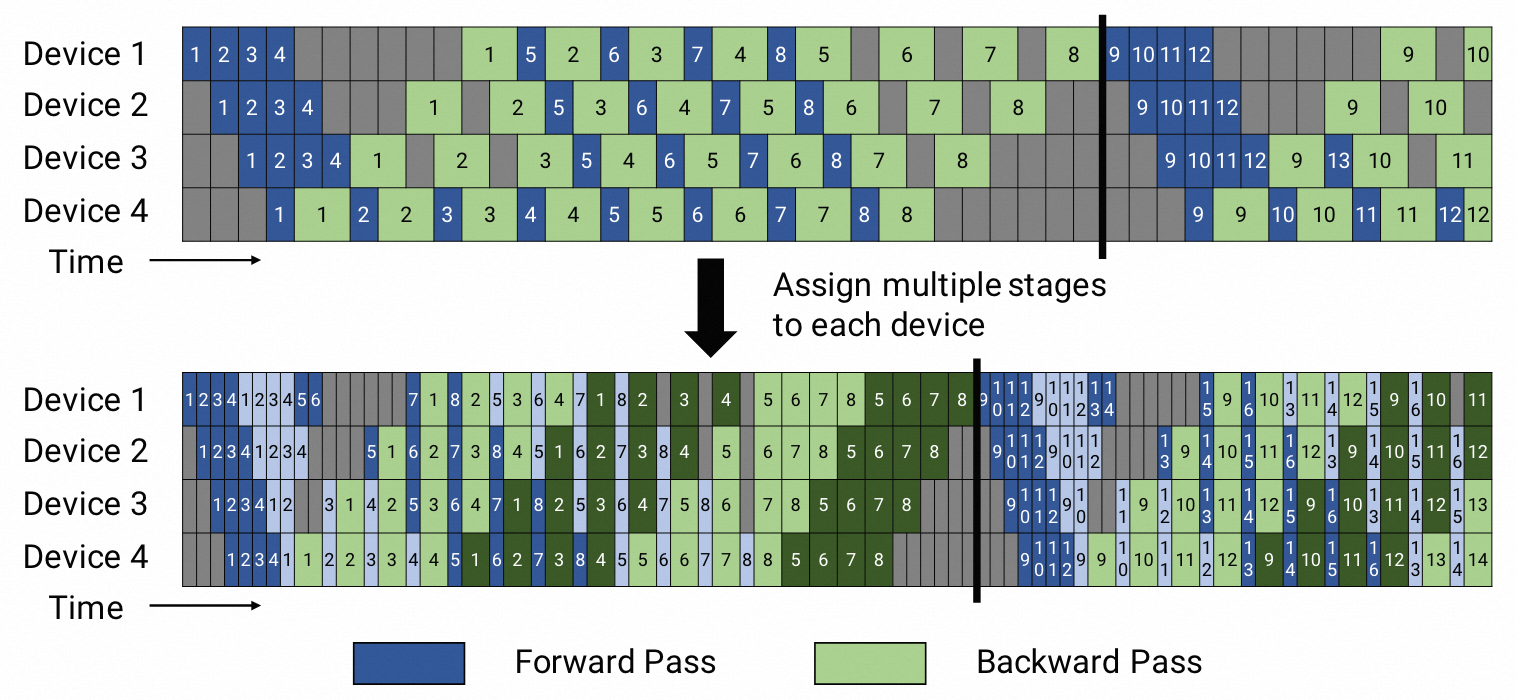


上述每種技術都有不同的權衡,如果互相結合需要仔細推敲才能獲得良好的訓練性能。Megatron-LM結合上述這些技術,提出了一種稱為PTD-P并行的技術,從而支持在千卡規模上以較好的計算性能來訓練大語言模型。