本文為您介紹如何使用深度學習框架TensorFlow,快速搭建圖像識別的預測模型。
前提條件
已創建OSS Bucket,并完成了OSS授權,詳情請參見控制臺創建存儲空間和云產品依賴與授權:Designer。
重要創建Bucket時,不要開通版本控制,否則可能導致訓練失敗。
已開啟GPU,詳情請參見MaxCompute資源。
背景信息
隨著互聯網發展,產生了大量圖片及語音數據。如何有效利用這些非結構化數據,一直是困擾數據挖掘工程師的一道難題。主要原因包括:
通常需要使用深度學習算法,上手門檻高。
通常需要依賴GPU計算引擎,計算資源費用高。
Designer及原PAI-Studio已經預置了使用深度學習框架實現圖片分類的模板,您可以直接從模板創建實驗,并將其復用到圖片鑒黃、物體檢測等領域。
數據集
本實驗使用CIFAR-10數據集,該數據集包含6萬張像素為32*32的彩色圖片,共10個類別,分別為飛機、汽車、鳥、貓、鹿、狗、青蛙、馬、船及卡車,如下圖所示。您可以下載該數據集及相關代碼,詳情請參見CIFAR 10案例。
使用過程中將該數據集拆分為訓練數據集(5萬張圖片)和預測數據集(1萬張圖片)。其中5萬張圖片的訓練數據集又被拆分為5個data_batch,1萬張圖片的預測數據集組成test_batch,如下圖所示。
數據準備
將本實驗的數據集和相關代碼上傳至OSS的Bucket路徑。例如,在OSS的Bucket下創建aohai_test文件夾及四個子文件夾,如下圖所示。 每個文件夾的作用如下:
每個文件夾的作用如下:
check_point:存儲實驗生成的模型。
說明從原PAI-Studio模板創建實驗后,必須手動將TensorFlow組件的checkpoint輸出目錄/模型輸入目錄參數配置為已有的OSS文件夾路徑,整個實驗才能運行。本實驗中,將checkpoint輸出目錄/模型輸入目錄配置為check_point文件夾路徑。
cifar-10-batches-py:存儲訓練數據集和預測數據集對應的數據源文件cifar-10-batcher-py和預測集文件bird_mount_bluebird.jpg。
train_code:存儲訓練數據,即cifar_pai.py。
predict_code:存儲cifar_predict_pai.py。
使用TensorFlow實現圖片分類
以原PAI-Studio的操作步驟為例,來說明如何使用TensorFlow實現圖片分類,具體操作步驟如下。
進入Designer頁面。
登錄PAI控制臺。
在左側導航欄單擊工作空間列表,在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應工作空間內。
在工作空間頁面的左側導航欄選擇,進入Designer頁面。
- 在可視化建模(Designer)頁面右上方,單擊前往舊版可視化建模(Studio)。
構建實驗。
在原PAI-Studio項目空間的左側導航欄,單擊首頁。
在模板列表,單擊Tensorflow圖片分類下的從模板創建。
在新建實驗對話框,配置參數(可以全部使用默認參數)。
參數
描述
名稱
輸入TensorFlow圖片分類。
項目
不支持修改。
描述
輸入使用TensorFlow實現圖片分類。
位置
選擇我的實驗。
單擊確定。
可選:等待大約十秒鐘,在原PAI-Studio控制臺的左側導航欄,單擊實驗。
可選:在我的實驗下,單擊TensorFlow圖片分類_XX。
其中我的實驗為已配置的實驗位置,TensorFlow圖片分類_XX為已配置的實驗名稱(_XX為系統自動添加的實驗序號)。
系統根據預置的模板,自動構建實驗,如下圖所示。
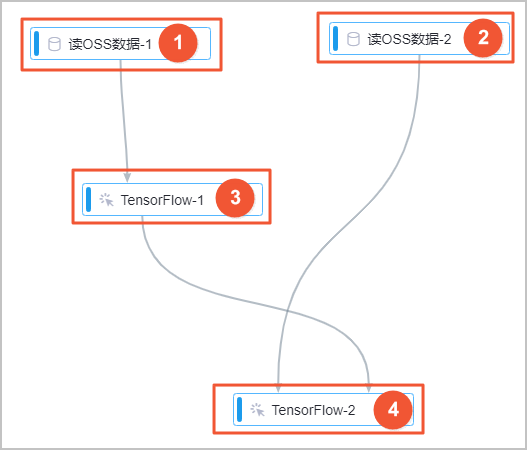
區域
描述
①
訓練數據,系統已自動配置了本實驗的訓練數據集路徑。如果使用其他數據集,只需單擊畫布中的讀OSS數據-1,在右側字段設置面板,將OSS數據路徑配置為存儲訓練數據的OSS路徑。
②
預測數據,系統已自動配置了本實驗的預測數據集路徑。如果使用其他數據集,只需單擊畫布中的讀OSS數據-2,在右側字段設置面板,將OSS數據路徑配置為存儲預測數據的OSS路徑。
③
使用TensorFlow訓練模型,只需要手動配置checkpoint輸出目錄/模型輸入目錄,其他參數使用默認值即可。該組件的參數與OSS路徑下的文件對應關系如下:
Python代碼文件:配置為OSS路徑中的cifar_pai.py。
OSS數據源目錄:配置為OSS路徑中的cifar-10-batches-py文件夾,系統會自動從上游讀OSS數據-1節點同步數據。
checkpoint輸出目錄/模型輸入目錄:配置為OSS路徑中的check_point文件夾,用于存儲輸出模型。
④
生成預測結果,只需要手動配置checkpoint輸出目錄/模型輸入目錄,其他參數使用默認值即可。該組件的參數與OSS路徑下的文件對應關系如下:
Python代碼文件:配置為OSS路徑中的cifar_predict_pai.py。
OSS數據源目錄:配置為OSS路徑中的cifar-10-batches-py文件夾,系統會自動從上游讀OSS數據-2節點同步數據。
checkpoint輸出目錄/模型輸入目錄:需要與TensorFlow訓練組件的模型輸出目錄保持一致,即配置為OSS路徑中的check_point文件夾。
運行實驗并查看輸出結果。
單擊畫布上方的運行。
實驗運行結束后,您可以在配置的OSS路徑(checkpoint輸出目錄/模型輸入目錄)下查看預測結果。
訓練代碼解析
針對cifar_pai.py文件中的關鍵代碼進行解析:
構建CNN圖片訓練模型
network = input_data(shape=[None, 32, 32, 3], data_preprocessing=img_prep, data_augmentation=img_aug) network = conv_2d(network, 32, 3, activation='relu') network = max_pool_2d(network, 2) network = conv_2d(network, 64, 3, activation='relu') network = conv_2d(network, 64, 3, activation='relu') network = max_pool_2d(network, 2) network = fully_connected(network, 512, activation='relu') network = dropout(network, 0.5) network = fully_connected(network, 10, activation='softmax') network = regression(network, optimizer='adam', loss='categorical_crossentropy', learning_rate=0.001)訓練生成模型model.tfl
model = tflearn.DNN(network, tensorboard_verbose=0) model.fit(X, Y, n_epoch=100, shuffle=True, validation_set=(X_test, Y_test), show_metric=True, batch_size=96, run_id='cifar10_cnn') model_path = os.path.join(FLAGS.checkpointDir, "model.tfl") print(model_path) model.save(model_path)
預測代碼解析
針對cifar_predict_pai.py文件中的關鍵代碼進行解析。首先讀入圖片bird_bullocks_oriole.jpg,將其調整為32*32像素大小。然后傳入model.predict預測函數評分,返回這張圖片對應的十種分類[‘airplane’,’automobile’,’bird’,’cat’,’deer’,’dog’,’frog’,’horse’,’ship’,’truck’]的權重。最后將權重最高的一個分類作為預測結果返回。
predict_pic = os.path.join(FLAGS.buckets, "bird_bullocks_oriole.jpg")
img_obj = file_io.read_file_to_string(predict_pic)
file_io.write_string_to_file("bird_bullocks_oriole.jpg", img_obj)
img = scipy.ndimage.imread("bird_bullocks_oriole.jpg", mode="RGB")
# Scale it to 32x32
img = scipy.misc.imresize(img, (32, 32), interp="bicubic").astype(np.float32, casting='unsafe')
# Predict
prediction = model.predict([img])
print (prediction[0])
print (prediction[0])
#print (prediction[0].index(max(prediction[0])))
num=['airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck']
print ("This is a %s"%(num[prediction[0].index(max(prediction[0]))]))