EAS提供了場景化部署方式,通過簡單配置幾個參數,您便可以一鍵部署集成了大語言模型(LLM)和檢索增強生成(RAG)技術的對話系統服務,顯著縮短服務部署時間。在使用該服務進行推理驗證時,它能夠有效地從知識庫中檢索相關信息,并與大語言模型的回答相結合,以產生準確且信息豐富的答案,從而大幅提高問答的質量和整體性能。該服務適用于問答、摘要生成和依賴外部知識的自然語言處理任務。本文為您介紹如何部署RAG對話系統服務以及如何進行模型推理驗證。
背景信息
大語言模型(LLM)在生成準確性和實時性回復方面存在局限,因此并不適合直接用于需要精確信息的客服或問答等場景。為了解決這一問題,當前業界廣泛采用的方法是利用檢索增強生成(Retrieval-Augmented Generation, RAG)技術來增強LLM的性能,這一技術可以顯著提升問答、摘要生成以及其他需要引用外部知識的自然語言處理(NLP)任務的質量。
RAG通過將大語言模型(如通義千問)和信息檢索組件結合在一起,增強了模型生成答案的準確性和信息量。在處理用戶查詢時,RAG通過信息檢索組件在知識庫中尋找與查詢相關的文檔或信息片段,將這些檢索到的內容與原始查詢一同輸入大語言模型之后,模型能夠利用現有的歸納生成能力產生基于最新信息的、符合事實的回復,而無需對模型進行重新訓練。
使用EAS部署的對話系統服務,通過集成大語言模型(LLM)和檢索增強生成(RAG)技術,克服了LLM在準確性和實時性方面的局限,為多種問答場景提供了準確且信息豐富的響應,從而提升了自然語言處理任務的整體效能和用戶體驗。
前提條件
注意事項
本實踐受制于LLM服務的最大Token數量限制,旨在幫助您體驗RAG對話系統的基本檢索功能:
該對話系統受制于LLM服務的服務器資源大小以及默認Token數量限制,能支持的對話長度有限。
如果無需進行多輪對話,建議您在RAG服務的WebUI頁面關閉with chat history功能,這樣能有效減少達到限制的可能性。詳情請參見如何關閉RAG服務的with chat history功能。
步驟一:部署RAG服務
部署大模型RAG對話系統,并綁定向量檢索庫,具體操作步驟如下:
登錄PAI控制臺,在頁面上方選擇目標地域,并在右側選擇目標工作空間,然后單擊進入EAS。
在模型在線服務(EAS)頁面,單擊部署服務,然后在場景化模型部署區域,單擊大模型RAG對話系統部署。
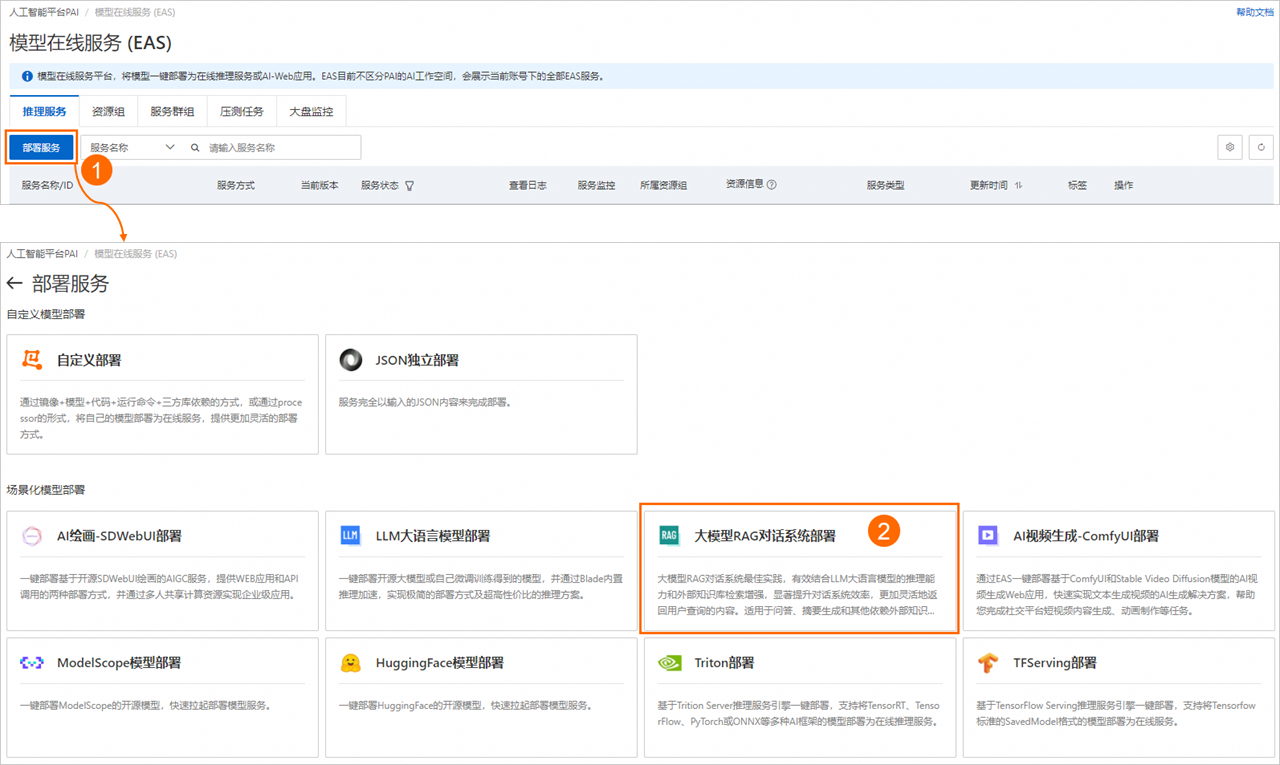
在部署大模型RAG對話系統頁面,配置以下關鍵參數。
基本信息
參數
描述
模型來源
支持以下兩種模型來源:
開源公共模型:PAI預置了多種開源公共模型供您選擇,包括Qwen、Llama、ChatGLM、Baichuan、Falcon、Yi、Mistral、Gemma、DeepSpeek等。您可以直接部署相應參數量的模型。
自持微調模型:PAI也支持部署您自行微調后的模型,來滿足特定的場景。
模型類別
當使用開源公共模型時,您可以根據具體使用場景選擇相應參數量的開源模型。
使用自持微調模型時,您需要根據您微調的模型,選擇相應的模型類別、參數量以及精度。
模型配置
使用自持微調模型時,您需配置微調模型的文件路徑。后續部署服務時,系統將從該路徑讀取模型配置文件。支持以下兩種配置類型:
說明建議您在Huggingface的Transformers下運行微調后的模型,確認其輸出結果符合預期后,再考慮將其部署為EAS服務。
對象存儲(OSS):請選擇微調模型文件所在的OSS存儲路徑。
文件存儲(NAS):請選擇微調模型文件所在的NAS文件系統、NAS掛載點和NAS源路徑。
資源配置
參數
描述
資源配置選擇
在選擇模型類別后,系統將自動匹配適合的資源規格。更換至其他資源規格,可能會導致模型服務啟動失敗。
推理加速
目前,部署在A10或GU30系列機型上的Qwen、Llama2、ChatGLM或Baichuan2等系列模型服務,支持啟用推理加速功能。支持以下兩種加速類型:
PAI-BladeLLM自動推理加速:BladeLLM提供超高性價比的大模型推理加速能力,可幫助您一鍵享受高并發和低延時的技術優勢。
開源框架vllm推理加速
向量檢索庫設置
RAG支持通過Faiss(Facebook AI Similarity Search)、Elasticsearch、Milvus、Hologres、OpenSearch或RDS PostgreSQL構建向量檢索庫。根據您的場景需要,任意選擇一種版本類型,作為向量檢索庫。
FAISS
使用Faiss構建本地向量庫,無需購買線上向量庫產品,免去了線上開通向量庫產品的復雜流程,更輕量易用。
參數
描述
版本類型
選擇FAISS。
OSS地址
選擇當前地域下已創建的OSS存儲路徑,用來存儲上傳的知識庫文件。如果沒有可選的存儲路徑,您可以參考控制臺快速入門進行創建。
說明如果您選擇使用自持微調模型部署服務,請確保所選的OSS存儲路徑不與自持微調模型所在的路徑重復,以避免造成沖突。
ElasticSearch
配置阿里云ElasticSearch實例的連接信息。關于如何創建ElasticSearch實例及準備配置項,請參見準備向量檢索庫Elasticsearch。
參數
描述
版本類型
選擇Elasticsearch。
私網地址/端口
配置Elasticsearch實例的私網地址和端口,格式為
http://<私網地址>:<私網端口>。如何獲取Elasticsearch實例的私網地址和端口號,請參見查看實例的基本信息。索引名稱
輸入新的索引名稱或已存在的索引名稱。對于已存在的索引名稱,索引結構應符合PAI-RAG要求,例如您可以填寫之前通過EAS部署RAG服務時自動創建的索引。
賬號
配置創建Elasticsearch實例時配置的登錄名,默認為elastic。
密碼
配置創建Elasticsearch實例時配置的登錄密碼。如果您忘記了登錄密碼,可重置實例訪問密碼。
Milvus
配置Milvus實例的連接信息。關于如何創建Milvus實例及準備配置項,請參見準備向量檢索庫Milvus。
參數
描述
版本類型
選擇Milvus。
訪問地址
配置為Milvus實例內網地址。您可以前往阿里云Milvus控制臺的實例詳情頁面的訪問地址區域進行查看。
代理端口
配置為Milvus實例的Proxy Port,默認為19530。您可以前往阿里云Milvus控制臺的實例詳情頁面的訪問地址區域進行查看。
賬號
配置為root。
密碼
配置為創建Milvus實例時,您自定義的root用戶的密碼。
數據庫名稱
配置為數據庫名稱,例如default。創建Milvus實例時,系統會默認創建數據庫default,您也可以手動創建新的數據庫,具體操作,請參見管理Databases。
Collection名稱
輸入新的Collection名稱或已存在的Collection名稱。對于已存在的Collection,Collection結構應符合PAI-RAG要求,例如您可以填寫之前通過EAS部署RAG服務時自動創建的Collection。
Hologres
配置為Hologres實例的連接信息。如果未開通Hologres實例,可參考購買Hologres進行操作。
參數
描述
版本類型
選擇Hologres。
調用信息
配置為指定VPC的host信息。進入Hologres管理控制臺的實例詳情頁,在網絡信息區域單擊指定VPC后的復制,獲取域名
:80前的host信息。數據庫名稱
配置為Hologres實例的數據庫名稱。如何創建數據庫,詳情請參見創建數據庫。
賬號
配置為已創建的自定義用戶賬號。具體操作,請參見創建自定義用戶,其中選擇成員角色選擇實例超級管理員(SuperUser)。
密碼
配置為已創建的自定義用戶的密碼。
表名稱
輸入新的表名稱或已存在的表名稱。對于已存在的表名稱,表結構應符合PAI-RAG要求,例如可以填寫之前通過EAS部署RAG服務自動創建的Hologres表。
OpenSearch
配置為OpenSearch向量檢索版實例的連接信息。關于如何創建OpenSearch實例及準備配置項,請參見準備向量檢索庫OpenSearch。
參數
描述
版本類型
選擇OpenSearch。
訪問地址
配置為OpenSearch向量檢索版實例的公網訪問地址。您需要為OpenSearch向量檢索版實例開通公網訪問功能,具體操作,請參見準備向量檢索庫OpenSearch。
實例id
在OpenSearch向量檢索版實例列表中獲取實例ID。
用戶名
配置為創建OpenSearch向量檢索版實例時,輸入的用戶名和密碼。
密碼
表名稱
配置為準備OpenSearch向量檢索版實例時創建的索引表名稱。如何準備索引表,請參見準備向量檢索庫OpenSearch。
RDS PostgreSQL
配置為RDS PostgreSQL實例數據庫的連接信息。關于如何創建RDS PostgreSQL實例及準備配置項,請參見準備向量檢索庫RDS PostgreSQL。
參數
描述
版本類型
選擇RDS PostgreSQL。
主機地址
配置為RDS PostgreSQL實例的內網地址,您可以前往云數據庫RDS PostgreSQL控制臺頁面,在RDS PostgreSQL實例的數據庫連接頁面進行查看。
端口
默認為5432,請根據實際情況填寫。
數據庫
配置為已創建的數據庫名稱。如何創建數據庫和賬號,請參見創建賬號和數據庫,其中:
創建賬號時,賬號類型選擇高權限賬號。
創建數據庫時,授權賬號選擇已創建的高權限賬號。
表名稱
自定義配置數據庫表名稱。
賬號
配置為已創建的高權限賬號和密碼。如何創建高權限賬號,請參見創建賬號和數據庫,其中賬號類型選擇高權限賬號。
密碼
專有網絡配置
參數
描述
VPC
當選擇Hologres、ElasticSearch、Milvus、OpenSearch或RDS PostgreSQL作為向量檢索庫時,請確保所配置的專有網絡與選定的向量檢索庫保持一致。
說明使用OpenSearch作為向量檢索庫時,此處可以使用其他專有網絡,但需要確保該專有網絡具有公網訪問能力,并將綁定的彈性公網IP添加為OpenSearch實例的公網訪問白名單。具體操作,請參見使用公網NAT網關SNAT功能訪問互聯網和公網白名單配置。
當選擇Faiss作為向量檢索庫時,無需配置專有網絡。
交換機
安全組名稱
單擊部署。
當服務狀態變為運行中時,表示服務部署成功。
步驟二:通過WebUI頁面進行調試
請按照以下操作步驟,在WebUI頁面上傳企業知識庫文件并對問答效果進行調試。
1、連接向量檢索庫
RAG服務部署成功后,單擊服務方式列下的查看Web應用,啟動WebUI頁面。
配置Embedding模型。系統將通過該模型將文本分塊轉換為Embedding向量。
Embedding Model Name:系統內置四種模型供您選擇,將自動為您配置最合適的模型。
Embedding Dimension:設置Embedding維度,維度的設置對模型的性能有直接影響。在您選擇Embedding模型后,系統將自動配置Embedding維度,無需手動操作。
測試向量檢索庫連接是否正常。
系統已自動識別并應用了部署服務時配置的向量檢索庫設置。以Hologres為例,您可以單擊Connect Hologres,來驗證Hologres連接是否正常。如果連接失敗,請檢查步驟一中向量檢索庫配置是否正確,修改對應配置項為正確配置,然后重新連接實例。
2、上傳企業知識庫文件
您可以按照以下流程上傳您的企業知識庫文件,系統會自動按照PAI-RAG格式將知識庫存儲到向量檢索庫中,以方便您進行后續的知識檢索。您也可以利用向量檢索庫中已有的知識庫,但必須符合PAI-RAG格式要求,否則可能會導致檢索報錯。
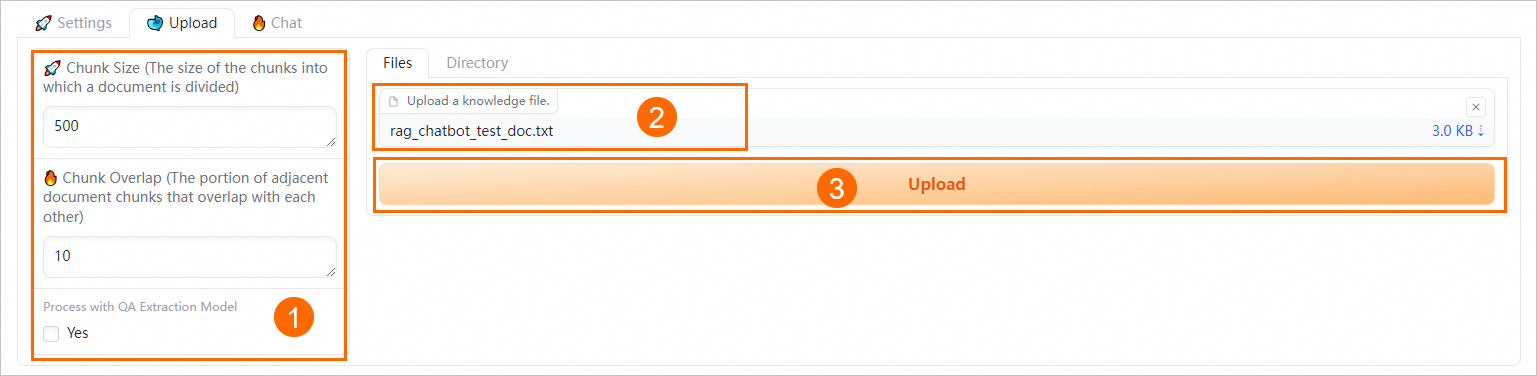
在Upload頁簽,設置語義分塊參數。
通過配置以下參數來控制文檔分塊粒度的大小和進行QA信息提取:
參數
描述
Chunk Size
指定每個文本分塊的大小,單位為字節,默認為500。
Chunk Overlap
表示相鄰分塊之間的重疊量,默認為10。
Process with QA Extraction Model
通過選中Yes復選框啟動QA信息提取功能,系統將在您上傳企業知識庫文件后自動抽取出QA對,以獲得更好的檢索和回答效果。
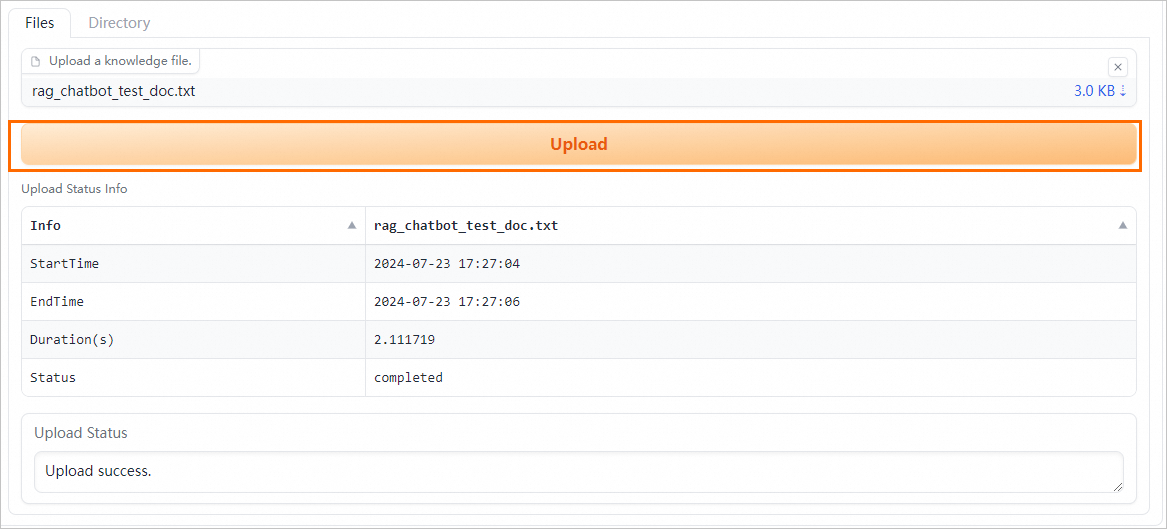
在Files或Directory頁簽下上傳企業知識庫文件(支持多文件上傳)或對應目錄。支持的文件類型為.txt、.pdf、Excel(.xlsx或.xls)、.csv、Word(.docx或.doc)、Markdown或.html,例如rag_chatbot_test_doc.txt。
單擊Upload,系統會先對上傳的文件進行數據清洗(包括文本提取、超鏈接替換等)和語義切塊,然后進行上傳。
3、配置模型推理參數
在Chat頁簽配置問答策略:
配置Retrieval問答策略

參數 | 說明 |
Streaming Output | 選中Streaming Output后,系統將以流式方式輸出結果。 |
Retrieval Mode | 支持以下三種檢索方式:
說明 在大多數復雜場景下,向量數據庫檢索召回都能有較好的表現。但在某些語料稀缺的垂直領域,或要求準確匹配的場景,向量數據庫檢索召回方式可能不如傳統的稀疏檢索召回方式。稀疏檢索召回方法通過計算用戶查詢與知識文檔的關鍵詞重疊度來進行檢索,因此更為簡單和高效。 PAI提供了BM25等關鍵詞檢索召回算法來完成稀疏檢索召回操作。向量數據庫檢索召回和關鍵詞檢索召回具有各自的優勢和不足,因此綜合二者的召回結果能夠提高整體的檢索準確性和效率。 倒數排序融合(Reciprocal Rank Fusion, RRF)算法通過對每個文檔在不同召回方法中的排名進行加權求和,以此計算融合后的總分數。當Retrieval選擇Hybrid時,PAI將默認使用RRF算法對向量數據庫召回結果和關鍵詞檢索召回結果進行多路召回融合。 |
Reranker Type | 大多數向量數據庫為了計算效率會犧牲一定程度的準確性,這使其檢索結果存在一定隨機性,原始返回的Top K不一定最相關。您可以選擇以下兩種排序類型,對向量數據庫第一次召回的Top K結果進行精度更高的Re-Rank操作,以得到相關度更高、更準確的知識文檔。
|
Top K | 向量檢索庫返回的相似結果數,即從向量數據庫中召回Top K條相似結果。 |
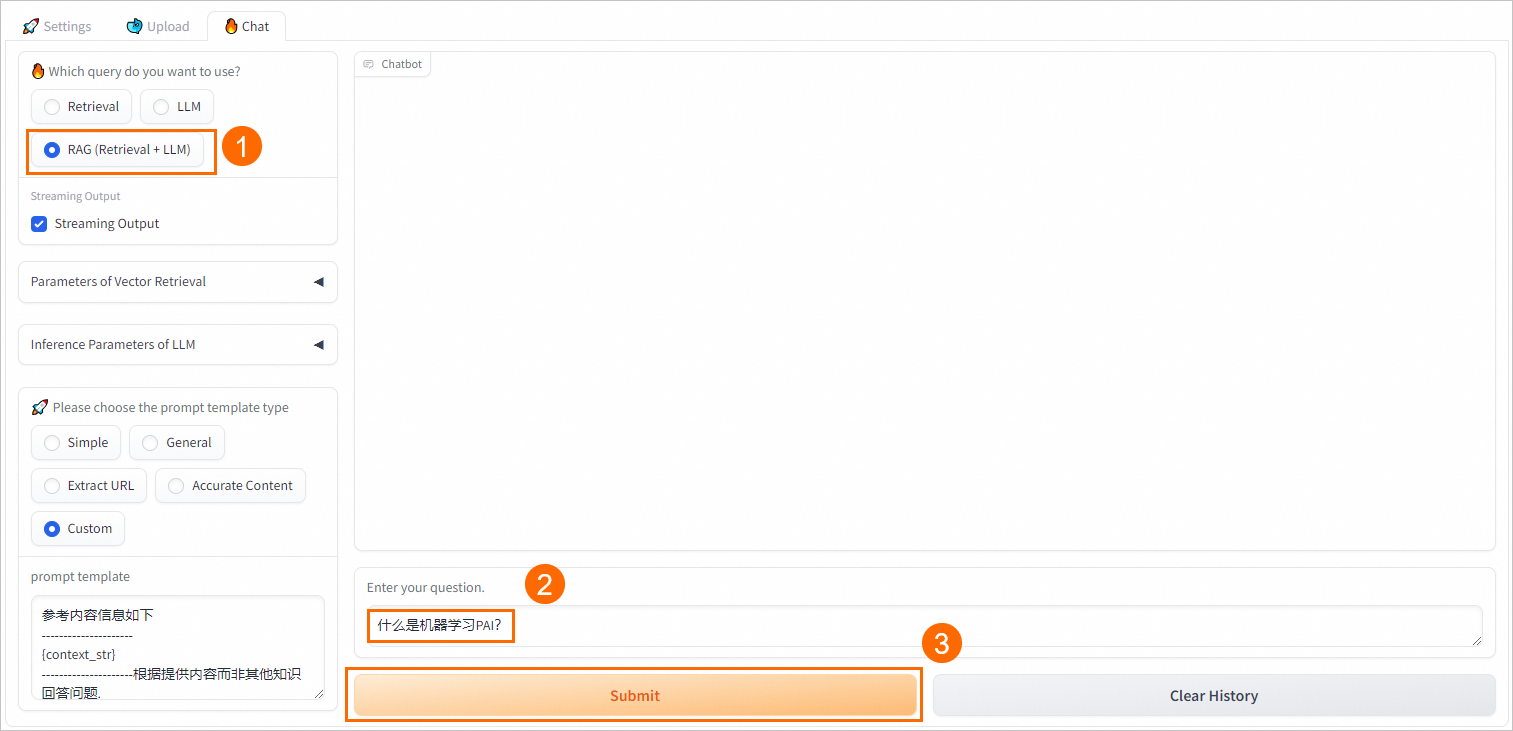
配置RAG(Retrieval + LLM)問答策略
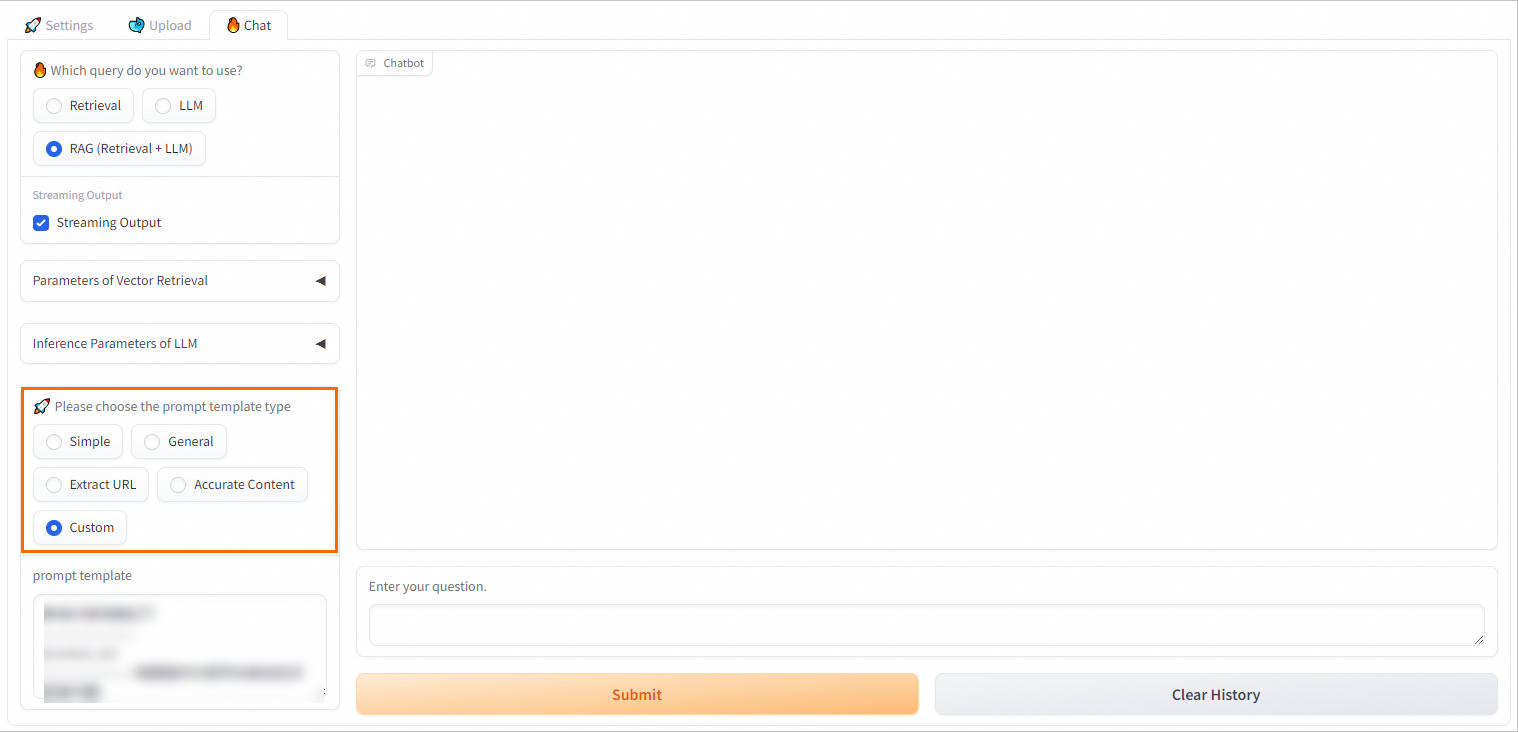
PAI提供多種不同的Prompt策略,您可以選擇合適的預定義Prompt模板或輸入自定義的Prompt模板以獲得更好的推理效果。RAG系統會將檢索返回的結果與用戶問題填充到提示詞模板中,隨后一并提交至大型語言模型進行處理。
此外RAG(Retrieval + LLM)問答方式還支持配置Streaming Output、Retrieval Mode和Reranker Type等參數。關于這些參數的配置說明,請參見配置Retrieval問答策略。
4、模型推理驗證
Retrieval
直接從向量數據庫中檢索并返回Top K條相似結果。
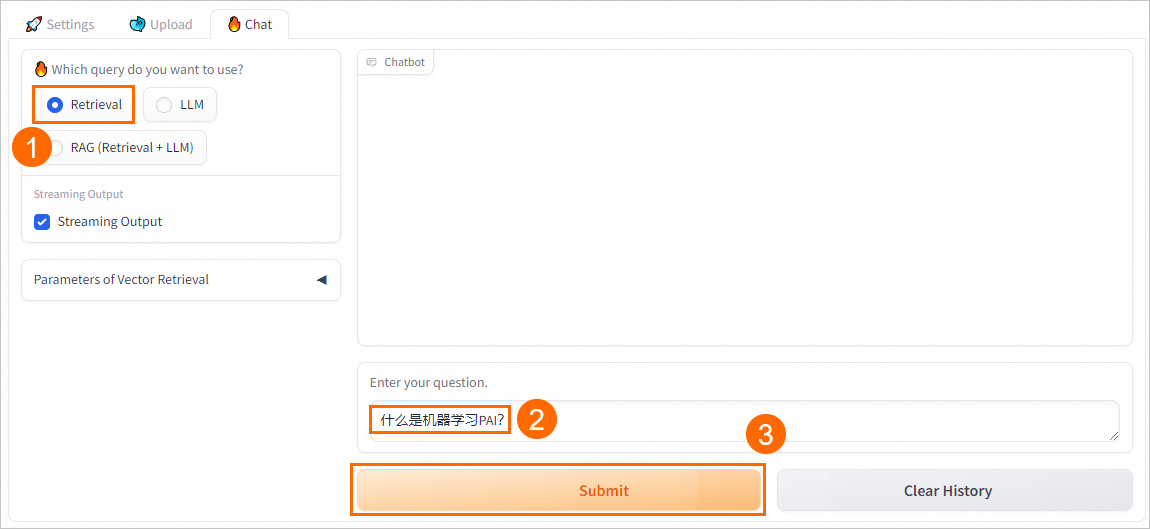
LLM
直接與EAS-LLM對話,返回大模型的回答。

RAG(Retrieval + LLM)
將檢索返回的結果與用戶問題填充至已選擇的Prompt模板中,一并送入EAS-LLM服務進行處理,從中獲取問答結果。
調試完成后,您可以基于PAI提供的API將其應用到您自己的業務系統中,詳情請參見步驟三:通過API調用進行模型推理。
步驟三:通過API調用進行模型推理
獲取RAG服務的調用信息。
單擊RAG服務名稱,進入服務詳情頁面。
在基本信息區域,單擊查看調用信息。
在調用信息對話框的公網地址調用頁簽,獲取服務訪問地址和Token。
您還可以根據已生成的符合PAI-RAG格式的表結構,將企業知識庫自行上傳到向量檢索庫中。
通過API調用服務。
PAI提供了三種調用API的對話方式:
service/query/retrieval(Retrieval)、service/query/llm(LLM)和service/query(RAG)。具體調用方法如下:cURL 命令
發送單輪對話請求
方式一:
service/query/retrieval(Retrieval)curl -X 'POST' '<service_url>service/query/retrieval' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平臺PAI?"}' # <service_url>替換為步驟1獲取的服務訪問地址;<service_token>替換為步驟1獲取的服務Token。方式二:
/service/query/llm(LLM)curl -X 'POST' '<service_url>service/query/llm' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平臺PAI?"}' # <service_url>替換為步驟1獲取的服務訪問地址;<service_token>替換為步驟1獲取的服務Token。支持添加其他可調推理參數,例如
{"question":"什么是人工智能平臺PAI?", "temperature": 0.9}。方式三:
service/query(RAG)curl -X 'POST' '<service_url>service/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平臺PAI?"}' # <service_url>替換為步驟1獲取的服務訪問地址;<service_token>替換為步驟1獲取的服務Token。支持添加其他可調推理參數,例如
{"question":"什么是人工智能平臺PAI?", "temperature": 0.9}。
發送多輪對話請求
其中對話方式RAG和LLM支持發送多輪對話請求,以RAG對話為例,具體配置方法如下:
# 發送請求。 curl -X 'POST' '<service_url>service/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平臺PAI?"}' # 傳入上述請求返回的session_id(對話歷史會話唯一標識),傳入session_id后,將對話歷史進行記錄,調用大模型將自動攜帶存儲的對話歷史。 curl -X 'POST' '<service_url>service/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "它有什么優勢?","session_id": "ed7a80e2e20442eab****"}' # 傳入chat_history(用戶與模型的對話歷史),list中的每個元素是形式為{"user":"用戶輸入","bot":"模型輸出"}的一輪對話,多輪對話按時間順序排列。 curl -X 'POST' '<service_url>service/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question":"它有哪些功能?", "chat_history": [{"user":"PAI是什么?", "bot":"PAI是阿里云的人工智能平臺......"}]}' # 同時傳入session_id和chat_history,會用chat_history對存儲的session_id所對應的對話歷史進行追加更新。 curl -X 'POST' '<service_url>service/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question":"它有哪些功能?", "chat_history": [{"user":"PAI是什么?", "bot":"PAI是阿里云的人工智能平臺......"}], "session_id": "1702ffxxad3xxx6fxxx97daf7c"}'
Python腳本
發送單輪對話請求,代碼示例如下:
import requests EAS_URL = 'http://xxxx.****.cn-beijing.pai-eas.aliyuncs.com' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', 'Authorization': 'MDA5NmJkNzkyMGM1Zj****YzM4M2YwMDUzZTdiZmI5YzljYjZmNA==', } def test_post_api_query_llm(): url = EAS_URL + '/service/query/llm' data = { "question":"什么是人工智能平臺PAI?" } response = requests.post(url, headers=headers, json=data) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = dict(response.json()) print(f"======= Question =======\n {data['question']}") print(f"======= Answer =======\n {ans['answer']} \n\n") def test_post_api_query_retrieval(): url = EAS_URL + '/service/query/retrieval' data = { "question":"什么是人工智能平臺PAI?" } response = requests.post(url, headers=headers, json=data) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = dict(response.json()) print(f"======= Question =======\n {data['question']}") print(f"======= Answer =======\n {ans['docs']}\n\n") def test_post_api_query_rag(): url = EAS_URL + '/service/query' data = { "question":"什么是人工智能平臺PAI?" } response = requests.post(url, headers=headers, json=data) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = dict(response.json()) print(f"======= Question =======\n {data['question']}") print(f"======= Answer =======\n {ans['answer']}") print(f"======= Retrieved Docs =======\n {ans['docs']}\n\n") # LLM test_post_api_query_llm() # Retrieval test_post_api_query_retrieval() # RAG(Retrieval+LLM) test_post_api_query_rag()其中:EAS_URL配置為RAG服務的訪問地址,您需要將訪問地址末尾的
/刪除;Authorization配置為RAG服務的Token。發送多輪對話請求
LLM和RAG(Retrieval+LLM)支持發送多輪對話請求,代碼示例如下:
import requests EAS_URL = 'http://xxxx.****.cn-beijing.pai-eas.aliyuncs.com' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', 'Authorization': 'MDA5NmJkN****jNlMDgzYzM4M2YwMDUzZTdiZmI5YzljYjZmNA==', } def test_post_api_query_llm_with_chat_history(): url = EAS_URL + '/service/query/llm' # Round 1 query data = { "question":"什么是人工智能平臺PAI?" } response = requests.post(url, headers=headers, json=data) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = dict(response.json()) print(f"=======Round 1: Question =======\n {data['question']}") print(f"=======Round 1: Answer =======\n {ans['answer']} session_id: {ans['session_id']} \n") # Round 2 query data_2 = { "question": "它有什么優勢?", "session_id": ans['session_id'] } response_2 = requests.post(url, headers=headers, json=data_2) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans_2 = dict(response_2.json()) print(f"=======Round 2: Question =======\n {data_2['question']}") print(f"=======Round 2: Answer =======\n {ans_2['answer']} session_id: {ans_2['session_id']} \n\n") def test_post_api_query_rag_with_chat_history(): url = EAS_URL + '/service/query' # Round 1 query data = { "question":"什么是人工智能平臺PAI?" } response = requests.post(url, headers=headers, json=data) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = dict(response.json()) print(f"=======Round 1: Question =======\n {data['question']}") print(f"=======Round 1: Answer =======\n {ans['answer']} session_id: {ans['session_id']}") print(f"=======Round 1: Retrieved Docs =======\n {ans['docs']}\n") # Round 2 query data = { "question":"它可以做什么?", "session_id": ans['session_id'] } response = requests.post(url, headers=headers, json=data) if response.status_code != 200: raise ValueError(f'Error post to {url}, code: {response.status_code}') ans = dict(response.json()) print(f"=======Round 2: Question =======\n {data['question']}") print(f"=======Round 2: Answer =======\n {ans['answer']} session_id: {ans['session_id']}") print(f"=======Round 2: Retrieved Docs =======\n {ans['docs']}") # LLM test_post_api_query_llm_with_chat_history() # RAG(Retrieval+LLM) test_post_api_query_rag_with_chat_history()其中:EAS_URL配置為RAG服務的訪問地址,您需要將訪問地址末尾的
/刪除;Authorization配置為RAG服務的Token。
相關文檔
通過EAS,您還可以完成以下場景化部署:
部署支持WebUI和API調用的LLM大語言模型,并在部署LLM應用后,利用LangChain框架集成企業知識庫,實現智能問答和自動化功能。詳情請參見5分鐘使用EAS一鍵部署LLM大語言模型應用。
部署基于ComfyUI和Stable Video Diffusion模型的AI視頻生成服務,幫助您完成社交平臺短視頻內容生成、動畫制作等任務。詳情請參見AI視頻生成-ComfyUI部署。
一鍵部署基于Stable Diffusion WebUI的服務。詳情請參見AI繪畫-SDWebUI部署。
常見問題
如何關閉RAG服務的with chat history功能
在RAG服務的WebUI頁面中,去勾選Chat history復選框。